Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
COMPARATIVA
Confluent Cloud vs. Amazon MSK en Apache Kafka®: una comparativa de costes y funcionalidades
Sacarle todo el partido a Apache Kafka® requiere recursos de ingeniería dedicados y una experiencia significativa en sistemas distribuidos. A medida que aumenta la huella de Kafka en tu empresa, gestionarlo de forma interna puede llevar a volverse insostenible, ya que te obliga a elegir entre pagar por clusters sobreaprovisionados o arriesgarte a sufrir interrupciones imprevistas.
Esta comparativa detallada de Confluent Cloud y Amazon MSK te mostrará la escalabilidad, resiliencia y funcionalidades de cada plataforma y cómo Confluent reduce el coste total de propiedad (TCO) de Kafka self-managed entre un 40 % y un 70 %.
Gana un 70 % de eficiencia en comparación con Apache Kafka® self-managed y alojado
Tanto si estás creando pipelines de datos en tiempo real como si vas a desarrollar tus propios agentes de IA, Kafka es la solución ideal. Su diseño distribuido está pensado para operar con cargas de trabajo de alto rendimiento y baja latencia, pero también requiere una gran experiencia para gestionar, asegurar y optimizar tus datos a gran escala sin los costes que conlleva el sobreaprovisionamiento ni el riesgo de posibles interrupciones en el servicio.
Confluent, la solución que diseñaron los creadores originales de Kafka, invirtió 3 millones de horas de ingeniería en redefinir la arquitectura de Kafka para operar con hasta un 70 % más de eficiencia en la nube. El resultado fue Kora: el motor cloud-native de Kafka que hace funcionar nuestra plataforma de streaming de datos totalmente gestionada. Estas son algunas de sus principales características:
-
Clusters serverless y con escalado automático que te permiten ahorrar más de la mitad de tus costes de infraestructura
-
El triple de eficiencia en los recursos que un cluster autogestionado de un solo inquilino
-
Un ~50 % menos de latencia en los clusters que las opciones self-managed para aumentar el uso
-
Enrutamiento optimizado e integraciones de API que reducen los costes de red
En la actualidad, Kora impulsa 30.000 clusters de Confluent Cloud que procesan más de 3 billones de mensajes al día en AWS, Google Cloud y Microsoft Azure.
Reserva tu plaza en este webinar sobre los costes de Kafka
Migración de MSK Zookeeper: convierte una actualización crítica en una ventaja estratégica
El soporte de Kafka para ZooKeeper finaliza en mayo de 2026, por lo que todos los usuarios de Kafka que se utilizan clusters basados en Zookeeper deberán enfrentarse a una migración de importancia crítica y a gran escala a KRaft para evitar que se ejecuten procesos en versiones obsoletas de Kafka.
¿Qué significa esto para los clientes de MSK?
-
Los clústeres basados en Zookeeper ya no recibirán actualizaciones críticas de la comunidad de código abierto: es decir, ya no podrán usar parches de seguridad y correcciones de errores de la comunidad. Esto significa que los clientes de MSK deberán utilizar una versión self-managed de Kafka con posibles problemas de seguridad y gestión.
-
MSK no ofrece ninguna ruta de actualización in situ: los clientes de MSK deben crear un nuevo cluster compatible con KRaft y migrar los datos y las cargas de trabajo manualmente.
-
La migración de MSK Express no es perfecta: pasar de MSK Provisioned Standard a MSK Express también requiere recursos adicionales.
¿Por qué migrar a Confluent?
Tener que realizar una migración imprescindible también presenta un momento ideal para revisar el statu quo. ¿Realmente hay que dedicar recursos adicionales para poder seguir usando un servicio básico? Quizá sea mejor idea migrar a una plataforma de streaming de datos totalmente gestionada, que te dé acceso a funciones avanzadas y te permita ahorrar costes.
-
Totalmente gestionado y cloud-native: automatiza todo el ciclo de vida de Kafka (desde el aprovisionamiento y las actualizaciones hasta el escalado y equilibrio de particiones) para que los usuarios puedan dedicarse a trabajar en sus aplicaciones, en lugar de en las operaciones.
-
Asistencia de primer nivel: Confluent ofrece la asistencia directa de expertos en Kafka y un SLA del 99,99 % que cubre toda la plataforma de streaming (un SLA 10 veces mejor que MSK).
-
Integraciones y ecosistema enriquecidos: accede a la mayor biblioteca de conectores gestionados, que incluye más integraciones de servicios de AWS, además de compatibilidad con soluciones multi-cloud y SaaS.
-
Gobernanza de datos: Confluent ofrece un conjunto completo de funciones de gobernanza —como Schema Registry, que garantiza la calidad y la coherencia de los datos— y una fuente central de información fiable para todos tus streams de datos.
-
Ubicua: admite despliegues multi-cloud en AWS, Azure y Google Cloud, así como arquitecturas híbridas que abarcan entornos en la nube y on-prem.
-
Ahorro en el coste total de propiedad (TCO): cuando migras a Confluent Cloud y aprovechas funciones como la interfaz de red privada (PNI) y el escalado automático, Confluent garantiza igualar (o mejorar) el precio de AWS MSK.
