Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
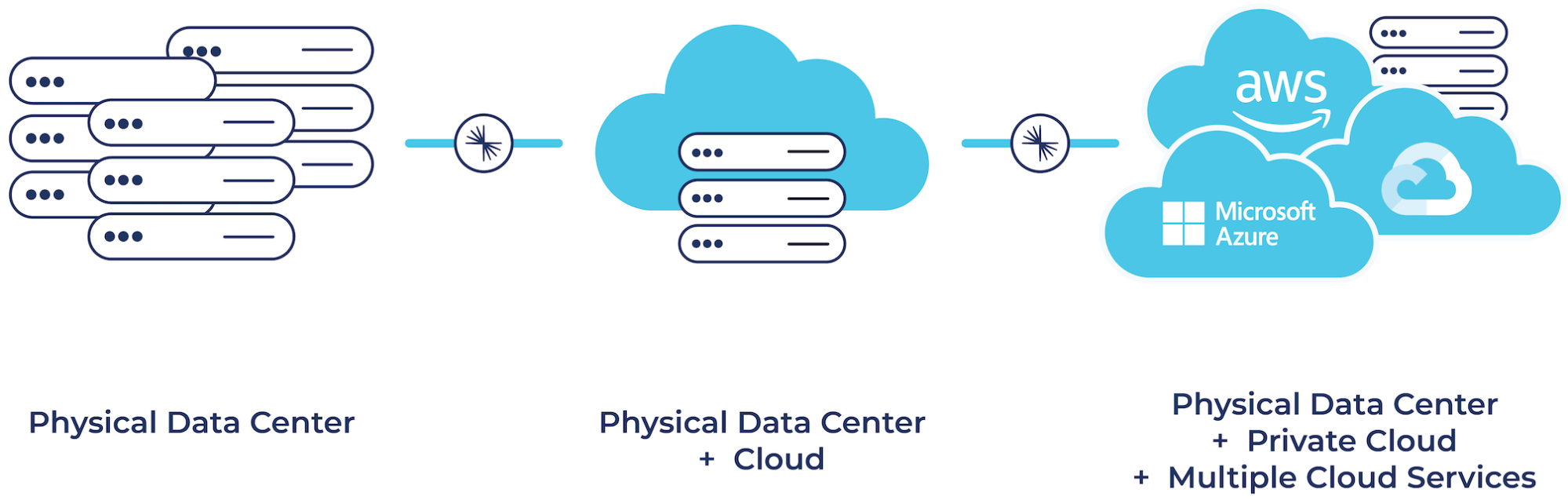
Modernize Your Hybrid and Multicloud Data Architecture
Whether you were born in the cloud, are just dipping your toes in the water with cloud, or are somewhere in between, chances are your organization is on a cloud journey at one stage or another. Maybe you ended up in the cloud as the result of strategic planning to take advantage of the simplicity, elasticity, and scalability that the cloud provides. Or perhaps mergers and acquisitions resulted in cloud environments that didn’t make sense to migrate. Different teams from inside your business might have simply adopted various cloud services for whatever projects they were working on, where you just organically ended up with a bunch of different cloud service providers. Regardless of how you got there, you’re most likely already operating in a hybrid and multicloud world.
But what about existing on-premises investments, many of which run mission-critical workloads? How can you leverage newer cloud services while ensuring that these on-prem environments are integrated with your cloud systems in order to ensure business continuity?
Ideally, your teams can build real-time applications using whatever cloud services they want without having to worry about where your data is or how they will access it. In practice, however, teams often find themselves hindered by legacy on-prem systems and complex architectures. Data silos, data gravity, and complex networks of connections between systems slow projects down, increase costs, and hinder innovation.
