New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
COMPARATIF
Confluent Cloud vs Amazon MSK: Apache Kafka® – coûts et fonctionnalités
Pour tirer pleinement parti de la valeur d'Apache Kafka®, vous aurez besoin de ressources d'ingénierie dédiées et d'une expertise en matière de systèmes distribués. Plus votre empreinte s'élargit, plus Kafka en interne devient ingérable : vous vous retrouvez à devoir choisir entre des clusters surprovisionnés peu rentables, ou des temps d'indisponibilité imprévus.
Cette analyse détaillée de Confluent Cloud et d'Amazon MSK mettra en évidence leurs fonctionnalités respectives en termes d’évolutivité, de résilience et de fonctionnalités de plateforme. Elle montrera également comment Confluent permet de réduire le coût total de possession de Kafka géré en interne de 40 à 70 %.
Jusqu'à 70 % d'efficacité en plus par rapport à Apache Kafka® self-managed et hébergé
Que vous développiez des pipelines de données en temps réel ou des agents IA, Kafka est la solution optimale. Sa conception distribuée permet de gérer des charges de travail à haut débit et à faible latence, tout en nécessitant une expertise pointue pour assurer sa gestion, sa sécurisation et son optimisation à grande échelle, sans surprovisionnement coûteux ni risque de panne.
Fondé par les co-créateurs originaux de Kafka, Confluent a investi 3 millions d’heures d’ingénierie dans la refonte de Kafka afin d’améliorer son efficacité de 70 % dans le cloud. Le résultat : Kora, le moteur Kafka cloud native qui alimente notre plateforme de streaming de données entièrement gérée avec :
-
Des clusters sans serveur avec scalabilité automatique qui permettent d'économiser plus de 50 % de vos coûts d'infrastructure
-
3x plus d’efficacité en termes de ressources qu’un cluster self-managed à un seul tenant
-
Latence des clusters réduite de 50 % par rapport à une gestion autonome, pour une utilisation optimisée
-
Optimisation du routage et des intégrations API pour une réduction des dépenses réseau
Aujourd’hui, Kora alimente 30 000 clusters Confluent Cloud qui traitent plus de 3 000 milliards de messages par jour sur AWS, Google Cloud et Microsoft Azure.
S’inscrire au webinar sur les coûts liés à Kafka
Migration MSK Zookeeper : transformer une mise à jour critique en avantage stratégique
Avec la fin du support de ZooKeeper par Kafka prévue en mai 2026, tous les utilisateurs de Kafka qui utilisent un cluster basé sur Zookeeper doivent procéder à une migration complète vers KRaft afin d’éviter d’utiliser des versions obsolètes de Kafka.
Qu’est-ce que cela signifie pour les clients de MSK ?
-
Vos clusters basés sur Zookeeper ne recevront plus les mises à jour critiques (notamment les correctifs de sécurité et les corrections de bugs) de la communauté open source. Cela signifie que les clients MSK utiliseront une version autogérée de Kafka, susceptible de présenter des problèmes de sécurité et de gestion.
-
MSK ne prend pas en charge les mises à niveau sur place (in-place) : les clients MSK doivent mettre en place un nouveau cluster compatible KRaft et migrer manuellement les données et les charges de travail.
-
La migration vers MSK Express n’est pas sans difficulté : le passage de MSK Provisioned Standard à MSK Express nécessite également des efforts supplémentaires.
Pourquoi migrer vers Confluent ?
Cette migration indispensable est le moment idéal pour réévaluer la situation. Pourquoi effectuer un travail fastidieux juste pour conserver un service de base ? Migrez vers une plateforme de streaming de données entièrement gérée et profitez de toutes ses fonctionnalités avancées et des économies réalisées !
-
Entièrement géré et cloud-native : automatise l’ensemble du cycle de vie de Kafka (provisionnement, mises à niveau, mise à l’échelle et équilibrage des partitions) afin que les utilisateurs puissent se concentrer sur les applications plutôt que sur les opérations.
-
Assistance supérieure : offre une assistance Kafka spécialisée et directe, ainsi qu’un SLA de 99,99 % couvrant l’ensemble de la plateforme de streaming, ce qui est 10 fois meilleur que MSK
-
Intégrations et écosystème riches : fournit la plus grande bibliothèque de connecteurs gérés, comprenant davantage d’intégrations de services AWS et la prise en charge de solutions multicloud et SaaS.
-
Gouvernance des données : offre une suite complète de fonctionnalités de gouvernance telles que Schema Registry, qui garantit la qualité et la cohérence des données, ainsi qu’une source centrale fiable pour tous vos flux de données.
-
Omniprésent : prend en charge les déploiements multi-cloud sur AWS, Azure et Google Cloud, ainsi que les architectures hybrides qui couvrent les environnements cloud et sur site.