«Con Confluent, hemos reducido nuestra previsión anual de costes en un 69 % y hemos ahorrado meses de planificación que tendríamos que dedicar a reuniones y proyecciones de temporadas».
Justin Dempsey, Senior Manager de SAS Cloud
«Desde que creamos Horus —nuestra plataforma mundial de escaneo de IPV4— sobre Confluent, hemos ahorrado más de un millón de dólares en comparación con Kafka o MSK de código abierto».
Jared Smith, Senior Director, Threat Intelligence en SecurityScorecard
«Con Confluent, obtenemos una elasticidad total, que es fundamental para escalar durante los picos en la demanda del comercio minorista, como el Black Friday, o al cerrar acuerdos con nuevos clientes grandes; ademas, todo queda respaldado por un SLA superior».
Alan Compton, Technology Director en RevLifter
El coste de propiedad de Kafka: MSK vs. Confluent
A medida que aumente la adopción interna y se expanda la huella de Kafka en tu empresa, tu equipo tendrá que dedicar más tiempo y recursos a un amplio abanico de tareas:
-
Planificación, dimensionamiento y gestión del aprovisionamiento de clusters
-
Parches y actualizaciones de software
-
Diseño y planificación de la conmutación por error para garantizar la disponibilidad
-
Mitigar riesgos de gobernanza y seguridad
-
Planificación y optimización para mantener la fiabilidad
-
Equilibrio de las cargas manuales
Sacarle todo el partido a Kafka conlleva importantes costes, tanto económicos como de oportunidad: una media de más de 2 años para alcanzar la producción a gran escala y entre 3 y 5 millones de dólares en costes de desarrollo y operaciones de la plataforma. Confluent Cloud y Amazon MSK prometen aliviar esta carga operativa, pero no todos los servicios «gestionados» de Kafka ofrecen las mismas prestaciones: elegir la opción que aloja Kafka con tu proveedor de servicios en la nube puede hacer que tu equipo tenga que encargarse de todas las tareas recurrentes y pesadas.
En esta comparativa entre servicios gestionados de Kafka, descubrirás todo lo que puedes conseguir (y ahorrar) con una solución de Kafka realmente gestionada, serverless y con una plataforma de streaming de datos que ofrece un ROI del 257 % y se amortiza en menos de 6 meses.
| Confluent Cloud | Amazon MSK | |
|---|---|---|
| Resumen | Confluent te permite delegar la mayor parte de las tareas manuales gracias a sus funciones automatizadas para escalar clusters de Kafka e instancias de conectores. | Con Amazon MSK, la carga operativa sigue siendo elevada, ya que solo ofrece funciones limitadas de automatización para tareas de despliegue, incluso en los Serverless Clusters de MSK. |
| Funciones de automatización vs. operaciones manuales y desarrollo personalizado |
Gestión interna:
Automatizado en todos los clusters:
Personalizado:
*En todos los clusters de Confluent Cloud |
Gestión interna:
Personalizado:
Automatizado:
*Solo en clusters serverless de MSK |
| Libertad de elección | Disponible en AWS, Google Cloud y Microsoft Azure | Disponible solo en AWS |
Gestión, supervisión y mantenimiento en Confluent Cloud vs. Amazon MSK
Aunque MSK da respuesta a algunas brechas operativas, sigue teniendo muchas limitaciones La gestión interna o el uso de Kafka alojado conlleva unos costes significativos, tanto directos como indirectos:
- Gasto elevado en infraestructura por clusters sobreaprovisionados: el sobredimensionamiento que se necesita para dar respuesta a los picos en la demanda, las limitaciones a la hora de escalar el almacenamiento sin aumentar la capacidad de computación y las caídas de rendimiento derivadas de configuraciones manuales, los ajustes al equilibrio y las actualizaciones elevan considerablemente los costes.
-
Costes operativos y recursos limitados: el tiempo y los recursos dedicados al aprovisionamiento, la planificación de la capacidad, las actualizaciones y la monitorización conllevan un coste elevado e impiden dedicar recursos a la diferenciación del negocio. A ello se suman los costes de encontrar, contratar y retener talento especializado en Kafka.
-
Interrupciones imprevistas: el riesgo de caídas y brechas de seguridad aumenta a medida que Kafka se extiende a más casos de uso, aplicaciones, sistemas de datos, equipos y entornos.
Estos costes se acumulan, lo que retrasa la amortización de la inversión, aumenta el coste total de propiedad (TCO) y eleva el riesgo de pérdida de ingresos por caídas imprevistas, brechas de seguridad y pérdidas de datos.
Veamos cómo se comparan Confluent Cloud y Amazon MSK a la hora de reducir la carga operativa y resolver los desafíos más comunes de Kafka.