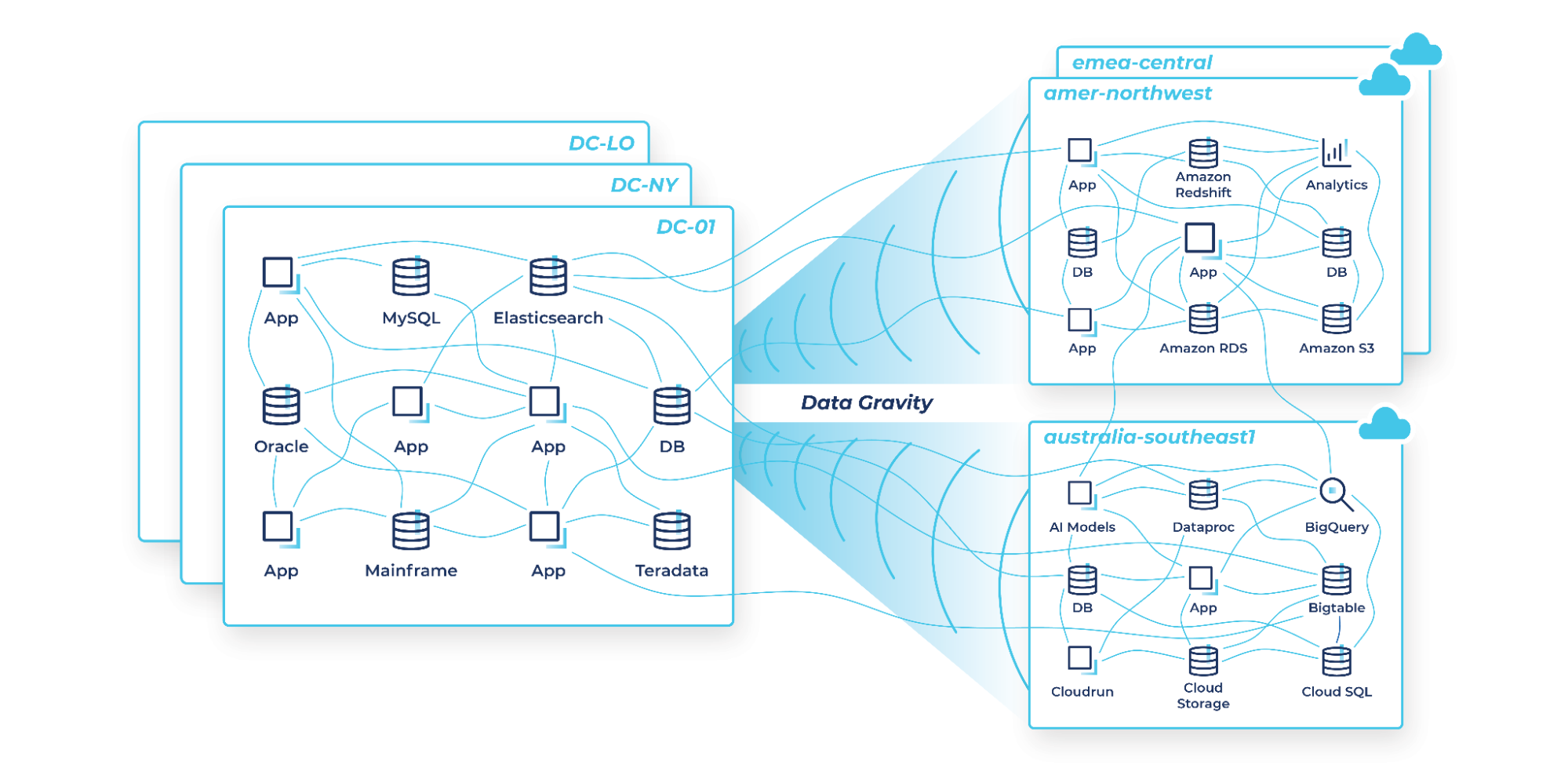
The drag effect of on-prem slows innovation
The problem with legacy data integration systems
Most enterprises are using the same batch ETL tools, messaging systems, APIs, and other homegrown systems they already have in place to power data movement across hybrid and multicloud architectures. While these approaches offer a quick fix, they often result in a spaghetti-like mess of point-to-point connections between systems and across environments that result in unforeseen consequences.
Periodic batch jobs result in different copies of data in different places at different times, which means stale information is being used to run your business. Expensive and valuable engineering resources are spent on data pipeline projects instead of building new capabilities. Each of these brittle point-to-point connections needs to be networked, secured, monitored, maintained, and can easily break as data volumes increase. And security and data governance challenges are exacerbated with each additional connection and as individual teams each implement their own tools and processes.
As you add new cloud services, these problems become exponentially worse because even more connections are established, complex new cloud networking and security issues emerge, and all sorts of additional compliance and data sovereignty laws must be addressed across different global regions. All of the architectural challenges enterprises were already facing get amplified with the addition of new cloud environments, and some new cloud-specific challenges arise.