-
Économies sur le coût total de possession : en migrant vers Confluent Cloud et en tirant parti de fonctionnalités telles que PNI (Private Network Interface) et la mise à l'échelle automatique, Confluent garantit un prix égal ou inférieur à celui d’AWS MSK
« [Grâce à Confluent,] nous avons réduit nos dépenses annuelles prévisionnelles de 69 %. Nous avons aussi [économisé] plusieurs mois de planification qui auraient été consacrés à des réunions et à des projections saisonnières. »
Justin Dempsey, Senior Manager chez SAS Cloud
« Depuis que nous avons développé Horus, notre plateforme mondiale de scan IPV4, sur Confluent, nous avons économisé plus d’un million de dollars par rapport à Kafka ou MSK open source. »
Jared Smith, Senior Director, Threat Intelligence chez SecurityScorecard
« Confluent nous offre une véritable élasticité, qui est essentielle pour faire face à la forte demande lors d’événements commerciaux majeurs tels que le Black Friday ou lors de la signature de nouveaux contrats avec de gros clients, tout en nous permettant de bénéficier d'un SLA plus élevé. »
Ian Compton, Technology Director chez RevLifter
Coût de possession de Kafka – MSK vs Confluent
Plus votre adoption de Kafka en interne se développe, plus votre équipe devra consacrer de temps et de ressources aux tâches suivantes :
-
Planification, dimensionnement et gestion de la mise à disposition des clusters
-
Correctifs et mise à niveau des logiciels
-
Conception et planification du failover pour garantir la disponibilité
-
Combler les lacunes en matière de gouvernance et de sécurité à haut risque
-
Planification et optimisation pour assurer la fiabilité
-
Répartition de charge manuelle
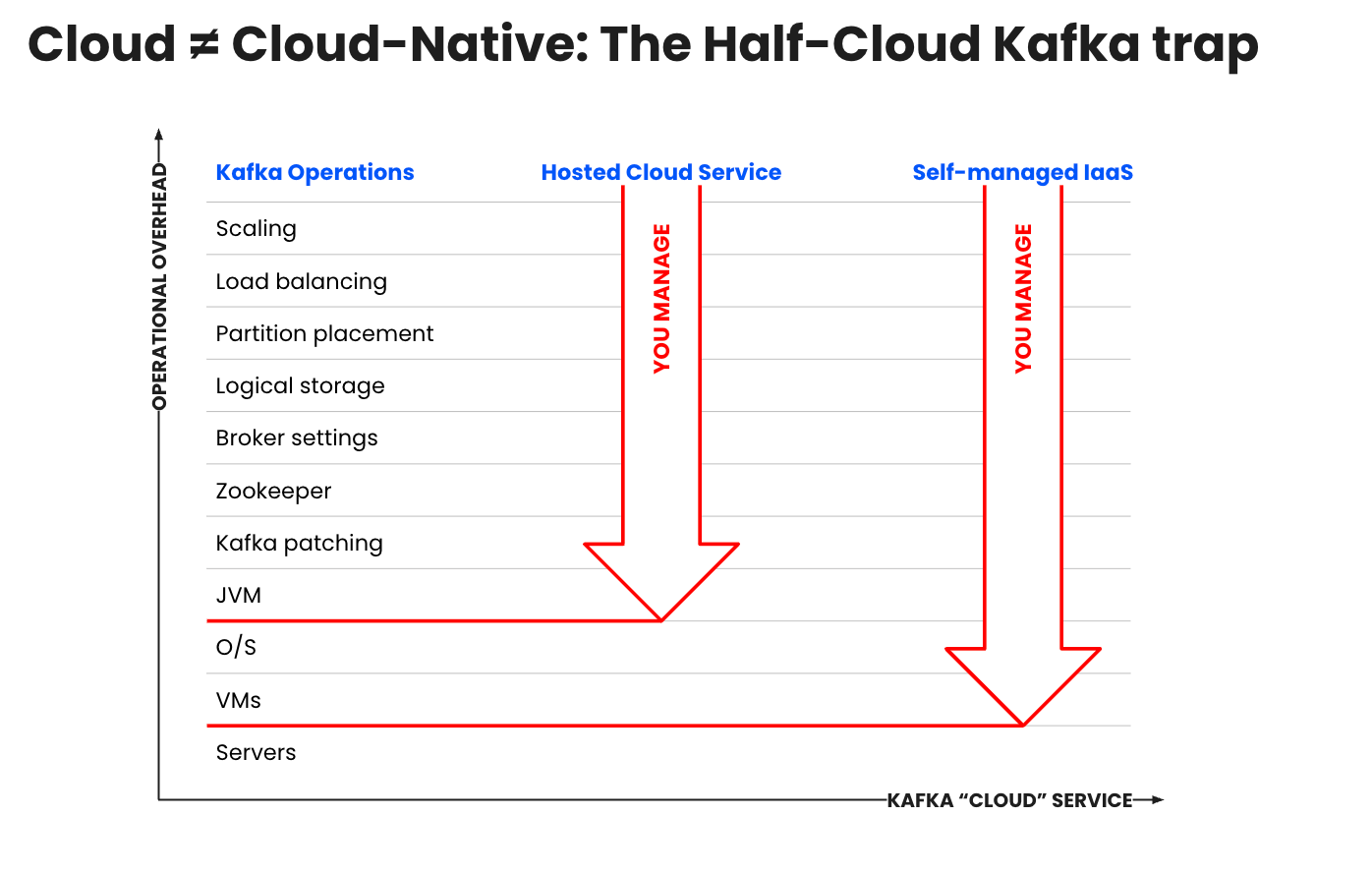
Maximiser la valeur de Kafka implique des coûts élevés, tant financiers qu’en termes d’opportunités : en moyenne, il faut plus de deux ans pour atteindre une production à grande échelle et compter entre 3 et 5 millions de dollars de coûts de développement et d’exploitation de la plateforme. Confluent Cloud et Amazon MSK promettent tous deux de vous libérer de cette charge opérationnelle. Cependant, les services Kafka « gérés » ne sont pas tous identiques, et vous ne déchargerez pas vos équipes de toutes les tâches fastidieuses simplement en optant pour Kafka hébergé auprès de votre fournisseur cloud.
