[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Compare
Apache Kafka® vs Amazon Kinesis: What’s the Difference?
In today's data-driven world, real-time data streaming is a necessity for everything from website clickstreams and IoT sensor data to real-time analytics. Two of the most prominent names in this space are Apache Kafka® and Amazon Kinesis.
While both platforms serve a similar purpose—managing and acting on data as continuous streams—they are built on fundamentally different philosophies. The choice between Kafka and Kinesis often comes down to a core streaming tradeoff: control versus simplicity.



In this guide, we’ll compare Kafka and Kinesis on architectural design, operational model, key features, and total cost of ownership (TCO) to help you decide which platform is right for your next streaming architecture.
Apache Kafka vs Amazon Kinesis: A Quick Comparison
Apache Kafka is an open source, distributed event streaming platform used for building real-time data pipelines and streaming applications. Organizations often choose it for high-throughput, fault-tolerant data management with a high degree of control over the infrastructure.
In contrast, Amazon Kinesis is a fully managed, serverless real-time data streaming service provided by Amazon Web Services (AWS). It is designed to simplify the collection, processing, and analysis of streaming data, as AWS manages the underlying infrastructure.
What Is the Core Difference Between Kafka and Kinesis?
Both Kafka and Kinesis utilize a publish-subscribe model to handle event streams. However, their primary differences lie in control, ecosystem, and data retention models.
Side-by-Side Comparison: Key Attributes of Kafka and Kinesis
|
Feature |
Apache Kafka |
Amazon Kinesis |
|
Management Model |
Open source engine (self-managed or as a managed service) |
Fully managed, serverless service (AWS-managed) |
|
Control |
Offers high control: Provides deep, granular control over configuration, deployment, operations, and data. |
Low control: AWS handles infrastructure, scaling, and operations; users manage data flow. |
|
Ecosystem |
Vast open ecosystem: Extensive open-source community (e.g., Kafka Connect, ksqlDB) and broad vendor support. |
AWS-centric: Deep native integration with other AWS services (e.g., Lambda, S3, Redshift). |
|
Data Retention |
Flexible, long-term retention: Retention is configurable by topic and can be unlimited, stored on your own clusters. |
Time-limited data retention: Default retention is 24 hours, extendable up to 1 year (with Kinesis Data Streams). |
When Should You Choose Kafka vs. Kinesis?
Organizations often choose one or the other based on their ecosystem and management preferences. Kinesis is a common choice for teams already deeply embedded in the AWS ecosystem who need simple, serverless ingestion. Kafka is often chosen by teams that require ultimate control, hybrid-cloud or multi-cloud flexibility, and an open source standard.
For these reasons, many large organizations use both Kafka and Kinesis: a common pattern involves using Kinesis for simple, serverless data collection within a specific AWS application, which then feeds that data into a central Kafka environment that acts as the organization's "central nervous system" for data.
How Do Kafka and Kinesis Compare on Architecture and Design?
While both platforms move data, their underlying architectures are fundamentally different. The Kafka architecture is designed as a distributed, log-based storage system, whereas Amazon Kinesis is a managed service in which capacity is provisioned as a stream.
Think of Kafka's architecture as a commit log or a file system designed specifically for streaming data. This design gives you granular control over data retention, replication, and storage, treating your data as a continuous log that can be re-read multiple times by different applications:
-
Topics and Partitions: Data in Kafka is organized into topics (e.g., "user_clicks"). These topics are split into one or more partitions.
-
Durable Storage: Kafka stores ordered records in these partitions, which are appended to a log file on disk. Because the data is stored on disk, it is durable and can be retained for configurable periods—from minutes to years—or even indefinitely.
-
Brokers and Replication: These partitions are distributed and replicated across a cluster of servers called brokers. This replication makes Kafka highly fault-tolerant. If one broker fails, another broker with a copy of the partition can take over.
