Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
What Is Serverless Kafka?
Serverless Kafka is a fully managed delivery model for Apache Kafka® where complex scaling, infrastructure, and operations tasks are abstracted away. Developers interact with the service through familiar APIs, while the platform automatically handles provisioning, elasticity, availability, and maintenance.
What Does “Serverless” Mean?
In cloud computing, serverless refers to computing models that allow developers to write code without having to manage servers or capacity. The service provider is responsible for:
-
Provisioning and maintaining infrastructure
-
Scaling resources up or down based on demand
-
Handling failures, upgrades, and routine operations
This general concept is explained in more detail in this overview of serverless computing.
How Does Serverless Apply to Event Streaming?
Event streaming systems like Kafka are designed to handle continuous flows of data—such as application events, logs, metrics, or transactions. Traditionally, running Kafka efficiently and cost-effectively requires complex decisions about:
-
Network and storage capacity
-
Scaling strategies for peak traffic
With Kafka, serverless development means these operational concerns are removed from the developer workflow. The platform dynamically allocates capacity as traffic changes, without requiring manual intervention. This design aligns with Kafka’s evolution toward elastic, cloud-native architectures.
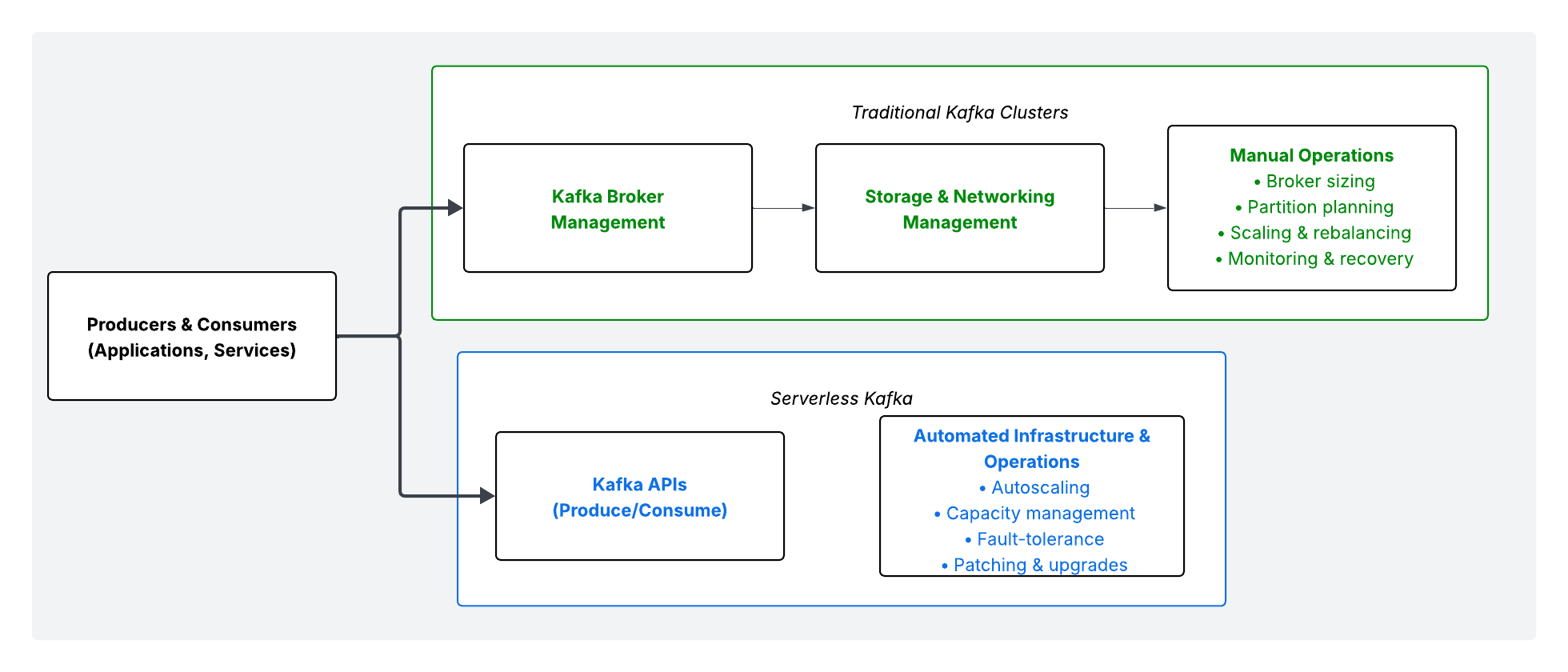
Serverless Kafka vs. Other Kafka Deployment Models
To set a clear baseline, it helps to compare serverless Kafka with other common approaches:
-
Self-managed Kafka: Teams run Kafka on their own infrastructure (on-premises or cloud VMs). They are responsible for installation, upgrades, scaling, monitoring, and incident response.