Dans cette comparaison des services Kafka gérés, découvrez tout ce que vous pouvez faire (et économiser) grâce à une version de Kafka véritablement gérée et sans serveur, ainsi qu’à une plateforme de streaming de données offrant un retour sur investissement de 257 %, avec un amortissement en moins de 6 mois.
Essayer gratuitement Confluent Cloud
| Confluent Cloud | Amazon MSK | |
|---|---|---|
| Résumé | Confluent élimine la plupart des opérations manuelles grâce à ses capacités automatisées de mise à l’échelle des clusters Kafka et des instances de connecteurs. | Votre charge opérationnelle reste élevée, car Amazon MSK offre des capacités d'automatisation limitées pour les tâches de déploiement, même pour les clusters MSK Serverless |
| Fonctionnalités automatisées des produits vs opérations manuelles et développement sur mesure |
Self-managed :
Automatisé sur tous les clusters :
Sur mesure :
*Sur tous les clusters Confluent Cloud |
Self-managed :
Sur mesure :
Automatisé :
*Uniquement sur les clusters MSK Serverless |
| Liberté de choix | Disponible sur AWS, Google Cloud et Microsoft Azure | Disponible uniquement sur AWS |
Gestion, surveillance et maintenance sur Confluent Cloud par rapport à Amazon MSK
Bien que MSK comble certaines lacunes opérationnelles, il présente encore de nombreuses limites. L’autogestion ou l’utilisation de Kafka hébergé entraîne des coûts directs et indirects importants, notamment :
- Coûts d’infrastructure élevés liés aux clusters surdimensionnés : surdimensionnement nécessaire pour répondre à une demande fluctuante, impossibilité de faire évoluer le stockage sans augmenter la puissance de calcul, dégradations des performances due aux configurations manuelles, au rééquilibrage, aux mises à niveau et aux correctifs.
-
Frais généraux opérationnels et ressources limitées : temps et ressources consacrés à l’approvisionnement et à la planification des capacités, aux mises à niveau et à la surveillance, plutôt qu'à la différenciation de l’entreprise ; coûts liés au recrutement, au recrutement et à la fidélisation des talents Kafka.
-
Pannes imprévues : les risques de temps d’arrêt coûteux et de failles de sécurité augmentent à mesure que Kafka couvre davantage de cas d’usage, d’applications et de systèmes de données, d’équipes et d’environnements
Ces coûts ne font que s’accumuler, ce qui retarde la rentabilisation, augmente le coût total de possession et accroît le risque de perte de revenus en raison de temps d’arrêt imprévus, de fuites de sécurité et de pertes de données.
Voyons comment Confluent Cloud et Amazon MSK différent en termes de réduction de la charge opérationnelle et de résolution des défis courants liés à Kafka.
Lire le livre blanc Kafka vs Confluent vs MSK
| Service | Confluent Cloud | Amazon MSK | MSK Serverless |
|---|---|---|---|
| Provisionnement | Libre-service, à la demande pour Kafka, Schema Registry et Flink | Libre-service, à la demande pour Kafka uniquement | Libre-service, à la demande pour Kafka uniquement |
| Mise à l'échelle automatique | Clusters sans serveur et à dimensionnement automatique, adaptés à toutes les charges de travail | Mise à l’échelle manuelle | Scalabilité élastique plafonnée à un quota limité (200/400 Mbps) |
| Types de clusters | Clusters flexibles et économiques pour toutes les charges de travail et tous les cas d’usage | Clusters standard et express, qui nécessitent tous deux une mise à l'échelle manuelle | Les clusters MSK Serverless sont des clusters préprovisionnés par MSK, adaptés aux charges de travail imprévisibles et critiques |
| Infrastructure en tant que code | Pour le plan de contrôle et le plan de données | Pour le plan de contrôle uniquement | Pour le plan de contrôle uniquement |
| Surveillance de l'infrastructure | Surveillance proactive | Surveillance manuelle | Surveillance proactive |
| Surveillance des topics | Indicateurs gratuits et pré-agrégés | Les indicateurs au niveau des topics entraînent des coûts supplémentaires | La surveillance par défaut est gratuite |
| Mises à niveau | Toujours la dernière version stable | Compatibilité limitée | Compatibilité limitée |
| Correctifs logiciels | Correctifs proactifs | Corrections réactives | Corrections réactives |
| Expansions de clusters | Grande évolutivité | Rééquilibrage manuel des données | Grande évolutivité |
| Connecteurs de dimensionnement | Prédéfinis et entièrement gérés | Développés et gérés en interne | Développés et gérés en interne |
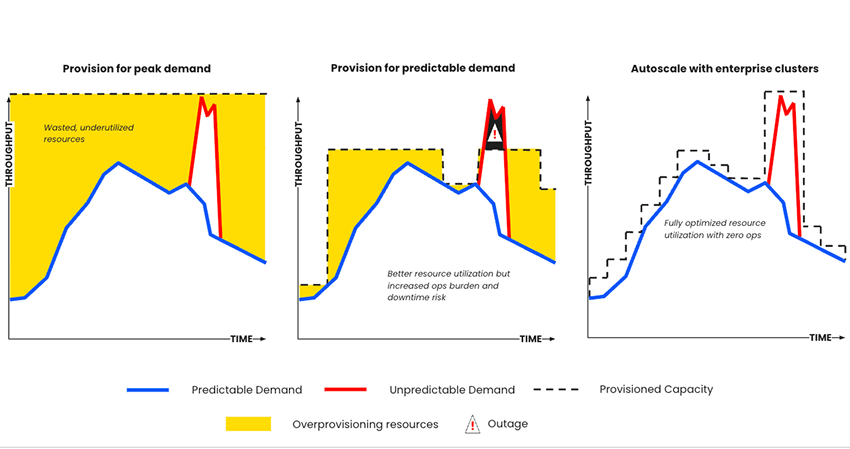
Comment Confluent Cloud et Amazon MSK simplifient-ils le dimensionnement des clusters ?
