Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
RBAC at Scale, Oracle CDC Source Connector, and More – Q2’22 Confluent Cloud Launch
The Confluent Q2 ‘22 cloud bundle, our latest set of product launches, is live and packed full of new features to help your business innovate quickly with real-time data streaming. Our quarterly launches provide a single resource to learn about the new features we’re bringing to Confluent Cloud, our fully managed data streaming platform.
This quarter, you’ll find new features designed to make securing your data and connecting your systems easier. Here’s an overview of everything included in this launch—read on for more details:
Here’s a quick glance at what’s new this quarter:
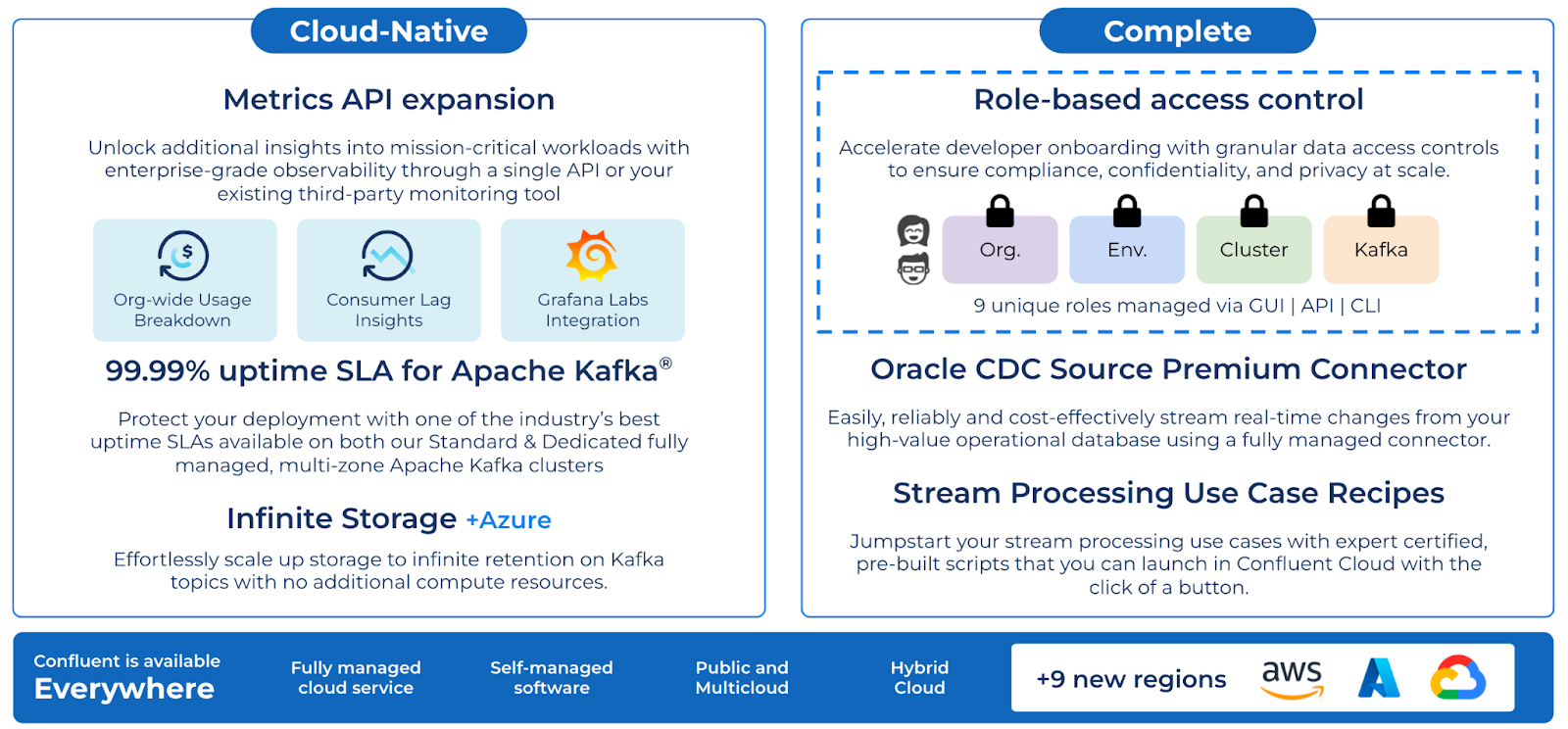
Q2 ‘22 Launch Summary

Accelerate developer onboarding with granular data access controls to ensure compliance, confidentiality, and privacy at scale through RBAC
Role-based access control (RBAC) is one of the most critical identity and access management tools on Confluent Cloud, allowing users to set role-based permissions per user for key resources like production environments, sensitive clusters, and billing details. We’ve expanded the scope of RBAC to cover access control for individual Apache Kafka® resources, including topics, consumer groups, and transactional IDs—enabling you to accelerate your developer onboarding while ensuring compliance, confidentiality, and privacy at scale. With the enhanced version of RBAC, you have access to granular yet intuitive controls to manage users and applications within a single cluster, a feature that no other Kafka service provides.