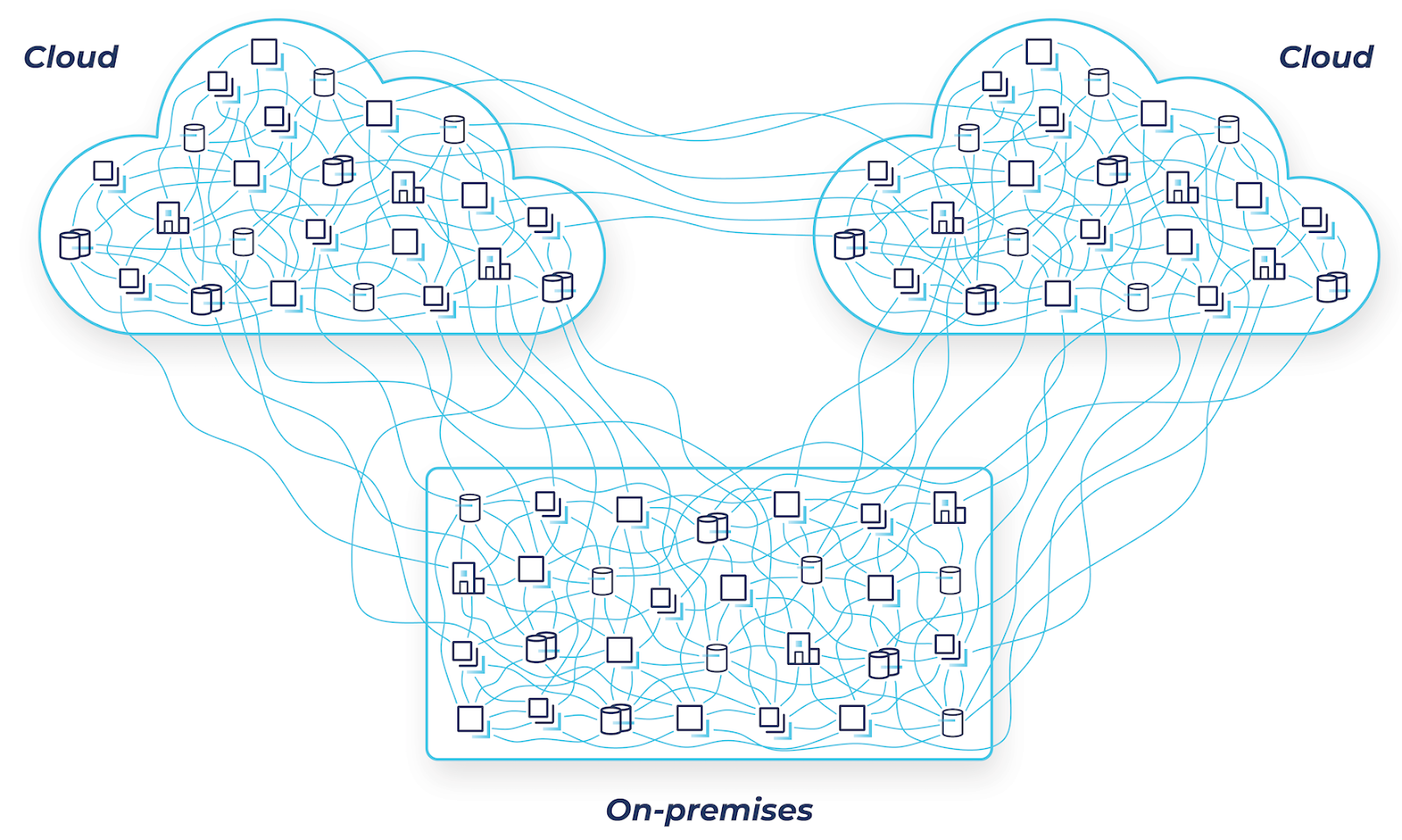
Confluent’s solution for hybrid and multicloud architectures
Back in November, we announced the general availability of Cluster Linking, a new capability that defines a communications link between two independent Confluent deployments and introduces a new way to securely “mirror” your data anywhere. This capability enables you to overcome the challenges that point-to-point connections create. By using Cluster Linking, you can unlock valuable data from the systems, applications, and data stores that run across any number of global environments and stream that data in real time wherever it needs to go, enabling a modern hybrid and multicloud architecture that is fast, cost-effective, resilient, and secure.
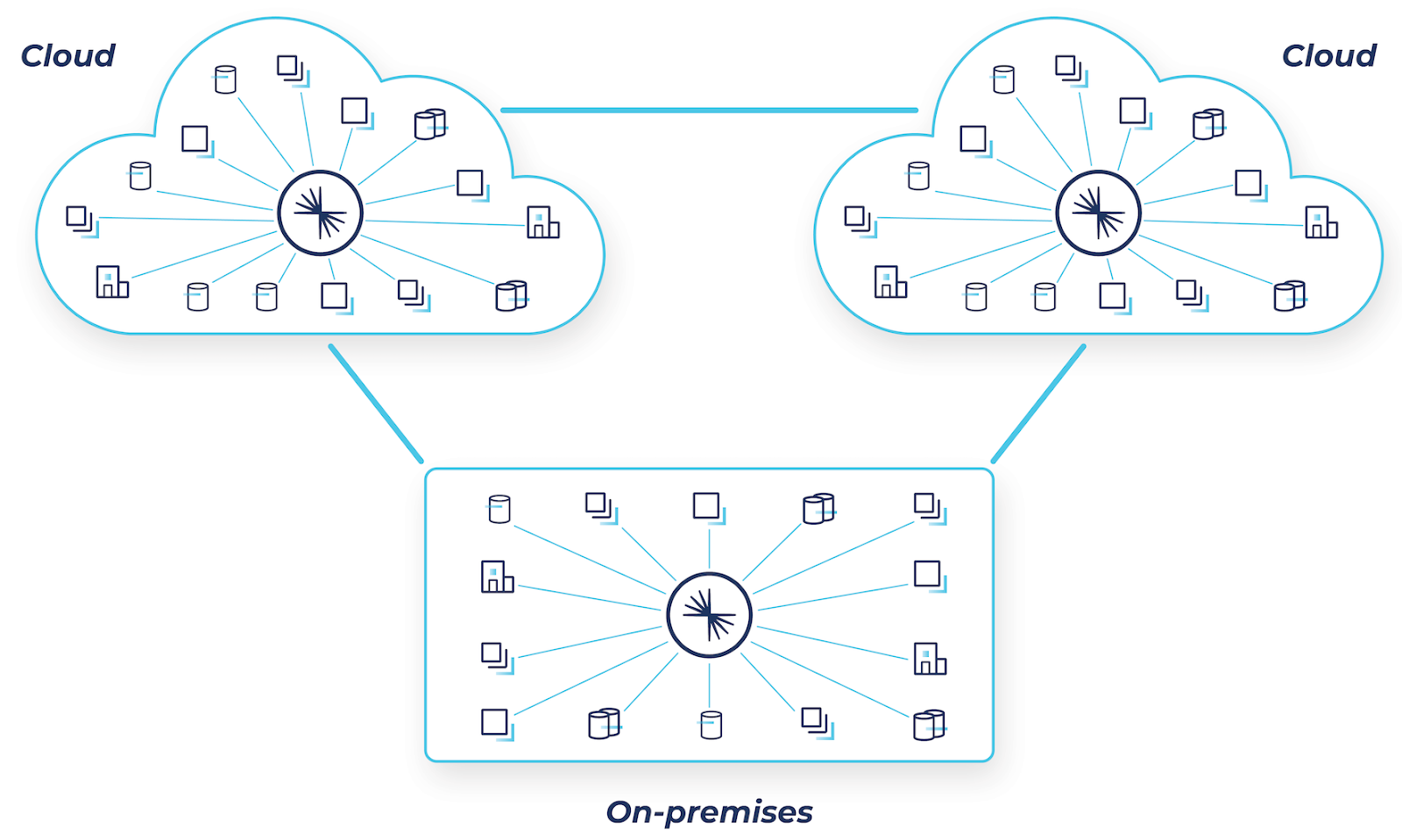
Confluent supports any combination of on-prem, single cloud, hybrid cloud, multicloud, or multi-region deployments. Our 120+ out-of-the-box connectors make it easy to integrate existing systems into Confluent, building on top of what you already have and mobilizing data for others to use.
Connecting your clusters together with Cluster Linking
Cluster Linking enables topic replication with exact offset preservation between clusters, regardless of where they are or who is hosting them. Cluster Linking enables a variety of hybrid cloud use cases such as migrations to cloud, data warehouse or database modernization, mainframe augmentation, disaster recovery, or simply connecting all of your business’s applications with the data they need to operate a real-time business.