-
Confluent Cloud utilise un dimensionnement basé sur le débit : cela élimine les tests de performances fastidieux et réduit les coûts d’infrastructure grâce à des clusters élastiques, qui s’adaptent à votre charge et se mettent à zéro lorsqu’ils ne sont pas utilisés.
-
MSK Provisioned utilise un dimensionnement basé sur les brokers : vous devez consacrer du temps et des ressources à l’exécution de tests de performances afin de choisir les types de brokers, de compter et de surprovisionner l’infrastructure pour réduire le besoin d’extensions complexes ultérieures en raison des limitations de l’autoscaling (quatre opérations par jour).
-
MSK Serverless utilise un dimensionnement basé sur le débit : provisionnez des clusters Kafka avec Glue Schema Registry et Flink. Les connecteurs et le proxy Kafka requièrent des efforts personnalisés.
Comment Confluent Cloud ou Amazon MSK automatisent-ils le provisionnement et la gestion ?
-
Confluent Cloud offre un provisionnement en libre-service et à la demande pour l’ensemble de la plateforme : provisionnez des clusters Kafka ainsi que tout autre composant Confluent Cloud, y compris Schema Registry, Connect et Confluent Cloud pour Apache Flink®. Vous pouvez également utiliser le fournisseur Terraform pour automatiser la gestion des ressources du plan de contrôle, telles que les clusters et Schema Registry, et des ressources du plan de données, telles que les topics et les ACL.
-
Amazon MSK offre un provisionnement à la demande en libre-service, mais uniquement pour Kafka : provisionnez des clusters Kafka avec Glue Schema Registry et Flink. Des efforts personnalisés sont nécessaires pour les connecteurs et le proxy Kafka pour MSK Provision et MSK Serverless. Terraform ne peut déployer et gérer que les ressources du plan de contrôle. Vous devez créer des opérateurs et des processus personnalisés pour gérer les ressources du plan de données.
Confluent Cloud ou Amazon MSK offrent-ils une surveillance prête à l’emploi ?
-
Confluent Cloud offre une surveillance proactive de l’infrastructure et des métriques agrégées gratuitement pour la surveillance des topics. Consacrez-vous au développement de nouvelles applications grâce à la surveillance et à la maintenance proactives des clusters par les experts Kafka. Infinite Storage permet des cas d’usage illimités du stockage au niveau du cluster tout en réduisant le risque de pannes liées à l’espace disque. L’accès aux principales métriques pré-agrégées au niveau des topics et des clusters est disponible sans frais supplémentaires. De plus, vous pouvez intégrer ces métriques avec l'outil de surveillance tiers de votre choix à l’aide de l’API Metrics.
-
MSK Provisioned propose une surveillance manuelle de l’infrastructure et des métriques au niveau des topics moyennant un coût supplémentaire. Affectez des ressources à la surveillance des indicateurs liés aux brokers (tels que l’utilisation du processeur) afin de gérer de manière proactive les performances du cluster. Surveillez et créez des alertes pour l’espace disque afin d’éviter les défaillances dues à la capacité de stockage. Payez à l’utilisation et agrégez manuellement les métriques par broker et par topic afin de surveiller l’utilisation globale.
-
Les clusters MSK Serverless bénéficient d’une surveillance proactive de l’infrastructure et d’une surveillance gratuite des topics par défaut : concentrez-vous sur le développement d’applications grâce à la surveillance et à la maintenance proactives des clusters. Infinite Storage permet des cas d’utilisation illimités du stockage au niveau des clusters tout en réduisant le risque de pannes liées à l’espace disque. Et accédez gratuitement aux métriques au niveau des topics à l’aide de la console CloudWatch, un outil permettant de surveiller plusieurs produits AWS ; n’inclut pas les indicateurs au niveau des partitions, ni l’intégration native avec des outils de surveillance populaires tels que Datadog et Dynatrace.
Comment la maintenance de Kafka est-elle gérée sur Confluent Cloud par rapport à Amazon MSK ?
-
Confluent Cloud est toujours mis à jour vers la dernière version stable et les bogues et vulnérabilités sont corrigés de manière proactive. Il offre un SLA de 99,99 % comprenant Kafka, les corrections de bogues, les correctifs et bien plus encore.
-
Amazon MSK offre une prise en charge limitée des versions et des correctifs réactifs : MSK ne prend en charge qu’un sous-ensemble des versions de Kafka, et vous devez déclencher manuellement les mises à niveau une fois qu’AWS a ajouté la prise en charge après la sortie prévue d’Apache. MSK offre un SLA de 99,9 % et ne propose que certaines versions de Kafka. Les pannes dues au logiciel Kafka ne sont pas couvertes par les SLA de disponibilité de MSK. Le fait de prendre en charge un sous-ensemble de versions oblige à corriger les vulnérabilités de manière réactive. Les clusters MSK Serverless ne nécessitent aucune intervention dans le cadre de mises à niveau progressives sans interruption. MSK ne prend en charge qu’un sous-ensemble de versions Kafka et la dernière version est inconnue et entièrement abstraite.
Comment Confluent Cloud et Amazon MSK étendent-ils et réduisent-ils les clusters ?