-
Kafka hosted in the cloud: A cloud provider operates Kafka clusters on behalf of the user. While operational burden is reduced, users still provision clusters, plan capacity, and manage scaling.
-
Kafka serverless in the cloud: There are no clusters to size or manage. Capacity scales automatically, and usage is typically measured by actual data throughput rather than pre-allocated resources.
Here’s a practical way to think about it: in traditional Kafka deployments, developers and operators manage both:
-
The data plane (i.e., the events flowing through topics)
-
The operations plane (i.e., the brokers, storage, scaling, performance tuning)
On the other hand, teams using Kafka as a serverless platform focus almost entirely on the data plane. The operations plane is handled by their MSP.
What Are the Benefits of Making Kafka Serverless?
Moving to serverless shifts Kafka from an infrastructure-heavy platform to a cloud-native service that supports faster development and more responsive business operations. The advantages are most visible when they are mapped to real-world outcomes rather than technical features alone.
Key Advantages and Business Outcomes of Taking Kafka Serverless
-
No infrastructure management: Teams no longer provision brokers, manage storage, or plan capacity. Instead, engineering teams spend more time building customer-facing features, reducing operational overhead, and accelerating product delivery.
-
Elastic scaling up and down instantly. Making Kafka serverless automatically adjusts throughput and storage as traffic changes, without manual intervention. Having applications remain responsive during traffic spikes ensures reliable real-time insights and uninterrupted user experiences.
-
Lower cost for spiky workloads: Capacity is not pre-allocated for peak usage. Costs scale with actual data volume instead of fixed infrastructure. This results in more efficient spending on data infrastructure, especially for event-driven systems with unpredictable or seasonal traffic patterns.
-
Faster time-to-value: Developers can start streaming events immediately, without weeks of cluster setup and tuning. This leads to faster experimentation, quicker time-to-market for new products and services, and earlier access to real-time data for decision-making.
High-Throughput Scenarios Where Serverless Kafka Excels
Serverless Kafka is particularly effective for workloads that combine high data volume with variable demand, including:
-
Real-time analytics and AI pipelines: Continuous ingestion of application events, logs, or user interactions to power real-time dashboards and machine learning models.
-
IoT and telemetry ingestion: Large numbers of devices producing bursts of data, where traffic can vary significantly based on usage patterns or external events.
In these scenarios, automatic scaling and usage-based cost models make Kafka serverless use cases easier to operate and more cost-efficient.
By removing operational complexity and improving elasticity, serverless Kafka enables organizations to adopt real-time architectures across AI, IoT, and analytics initiatives. These outcomes are closely tied to broader business solutions such as real-time decision-making and intelligent automation, which are explored further in Confluent’s solutions.
If Serverless Is So Great, Why Doesn’t Everyone Do It?
At first glance, serverless Kafka appears to be an ideal solution: no infrastructure to manage, built-in elasticity, and usage-based cost efficiency. However, building and operating a truly reliable serverless Kafka platform is challenging.
Below are key reasons why serverless Kafka is non-trivial to implement and why not every organization adopts it immediately.
Kafka’s Operational Complexity Still Matters
Kafka’s design emphasizes high throughput, low latency, and strong durability. Achieving these properties in production requires careful handling of several core concerns:
-
Partitioning strategy: Effective partition strategy directly influences throughput, consumer parallelism, and data locality. Designing partitions without understanding traffic characteristics can lead to hotspots or uneven load distribution.
-
Performance testing: Real-world Kafka workloads can vary significantly. Load characteristics such as message size, key distribution, and consumer group patterns have a material impact on performance outcomes. Understanding how to benchmark and test Kafka workloads is a skill in its own right.