“Here at Neon we have many teams, with different roles and business contexts, that use Confluent Cloud. Therefore, our environment needs a high level of security to support these different needs. With RBAC we can isolate data for access only to people who really need to access it, and operations to people who really need to do it. The result is more security and less chance of failure and data leakage, reducing the scope of action.” -Thiago Pereira de Souza, Sr. IT Engineer at Neon
Learn more about how the expanded RBAC tool can accelerate developer onboarding here.
Easily, reliably, and cost-effectively stream real-time changes from your operational database with our new Oracle CDC Source Premium Connector
While Oracle DB remains one of the most commonly used relational databases, many companies are adopting more modern, cloud-native technologies. Using Kafka as the data streaming pipeline makes it easy to share business-critical operational data from the legacy system with the broader organization in real time with change data capture (CDC).
The new Oracle CDC Source Connector enables businesses to significantly reduce the resource burden and accelerate the time to market of this work. Traditionally, to transmit Oracle CDC data to Kafka, businesses either turn to proprietary solutions, which come with significant licensing fees, or invest internally to design, build, test, and maintain a customized connector, which incurs ongoing tech debt and operational management burdens.
Learn more about how you can save time and cost with this fully managed connector here.
In addition to the Oracle CDC Connector, we’ve launched five new fully managed connectors so you can share data more broadly from common databases, data stores, and apps: Amazon S3 Source, Azure Cosmos DB Source, InfluxDB 2 Source, InfluxDB 2 Sink, and Jira Source connectors.
Jumpstart your stream processing journey with expert-certified, pre-built scripts that you can launch with the click of a button
Many developers have asked us for a prescriptive approach to easily start with stream processing, which is why we launched Stream Processing Use Case Recipes, powered by ksqlDB. This packages the 25+ most popular real-world use cases which are validated by our experts.
“ksqlDB made it super easy to get started with stream processing thanks to its simple, intuitive SQL syntax. By easily accessing and enriching data in real-time with Confluent, we can provide the business with immediately actionable insights in a timely, consistent, and cost-effective manner across multiple teams and environments, rather than waiting to process in silos across downstream systems and applications. Plus, with the Stream Processing Use Case recipes, we will be able to leverage ready-to-go code samples to jumpstart new real-time initiatives for the business.” -Jeffrey Jennings, Vice President of Data and Integration Services at ACERTUS
Each recipe provides pre-built SQL code samples and a step-by-step tutorial to tackle the most popular, high-impact use cases for stream processing, helping developers move quickly from ideation to proof of concept. You can launch any of the recipes directly in Confluent Cloud with a single click of a button.
Learn more about how you can bootstrap your stream processing use cases here.
In addition to the recipes, we’ve raised the number of ksqlDB clusters you can deploy for each of your Kafka clusters from three to ten. This enables you to support even more stream processing applications and to isolate workloads across different teams more easily. We’ve also recently introduced a slew of improvements and new features with the launch of ksqlDB 0.24, including access to Kafka record headers, JSON functions, and pull query limit clause.