Descarga el whitepaper: Kafka vs. Confluent vs. MSK
| Servicio | Confluent Cloud | Amazon MSK | MSK Serverless |
|---|---|---|---|
| Aprovisionamiento | Autoservicio, bajo demanda para Kafka, Schema Registry y Flink | Autoservicio, bajo demanda solo para Kafka | Autoservicio, bajo demanda solo para Kafka |
| Escalado automático | Clusters serverless, con escalado automático y dimensionados para cualquier carga de trabajo | Escalado manual | Escalado elástico con una cuota limitada (200/400 MBps) |
| Tipos de cluster | Tipos de clusters flexibles y rentables para cualquier carga de trabajo y caso de uso | Clusters estándar y exprés, que requieren escalado manual | Los clusters serverless de MSK son clusters preaprovisionados de MSK, adecuados para cargas de trabajo impredecibles y de mayor importancia para el negocio |
| Infraestructura como código | Tanto para el plano de control como para el plano de datos | Solo para el plano de control | Solo para el plano de control |
| Supervisión de infraestructuras | Supervisión proactiva | Supervisión manual | Supervisión proactiva |
| Supervisión de topics | Métricas gratuitas y preagregadas | Las métricas a nivel de topic tienen un coste adicional | La supervisión predeterminada es gratuita |
| Actualizaciones | Siempre la última versión estable | Compatibilidad limitada con versiones | Compatibilidad limitada con versiones |
| Parches de software | Correcciones proactivas | Correcciones reactivas | Correcciones reactivas |
| Ampliaciones de cluster | Escalabilidad elástica | Reequilibrio manual de datos | Escalabilidad elástica |
| Escalado de conectores | Prediseñado y totalmente gestionado | Desarrollado y gestionado por tu cuenta | Desarrollado y gestionado por tu cuenta |
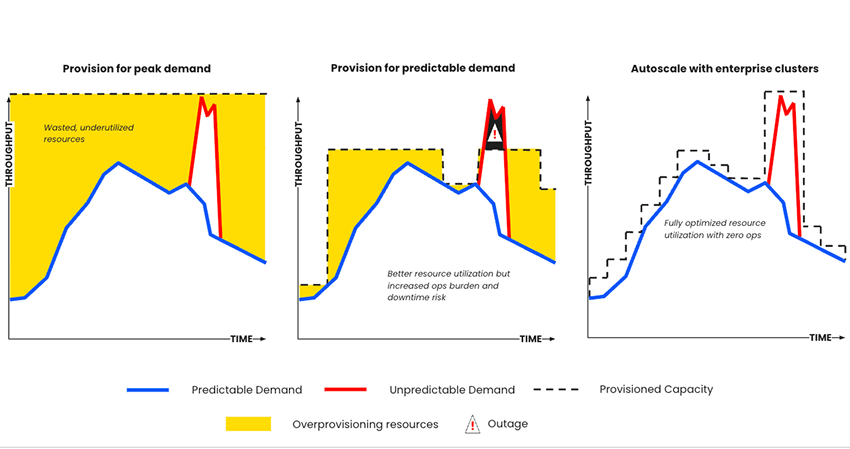
¿Cómo simplifican Confluent Cloud y Amazon MSK el dimensionamiento de los clústeres?
-
Confluent Cloud utiliza un dimensionamiento basado en el rendimiento (throughput): elimina la necesidad de pruebas de rendimiento complejas y reduce los costes de infraestructura mediante clusters elásticamente escalables (incluso hasta cero), en los que solo se paga por el uso real.
-
MSK Provisioned utiliza un dimensionamiento basado en brokers: es necesario asignar tiempo y recursos para ejecutar pruebas de rendimiento, seleccionar tipos y número de brokers y sobreaprovisionar la infraestructura para evitar futuras expansiones complejas debido a las limitaciones de autoescalado (máximo de cuatro operaciones al día).
-
MSK Serverless utiliza un dimensionamiento basado en el rendimiento (throughput): permite aprovisionar clusters de Kafka junto con Glue Schema Registry y Flink, pero requiere personalización manual para conectores y proxy de Kafka.
¿Cómo automatizan Confluent Cloud o Amazon MSK el aprovisionamiento y la gestión?
-
Confluent Cloud ofrece aprovisionamiento bajo demanda y de autoservicio para toda la plataforma: aprovisiona clusters de Kafka junto con cualquier otro componente de Confluent Cloud, entre los que se incluyen Schema Registry, Connect y Confluent Cloud para Apache Flink®. También puedes utilizar el proveedor Terraform para automatizar la gestión de los recursos del plano de control (como clusters y Schema Registry) y de los recursos del plano de datos, como topics y ACL.
-
Amazon MSK ofrece aprovisionamiento de autoservicio bajo demanda, pero solo para Kafka: aprovisiona clusters de Kafka junto con Glue Schema Registry y Flink. Requiere personalización manual para conectores y el proxy de Kafka, tanto para MSK Provision como para MSK Serverless. Terraform solo puede implementar y gestionar los recursos del plano de control y necesitas crear operadores y procesos personalizados para gestionar los recursos del plano de datos.
¿Confluent Cloud o Amazon MSK ofrecen funciones integradas de monitorización?