Even with elastic scaling, poorly designed topics or imbalanced partitions can bottleneck throughput, creating a system that scales compute but not effective parallelism.
Scaling in Distributed Systems Is Hard
Scaling is more than adding capacity—it’s about maintaining performance and consistency under load. In distributed systems like Kafka, you have to consider:
-
Horizontal vs. vertical scaling tradeoffs: Scaling out (adding more brokers) distributes load but introduces coordination overhead; scaling up (larger machines) increases capacity but can mask distribution issues.
-
Domain-specific best practices for scaling: Effective scaling involves tuning producer throughput, optimizing network and disk I/O, and balancing partition counts. These techniques often require domain insight, even in managed environments.
Achieving seamless elasticity that doesn’t compromise performance requires sophisticated orchestration under the hood, which is a non-trivial engineering challenge.
Production Issues Don’t Vanish
Stream processing failures, consumer lag, backpressure, and connector misconfigurations create real operational headaches in any event streaming deployment. These production issues still occur in serverless environments and often require deep understanding to diagnose:
Even in a serverless model, understanding how key parts of the data streaming platform behave at scale helps organizations build resilient streaming architectures. For example, Kafka Streams applications may require stateful processing, fault tolerance, and windowing configurations that interact with the underlying event fabric. Understanding how to scale all these essential components is a key part of being able to deliver reliable a reliable Kafka service for your developer teams.
Cost Dynamics of Real-Time Streaming
While serverless billing models align cost with usage, predictable cost modeling is itself a discipline. Real-time workloads can generate significant throughput charges, and events that were once infrequent can quickly become high-volume streams. The dynamics of throughput, storage duration, and connector usage contribute to real-time streaming expenses.
Streaming Architecture Is Evolving
Apps built on event streaming make use of complex data pipelines—such as Kafka Streams topologies or multi-stage ETL flows. Scaling these logically layered workloads involves intricate tradeoffs.
Every architectural decision — from batching strategies to commit intervals — introduces tradeoffs between latency, throughput, and reliability. Designing streaming logic that meets business service-level agreements (SLAs) still demands engineering discipline, regardless of how the Kafka layer itself is delivered.
Kafka Serverless vs. Traditional Kafka Clusters
Choosing between serverless and traditional Kafka operating models depends on how much operational control, scalability, and cost predictability an organization needs. While both models are built on Kafka APIs, they differ significantly in how capacity is managed, how costs are incurred, and how much responsibility falls on the engineering team.
At a high level, traditional Kafka clusters require users to provision and manage infrastructure, even when the service is hosted by a cloud provider. Serverless Kafka, by contrast, abstracts these responsibilities and automatically adapts to workload demand.
Key differences at a glance:
|
Dimension |
Serverless Kafka |
Traditional Kafka Clusters (Self-managed or Provisioned) |
|
Infrastructure management |
Fully abstracted; no brokers or clusters to manage |
Users provision, operate, and maintain clusters |
|
Scalability |
Automatic, elastic scaling based on real-time demand |
Manual or semi-automated scaling; requires planning |
|
Cost model |
Usage-based, aligned to data throughput and storage |
Fixed or pre-allocated capacity sized for peak load |
|
Operational effort |
Minimal day-to-day operations |
Significant operational overhead (upgrades, tuning, recovery) |
|
Flexibility and control |
Less low-level tuning, standardized configurations |
Full control over broker configs and deployment topology |
|
Time to get started |
Immediate; no provisioning required |
Slower; setup and capacity planning needed |
|
Best suited for |
Variable, bursty, or unpredictable workloads |
Stable workloads with predictable capacity needs |
How Serverless Kafka Works in Practice
In practice, serverless Kafka delivers the same core Kafka semantics—topics, partitions, producers, and consumers—while fundamentally changing how capacity and operations are handled. The system is designed to be cloud-native from the ground up, with elasticity and automation built into the architecture rather than added later.
There are no brokers or clusters to provision, no disks to size, and no capacity plans to maintain. Instead, the platform dynamically allocates compute, storage, and network resources based on real-time workload demand.