-
Confluent Cloud adapte automatiquement la taille de votre cluster et répartit automatiquement les ressources : Confluent gère la latence des consumers même lorsque le débit varie dynamiquement, jusqu’à plusieurs Go/s, grâce à des clusters entièrement élastiques et auto-adaptables qui vous permettent d’économiser plus de 50 % sur vos coûts d’infrastructure. Éliminez le surprovisionnement informatique des clusters et définissez vos propres limites de rétention avec un stockage illimité.
-
Amazon MSK nécessite un rééquilibrage manuel des données pour les clusters provisionnés ainsi que des connecteurs développés et gérés en interne : un processus de rééquilibrage manuel des données est nécessaire à l’aide de Cruise Control après l’ajout de brokers à un cluster. Le stockage hiérarchisé est disponible, mais nécessite toujours des volumes EBS pouvant être étendus jusqu’à 16 To par broker, avec une limite de 30 brokers. Tirez parti des connecteurs développés en interne ou par la communauté, sans assistance technique de la part d’AWS car seule l’infrastructure MSK Connect sous-jacente est incluse.
-
Les clusters MSK Serverless offrent une évolutivité élastique avec des quotas limités et requièrent encore des connecteurs développés et gérés en interne : la scalabilité automatique de 0 à 200 , combinée au rééquilibrage des clusters, empêche le surprovisionnement des clusters lorsque la rétention des topics est étendue avec Infinite Storage.
Plateforme complète de streaming de données Confluent vs Kafka hébergé sur AWS
Pourquoi Confluent est-il plébiscité dans tous les secteurs ? Confluent offre des fonctionnalités professionnelles qui vont bien au-delà de celles proposées par MSK afin de fournir une plateforme complète de streaming de données, vous permettant ainsi de bénéficier d’innombrables cas d’usage.

| Service | Confluent Cloud | Amazon MSK | MSK Serverless |
|---|---|---|---|
| Kafka UI | Entièrement géré | Non disponible | Non disponible |
| Authentification | Authentification étendue | Authentification étendue | Authentification limitée |
| Chiffrement | Chiffrement de bout en bout | Non pris en charge | Non pris en charge |
| Connecteurs | Préconfigurés et entièrement gérés | Conçus en interne et self-managed | Conçus en interne et self-managed |
| Gouvernance des données | Entièrement géré | Non disponible | Non disponible |
| Stream Processing | Entièrement géré | Ajoute des complexités | Ajoute des complexités |
| Zero-ETL pour les flux vers les tables | Désormais disponible avec Tableflow | Non disponible | Non disponible |
Quelles sont les fonctionnalités de sécurité adaptées aux entreprises offertes par Confluent Cloud et Amazon MSK ?
-
Confluent Cloud prend en charge une large gamme d’authentifications pour tous les types de clusters : seuls les clients authentifiés sont autorisés à accéder à un cluster. Confluent Cloud prend en charge SASL/PLAIN et SASL/OAUTHBEARER (en préversion) comme mécanismes d’authentification. Avec Confluent Cloud, le chiffrement des champs côté client assure une protection supplémentaire : les données sensibles sont chiffrées dès le client, sécurisées sur le client comme sur le serveur, et protégées pendant leur transit entre les mécanismes des producers et des consumers.
-
Amazon MSK prend en charge l’authentification étendue pour les clusters MSK Provisioned, l’authentification limitée pour MSK Serverless, et ne prend pas en charge le chiffrement : tous les clusters MSK autorisent uniquement l’accès authentifié, mais les clusters MSK Provisioned prennent en charge SASL/SCRAM, mTLS et IAM comme mécanismes d’authentification, tandis que les clusters MSK Serverless prennent uniquement en charge IAM comme mécanisme d’authentification.
Quels types de connecteurs Kafka Confluent Cloud et Amazon MSK proposent-ils ?
-
Confluent Cloud propose plus de120 connecteurs préconfigurés et plus de 80 connecteurs entièrement gérés : Intégrez Confluent facilement et de manière transparente à des services modernes et hérités, sur site et dans les environnements cloud publics, grâce à un portefeuille en constante expansion de plus de 120 connecteurs disponibles sous forme de composants entièrement gérés ou préconfigurés, et pris en charge par l’assistance Confluent.
-
Amazon MSK prend uniquement en charge les connecteurs personnalisés et autogérés : intégrez Kafka à vos services de données avec la possibilité de créer vos propres connecteurs ou de déployer à partir d’un petit sous-ensemble de connecteurs développés par la communauté Kafka. Les connecteurs personnalisés nécessitent une maintenance et les connecteurs de la communauté Kafka ne sont pas couverts par le support technique AWS.
Quelles sont les capacités de gouvernance offertes par Confluent Cloud et Amazon MSK ?
-
Confluent Cloud propose Stream Governance, une suite de services entièrement gérée qui assure la disponibilité, l’intégrité et la sécurité des données : Stream Governance repose sur trois piliers stratégiques clés : Stream Lineage, Stream Catalog et Stream Quality. Les règles de qualité des données garantissent des flux de haute qualité.
-
Amazon MSK nécessite l’utilisation d’outils communautaires gratuits sans assistance ou d’outils tiers payants pour gérer les données dans les topics Kafka : MSK ne dispose pas de fonctionnalités de traçabilité ou de catalogage. Pour la qualité des données, MSK et MSK Serverless s’intègrent à Confluent et Glue Schema Registry. Cependant, ils ne disposent pas de la validation de schéma côté broker, qui oblige les producers de données à utiliser Schema Registry pour contrôler l’évolution des schémas, Data Quality Rules pour valider et contraindre les valeurs des champs individuels dans un flux de données, et Schema Linking pour synchroniser les schémas entre différents environnements.