Amazon Kinesis's architecture is a fully managed service focused on data ingestion and throughput. The core concepts are streams and shards, and its design abstracts all infrastructure management, allowing you to focus purely on the data flow and scaling throughput up or down by adding or removing shards.
-
Streams and Shards: A Kinesis stream represents your data flow. Within that stream, you provision capacity using shards. Each shard is a fixed unit of capacity, offering 1MB/second of data ingestion and 2MB/second of data egress.
-
Managed Infrastructure: Unlike Kafka, you do not manage brokers or servers. Kinesis uses shards managed entirely within AWS. You simply specify the number of shards you need, and AWS handles the underlying infrastructure, provisioning, and scaling.
-
Ephemeral Storage: Data is stored temporarily (by default 24 hours, extendable up to one year). Kinesis is designed primarily for real-time processing and forwarding data to another destination (like Amazon S3, Lambda, or Redshift), not as a long-term data store.
Architectural Benefits: Control vs Simplicity
The architectural differences lead to clear, distinct benefits for each platform:
-
Kafka provides high control and flexibility. Its durable log-based design allows for configurable retention (including permanent storage), guarantees strict ordering within a partition, and is supported by a massive, open-source client ecosystem (Kafka Connect, Flink, Kafka Streams) that works across any cloud or on-premise environment.
-
Kinesis provides operational simplicity. It simplifies operations by abstracting all the underlying infrastructure. Teams can get started quickly without worrying about cluster management, and it scales by simply adjusting the shard count, making it a simple, serverless option for teams inside the AWS ecosystem.
Data Retention and Replay
A critical architectural difference that impacts system design is how each platform handles data retention and the ability to "replay" data. This capability is crucial for auditing, disaster recovery, and running new analytical models on historical data.
-
Kafka allows retention to be highly configurable. You can set retention policies per topic based on time (e.g., 30 days, 1 year, or indefinitely) or size (e.g., 1 TB). Because the log is persistent, Kafka supports long-term replay of events. A new application can subscribe and read the entire history of a topic from the very beginning. This makes it simple to replay events to recover from an application failure or train a new machine-learning model.
-
Kinesis is designed primarily for real-time processing, not long-term storage. By default, Kinesis offers limited retention windows set by the service configuration, typically from 24 hours to 7 days. While this is sufficient for many in-the-moment processing applications, it does not support the long-term replay use case. Data is expected to be processed and then moved to a permanent store (like Amazon S3) if historical access is required.
Scalability and Throughput
Both platforms are built to handle massive data volumes, but they approach scaling differently.
-
In Kafka, scaling is achieved through horizontal scaling via partitioning and cluster expansion. To increase throughput, you can add more partitions to a topic (which distributes the load) and add more brokers to your cluster to handle the increased work. This model offers near-infinite Kafka scalability, but it often requires manual intervention to add the new hardware (or VMs) and rebalance the partitions across the cluster.
-
Scaling in Kinesis is accomplished through shard-based scaling with automated management in AWS. A shard is a fixed unit of capacity. To scale up, you increase the number of shards in your stream; to scale down, you decrease them. This can be done on-demand or automatically, and AWS handles all the underlying infrastructure provisioning and management.
When comparing Kafka vs Kinesis throughput, the primary difference is the tradeoff between control and convenience.
-
Kafka gives you full control to fine-tune your cluster for specific performance needs, but you are responsible for the operational work.
- Kinesis provides the convenience of push-button, serverless scaling, but you are limited to the fixed capacity units (shards) that AWS provides.
Reliability and Delivery Guarantees
In data streaming, a "delivery guarantee" refers to the system's promise for how it handles messages. This is a critical factor for use cases like financial transactions or inventory management, where data loss or duplication is not an option.
- Kafka is well-known for providing strong, configurable delivery guarantees.
-
With the right configuration, Kafka offers configurable delivery guarantees up to and including exactly-once semantics. This ensures that a message is processed one time and one time only, even in the event of producer or broker failures. Kafka also provides strong ordering guarantees within a single partition.