Previous attempts to bring Kafka to hybrid and multicloud architectures, such as Confluent Replicator and MirrorMaker 2, relied on Kafka Connect. While these approaches copied messages from one cluster to another, they did not preserve the offsets of each event, and access control had to be handled separately. This made it difficult for consumer clients to seamlessly migrate between clusters, and required additional work for clients to translate the offsets and for administrators to duplicate the access control. With the “byte-for-byte” replication provided by Cluster Linking, the mirror topic’s offsets exactly match those on the source topic, giving you a precise one-to-one copy, and ACLs can be selectively mirrored.
With Cluster Linking, consumers on the destination cluster can read the mirrored read-only topics originally produced on the source cluster. Read-only topics can also be decoupled from the source. One common use case is moving a topic to a new cluster. This consists of replicating the topic, deleting the source, and marking the newly replicated destination topic as writable. Finally, you can restart the producer and point it at the new topic location.
To use Cluster Linking, the source cluster can be Apache Kafka 2.4 or later, Confluent Platform 5.4 or later, or Confluent Cloud. The target cluster must be Confluent Platform 7.0 or later, or a Dedicated cluster in Confluent Cloud.
Topic replication requires three steps. First, a link is defined between a source and a destination cluster. Second, a read-only mirror topic will be created on the destination cluster and associated with the cluster link. Lastly, mirror topics can be promoted to writable topics as required, such as during a failover.