Quelles sont les capacités de traitement des flux offertes par Confluent Cloud et Amazon MSK ?
-
Confluent propose un traitement des flux sans serveur avec Confluent Cloud pour Apache Flink® : il suffit aux utilisateurs de créer un cluster Flink et de se lancer dans le traitement des flux à l’aide d’un langage de type SQL. Confluent Cloud prend également en charge le service AWS Lambda entièrement géré.
-
Amazon MSK propose le traitement des flux avec Flink, mais avec des complexités supplémentaires : MSK prend en charge Managed Service for Apache Flink (MSF), qui est puissant mais ajoute des complexités. Les utilisateurs doivent en effet configurer le réseau, créer un notebook MSF Studio, rédiger la tâche à l’aide d’une syntaxe de type SQL, tester le code, le packager, l’importer vers S3 et créer une application MSF à partir du code importé.
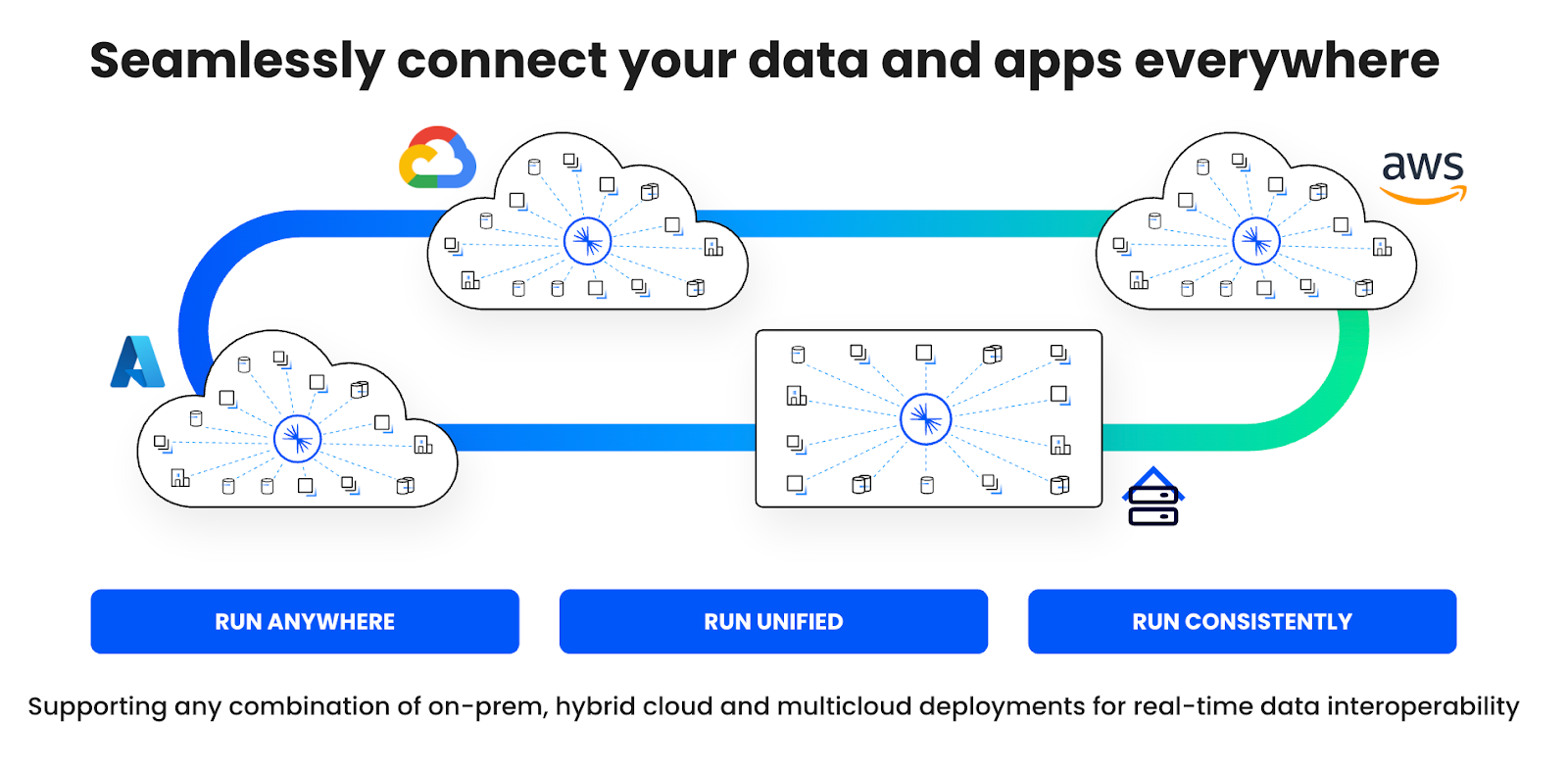
Hybride et multicloud avec Confluent vs verrouillage fournisseur sur AWS
Développez à grande échelle grâce au streaming de données cloud native, le tout sans dépendre d'un fournisseur cloud unique. Contrairement à Amazon MSK (disponible uniquement sur AWS), Confluent vous offre une véritable flexibilité de déploiement pour prendre en charge n’importe quelle combinaison d’architectures sur site, hybrides et multicloud pour une interopérabilité transparente des données :
-
Service cohérent et entièrement géré sur AWS, Microsoft Azure et Google Cloud
-
Streaming de données cloud native et self-managed avec Confluent Platform
-
Contrôle et rentabilité avec WarpStream BYOC
De plus, Cluster Linking permet de synchroniser les données en continu entre tous types d'environnements en temps réel.