-
For organizations that cannot compromise on reliability, Confluent extends Kafka's capabilities with enterprise-grade reliability, monitoring, and governance. This includes advanced monitoring tools to proactively detect issues, sophisticated data governance features to ensure data quality, and a complete platform designed for mission-critical 24/7 operations.
-
- As a managed service, Kinesis provides managed reliability with AWS SLAs. It ensures at-least-once delivery, which guarantees that a message will be delivered, but it might be delivered more than one time (duplicates are possible). Consumers must be designed to handle these potential duplicates. Kinesis provides ordering per shard, similar to Kafka's per-partition guarantee.
Ecosystem and Integration
A streaming platform's value is multiplied by its ability to connect to other systems. Here, the philosophies of Kafka and Kinesis diverge significantly.
-
As an open source standard, Kafka benefits from a massive, open Kafka ecosystem.
-
It has a vast library of Kafka connectors and native integrations with a wide range of data systems, including open-source processing engines (like Apache Flink, Apache Spark, and its own ksqlDB) and data stores (like MongoDB, Elasticsearch, and HDFS).
-
Confluent extends the open Kafka ecosystem by providing a library of 120+ pre-built, fully managed connectors that allow you to easily connect Kafka across all your environments—from on-premise systems to AWS services (including Kinesis itself) and other clouds like Google Cloud and Azure.
-
- Kinesis is designed for tight integration within the AWS cloud. It works seamlessly with other AWS services like AWS Lambda (for serverless processing), Amazon S3 (for data lake storage), Amazon Redshift (for warehousing), and Amazon EMR (for Spark processing). Its strength is its deep, native connection to this AWS-centric world.
Strategic Assessment: Benefits, Risks, Cost, and Operational Plan
The decision between Apache Kafka and Amazon Kinesis is not just about technology directly impacts one of the most critical factors for any business: the total cost and operational model.
-
Amazon Kinesis operates on a pay-as-you-go managed service model. You pay for the resources you provision (e.g., shard-hours) and the data you move (e.g., per GB). This model offers minimal operational overhead, as AWS handles all infrastructure management, patching, and availability. The cost is predictable as long as your data volume is predictable, but it can become expensive at a very high scale or with spiky, unpredictable workloads.
- Self-managed Kafka comes with a higher operational burden. You are responsible for provisioning hardware, installing and configuring the clusters, and managing 24/7 operations, including scaling, patching, and failure recovery. This requires a dedicated operations team with specialized Kafka expertise.