Example: Source-initiated Cluster Linking for hybrid cloud architectures
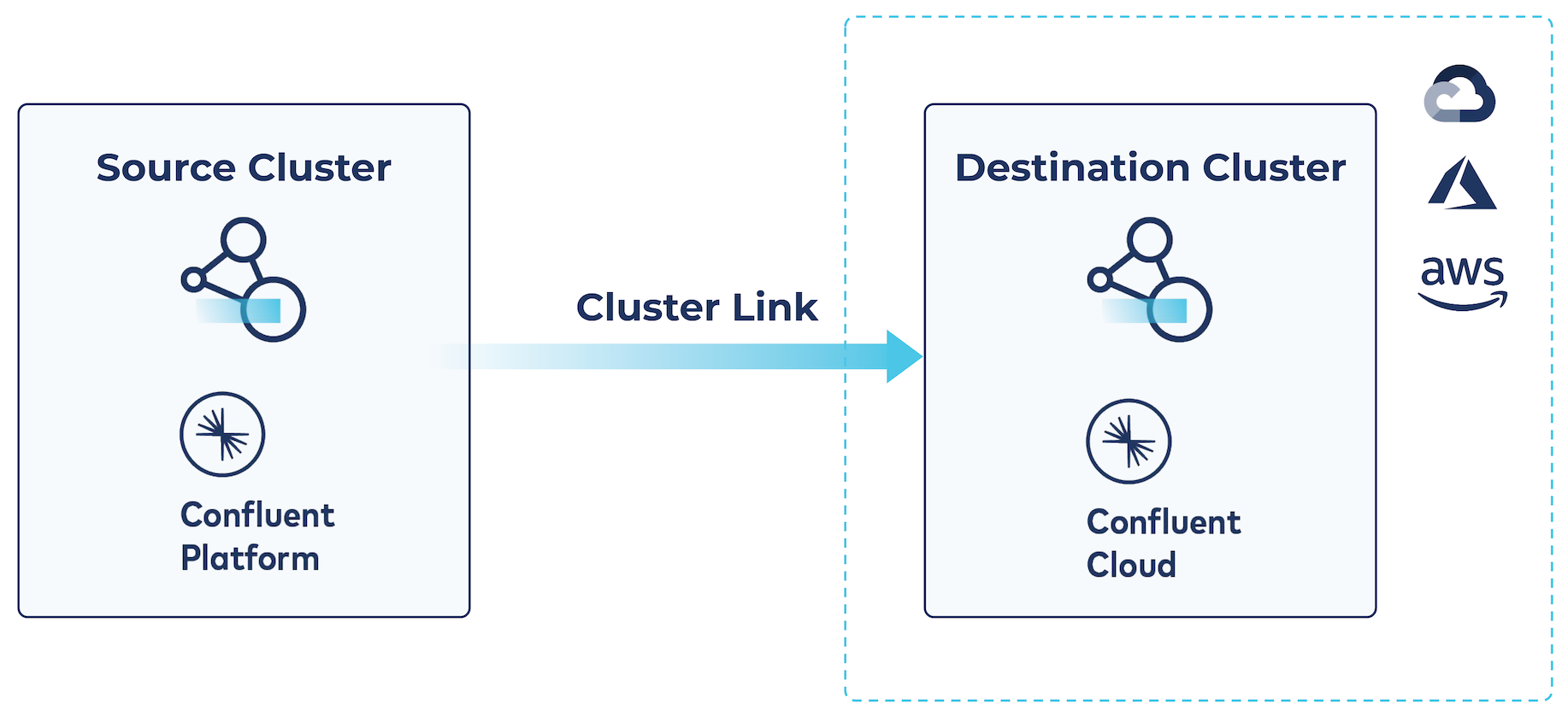
Prior to the introduction of Cluster Linking, the target for the cluster link always initiated the link. When your on-prem cluster was not visible from Confluent Cloud, Cluster Linking was not possible. Now, Confluent includes source initiated Cluster Linking, which allows a cluster link between Confluent Platform and Confluent Cloud without having to open up your firewall to Confluent Cloud.
Since Confluent Cloud allows you to scale from experimentation to production in the same environment, it’s important to be security conscious from the beginning. To that end, we use service accounts with specific ACLs and a dedicated API key to govern the cluster link. In the example below, the cluster link service account is granted the ability to read and write any topic in Confluent Cloud:
confluent service-account create CP-and-CC-Linking --description "Hybrid cloud cluster linking" confluent kafka acl create --allow --service-account $SERVICE_ACCOUNT_ID --operation read --operation write --topic '*' --cluster $CCLOUD_CLUSTER confluent api-key create --resource $CCLOUD_CLUSTER --service-account $ACCOUNT_ID
Where $ACCOUNT_ID is the id of the service account and $CCLOUD_CLUSTER is the Confluent Cloud cluster.
Confluent Platform uses a special config file side to indicate source initiated cluster linking. In this example, that’s $CONFLUENT_CONFIG/clusterlink-hybrid-dst.config and looks like this:
link.mode=DESTINATION connection.mode=INBOUND
Both Confluent Cloud and Confluent Platform need to be made aware of the link, so the link needs to be created on both and given the same name.
This command creates the cluster link on Confluent Cloud:
confluent kafka link create <link-name> --cluster \ <CC-cluster-id> --source-cluster-id \ <CP-cluster-id> --config-file $CONFLUENT_CONFIG/clusterlink-hybrid-dst.config \ --source-bootstrap-server 0.0.0.0
The bootstrap server of 0.0.0.0 tells Confluent Cloud that the cluster link is source initiated.