Obtenez une estimation personnalisée des économies de coûts
Obtenez une comparaison personnalisée des coûts pour voir les économies que vous pouvez réaliser en utilisant Confluent Cloud plutôt qu'Amazon MSK. Remplissez le formulaire de contact avec vos coordonnées, et un membre de notre équipe vous contactera pour vous aider à mesurer les économies possibles avec Confluent et répondre à vos questions.
Vous n’êtes pas prêt à parler à un commercial ? Découvrez les ressources sur le sujet :
Confluent Cloud vs. Amazon MSK: FAQs
Is Confluent Cloud more cost-effective than Amazon MSK?
Yes, Confluent Cloud is more cost-effective than Amazon MSK because of cost savings from:
-
Reduced infrastructure costs: Confluent Cloud’s serverless, cloud-native architecture eliminates the need for over-provisioning that is common with MSK’s node-based pricing. Features like Infinite Storage and Tiered Storage decouple compute and storage, further reducing infrastructure spending. For example, SecurityScorecard saved over $1M in infrastructure and operational costs by migrating to Confluent Cloud
-
Lower operational overhead: Offloading complex and time-consuming operational tasks—such as capacity management, scaling, and upgrades—to Confluent Cloud allows you to reallocate valuable engineering resources to innovation instead of infrastructure management. One customer reported they would have needed to hire at least 10 more people to manage Kafka themselves.
-
Minimized downtime and risk: Confluent Cloud offers a 99.99% uptime SLA for production workloads. Compared to MSK (with a 99.9% SLA with exclusions for Kafka failures and customer configuration failures), Confluent’s SLA delivers higher reliability and reduces the substantial hidden costs associated with downtime.
Choosing Confluent Cloud can reduce your self-managed Kafka costs by 40-70%.
What are the main cost drivers of Confluent Cloud vs Amazon MSK?
The main cost drivers of Confluent Cloud are:
-
Usage based consumption: Confluent Cloud’s pay-as-you-go pricing is based on actual usage (e.g., throughput) rather than provisioned infrastructure. This pay-as-you-go model eliminates the need for over-provisioned, underutilized clusters that typically lead double the infrastructure costs for self-managed Kafka vs fully managed on Confluent.
-
Managed horizontal scaling: Elastic Confluent Units for Kafka (eCKUs) are a Confluent Cloud’s unit of horizontal scalability for billing. eCKUs autoscale up and down based on workload. The cost includes the complete management of the platform, from infrastructure and scaling to monitoring and support, which is designed to reduce or eliminate the separate operational and support costs customers would otherwise incur.
The main cost drivers of Amazon MSK are:
-
Higher infrastructure spend: MSK uses node-based pricing, requiring users to pay for provisioned compute and storage, which often leads to over-provisioning to handle peak loads. Networking, particularly cross-Availability Zone (cross-AZ) traffic, can also become a significant hidden cost, sometimes accounting for 80-90% of total infrastructure expenses.
-
Self-managed operations and management: Since MSK is not a fully managed Kafka service, significant engineering resources are required for manual tasks like sizing, scaling, rebalancing partitions, patching, and monitoring. This includes the cost of hiring and retaining specialized Kafka talent.
-
Custom development and maintenance: MSK requires significant custom platform development and maintenance, which can take 2+ years to bring to production and cost $3-5M or more in costs. Because MSK is a hosted service rather than a complete platform with essential components included out-of-the-box, engineering teams must spend valuable time and resources building and maintaining their own solutions for developer tools, DevOps automation, infrastructure enhancements for reliability and disaster recovery, monitoring, integration, security controls, and governance.
-
Unplanned downtime and higher business risk: MSK's 99.9% SLA excludes failures in the underlying Kafka software, as well as failures due to customer errors in configuration, leaving customers responsible for resolving failures that can easily turn into major outages. The risk of outages due to storage limitations, manual scaling errors, or unresolved bugs can lead to substantial hidden costs, including lost revenue and reputational damage.
What are the pros and cons of MSK Serverless vs Confluent Cloud?
Confluent Cloud pros and cons include:
-
Pro: Confluent Cloud offers a complete, serverless experience that automates all operational aspects, from capacity planning and elastic scaling (to GBps+) to upgrades and monitoring.
-
Pro: Confluent Cloud goes far beyond core Kafka, providing a rich ecosystem of 120+ connectors, serverless Flink for advanced stream processing, and an enterprise-grade Stream Governance suite.
-
Pro: Confluent Cloud delivers significant cost savings through cost-efficient autoscaling and usage-based consumption (which prevents overprovisioned and underutilized clusters and cuts infrastructure costs by 50%+), lowers TCO 40-70% compared to self-managed Kafka by eliminating $1M in development and operations costs over 3 years, and with a 99.99% uptime SLA that reduces business risk.
-
Con: For smaller teams, projects with predictable workloads, or organizations that already have in-house Kafka expertise, Confluent's fully managed service and advanced features may not present a clear upfront financial advantage.
MSK Serverless pros and cons include:
-
Pro: MSK Serverless addresses some of MSK's operational challenges with pre-provisioning
-
Pro: MSK Serverless can elastically scale to a given quota without the need for manual rebalancing.
-
Pro: MSK Serverless offers unlimited storage (with a per-partition quota) without the manual configuration required by MSK Standard brokers.
-
Con: MSK Serverless has a strict throughput limit of 200MBps ingress and 400MBps egress, with no upgrade path for workloads that exceed this.