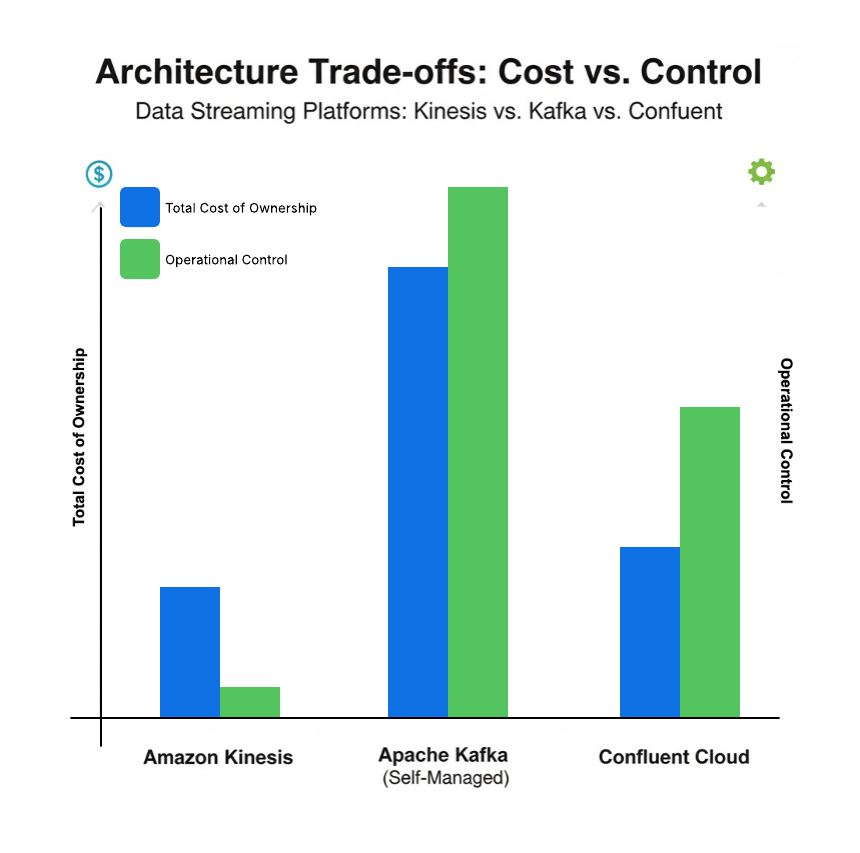
Self-managed Kafka often has the highest TCO. While the software is free, the combined cost of server infrastructure (or cloud VM equivalents), network bandwidth, and—most significantly—the multi-person engineering team required to operate it 24/7, makes it the most expensive option in practice. Kinesis has a low TCO for small-to-medium workloads, especially for teams already using AWS. The costs are primarily your direct AWS bill, but the technology won't be a replacement for Kafka in scenarios where you need fine-grained control, reliability, data retention, and replayability.
Where Does Managed Streaming Fit in the Kafka vs. Kinesis Comparison?
Choosing the right data streaming technology is critical for building reliable, scalable, and cost-efficient real-time systems. Organizations often choose one or the other based on their ecosystem and management preferences.
-
Kinesis is a common choice for teams already deeply embedded in the AWS ecosystem who need simple, serverless ingestion.
-
Kafka is often chosen by teams that require ultimate control, hybrid-cloud or multi-cloud flexibility, and an open-source standard.
Many organizations use Kinesis for simple, serverless data collection within AWS, while those workloads are then streaming into Kafka for centralized integration, governance, and processing. This is where a complete data streaming platform like Confluent becomes essential. Confluent is built on the foundation of open source Kafka but also provides a complete, cloud-native platform that goes beyond what Kafka can do alone. It simplifies management and provides enterprise-grade tools for streaming integration, governance, and security, allowing you to manage data streams from all sources (including Kinesis).
Comparison: Kafka vs. Kinesis vs. Confluent
Here are common use cases where we see customers using both Kinesis and Confluent:
-
Hybrid-Cloud Analytics: Imagine a global retailer uses Kinesis to ingest raw clickstream data from its AWS-hosted web app. It can then use a fully managed Confluent connector to stream that Kinesis data into a central Confluent Cloud cluster. This central cluster enriches the data and streams it to both an on-premise data warehouse and a separate cloud (like Google BigQuery on Google Cloud) for different analytics teams.
-
Centralized Governance: Financial services firms often use Kinesis for simple log collection within isolated AWS accounts. If all high-value transaction data flows through Confluent, then the organization can use the built-in Schema Registry and Data Portal to provide a single-pane-of-glass for data governance, ensuring all data, regardless of its source, is compliant and trustworthy before it's used by downstream applications.