-
Confluent Cloud ofrece una supervisión proactiva de la infraestructura, ademas de métricas agregadas y gratuitas para supervisar los topics: Dedica tus recursos al desarrollo de aplicaciones y deja la supervisión y el mantenimiento de clusters en manos de expertos en Kafka. Infinite Storage hace realidad un sinfín de casos de uso del almacenamiento a nivel de cluster, al tiempo que reduce el riesgo de errores relacionados con el espacio en disco. El acceso a las métricas preagregadas (a nivel de topic y de cluster) está disponible sin coste adicional; también puedes consumir métricas desde tu solución de supervisión de terceros preferida gracias a la API Metrics.
-
MSK Provisioned ofrece una supervisión manual de la infraestructura y métricas a nivel de topic con un coste adicional: Asigna recursos para supervisar las métricas de los brokers, como el uso de la CPU, para gestionar de forma proactiva el rendimiento del cluster. Supervisa y crea alertas de espacio en el disco para evitar fallos debido a la capacidad de almacenamiento. Paga por el consumo y agrega manualmente métricas a nivel de broker y de topic para controlar el uso general.
-
Los clusters serverless de MSK ofrecen una supervisión proactiva de la infraestructura y permiten monitorizar los topics de forma gratuita por defecto: Céntrate en el desarrollo de tus aplicaciones gracias a la monitorización y el mantenimiento proactivos del clusters. Infinite Storage hace realidad un sinfín de casos de uso del almacenamiento a nivel de cluster, al tiempo que reduce el riesgo de errores relacionados con el espacio en disco. Además, podrás acceder a métricas a nivel de topic de forma gratuita mediante la consola CloudWatch, una herramienta independiente para supervisar varios productos de AWS. No incluye métricas a nivel de cada partición ni integraciones nativas con las herramientas de supervisión más utilizadas, como Datadog y Dynatrace.
Diferencias en la gestión del mantenimiento de Kafka en Confluent Cloud y en Amazon MSK
-
Confluent Cloud siempre se actualiza a la última versión estable y los errores y vulnerabilidades se corrigen de forma proactiva. Ofrece un SLA del 99,99 % que incluye Kafka, correcciones de errores, parches y mucho más.
-
Amazon MSK tiene una compatibilidad de versiones y correcciones reactivas limitadas: MSK solo admite un subconjunto de versiones de Kafka y debes activar las actualizaciones manualmente una vez que AWS añada compatibilidad para ellas tras el lanzamiento programado de Apache. MSK ofrece un SLA del 99,9 % y elige ofrecer solo versiones seleccionadas de Kafka; además, los fallos provocados por el software de Kafka no están cubiertas por el uptime SLA de MSK. Trabajar únicamente con un subconjunto de versiones obliga a adoptar una estrategia reactiva para corregir vulnerabilidades. Los clusters serverless de MSK no tienen ninguna intervención como parte de las actualizaciones continuas no disruptivas: MSK solo admite un subconjunto de versiones de Kafka y la última versión es desconocida y está totalmente abstraída.
¿Cómo expanden y reducen Confluent Cloud y Amazon MSK los clusters?
-
Confluent Cloud escala automáticamente y asigna recursos a tu cluster: Confluent gestiona la latencia de los consumers a medida que el rendimiento aumenta o disminuye (hasta escalas de GBps) con clusters totalmente elásticos y con escalado automático que reducen los costes de infraestructura a más de la mitad. Elimina el sobreaprovisionamiento de recursos de computación para los clusters y establece tus propios límites de retención con Infinite Storage.
-
Amazon MSK requiere un reequilibrio manual de datos para los clusters aprovisionados, así como conectores self-managed desarrollados a medida: se requiere un proceso de reequilibrio manual de datos con Cruise Control después de añadir los brokers a cualquier cluster. Ofrece almacenamiento por niveles, pero sigue necesitando volúmenes de EBS que se pueden escalar hasta 16 TB por broker con un límite de 30 brokers. Aprovecha conectores creados internamente o por la comunidad que no disponen de asistencia técnica ofrecida por AWS (solo incluye soporte para la infraestructura subyacente de MSK Connect).
-
Los clusters serverless de MSK tienen escalado elástico a cuotas limitadas y siguen requiriendo conectores self-managed desarrollados a medida: permite escalar fácilmente de 0 a 200 MBps con el reequilibrio automático del cluster, que elimina el sobreaprovisionamiento de computación para el cluster al aumentar la retención de topics con Infinite Storage.
La plataforma de streaming de datos completa de Confluent vs. Kafka alojado en AWS
¿Por qué empresas de todos los sectores confían en Confluent? Confluent ofrece funciones a nivel enterprise que van más allá del conjunto de funciones de MSK y proporcionan una plataforma de streaming de datos completa, preparada para hacer realidad un sinfín de casos de uso.