Key architectural characteristics include:
-
Elastic scaling: Throughput and storage scale automatically as traffic increases or decreases.
-
Pay-per-use consumption: Usage is metered based on actual data streamed and stored, rather than fixed infrastructure.
-
No broker provisioning: Developers never create or manage Kafka brokers or clusters.
-
Automatic capacity management: The platform handles cluster rebalancing, fault tolerance, and resource optimization transparently.
This approach reflects modern cloud-native design principles and allows Kafka to behave like a managed cloud service rather than a system that must be operated.
For a deeper look at how this model is implemented in production, learn more about Confluent Cloud, a fully managed data streaming platform powered by a serverless Kafka engine.
What Changes Compared to Traditional Kafka Operations?
To understand the practical impact of serverless Kafka, it helps to contrast it with the responsibilities involved in operating traditional Kafka clusters.
What Changes Compared to Traditional Kafka Operations?
To understand the practical impact of serverless Kafka, it helps to contrast it with the responsibilities involved in operating traditional Kafka clusters.
Scenario 1: Your Kafka environment is experiencing high consumer lag and latency. In a traditional Kafka environment, you would have to add brokers, rebalance partitions, tune fetch and poll configurations, and investigate log metrics to ensure you’re addressing the actual cause.
If your interventions fail, your consumers won’t be able to keep up with producers. Any impacted applications or services will experience slow loading, unresponsiveness, or data errors, which could result in poor user experiences, lost revenue, and more.
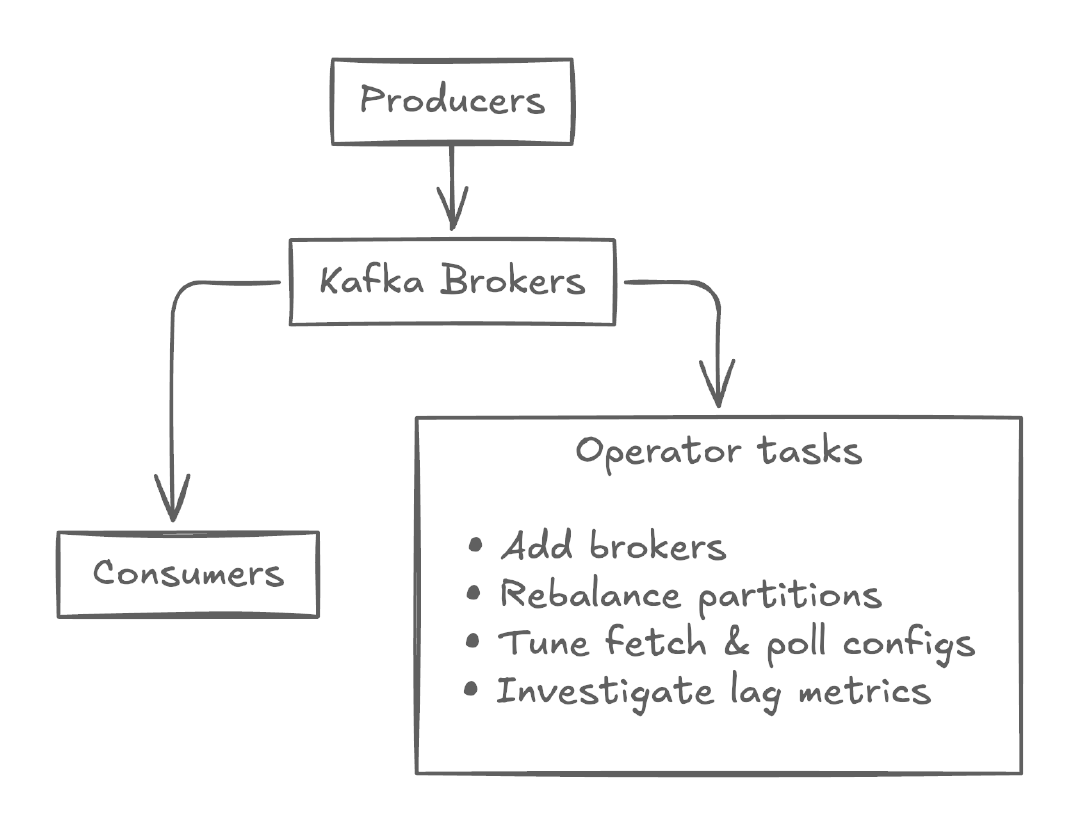
Scenario 2: You’ve misconfigured your Kafka broker and are dealing with poor performance and at risk of data loss. To avoid further consequences, you’ll first need to monitor in-sync replicas (ISR) and under-replicated partitions to identify the issue. Once you’ve identified the root cause, you’ll need to move quickly, determine the right partition strategy, adjust the replication factor, and tune disk and network I/O.