Unlock additional insights into mission-critical workloads through a single Metrics API or your existing third-party monitoring tools like Grafana Cloud
Confluent’s Metrics API gives you a fast and easy way to understand the performance of your Confluent Cloud deployments to deliver high-quality services and manage operating costs. We have expanded the Metrics API with two new capabilities: Principal ID breakdown for organizational chargebacks and consumer lag metric for performance monitoring. You can also choose to monitor data streams with Grafana Cloud integrations, the latest addition to the set of observability tool integrations available, including those that were launched in our Q1 bundle.
Learn more about the new metrics and Grafana Cloud integration here.
Protect your deployment with one of the industry’s best uptime SLAs at 99.99%
Service downtimes can have a huge impact, and a high SLA is more than just a metric—it reflects high levels of reliability and security.
Within this launch, you’ll also find a new 99.99% (“four 9s”) uptime SLA for our Standard and Dedicated multi-zone clusters. Covering not only infrastructure, but also Apache Kafka performance, critical bug fixes, security updates, and more, this comprehensive SLA allows you to run your most sensitive, mission-critical data streaming workloads in the cloud with high confidence.
You can pursue an even higher level of availability and protect yourself from cloud service provider-level outages by doing a multi-region or multi-cloud deployment using Confluent’s Cluster Linking feature.
Learn more about the updated 99.99% uptime SLA here.
Infinite Storage on Kafka topics with no additional compute resources, now available with all three main cloud providers
With Infinite Storage, now generally available for AWS, Microsoft Azure, and Google Cloud for both Standard and Dedicated clusters, you never have to worry about data storage limitations again. You can offer business-wide access to all of your data while creating an immutable system of record that ensures events are stored for as long as needed.

Stream your data consistently across all three major clouds, now available in 66 regions
We have added nine new regions in Europe and Asia across AWS, GCP, and Microsoft Azure.
Check out the full list of regions supported by Confluent Cloud here.
Simplify cluster link management with the brand-new Cluster Linking UI
You can now monitor the real-time performance of your existing cluster links in the new UI in lineage views at link and topic levels. We have also included copy-pastable CLI instructions to easily create new cluster links.
Check out a demo video of the new UI
Now let’s take a deeper dive into some of the individual features within the release. If you’ve already seen enough and are ready to learn how to put these new tools to use, register for the Confluent Q2 ‘22 launch demo webinar.
Learn more about select new features
Complete: Role-based access control
Role-based access control
Data security is paramount in any organization, especially as they migrate to public clouds. To operate efficiently and securely, organizations need to ensure the right people have the right access to only the right data. However, controlling access to sensitive data all the way down to individual Apache Kafka topics takes significant time and resources because of the complex scripts needed to manually set permissions.
Last year, we introduced RBAC to gate management access to critical resources like production environments, sensitive clusters, and billing details, all based on user roles. Today, we expanded the scope of RBAC to cover access control on Standard and Dedicated clusters for individual Kafka resources. This enables you to accelerate your developer onboarding while ensuring compliance, confidentiality, and privacy at scale.
The enhanced RBAC allows you to extend access to developers for critical resources like topics, and simplify developer onboarding using any of our API/CLI/GUI tools. You can also leverage a unified access control across users and applications, which enables better alignment and faster time to production. RBAC enables delegation of responsibility i.e., the ownership and management of access rests with the true owners of these resources. For example, you can onboard a development team and delegate the ownership of managing all Kafka resources to the team.