| Servicio | Confluent Cloud | Amazon MSK | MSK Serverless |
|---|---|---|---|
| Interfaz de usuario de Kafka | Totalmente gestionado | No disponible | No disponible |
| Autenticación | Autenticación amplia | Autenticación amplia | Autenticación limitada |
| Cifrado | Cifrado de extremo a extremo | No compatible | No compatible |
| Conectores | Preconstruidos y totalmente gestionados | Personalizados y self-managed | Personalizados y self-managed |
| Gobernanza de datos | Totalmente gestionado | No disponible | No disponible |
| Procesamiento en streaming | Totalmente gestionado | Añade complejidad | Añade complejidad |
| Zero-ETL para Streams-to-Tables | Ahora disponible con Tableflow | No disponible | No disponible |
¿Qué características de seguridad a nivel enterprise ofrecen Confluent Cloud y Amazon MSK?
-
Confluent Cloud ofrece estrictos sistemas de autenticación para todos los tipos de clusters: solo los clientes autenticados pueden acceder a un cluster. Confluent Cloud admite SASL/PLAIN y SASL/OAUTHBEARER (en versión preliminar) como mecanismos de autenticación. El cifrado a nivel de campo del cliente en Confluent Cloud añade una capa adicional de seguridad al cifrar los datos confidenciales del cliente, protegerlos tanto del lado del cliente como del servidor y mantener la seguridad cuando los datos están en movimiento entre mecanismos de producers y consumers.
-
Amazon MSK ofrece amplias opciones de autenticación para clusters aprovisionados de MSK, opciones limitadas para MSK sin servidor y no admite opciones de cifrado: todos los clusters de MSK solo permiten el acceso autenticado, pero los clusters aprovisionados de MSK admiten SASL/SCRAM, mTLS e IAM como mecanismos de autenticación, mientras que los clusters de MSK Serverless solo admiten IAM como mecanismo de autenticación.
¿Qué tipo de Kafka Connectors ofrecen Confluent Cloud y Amazon MSK?
-
Confluent Cloud ofrece más de 120 conectores preconstruidos y más de 80 conectores totalmente gestionados: integra Confluent de forma fácil y eficiente con otros servicios modernos y heredados en nubes locales y públicas con una cartera de más de 120 conectores que se amplía periódicamente y está disponible como componentes totalmente gestionados o como componentes prediseñados con la asistencia de Confluent.
-
Amazon MSK solo admite conectores personalizados y self-managed: integra Kafka con tus servicios de datos con la opción de crear tus propios conectores o desplegarlos a partir de un pequeño subconjunto de conectores desarrollados por la comunidad. Los conectores personalizados requieren mantenimiento y la asistencia técnica de AWS no cubre los conectores de la comunidad de Kafka.
¿Qué funcionalidades de gobernanza de streams ofrecen Confluent Cloud y Amazon MSK?
-
Confluent Cloud ofrece Stream Governance, un conjunto de servicios totalmente gestionados para administrar la disponibilidad, la integridad y la seguridad de los datos: Stream Governance se basa en tres pilares estratégicos clave: Stream Lineage, Stream Catalog y Stream Quality. Además, Data Quality Rules garantiza la calidad de los streams.
-
Amazon MSK exige el uso de herramientas comunitarias gratuitas sin asistencia o, alternativamente, de herramientas de terceros de pago para gobernar los datos en los topics de Kafka: MSK no tiene funciones de linaje o catálogo. Para garantizar la calidad de los datos, MSK y MSK Serverless se integran con el Schema Registry de Confluent y Glue. Sin embargo, no disponen de soluciones de validación de esquemas del broker —que obliguen a los producers de datos a utilizar Schema Registry para controlar la evolución del esquema—, Data Quality Rules —para validar y restringir valores de campo individuales dentro de un stream—, ni Schema Linking —para sincronizar esquemas en distintos entornos—.
¿Qué capacidades de procesamiento en streaming ofrecen Confluent Cloud y Amazon MSK?
-
Confluent ofrece procesamiento en streaming serverless con Confluent Cloud para Apache Flink®: los usuarios solo tienen que crear un cluster de Flink y empiezan a usar el procesamiento de streams con un lenguaje similar a SQL. Confluent Cloud también es compatible con el servicio fully-managed AWS Lambda.
-
Amazon MSK ofrece procesamiento en streaming con Apache Flink, aunque con mayor complejidad: MSK admite el servicio gestionado para Apache Flink (MSF): una opción potente, pero que añade cierta complejidad a medida que los usuarios necesitan configurar redes, crear un cuaderno de MSF Studio, escribir con una sintaxis similar a SQL, probar y empaquetar el código, subirlo a S3 y utilizar ese código para crear una aplicación en MSF.