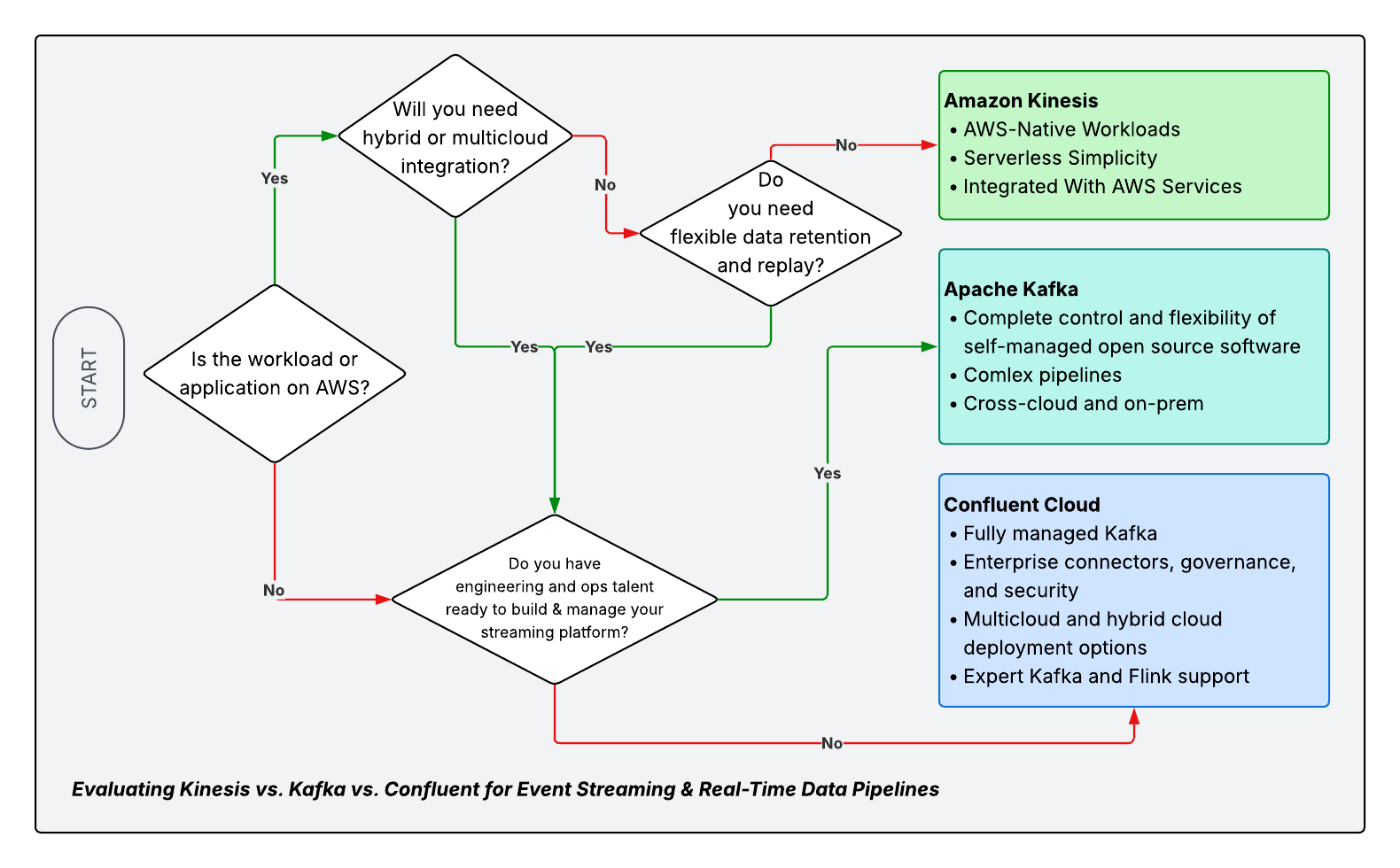
This table summarizes the key differences between self-managing open-source Kafka, AWS's managed Kinesis, and Confluent's data streaming platform. Explore this Confluent vs. Kinesis guide for a complete managed streaming comparison.