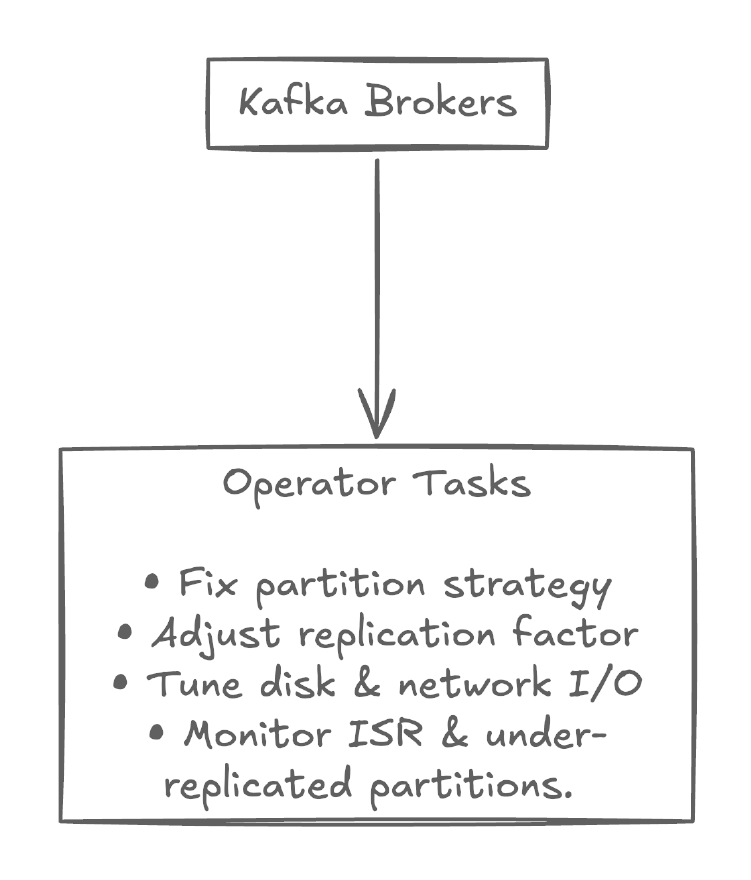
Operational complexity does not disappear, but it is shifted away from application teams and handled by the platform. This separation is what enables serverless Kafka to deliver elasticity and reliability without increasing developer burden. By abstracting these operational concerns, a serverless Kafka architecture allows your team to focus on:
Cost Drivers of Serverless Kafka vs. Self-Managing Kafka
Evaluating Kafka deployment options requires looking beyond infrastructure pricing to the full cost drivers: engineering time, operational risk, scaling complexity, and long-term agility. Below, we compare self-managing Kafka, building an internal serverless Kafka platform, and using a fully managed, serverless Kafka service such as Confluent Cloud, considering both pros and cons of each approach.
