Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Easily Copy or Migrate Schemas Anywhere with Schema Linking
Schema Linking is a new feature that’s available in preview for both Confluent Cloud and Confluent Platform 7.0 and can be used to complement Cluster Linking, in order to keep both schemas and topic data in sync between two clusters. Schema Linking can also be used independently of Cluster Linking, in order to replicate schemas between clusters for purposes of aggregation, backup, staging, and migration of schemas. Additionally, it can be used to replicate schemas within a single cluster. Get an overview of how Schema Linking works in the video below.
Schema Linking replaces and extends the functionality in Confluent Replicator that was used to migrate schemas from on-premises to Confluent Cloud. Schema Linking can replicate schemas between two Schema Registry clusters that are both in Confluent Cloud, which was not possible with Confluent Replicator. Schema Linking can also be used in both directions between two clusters, allowing each side to continue to receive both reads and writes for schemas.
With the introduction of Schema Linking, two new concepts have been added to Schema Registry: schema contexts and schema exporters.
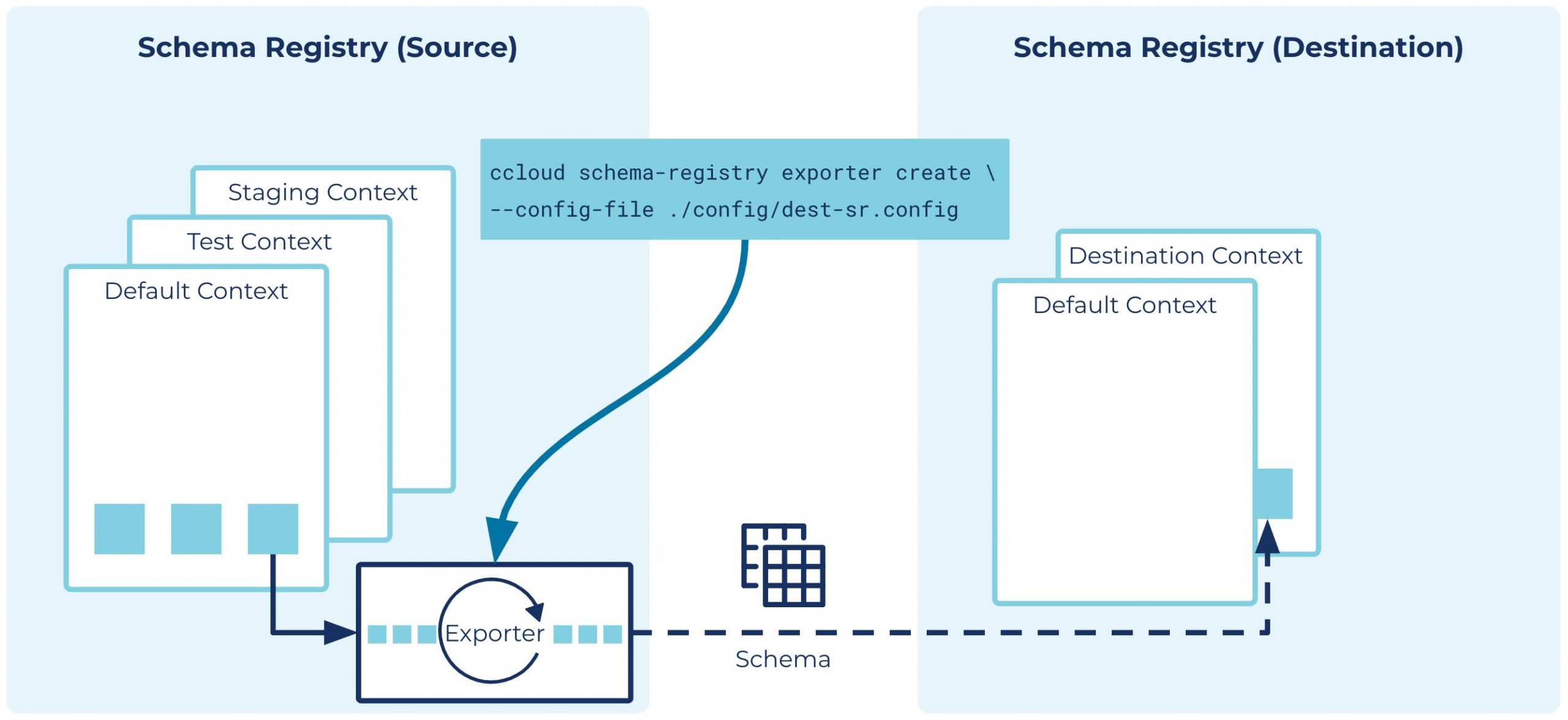
Schema contexts
A schema context represents an independent scope within Schema Registry, and can be used to create any number of separate “sub-registries” within one Schema Registry cluster. Each schema context is an independent grouping of schema IDs and subject names, so that the same schema ID in different contexts can represent completely different schemas.
Schema contexts allow you to separate schemas used for testing or pre-production from those used in production, all in the same Schema Registry cluster. They can also be used to import schemas from another Schema Registry cluster, while preserving the schema IDs and subject names from the original cluster.
Any schema ID or subject name without an explicit context lives in the default context, which is denoted by a single dot “.”. An explicit context starts with a dot and can contain any parts separated by additional dots, such as .mycontext.subcontext. You can think of context names as similar to absolute Unix paths, but with dots instead of forward slashes (in this analogy the default schema context is like the root Unix path). However, there is no relationship between two contexts that share a prefix.
A subject name can be qualified with a context, in which case it is called a qualified subject. When a context qualifies a subject, the context must be surrounded by colons. For example, :.mycontext:mysubject. A subject name that is unqualified is assumed to be in the default context, so that mysubject is the same as :.:mysubject. Any API that currently takes a subject name can be passed a qualified subject name.
Schema exporters
A schema exporter is a component that resides in Schema Registry that can be used to continuously export schemas from one Schema Registry cluster to another, or across different contexts within the same Schema Registry cluster. The lifecycle of a schema exporter is managed through APIs, which are used to create, pause, resume, and destroy a schema exporter. A schema exporter is like a “mini-connector” that can perform change data capture for schemas.
By default, a schema exporter will export schemas from the default context in the source Schema Registry to a new context in the destination Schema Registry. For Confluent Cloud, the default destination context will be the logical ID of the source cluster, while for Confluent Platform, it will be based on the Apache Kafka® cluster ID and Schema Registry group ID of the source cluster. The destination context (or a subject within the destination context) will be placed in IMPORT mode. This will allow the destination Schema Registry to use its default context as usual, without affecting any clients of its default context.
Note that two Schema Registry clusters can each have a schema exporter that exports schemas from the default context to the other Schema Registry. In this setup, each side can read from or write to the default context, and each side can read from (but not write to) the destination context. This allows you to match a Cluster Linking setup between two Kafka clusters in which you might have a mutable source topic and a read-only mirror topic on each side.
In addition, a schema exporter can copy schemas from one context to another within the same Schema Registry cluster. You might create a new context to stage schemas before they are ready to be used for production, and then later copy the schemas from the staging context to the default context using a schema exporter when they are finally production ready.
Summary
Schema Linking introduces two new concepts, schema contexts and schema exporters, that make managing and copying schemas easier than ever before. Schema Linking can be used to complement Cluster Linking, or to support scenarios such as aggregation, backup, staging, and migration of schemas, as well as many more. To learn more, please read the Schema Linking documentation. If you’d like to get started using Schema Linking, download Confluent Platform or sign up for a free trial of Confluent Cloud. You can use the promo code CL60BLOG for an additional $60 of free cloud usage.*
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.