Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Event Processing – How It Works & Why It Matters
Event processing means capturing, analyzing, and acting on data in motion as events occur. It forms the foundation of real-time systems that power capabilities like fraud detection, IoT monitoring, and AI-driven decision-making.
With technologies like Apache Kafka® and Apache Flink®, organizations can process continuous streams of data instantly rather than in batches. That's why event processing is critical for responding to transactions, new insights, system activities, and customer behavior the moment they happen, turning raw data into immediate action.
TL;DR: Event processing captures and analyzes data the instant it’s created—powering fraud detection, IoT automation, and real-time AI. Learn how it works, key architecture patterns, and how Confluent Cloud enables event-driven applications at scale.
What Is Event Processing and How Does It Work?
Event processing is the method of capturing, analyzing, and responding to data events as they happen. Each event represents a specific change or action, such as a financial transaction, sensor reading, or user interaction. The goal is to interpret these events in real time and trigger meaningful actions based on their real-world context.
A common question people have: “Is event processing the same as event streaming?” While they are closely related, they serve different purposes. Event streaming focuses on the continuous movement of events from sources to destinations in real time, often using platforms like Kafka. Event processing, on the other hand, focuses on interpreting those streams, filtering, correlating, and analyzing events to uncover insights or trigger automated actions—all things that are key for powering real-time analytics and AI.
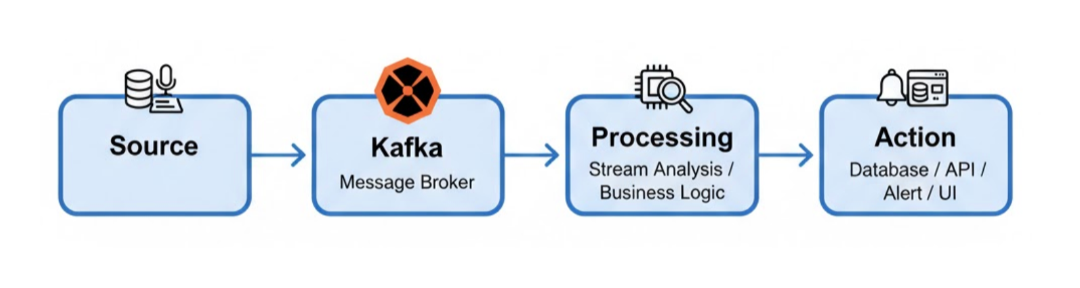
A typical event processing flow might look like this: Source → Kafka → Processing → Action, where Kafka manages the reliable movement of events, and processing engines analyze the data before initiating the next step.
Why Event Processing Matters
As organizations increasingly move toward real-time, data-driven decision-making, event processing has become a foundational capability. It sits at the core of modern data architectures that demand instant responses—whether in finance, e-commerce, IoT, or customer engagement platforms. By continuously interpreting and acting on streams of incoming events, businesses can move from reactive to proactive operations.
What’s the Benefit of Processing Events in Real Time?
Real-time processing allows businesses to detect and prevent fraud the moment a suspicious transaction occurs, personalize user experiences as customers interact with digital platforms, and optimize operations across IoT systems instantly. This immediate responsiveness helps organizations stay competitive and meet growing expectations for instant, intelligent services.
A simple way to visualize this is through a timeline comparison of batch versus real-time processing. In batch systems, insights arrive minutes or hours after the event. In event processing systems, insights are delivered and acted upon the instant data is generated.
Why Do Companies Use Event Processing?
The primary reason is speed. In today’s digital world, reacting to data in milliseconds can directly translate to increased revenue, improved customer experiences, and reduced risk. Event processing enables organizations to act on insights as they happen rather than waiting for batch updates or daily reports.
What’s the Difference Between Simple vs. Complex Event Processing?
Event processing generally falls into two main categories, simple vs. complex event processing, and each designed for different kinds of real-time data challenges.
-
Simple event processing deals with individual events that trigger a single action. For example, a temperature sensor exceeding a threshold can immediately trigger an IoT alert. This type of processing is straightforward and ideal for use cases that require direct, immediate responses.
-
Complex event processing (CEP) involves analyzing patterns across multiple events to detect trends or anomalies. It is commonly used in applications such as fraud detection, network monitoring, and anomaly detection, where insights emerge only after correlating events over time or across multiple sources.