|
Feature |
Amazon Kinesis |
Open source Kafka |
Confluent |
|
Architecture |
Managed shards: A fully managed, serverless service. You provision "shards" (streams). |
Broker-based cluster: You self-manage brokers, topics, and partitions. |
Kafka-based platform: A complete platform built around Kafka, adding managed connectors, stream processing (Flink), and governance tools. |
|
Retention |
Time-limited: The default is 24 hours. Can be extended up to 1 year, but it is not designed for "forever" storage. |
Flexible (Unlimited): Limited only by your disk storage. Designed for permanent, long-term storage. |
Flexible & tiered: Unlimited retention (like Kafka) plus automated, cost-effective Tiered Storage to object stores (e.g., S3). |
|
Scaling |
Automatic (Shards): You provision the number of shards needed; AWS handles the underlying server scaling. |
Manual/semi-manual: You must manually add brokers and rebalance partitions. High operational effort. |
Automated & elastic: Fully managed cloud service provides push-button, elastic scaling of clusters, plus self-healing. |
|
Ordering |
Guaranteed: Strict ordering is guaranteed within a single shard. |
Guaranteed: Strict ordering is guaranteed within a single partition. |
Guaranteed: Same as Kafka (per-partition), with platform tools to easily manage partitioning. |
|
Ecosystem |
AWS-native: Deeply integrated with the AWS ecosystem (Lambda, S3, Redshift). Very limited outside of AWS. |
Vast (open source): A massive ecosystem (Kafka Connect, Kafka Streams) but requires manual setup and integration. |
Hybrid & multicloud: Connects to all clouds and on-prem systems with 120+ pre-built, fully managed connectors. |
|
Deployment |
Fully managed on AWS: A serverless offering. No servers to manage, but it is AWS-only. |
Self-managed: You deploy and operate it anywhere (on-prem, cloud VMs). High operational burden. |
Fully managed and self-managed: Can be self-managed (Confluent Platform) or a fully managed, serverless service on any major cloud (Confluent Cloud), as well as self-managed in private cloud (Confluent Private Cloud) and bring-your-own-cloud (BYOC) environments (WarpStream). |
|
Cost |
Pay-as-you-go: Pay per shard-hour and data transfer (GB). Can become very expensive at high scale. |
Hidden infrastructure & operations costs: "Free" (open source) software but has a very high TCO due to hardware and staffing. |
Consumption/subscription-based: Lower TCO than self-managing Kafka. Predictable pricing based on consumption (cloud) or subscription (on-prem). |
|
Governance |
AWS IAM: Governance is handled through standard AWS IAM policies. Lacks data-centric governance. |
Basic (ACLs): Provides basic security (ACLs). Governance tools (like schema registry) are separate projects. |
Integrated & centralized: Built-in Schema Registry, data lineage, data catalog, and role-based access control (RBAC) across all environments. |
Amazon Kinesis, self-managed Kafka, and Confluent Cloud each offer unique strengths depending on your operational needs, cloud strategy, and use case complexity.
The table below summarizes the key criteria and highlights which platform is best suited for which type of workload and organizational requirement.
Data Streaming Evaluation: Key Criteria for Comparing Kinesis, Kafka, and Confluent Cloud
|
Criteria |
Amazon Kinesis |
Self-Managed Apache Kafka |
Confluent Cloud |
|
Best For |
Simplicity and AWS-native workloads |
Maximum control and flexibility |
Fully managed Kafka with enterprise capabilities |
|
Cloud Strategy |
AWS-only environments |
Cross-cloud / hybrid deployments |
Multi-cloud (AWS, Azure, GCP) + hybrid |
|
Vendor Lock-In |
High AWS lock-in |
Avoids vendor lock-in; open source |
Low vendor lock-in; portable across clouds |
|
Operational Ownership |
Minimal operational overhead; serverless |
Requires a dedicated team for 24/7 ops |
No operational burden; fully managed |
|
Retention Needs |
Short retention (1–7 days) |
Long-term storage, large durable logs |
Long-term, scalable storage (Tiered Storage) |
|
Complexity of Use Case |
Simple real-time ingestion and processing |
Complex, high-scale pipelines |
Enterprise-wide streaming, governance, and mission-critical workloads |
|
Integrations |
Deep AWS integration (Lambda, S3, Redshift) |
Flexible; build your own connectors |
120+ connectors including Kinesis → Kafka |
|
Cost Profile |
Pay-as-you-go AWS pricing |
Higher engineering + infra costs |
Lowest TCO at scale due to no ops burden |
|
Security & Governance |
Basic AWS security |
Custom implementation required |
Enterprise-grade security, governance, and SLAs |
|
Ideal Scenarios |
Teams needing fast, AWS-native ingestion |
Teams wanting full control and customization |
Organizations needing a unified, governed streaming platform |
Get Started With Your Data Streaming Journey
Whether you're building a new real-time application or modernizing your data architecture, a data streaming platform is the foundation for success. Confluent provides a complete, cloud-native platform built for the enterprise, so you can focus on innovation, not operations.