This command creates the link on Confluent Platform. The source initiated cluster link is specified with the path to the config file.
kafka-cluster-links --bootstrap-server localhost:9092 \ --create --link <link-name> \ --config-file $CONFLUENT_CONFIG/clusterlink-CP-src.config \ --cluster-id <CP-cluster-id>
A single command creates the mirrored topic:
confluent kafka mirror create topic --link <link-name>
Now data produced to the topic in Confluent Platform can be consumed in Confluent Cloud. And of course topics on Confluent Cloud can be mirrored in Confluent Platform as well.
Example: Cloud-to-cloud cluster linking for multicloud architectures
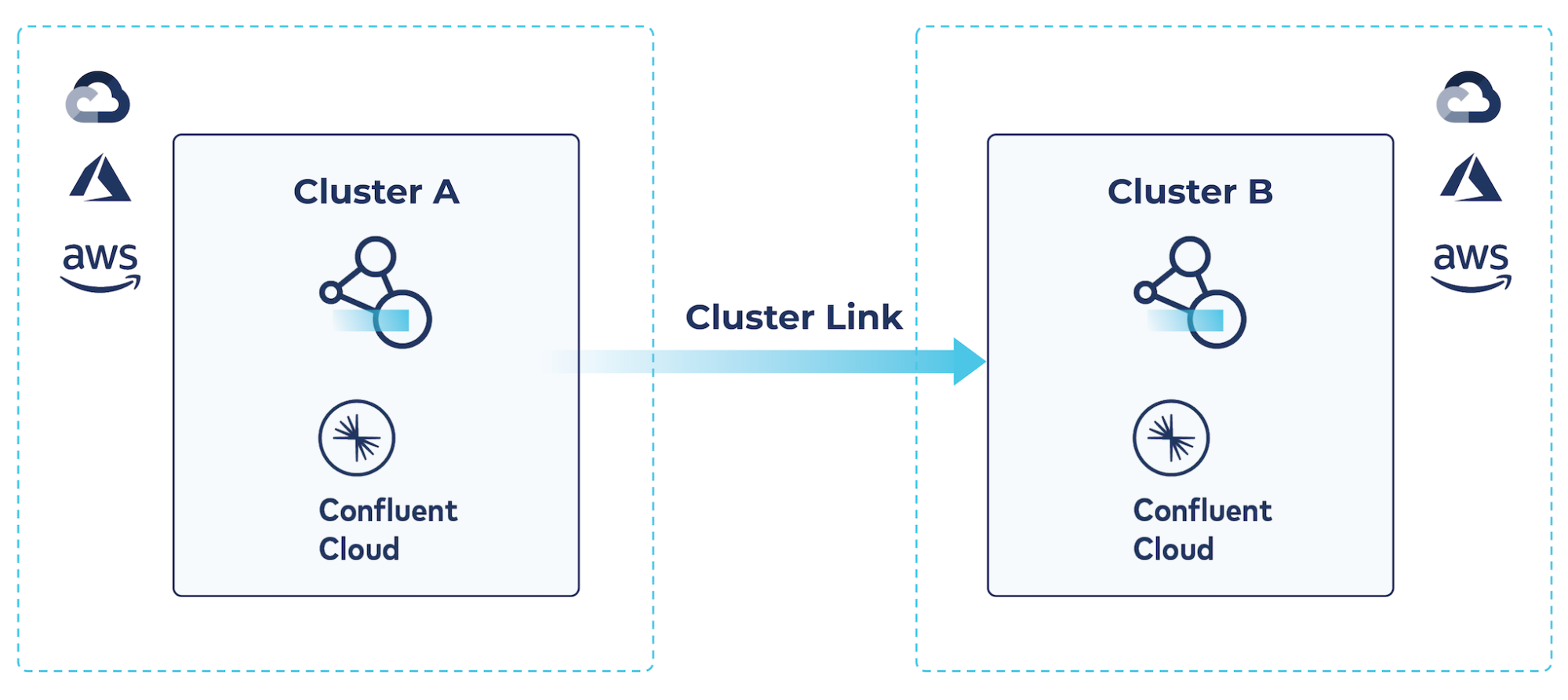
Confluent Cloud supports cluster linking between two clusters within Confluent Cloud, even running in different regions or different cloud service providers, as well as between a Confluent Platform cluster and one or more Confluent Cloud clusters.
When linking to Confluent Cloud in production settings, it’s important to configure access control correctly so as to protect the cluster link data. Confluent Cloud service accounts along with role-based access control can be used for this purpose.