Some of the key highlights of RBAC include:
- Grant granular access controls, including create, read, write, and delete, for topics, consumer groups, and transactional IDs
- Set clear roles and permissions for administrators, operators, and developers to access only the required functions at the Kafka resource level
- View or manage them through whichever tools you choose, whether it’s the Confluent Cloud UI, CLI, or through our Confluent APIs
- Assign multiple roles for both users and service accounts
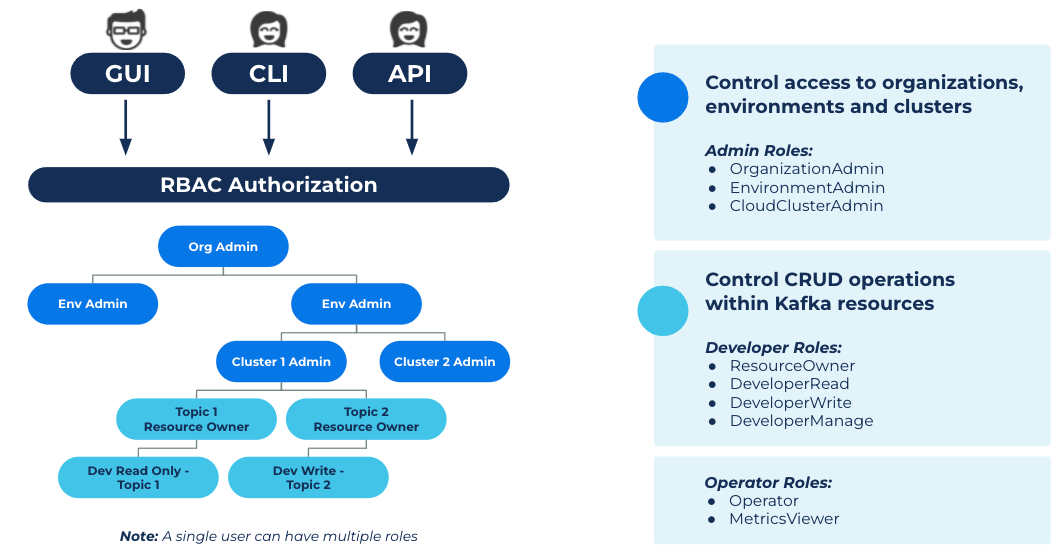
As shown above, the organization resource is the root node in the Confluent Cloud resource hierarchy. The Organization Admin has the authorization to set permissions across underlying environments, and the Environment Admin can set permissions across underlying clusters. With the new update, admins can now set granular permissions at the Kafka resource level. A single user can have multiple roles, including admin, developer, and operator across the hierarchy. These granular permissions and allocation flexibility are what make the enhanced RBAC impactful.
Complete: Oracle CDC Source Connector
Oracle CDC Source Connector
Oracle DB remains one of the most commonly used relational databases in enterprises. While Oracle DB excels at storing business-critical operational data, its rigidity makes it challenging to share data with other systems, especially across different environments. Many companies plan to migrate from this legacy system to a modern, cloud-native database. Leveraging Kafka as the streaming data pipeline for the migration enables teams to share real-time data broadly across the organization at massive scale and build real-time applications.
As Oracle DB constantly receives updates from heavy enterprise transaction workloads, Change Data Capture (CDC) technology captures the changes and provides real-time updates as new events occur. The two traditional approaches for sharing Oracle CDC data with Kafka both have their own challenges. First, companies may choose to purchase a legacy vendor’s proprietary solution, such as Oracle GoldenGate for Big Data, which can cost millions of dollars every year. Alternatively, teams could build their own Oracle CDC connector, which takes significant in-house engineering efforts due to integration complexity. After building the connector, you would also have to maintain, update, and manage it—resulting in ongoing tech debt and operational management burdens.
We’re excited to launch Confluent’s Oracle CDC Source Premium Connector, a fully managed connector that democratizes access to Oracle CDC data with no operational overhead. With this connector, you’re able to:
- Avoid prohibitive licensing costs of capturing high-value Oracle DB change events from legacy vendors
- Modernize your database by streaming valuable operational data to modern, cloud-native technologies
- Save ~12–24 engineering months and eliminate operational burden by leveraging pre-built, fully managed connection for a highly complex integration
The Oracle CDC Source Premium Connector is the first Premium Connector on Confluent Cloud. Premium Connectors provide high-value integrations with Kafka, solving for legacy system complexities, saving in-house build time, and reducing your total cost of ownership as an alternative to expensive proprietary licenses. It joins our rich ecosystem of over 65 (and counting) expert-built, fully managed source and sink connectors—the largest such portfolio in the market.