-
Try Confluent Cloud: Start your free trial and get a fully managed Kafka cluster in minutes
-
Learn More: Explore more Kafka use cases and how to integrate with your tech stack
- Read the Blog: “How to build a hybrid streaming architecture with Confluent”
Kafka vs. Kinesis – FAQs
What is the difference between Kafka and Kinesis?
The primary difference is in their management and architecture.
- Kafka is an open source, distributed event streaming platform. You can run it anywhere (on-premise, any cloud), giving you high control, flexible data retention (unlimited), and a vast open-source ecosystem.
- Kinesis is a fully managed, serverless data streaming service on AWS. It offers simplicity and deep integration with the AWS ecosystem, but it is limited to the AWS cloud and has a limited data retention window (1-7 days).
Which is better for real-time data streaming, Kafka or Kinesis?
Both are powerful for real-time streaming, but "better" depends on your use case:
- Kinesis is often better for simple, serverless ingestion within an all-AWS ecosystem where operational simplicity is the top priority.
- Kafka is generally better for complex, large-scale pipelines, hybrid cloud or multicloud architectures, and use cases that require long-term data retention and event replay (e.g., compliance & auditing, historical data analytics).
Can Kafka run on AWS?
Yes, there are three primary ways to run Apache Kafka on AWS:
- Self-Managed: You can install and operate open source Kafka on your own AWS infrastructure (e.g., on EC2 virtual machines). This gives you full control but requires a high level of operational effort to manage, scale, and secure the cluster.
- Managed AWS Service: You can use an AWS-managed Kafka service, Amazon MSK. AWS addresses some operational gaps, but still incurs significant direct and indirect costs from overprovisioned clusters, operational overhead that remains your responsibility, and the impact of unplanned downtime and outages.
- Fully Managed Service: You can use a fully managed, cloud-native service like Confluent Cloud. Confluent runs on AWS for you, providing a serverless, elastic Kafka experience with 120+ pre-built connectors, enterprise security, and governance, which eliminates the operational burden.
How does Confluent work with Kinesis and AWS Services?
Confluent’s data streaming platform uses fully managed connectors to easily integrate its cloud-native Kafka engine with AWS services. For example, you can use the:
- Amazon Kinesis Source Connector to pull data from Kinesis and stream it into your central Confluent cluster.
- Amazon S3 Sink Connector to continuously archive data from Kafka to Amazon S3.
- Amazon Redshift Sink Connector to feed a real-time analytics dashboard.
This allows you to connect your AWS-native services to the broader Kafka ecosystem, including other clouds and on-prem systems.
What is the cost difference between Kafka and Kinesis?
Their cost models are very different and depend on your workload and whether or not you're comparing Kinesis against a self-managed Kafka deployment or a managed Kafka service. Here are the important cost considerations to keep in mind:
- Kinesis has a pay-as-you-go model. You pay per shard-hour and data transfer (GB). This is easy to start with but can become expensive at a high scale.
- Open source, self-managed Kafka is free to start but you must pay for the server infrastructure (e.g., EC2 instances) and, more importantly, the large, specialized operations team to manage it 24/7.
- Confluent offers a consumption-based model for its fully managed Kafka service on Confluent Cloud. It is designed to provide a much lower total cost of ownership than self-managing Kafka or managing hosted or partially managed Kafka services by eliminating all operational, scaling, and management burdens.