Create a service account for the cluster link and for the CLI:
confluent iam service-account create cluster-link --description "Linked cluster service account" confluent iam service-account create cli --description "cli service account"
Create and store API keys for the cluster link service account:
confluent api-key create --resource $SOURCE_ID --service-account $CLI_SERVICE_ACCOUNT_ID confluent api-key create --resource $TARGET_ID --service-account $CLI_SERVICE_ACCOUNT_ID
Where $SOURCE_ID is the cluster you’re linking from and $LINK_SERVICE_ACCOUNT_ID is the service account just created.
Create and store the API keys for the CLI for both the source and target clusters:
confluent api-key create --resource $SOURCE_ID --service-account $CLI_SERVICE_ACCOUNT_ID confluent api-key create --resource $TARGET_ID --service-account $CLI_SERVICE_ACCOUNT_ID
In this example, the service account governing the cluster link is granted read, write, and describe privileges on all topics. We also grant separate privileges to the CLI service account, but these can be made more specific as required:
confluent kafka acl create --allow --service-account $LINK_SERVICE_ACCOUNT_ID --operation READ --operation DESCRIBE_CONFIGS --topic "*" --cluster $SOURCE_ID confluent kafka acl create --allow --service-account $LINK_SERVICE_ACCOUNT_ID --operation DESCRIBE --cluster-scope --cluster $SOURCE_ID confluent kafka acl create --allow --service-account $LINK_SERVICE_ACCOUNT_ID --operation DESCRIBE --topic "*" --cluster $SOURCE_ID confluent kafka acl create --allow --service-account $LINK_SERVICE_ACCOUNT_ID --operation READ --operation DESCRIBE --consumer-group "*" --cluster $SOURCE_ID confluent kafka acl create --service-account $CLI_SERVICE_ACCOUNT_ID --allow --operation READ --operation DESCRIBE --operation WRITE --topic "*" --cluster $SOURCE_ID confluent kafka acl create --service-account $CLI_SERVICE_ACCOUNT_ID --allow --operation DESCRIBE --operation READ --consumer-group "*" --cluster $SOURCE_ID
In the example link.config file below, cluster linking is enabled with consumer offset sync. We also sync the topics every 1000 milliseconds and enable SSL security. ACL sync is also enabled. This feature fully syncs the ACLs on the source cluster to the destination cluster, such that permissions remain exactly the same. This is important for ensuring that unauthorized access is not inadvertently granted. The example shows a liberal acl.filters but this can be refined. Substitute the secret and key with the api credentials for the service account on the source:
consumer.offset.sync.enable=true
consumer.offset.group.filters=\{"groupFilters": [\{"name": "*","patternType": "LITERAL","filterType": "INCLUDE"}]}
consumer.offset.sync.ms=1000 acl.sync.enable=true acl.sync.ms=1000
acl.filters=\{ "aclFilters": [ \{ "resourceFilter": \{ "resourceType": "any", "patternType": "any" }, "accessFilter": \{ "operation": "any", "permissionType": "any" } } ] }
topic.config.sync.ms=1000 security.protocol=SASL_SSL sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="secret" password="key";
To create the cluster link, using the source cluster ID for the target cluster as $TARGET_ID, the cluster ID for the source cluster as $SOURCE_ID, and the bootstrap server for the source as the $SOURCE_BOOTSTRAP, use this command:
confluent kafka link create cloud-link \ --cluster $TARGET_ID \ --source-cluster-id $SOURCE_ID \ --source-bootstrap-server $SOURCE_BOOTSTRAP \ --config-file link.config
Create the mirror topic and mirror it over the link:
ccloud kafka topic create mirror-topic --partitions 1 --cluster $SOURCE_ID ccloud kafka mirror create mirror-topic --link-name dr-link --cluster $SOURCE_ID
Now, when you produce data to the named topic, you’ll see the data mirrored on the target cluster. Confluent documentation includes more detailed information on promoting the mirrored topic or breaking down the cluster link.