Cloud native: Metrics API expansion and Grafana Cloud integration
Metrics API Expansion and Grafana Cloud Integration
Businesses need a strong understanding of their IT stack to effectively deliver high-quality services and efficiently manage operating costs. For example, businesses need to monitor their consumer lag to ensure their real-time experiences are meeting expectations. Internally, they also need to monitor the usage of their various organizations and subdivisions to see where and how capacity is used.
To avoid monitoring data sprawling across clouds, hybrid environments, and disparate systems, companies have established internal monitoring stacks or leveraged third-party observability solutions to access all infrastructure performance indicators in one place.
Metrics API provides businesses with the easiest and fastest means to understand usage and performance for their Confluent Cloud deployments in their preferred stack for monitoring infrastructure. We have recently added two new capabilities to the API:
- Organizational-wide usage breakdown: With the new principal_id label, you can now easily break down organizational resource consumptions by users or service accounts for a more accurate organizational chargeback. This will provide insights into resource over- or underutilization down to the user level, informing internal controls and better resource allocation.
- Consumer lag monitoring: Consumer lag information was originally available via Cloud UI, client-side monitoring, and Admin API. With the newly available server-side access through Metrics API and the added option for a time series view, you can not only make better-informed decisions about resource scaling and retention policy, but also avoid additional operational complexities by integrating the metrics with your existing monitoring stack of choice.
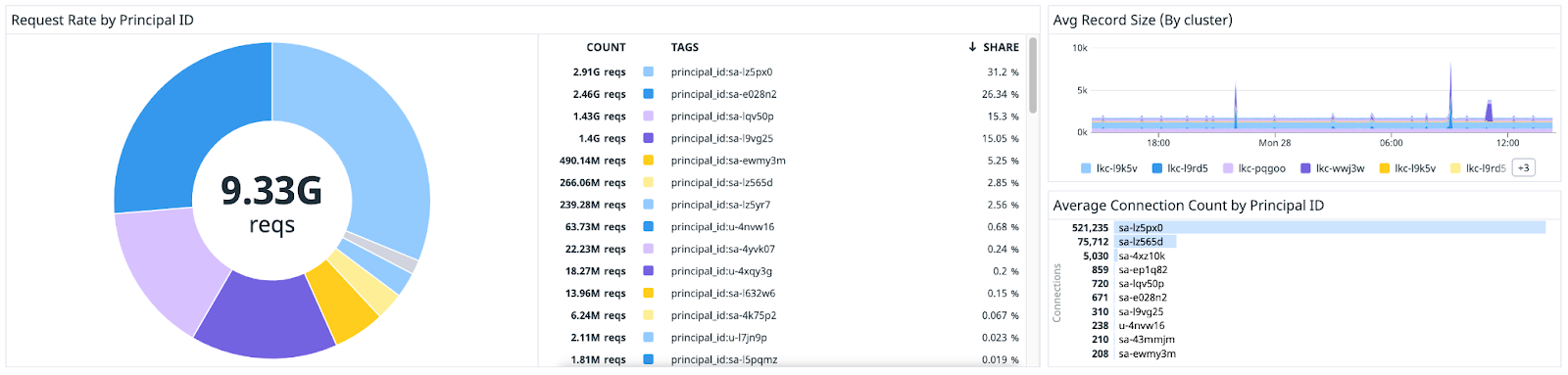
Usage breakdown by service accounts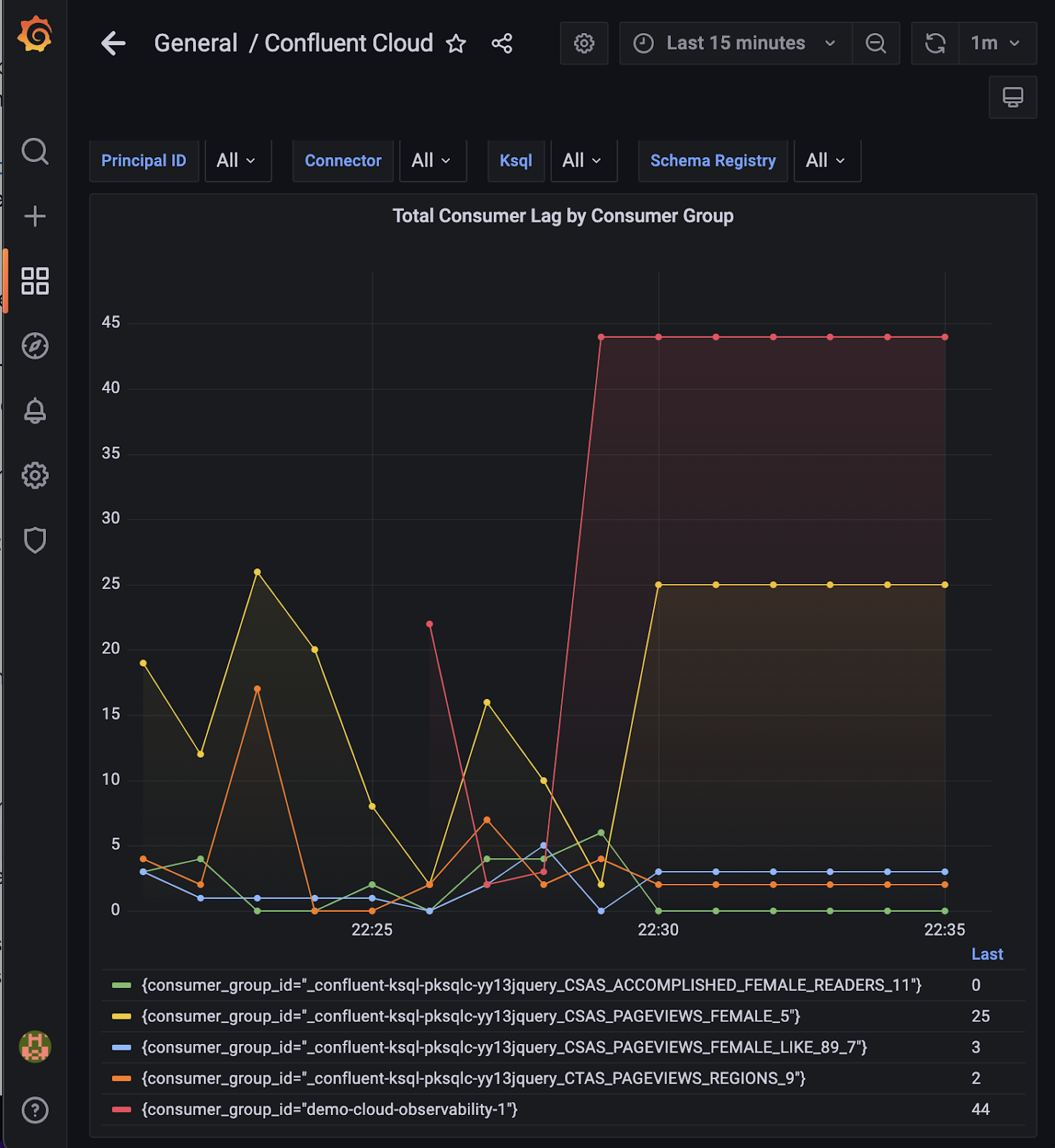
Consumer lag time series data can be shown on your chosen third-party visualization tool
Confluent Cloud customers can also choose to monitor their data streams with our new Grafana Cloud integration, the latest addition to the various options we’re building for customers to monitor Confluent Cloud within their chosen third-party tools. Learn more about how to set up and leverage this new integration within the Grafana announcement blog.
Start building with features in the Confluent Q2 ‘22 Launch
Ready to get started? Remember to register for the Q2 ‘22 Launch demo webinar where you’ll learn firsthand how to put these new features to use from our product managers!
And if you haven’t done so already, sign up for a free trial of Confluent Cloud. New signups receive $400 to spend within Confluent Cloud during their first 60 days. Use the code CL60BLOG for an additional $60 of free usage.*
Looking for expert advice on how these new features can meet your specific use cases? Reach out to our committer-led Professional Services team via your account executive or by submitting a request.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.