Comparative Cost and Responsibility Table
|
Cost Dimension |
Self-Managing Kafka |
Internal Serverless Platform |
Fully Managed Serverless Kafka |
|
Infrastructure Cost |
High, pre-provisioned |
Variable, but requires custom tooling |
Pay-per-use, scales with actual demand |
|
Operational Effort |
High (clusters, upgrades, scaling) |
Very high (platform engineering) |
Low (abstracted, automated) |
|
Engineering Time |
Significant |
Very significant |
Minimal |
|
Skill Requirement |
Deep Kafka ops expertise |
Deep platform + Kafka expertise |
Moderate (application focus) |
|
Scalability |
Manual/semi-automated |
Automated (internal tooling) |
Fully automated, elastic |
|
Time-to-Value |
Slow |
Moderate |
Fast |
|
Risk of Outage & Misconfig |
High |
Moderate to high |
Low |
|
Best Fit For |
Full control and custom ops |
Large orgs with platform engineering capacity |
Variable workloads, fast engineering cycles |
Cost Implications of Self-Managing Kafka
Pros
-
Full control over infrastructure and configurations
-
Fine-tuned performance when expertly managed
-
No dependency on external cloud provider pricing
Cons
-
High operational overhead: capacity planning, scaling, patching, and monitoring require dedicated engineering teams
-
Significant skill requirement: Kafka scaling and operational expertise are needed to maintain performance and reliability
-
Risk of production issues such as consumer lag, misconfiguration, or under-replicated partitions, which necessitate ongoing maintenance and incident resolution
-
Delayed time-to-value because clusters must be provisioned and tuned before production use
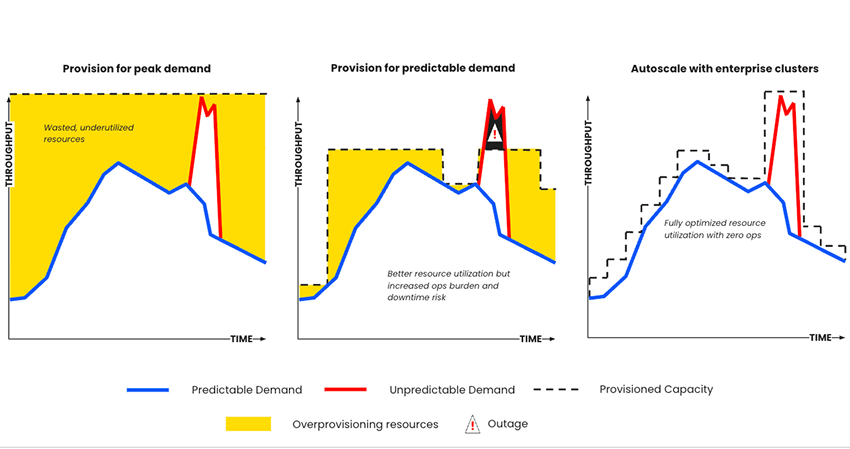
Costs of Building an Internal “Serverless” Kafka Platform
Pros
-
Provides an internal abstraction layer that simplifies Kafka usage for development teams
-
Centralized platform engineering can abstract infrastructure details from application teams
Cons
-
Requires substantial investment in platform engineering to build and operate automation for scaling, monitoring, upgrades, and recovery
-
Internal platform teams must solve distributed systems challenges that Kafka itself exposes, including partition strategy, throughput variability, and stateful stream processing trade-offs
-
Engineering effort for automation and operational tooling competes with product development priorities
-
Ongoing maintenance of custom tooling and platform services adds to long-term cost
While building an internal platform can be a logical step for large enterprises with extensive Kafka usage, it shifts costs from infrastructure to specialized human capital and tooling debt.
Fully Managed Serverless Kafka Platform
Pros
-
No infrastructure provisioning or broker management; capacity and scaling are automatic
-
Elastic, pay-per-use pricing aligns cost with actual throughput and storage instead of fixed capacity
-
Reduced operational burden frees engineering teams to focus on application logic and data workflows
-
Predictable delivery of Kafka fundamentals without heavy ops investment
Cons
-
Less direct control over low-level configurations
-
Cost models dependent on workload patterns; high sustained throughput can lead to higher variable costs if not monitored
By providing an elastic, cloud-native streaming platform, Managed serverless offerings reduce the four major cost drivers of self-managing Kafka: infrastructure, operations, downtime risk, and delayed time-to-value. Analyses such as the Forrester TEI report on Confluent Cloud show significant reductions in total cost of ownership (TCO) compared to self-managed deployments over time.
When to Choose Serverless Kafka – Key Use Cases
When should you use Kafka serverless? You should choose serverless Kafka when you need real-time event streaming that scales automatically, minimizes operational overhead, and accelerates time-to-market—especially for workloads with variable traffic, fast-moving teams, or experimentation-heavy environments.