A Summary of the Differences – Simple vs. Complex Event Processing
|
Feature |
Simple Event Processing |
Complex Event Processing |
|
Definition |
One event triggers one action |
Multiple events analyzed to detect patterns or correlations |
|
Example Use Case |
IoT alert when temperature exceeds threshold |
Fraud detection across multiple transactions |
|
Data Scope |
Single event at a time |
Aggregated events over time or from multiple sources |
|
Decision Making |
Immediate and direct |
Pattern-based or rule-based, may involve correlation and aggregation |
|
Complexity |
Low |
High |
|
Latency |
Very low |
Low to moderate, depending on event aggregation |
Do You Need Complex Event Processing for Most Use Cases?
Not always. The choice depends on the complexity of the problem you’re solving and how much context is needed to act on incoming data.
How Does an Event Processing Architecture Work With Apache Kafka®?
Event processing relies on an event-driven architecture, where events flow continuously from sources to destinations through a scalable processing pipeline. A typical architecture includes:
-
Producers: Systems or applications that generate events, such as sensors, user interactions, or transactional systems.
-
Kafka: Acts as the central event streaming platform, reliably transporting events from producers to processors.
-
Processors: Applications or engines that consume events from Kafka, perform transformations, aggregations, or complex analyses.
-
Outputs/Consumers: Systems that receive processed insights or trigger actions, such as alerting systems, dashboards, or downstream applications.
This architecture provides scalability, allowing organizations like Optimove and Arcese to handle millions of events per second, and governance, ensuring data consistency, security, and traceability across the pipeline.
Producers → Kafka → Processors → Outputs/Consumers
Kafka sits at the core, enabling reliable, high-throughput event transport, while processors handle real-time analytics and outputs act on insights instantly.
How Does Confluent Simplify Event Processing?
Confluent Cloud, powered by a cloud-native Kafka engine, provides a fully managed platform that empowers organizations to ingest, process, and act on events in real time—all without the operational burden of managing Kafka clusters. This makes it easier to build scalable, event-driven applications that respond instantly to business-critical data.
Governance and Monitoring
Reliable event processing requires strong governance. Confluent Cloud’s Schema Registry enforces consistent data formats across producers and consumers, reducing errors and ensuring data quality. Combined with Confluent’s built-in monitoring and observability tools, teams can track event flows, detect anomalies, and maintain high reliability across the entire event-driven architecture.
Stream-to-Table Pipelines With Tableflow
Tableflow enhances event processing by enabling stream-to-table pipelines. It allows streaming data to be transformed and materialized into structured tables, making it easy to query, analyze, or integrate with downstream systems. With Tableflow, organizations can bridge the gap between real-time streams and analytics-ready datasets seamlessly.
This setup—cloud-native Kafka, Tableflow, and governance with Schema Registry—provides a complete ecosystem for building, managing, and scaling robust event-processing pipelines.
Top Use Cases for Event Processing
Event processing powers real-time decision-making across industries, enabling organizations to act instantly on streaming data. Its applications vary by sector, reflecting the unique needs of each domain.
In the banking sector, for example, event processing is critical for fraud detection, monitoring transactions in real time to identify suspicious activity, and for payments processing, ensuring transactions are validated and completed instantly.
Examples of Event-Driven Use Cases by Industry
|
Industry |
Use Case |
|
Retail |
Personalization of offers and recommendations, inventory management, and dynamic pricing based on live demand |
|
IoT |
Monitoring connected devices, triggering automated responses, predictive maintenance for sensors and machinery |
|
AI/ML |
Real-time model inference to provide instant predictions, anomaly detection, or adaptive decision-making |
Ready to get started with event processing?
-
Find your next use case in our library of reference architectures.
-
Take on-demand courses from Confluent Developer like Designing Events and Event Streams
-
Sign up for Confluent Cloud for a $400 credit to use in your first 30 days.
Frequently Asked Questions (FAQs)
What is the difference between event processing and stream processing?
Event processing focuses on analyzing and acting on events as they occur, turning raw data into immediate insights or actions. Stream processing refers to the continuous movement of data from producers to consumers, often serving as the transport layer for event processing.
What’s the role of Kafka in event processing?
Kafka acts as the central event streaming engine, reliably moving events from producers to processors and consumers. It ensures high throughput, durability, and scalability, forming the backbone of real-time event-driven architectures.
How does event processing relate to microservices?
Event processing enables microservices architectures to communicate asynchronously by producing and consuming events. This decouples services, improves scalability, and allows independent services to react to real-time data without direct dependencies.
Do I need complex event processing for most use cases?
Not always. Simple event processing is sufficient when individual events trigger immediate actions, such as for IoT alerts. Complex event processing is needed when insights emerge from patterns or correlations across multiple events, such as fraud detection or anomaly detection in large datasets.