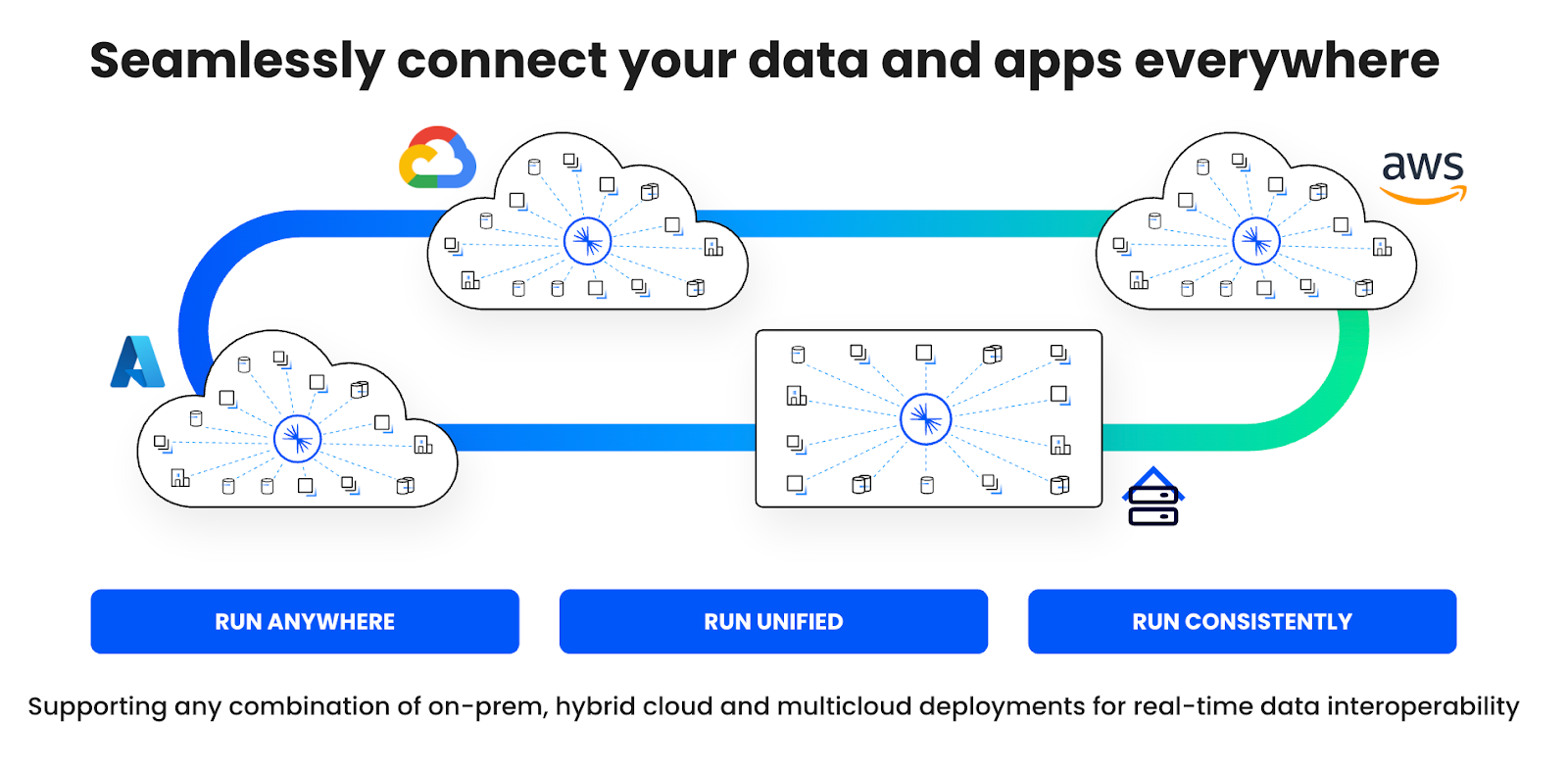
Nube híbrida y multi-cloud con Confluent frente a la dependencia de proveedores en AWS
Desarrolla a gran escala con streaming de datos cloud-native y sin quedar atado a un único proveedor de servicios en la nube. A diferencia de Amazon MSK (que solo está disponible en AWS), Confluent te ofrece una verdadera flexibilidad en el despliegue que admite cualquier combinación de arquitecturas locales, híbridas y multi-cloud y garantiza una perfecta interoperabilidad de datos:
-
Servicio coherente y totalmente gestionado en AWS, Microsoft Azure y Google Cloud
-
Streaming de datos cloud-native y self-managed con Confluent Platform
-
Control y rentabilidad con WarpStream BYOC
Además, Cluster Linking te ofrece un puente permanente para sincronizar datos entre cualquier entorno en tiempo real.
Solicita un cálculo a medida de cuánto podrías ahorrar
Obtén una comparativa de costes personalizada para ver cuánto ahorrarías al pasarte a Confluent Cloud desde Amazon MSK. Rellena el formulario con tus datos y un miembro de nuestro equipo se pondrá en contacto contigo para ayudarte a calcular tu ahorro con Confluent y resolver todas tus dudas.
¿Necesitas más información antes de hablar con el equipo de ventas? Aquí tienes algunos recursos relacionados:
Confluent Cloud vs. Amazon MSK: FAQs
Is Confluent Cloud more cost-effective than Amazon MSK?