Scenarios Where Serverless Kafka Delivers Strong Business and Engineering Outcomes
|
Use Case |
Why It Works |
Benefits |
|
Services publish and consume events without managing brokers or partitions. Traffic spikes from downstream consumers are handled automatically. |
Teams can onboard new microservices without re-architecting infrastructure, reduce coupling between teams, improve system reliability at scale, and delivery new features faster |
|
|
AI and ML systems increasingly depend on continuous, real-time data rather than batch ingestion. Serverless Kafka is ideal for real-time feature ingestion, streaming inference inputs and outputs, and feedback loops for online learning and automation |
Elastic scaling ensures the platform can absorb sudden spikes during model training, inference bursts, or experimentation—without capacity planning. This leads to faster AI experimentation and iteration and reduced friction between data and ML teams. |
|
|
Real-time IoT analytics and telemetry |
IoT and telemetry workloads are inherently unpredictable—devices connect, disconnect, and burst data at scale. Serverless Kafka easily handles sensor and device telemetry ingestion, real-time monitoring and alerting, and streaming analytics for dashboards and more. |
Automatic scaling ensures ingestion keeps pace with device traffic while avoiding overprovisioning during idle periods. This ensures real-time operational visibility is maintained at a lower cost. |
How Serverless Kafka Fits Into the Future of Streaming
Kafka’s evolution closely mirrors the broader shift in distributed systems—from infrastructure-heavy deployments to cloud-native platforms optimized for developer productivity. What began as self-managed Kafka running on dedicated servers has steadily progressed toward managed services, and now toward serverless Kafka, where infrastructure is fully abstracted.
In the early days, choosing to run Kafka meant operating your own clusters and being responsible for provisioning brokers, tuning partitions, managing storage, planning capacity, and responding to incidents. While this offered maximum control, it required deep operational expertise and significant ongoing effort.
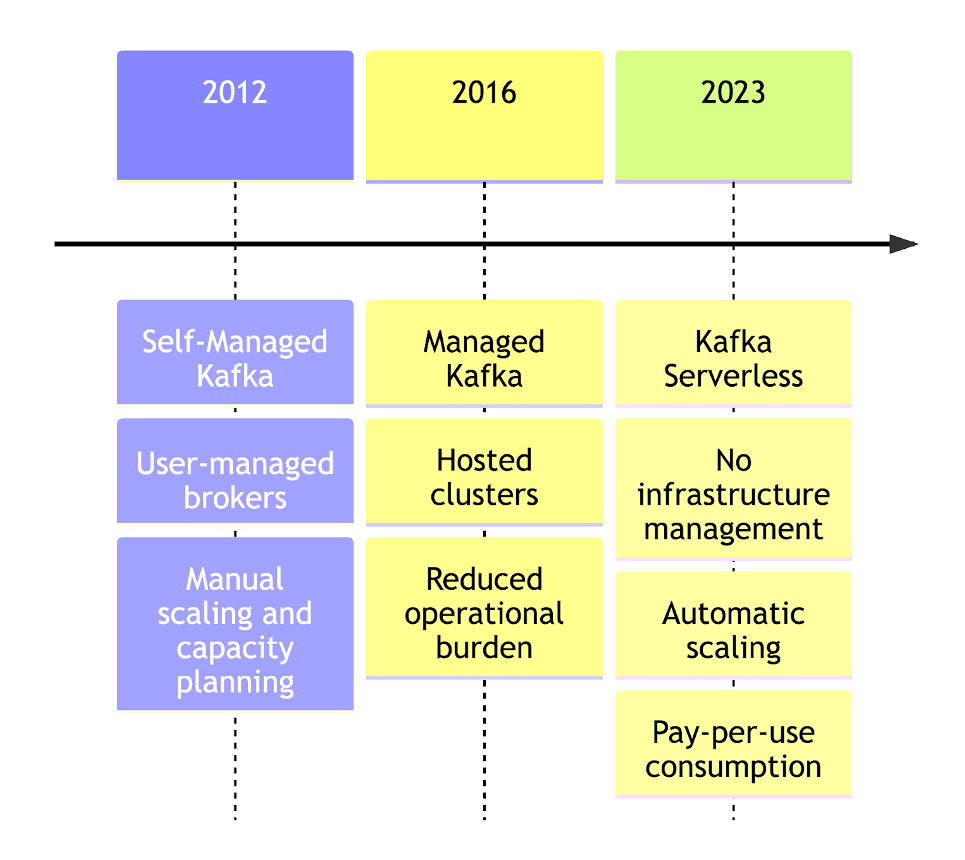
Hosted Kafka services reduced some of this burden by offloading cluster provisioning and maintenance to cloud providers. However, many operational concerns—such as scaling decisions, cost optimization, and performance tuning—still remained visible to users.
