Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Introducing Confluent Platform 4.0
I am very excited to announce the general availability of Confluent Platform 4.0, the enterprise distribution of Apache Kafka 1.0. This release includes a number of significant improvements, including enhancements to Confluent Control Center, Kafka Connect, the Streams API, and of course, Apache Kafka 1.0 itself.
Looking back on the previous three major releases of the Confluent Platform, we can see a relentless drive toward enterprise-readiness in the product. In Confluent Platform 1.0, we introduced the Platform to the public with Schema Registry and REST support. In Confluent Platform 2.0, we added security features, better client support, and our first supported Kafka Connect connectors. In Confluent Platform 3.0, we added support for the Streams API and a long list of other enhancements. This trend continues uninterrupted in Confluent Platform 4.0.
We have made substantial improvements to our management and monitoring tool, Control Center. We can now support larger clusters with ease. We’ve made simple but effective user experience improvements, like a visually loud notification bar telling you when your cluster is not available. And of course we’ve invested significant resources in fixing bugs in the prior release. We think the new Control Center is something you’ll appreciate.
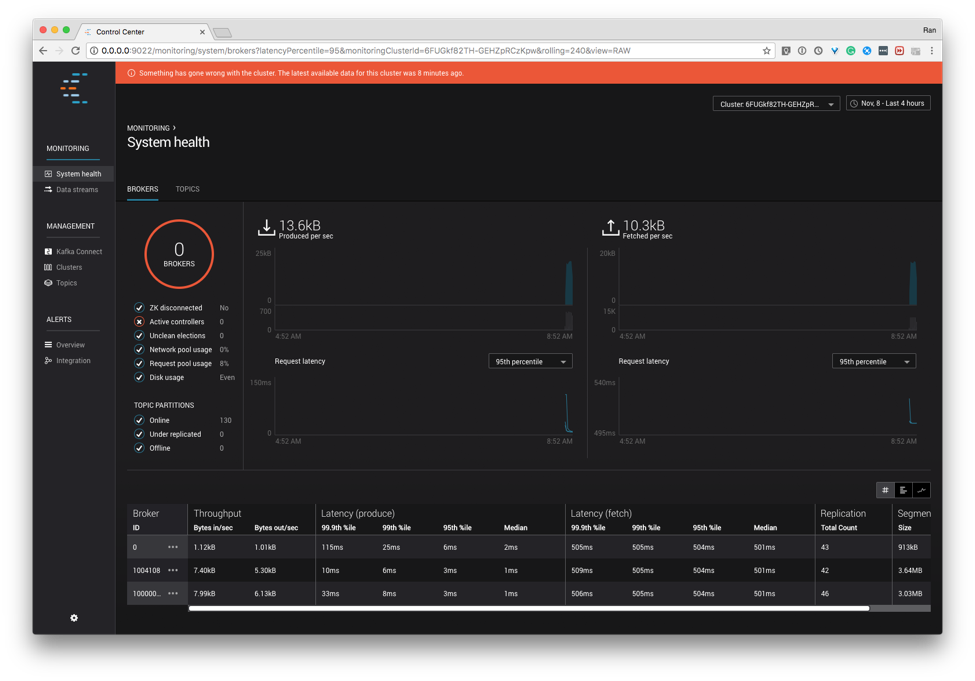
And our work in manageability has extended to Kafka Connect as well. We’ve added a ton of new metrics to better instrument the status and activity of connectors, tasks, workers, and even Connect rebalances. We’ve made connectors easier to deploy in a few ways. The connector config parameter plugin.path can now follow symbolic links. Each Connect task will use a separate converter, giving you more latitude in performance tuning. And classloader isolation now lets each connector find its own JDBC driver, when the driver is included with the connector deployment. All of these will give operators a much more pleasant experience when deploying Connect.
We’ve tuned up several of the connectors as well. The HDFS Connector has now caught up with the S3 Connector in its ability to extract timestamps from records themselves, rather than just relying on the wallclock time. And the S3 connector continues to evolve as well, growing the ability to include an optional ACL header on writes, retry partial uploads, and store BLOBs more easily using the new ByteArrayFormat formatter.
The Streams API is now a mature part of Apache Kafka and the Confluent Platform, and it has seen several improvements in this release. If you use the Processor API, you now have the option to periodically execute operations on your streams based on wall-clock time, event time, or both. (If you don’t use the Processor API, of course that’s fine, but you can read more about it here if you’re interested.) We have also built in better error handling logic for when your applications come across records that are corrupted or malformatted. For example, you can now decide that an application should skip over corrupted records. In previous versions, corrupted records triggered deserialization exceptions that would always cause application instances to fail-fast and terminate. And while using Streams means much less fuss with restoring state to application instances when a Streams application instance is re-entering a cluster (or partitions are reassigning within a cluster for any reason), we have now added the StateRestorationListener interface to let you hook the event for situations when you need to know it has happened, and what its progress is.
Last but certainly not least is Apache Kafka 1.0. I won’t repeat what Neha said so well earlier in the month about that release itself, but I will underscore that this is a critically important component that forms the foundation of the enterprise readiness of the platform. You can always check out the Apache Kafka 1.0 release notes for the full accounting of what happened in 1.0.
If you’re using the Confluent Platform, we encourage you to look at the enhancements in Streams, Connect, Control Center, and Kafka itself to see when it’s time for you to deploy this upgrade. If you’re not using the platform, there is no better time than now to check it out. 4.0 brings unprecedented levels of enterprise readiness and stability to a best-in-class platform. We excited to make this release available starting today!
If you’d like to try out 4.0 or just learn more, here are some resources for you:
- You can download the Confluent Platform
- Read the Confluent Platform 4.0 Release Notes
- Read our documentation
- Confluent Professional Services offers advice and help with deployments
- Confluent Training can get your team ready for development and deployment of the Confluent Platform
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.