Yes, Confluent Cloud is more cost-effective than Amazon MSK because of cost savings from:
-
Reduced infrastructure costs: Confluent Cloud’s serverless, cloud-native architecture eliminates the need for over-provisioning that is common with MSK’s node-based pricing. Features like Infinite Storage and Tiered Storage decouple compute and storage, further reducing infrastructure spending. For example, SecurityScorecard saved over $1M in infrastructure and operational costs by migrating to Confluent Cloud
-
Lower operational overhead: Offloading complex and time-consuming operational tasks—such as capacity management, scaling, and upgrades—to Confluent Cloud allows you to reallocate valuable engineering resources to innovation instead of infrastructure management. One customer reported they would have needed to hire at least 10 more people to manage Kafka themselves.
-
Minimized downtime and risk: Confluent Cloud offers a 99.99% uptime SLA for production workloads. Compared to MSK (with a 99.9% SLA with exclusions for Kafka failures and customer configuration failures), Confluent’s SLA delivers higher reliability and reduces the substantial hidden costs associated with downtime.
Choosing Confluent Cloud can reduce your self-managed Kafka costs by 40-70%.
What are the main cost drivers of Confluent Cloud vs Amazon MSK?
The main cost drivers of Confluent Cloud are:
-
Usage based consumption: Confluent Cloud’s pay-as-you-go pricing is based on actual usage (e.g., throughput) rather than provisioned infrastructure. This pay-as-you-go model eliminates the need for over-provisioned, underutilized clusters that typically lead double the infrastructure costs for self-managed Kafka vs fully managed on Confluent.
-
Managed horizontal scaling: Elastic Confluent Units for Kafka (eCKUs) are a Confluent Cloud’s unit of horizontal scalability for billing. eCKUs autoscale up and down based on workload. The cost includes the complete management of the platform, from infrastructure and scaling to monitoring and support, which is designed to reduce or eliminate the separate operational and support costs customers would otherwise incur.
The main cost drivers of Amazon MSK are:
-
Higher infrastructure spend: MSK uses node-based pricing, requiring users to pay for provisioned compute and storage, which often leads to over-provisioning to handle peak loads. Networking, particularly cross-Availability Zone (cross-AZ) traffic, can also become a significant hidden cost, sometimes accounting for 80-90% of total infrastructure expenses.
-
Self-managed operations and management: Since MSK is not a fully managed Kafka service, significant engineering resources are required for manual tasks like sizing, scaling, rebalancing partitions, patching, and monitoring. This includes the cost of hiring and retaining specialized Kafka talent.
-
Custom development and maintenance: MSK requires significant custom platform development and maintenance, which can take 2+ years to bring to production and cost $3-5M or more in costs. Because MSK is a hosted service rather than a complete platform with essential components included out-of-the-box, engineering teams must spend valuable time and resources building and maintaining their own solutions for developer tools, DevOps automation, infrastructure enhancements for reliability and disaster recovery, monitoring, integration, security controls, and governance.
-
Unplanned downtime and higher business risk: MSK's 99.9% SLA excludes failures in the underlying Kafka software, as well as failures due to customer errors in configuration, leaving customers responsible for resolving failures that can easily turn into major outages. The risk of outages due to storage limitations, manual scaling errors, or unresolved bugs can lead to substantial hidden costs, including lost revenue and reputational damage.
What are the pros and cons of MSK Serverless vs Confluent Cloud?
Confluent Cloud pros and cons include:
-
Pro: Confluent Cloud offers a complete, serverless experience that automates all operational aspects, from capacity planning and elastic scaling (to GBps+) to upgrades and monitoring.
-
Pro: Confluent Cloud goes far beyond core Kafka, providing a rich ecosystem of 120+ connectors, serverless Flink for advanced stream processing, and an enterprise-grade Stream Governance suite.
-
Pro: Confluent Cloud delivers significant cost savings through cost-efficient autoscaling and usage-based consumption (which prevents overprovisioned and underutilized clusters and cuts infrastructure costs by 50%+), lowers TCO 40-70% compared to self-managed Kafka by eliminating $1M in development and operations costs over 3 years, and with a 99.99% uptime SLA that reduces business risk.
-
Con: For smaller teams, projects with predictable workloads, or organizations that already have in-house Kafka expertise, Confluent's fully managed service and advanced features may not present a clear upfront financial advantage.
MSK Serverless pros and cons include:
-
Pro: MSK Serverless addresses some of MSK's operational challenges with pre-provisioning
-
Pro: MSK Serverless can elastically scale to a given quota without the need for manual rebalancing.
-
Pro: MSK Serverless offers unlimited storage (with a per-partition quota) without the manual configuration required by MSK Standard brokers.
-
Con: MSK Serverless has a strict throughput limit of 200MBps ingress and 400MBps egress, with no upgrade path for workloads that exceed this.
-
Con: MSK Serverless lack many mission-critical components, including a rich connector ecosystem, integrated stream processing (like Flink), and comprehensive, enterprise-grade security and governance tools.
-
Con: MSK Serverless has the same weak 99.9% SLA as MSK Provisioned, which does not cover Kafka-related failures.
-
Con: Like all MSK offerings, MSK Serverless has no multicloud support and is locked into the AWS ecosystem.
How does Confluent Cloud autoscale throughput compared to MSK?