-
Con: MSK Serverless lack many mission-critical components, including a rich connector ecosystem, integrated stream processing (like Flink), and comprehensive, enterprise-grade security and governance tools.
-
Con: MSK Serverless has the same weak 99.9% SLA as MSK Provisioned, which does not cover Kafka-related failures.
-
Con: Like all MSK offerings, MSK Serverless has no multicloud support and is locked into the AWS ecosystem.
How does Confluent Cloud autoscale throughput compared to MSK?
Confluent Cloud offers true elastic, automated scaling from 0 to GBps, while Amazon MSK's elastic scaling capabilities are more limited and manual:
-
Confluent Cloud provides fully managed, automated, and elastic scaling. It can automatically scale clusters up and down from 0 to GBps+ to meet demand without interruption. Its cloud-native Kora engine uses an intelligent control plane and self-balancing algorithms to manage capacity, rebalance partitions, and eliminate the need for overprovisioning and underutilizing clusters to avoid outages. As a result, customers can save 50% or more on infrastructure costs.
-
Standard clusters on MSK Provisioned require manual sizing, scaling, and rebalancing. While you can add brokers to scale up, you cannot easily scale down and are more likely to have a large number of overprovisioned clusters at any given time. Modifying storage capacity can take anywhere from 6 to 24 hours. Express clusters on MSK Provisioned offer faster scaling and rebalancing, but it is still a manual process.
-
MSK Serverless offers some autoscaling but only within a lower quota limit (up to 200 MBps ingress and 400 MBps egress). There is no solution to upgrade beyond this quota without moving to a different offering.
How do Confluent and MSK differ in cluster provisioning speed?
Confluent Cloud can provision clusters in minutes, whereas provisioning an Amazon MSK cluster can take from 30 minutes to over an hour.
Is Confluent Cloud more reliable and performant than MSK?
Yes, Confluent Cloud is architected to be more reliable and performant than Amazon MSK and significantly reduces the risk of unplanned downtime compared to MSK:
-
Confluent's Kora engine provides native resilience with continuous monitoring, proactive replacement of degraded nodes, and automatic rebalancing to maintain availability without operator intervention. MSK lacks these native self-healing capabilities, requiring customers to manually identify and replace failed brokers.
-
Confluent Cloud offers a 99.99% uptime SLA that covers all components, including Kafka-related failures. This translates to a maximum of 0.876 hours of downtime per year. Amazon MSK offers a 99.9% SLA (a maximum of 8.76 hours of downtime per year), but that SLA explicitly excludes failures caused by the underlying Apache Kafka or Zookeeper software, placing the burden of resolving these critical issues on the customer and significant increasing the actual maximum hours of downtime per year MSK customers may experience.
Which platform offers stronger developer tooling, Confluent Cloud or Amazon MSK?
Confluent Cloud offers significantly stronger and more comprehensive developer tooling than Amazon MSK:
-
Confluent Cloud provides a robust Terraform provider that allows developers to manage both control plane resources (like clusters and Schema Registry) and data plane resources (such as Topics and ACLs). This enables complete automation of infrastructure deployments as code. Amazon MSK offers more limited IaC capabilities, as its Terraform support can only manage control plane resources. Managing data plane resources requires building custom operators and processes.
-
Confluent Cloud offers a rich set of APIs for point-and-click operations and automation. It also provides a user-friendly and intuitive cloud UI that allows developers to easily manage and monitor their Kafka clusters and data streams. MSK does not have a dedicated Kafka UI and developers must often build their own tools on top of MSK’s APIs. For example, MSK lacks a native REST proxy for non-Java clients, a feature available in Confluent.
-
Confluent Cloud supports multi-language client development, providing client libraries for several non-Java languages including C/C++, Go, Python, and .NET. Users can generate the necessary configuration details (including cluster credentials and API keys) directly from the Confluent Cloud Console and paste them into client application code. Amazon MSK also supports non-Java clients but enabling them to interact with MSK requires some additional work when setting up and configuring the clients for authentication and authorization.
Does Confluent Cloud offer better support than Amazon MSK?
Yes, Confluent provides customers with guidance from the world's foremost Kafka experts. Confluent was founded by the original co-creators of Kafka, and its support and professional services teams have millions of hours of Kafka experience. MSK support is limited and does not have the same depth of Kafka-specific knowledge.
What are the feature differences around connectors and schema management?
Confluent Cloud provides 120+ pre-built connectors and 80+ fully managed connectors, enabling instant integration with a wide range of popular data sources and sinks both inside and outside the AWS ecosystem. In contrast, Amazon MSK has very limited connector support. It offers fewer than 10 direct or "half-supported" integrations and primarily provides just the underlying Connect infrastructure, requiring users to bring, manage, and maintain their own connectors. This results in additional operational burden and cost. In fact, Confluent offers instant, fully managed connectivity to more native AWS services than Amazon MSK does.
Confluent Cloud includes Stream Governance, a comprehensive, fully managed suite that provides Schema Registry, Data Portal, Stream Lineage, and Data Quality Rules. With features like broker-side schema validation and the ability to tag data containing personally identifiable information (PII), your data streams are discoverable, trustworthy, and secure. Amazon MSK integrates with AWS Glue Schema Registry but lacks a full suite of governance tools, such as schema validation, data lineage, or a data catalog.
Does Confluent Cloud support multicloud deployments?
Yes, Confluent Cloud supports multicloud deployments. It is designed for both multicloud and hybrid environments, whereas Amazon MSK is an AWS-only service. Confluent customers can use its fully managed Kafka service on all three major public clouds and use its Cluster Linking feature to replicate data across clouds.