Several forces are pushing Kafka toward a serverless future where more workloads will operate on a fully managed model:
-
Unpredictable workloads: Real-time applications, AI pipelines, and IoT systems experience highly variable traffic that is difficult to provision in advance.
-
Developer velocity: Teams want to experiment, deploy, and iterate without waiting on infrastructure changes.
-
Operational complexity: As Kafka adoption grows across organizations, managing clusters at scale becomes a bottleneck.
Serverless Kafka directly addresses these challenges by making elasticity and operational simplicity default rather than optional.
Confluent’s Role in Advancing the Serverless Kafka Model
Confluent has played a central role in advancing Kafka from an open source system to a cloud-native streaming platform. Rather than stopping at “hosted Kafka,” Confluent invested in rethinking Kafka’s architecture for the cloud—enabling true serverless characteristics such as fine-grained elasticity, usage-based pricing, and integrated governance.
This approach positions serverless Kafka not as a feature add-on, but as a foundational shift in how event streaming platforms are built and consumed.
Confluent Cloud extends its fully managed data streaming service beyond core messaging and event streaming use cases to deliver a complete, production-ready streaming platform with:
-
Fully managed connectors for databases, cloud services, and SaaS systems
-
Built-in governance with schemas, data contracts, and lineage
-
Enterprise-grade security including encryption, access controls, and auditability
-
Global availability across regions and cloud providers
-
Advanced stream processing capabilities with Confluent Cloud for Apache Flink®
-
Stream-to-table materialization with data lakes and data warehouses
Together, these capabilities enable teams to build real-time systems without assembling and operating a fragmented Kafka ecosystem.
Confluent extends the power of fully managed, serverless Kafka with these enterprise-grade platform features—designed for teams building real-time applications at global scale.
Get Started with Kafka Serverless on Confluent Cloud
If you’re exploring serverless Kafka for the first time or looking to simplify an existing Kafka deployment, Confluent Cloud provides a practical way to get started. You can create a serverless Kafka environment in minutes and begin building real-time applications without managing clusters or capacity.
Start building with serverless Kafka on Confluent Cloud today.
Serverless Kakfa – FAQ
What is Kafka serverless?
Kafka serverless is a fully managed delivery model for Apache Kafka where infrastructure provisioning, scaling, and operations are abstracted away from the user. Developers interact with Kafka through standard APIs, while the platform automatically manages capacity, availability, and performance behind the scenes. This allows teams to use Kafka without operating clusters or planning broker capacity.
How does Kafka serverless pricing work?
Kafka serverless pricing is typically usage-based. Instead of paying for pre-provisioned brokers or fixed cluster sizes, you pay for the amount of data you produce, consume, and store. This model is well suited for workloads with variable or unpredictable traffic, as costs scale up and down with actual usage rather than reserved capacity.
Kafka serverless vs Kafka on-premises: what’s the difference?
Kafka on-premises requires teams to provision hardware, manage brokers, plan capacity, handle upgrades, and respond to operational issues. Kafka serverless removes these responsibilities by running Kafka as a cloud-native service that scales automatically. The tradeoff is reduced infrastructure-level control in exchange for significantly lower operational overhead and faster time-to-value.
Is Kafka serverless right for production workloads?
Yes, Kafka serverless is designed for production use cases, including mission-critical systems. It supports high throughput, low latency, and built-in reliability while removing the operational risks associated with self-managed clusters. It is especially effective for production workloads that experience spiky traffic, rapid growth, or frequent changes in demand.
Does Confluent provide Kafka as a serverless platform?
Yes. Confluent delivers Kafka serverlessly as part of Confluent Cloud. The platform offers fully managed, serverless Kafka with enterprise-grade features such as built-in security, governance, global availability, and a rich ecosystem of connectors—allowing teams to run Kafka in production without managing infrastructure.