Confluent Cloud offers true elastic, automated scaling from 0 to GBps, while Amazon MSK's elastic scaling capabilities are more limited and manual:
-
Confluent Cloud provides fully managed, automated, and elastic scaling. It can automatically scale clusters up and down from 0 to GBps+ to meet demand without interruption. Its cloud-native Kora engine uses an intelligent control plane and self-balancing algorithms to manage capacity, rebalance partitions, and eliminate the need for overprovisioning and underutilizing clusters to avoid outages. As a result, customers can save 50% or more on infrastructure costs.
-
Standard clusters on MSK Provisioned require manual sizing, scaling, and rebalancing. While you can add brokers to scale up, you cannot easily scale down and are more likely to have a large number of overprovisioned clusters at any given time. Modifying storage capacity can take anywhere from 6 to 24 hours. Express clusters on MSK Provisioned offer faster scaling and rebalancing, but it is still a manual process.
-
MSK Serverless offers some autoscaling but only within a lower quota limit (up to 200 MBps ingress and 400 MBps egress). There is no solution to upgrade beyond this quota without moving to a different offering.
How do Confluent and MSK differ in cluster provisioning speed?
Confluent Cloud can provision clusters in minutes, whereas provisioning an Amazon MSK cluster can take from 30 minutes to over an hour.
Is Confluent Cloud more reliable and performant than MSK?
Yes, Confluent Cloud is architected to be more reliable and performant than Amazon MSK and significantly reduces the risk of unplanned downtime compared to MSK:
-
Confluent's Kora engine provides native resilience with continuous monitoring, proactive replacement of degraded nodes, and automatic rebalancing to maintain availability without operator intervention. MSK lacks these native self-healing capabilities, requiring customers to manually identify and replace failed brokers.
-
Confluent Cloud offers a 99.99% uptime SLA that covers all components, including Kafka-related failures. This translates to a maximum of 0.876 hours of downtime per year. Amazon MSK offers a 99.9% SLA (a maximum of 8.76 hours of downtime per year), but that SLA explicitly excludes failures caused by the underlying Apache Kafka or Zookeeper software, placing the burden of resolving these critical issues on the customer and significant increasing the actual maximum hours of downtime per year MSK customers may experience.
Which platform offers stronger developer tooling, Confluent Cloud or Amazon MSK?
Confluent Cloud offers significantly stronger and more comprehensive developer tooling than Amazon MSK:
-
Confluent Cloud provides a robust Terraform provider that allows developers to manage both control plane resources (like clusters and Schema Registry) and data plane resources (such as Topics and ACLs). This enables complete automation of infrastructure deployments as code. Amazon MSK offers more limited IaC capabilities, as its Terraform support can only manage control plane resources. Managing data plane resources requires building custom operators and processes.
-
Confluent Cloud offers a rich set of APIs for point-and-click operations and automation. It also provides a user-friendly and intuitive cloud UI that allows developers to easily manage and monitor their Kafka clusters and data streams. MSK does not have a dedicated Kafka UI and developers must often build their own tools on top of MSK’s APIs. For example, MSK lacks a native REST proxy for non-Java clients, a feature available in Confluent.
-
Confluent Cloud supports multi-language client development, providing client libraries for several non-Java languages including C/C++, Go, Python, and .NET. Users can generate the necessary configuration details (including cluster credentials and API keys) directly from the Confluent Cloud Console and paste them into client application code. Amazon MSK also supports non-Java clients but enabling them to interact with MSK requires some additional work when setting up and configuring the clients for authentication and authorization.
Does Confluent Cloud offer better support than Amazon MSK?
Yes, Confluent provides customers with guidance from the world's foremost Kafka experts. Confluent was founded by the original co-creators of Kafka, and its support and professional services teams have millions of hours of Kafka experience. MSK support is limited and does not have the same depth of Kafka-specific knowledge.
What are the feature differences around connectors and schema management?
Confluent Cloud provides 120+ pre-built connectors and 80+ fully managed connectors, enabling instant integration with a wide range of popular data sources and sinks both inside and outside the AWS ecosystem. In contrast, Amazon MSK has very limited connector support. It offers fewer than 10 direct or "half-supported" integrations and primarily provides just the underlying Connect infrastructure, requiring users to bring, manage, and maintain their own connectors. This results in additional operational burden and cost. In fact, Confluent offers instant, fully managed connectivity to more native AWS services than Amazon MSK does.
Confluent Cloud includes Stream Governance, a comprehensive, fully managed suite that provides Schema Registry, Data Portal, Stream Lineage, and Data Quality Rules. With features like broker-side schema validation and the ability to tag data containing personally identifiable information (PII), your data streams are discoverable, trustworthy, and secure. Amazon MSK integrates with AWS Glue Schema Registry but lacks a full suite of governance tools, such as schema validation, data lineage, or a data catalog.
Does Confluent Cloud support multicloud deployments?
Yes, Confluent Cloud supports multicloud deployments. It is designed for both multicloud and hybrid environments, whereas Amazon MSK is an AWS-only service. Confluent customers can use its fully managed Kafka service on all three major public clouds and use its Cluster Linking feature to replicate data across clouds.