For a demonstration of cloud-to-cloud cluster linking in action, see the video below:
Cluster linking for hybrid and multicloud architectures
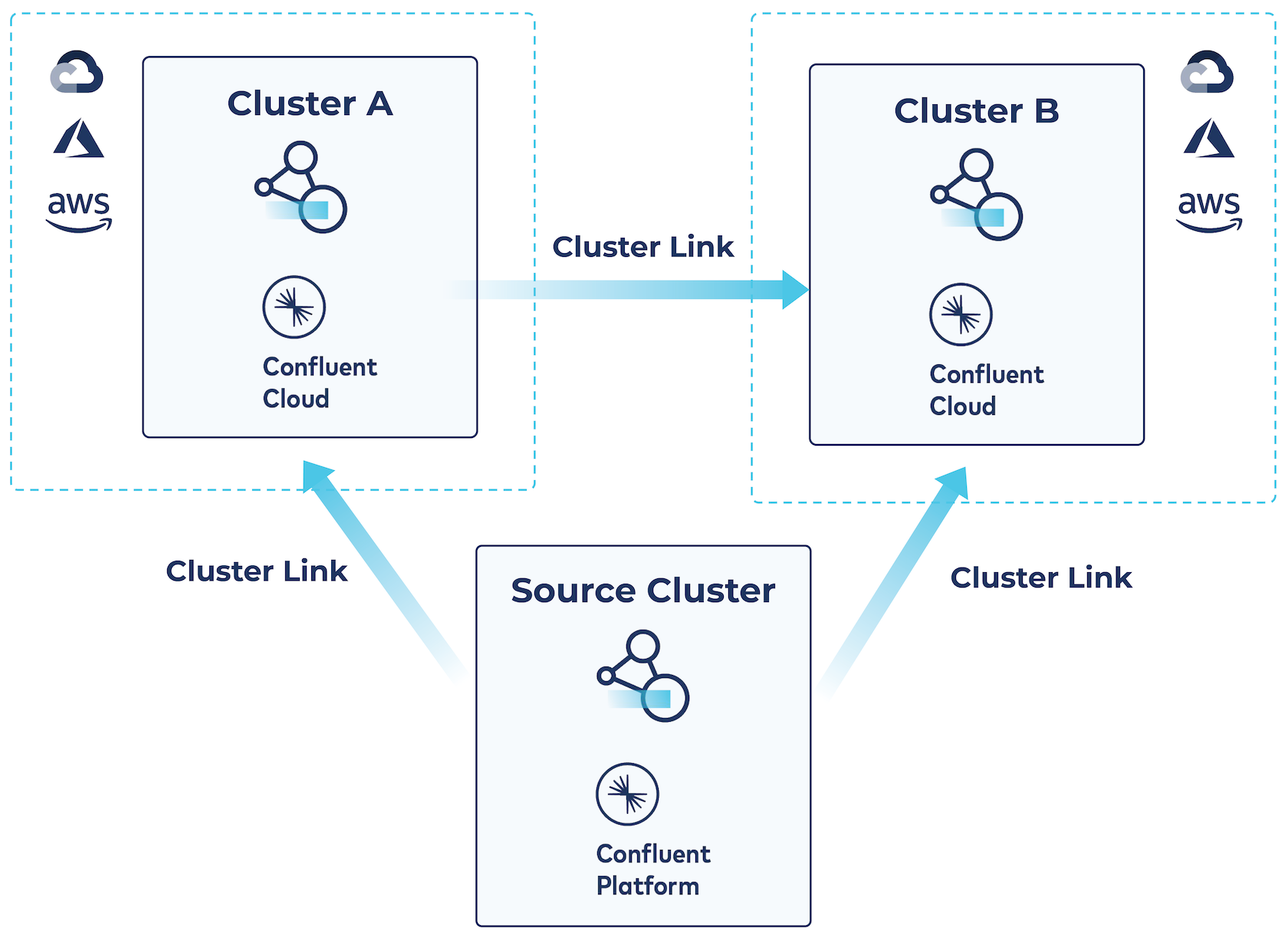
With Cluster Linking you can link to either cluster or both from Confluent Platform and the interface is the same. The same process for deploying a cluster link for platform-to-cloud discussed above can be followed to link Confluent Platform simultaneously to multiple Confluent Cloud Dedicated clusters, regardless of cloud provider or region.
For a demonstration of hybrid and multicloud cluster linking in action, check out the video below:
For a more detailed walkthrough of Cluster Linking, see our documentation, reference architecture, and associated walkthroughs in GitHub.
Benefits of Confluent’s approach
Some of the main benefits of Confluent’s solution for hybrid and multicloud architectures include:
- Speed: Give your teams real-time access to the data they need in the cloud services they want with a simple, globally connected data architecture. Build faster, more innovative customer-facing applications and more efficient backend operational systems.
- Cost Savings: Reduce hidden cloud costs and free up valuable engineering resources that are spent building, networking, securing, monitoring, and fixing data pipelines. Read Forrester’s Total Economic Impact report to learn exactly how much you can save by using Confluent.
- Resilience: Eliminate single points of failure with Confluent’s fault tolerant, horizontally scalable platform. Easily enable a disaster recovery strategy.
- Security: Enhance security with Confluent’s Stream Governance suite, and by standardizing on a single data platform that only has to address security challenges once.
What can you do next?
Many of our customers use Confluent to power hybrid and multicloud use cases—like KeyBank, who uses Confluent to migrate from their on-prem Teradata data marts to Google BigQuery or Bank BRI, the largest bank in Indonesia, who uses Confluent to deploy an event-driven microservices architecture that powers big data analytics for real-time credit scoring, fraud detection, and merchant assessment services. You can read more about how your industry peers are using Confluent for their hybrid and multicloud solution architecture in our success stories page, or even better, start a free trial of Confluent Cloud today! Use the code CL60BLOG to get an additional $60 of free usage when you sign up.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.