Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Project Metamorphosis Month 2: Cost-Effective Apache Kafka for Use Cases Big and Small
In April, we kicked off Project Metamorphosis. Project Metamorphosis is an effort to bring the simplicity of best of breed cloud systems to the world of event streaming. It is structured as a progression of releases and launches we’re sequencing over the rest of the year to contribute new capabilities to Apache Kafka®, its ecosystem, and Confluent’s products. These releases are all organized around a single goal: bringing together event streams and the best characteristics of modern cloud data systems.
Why do this? Well, we think Kafka and event streams have become a foundational part of the modern software stack, but, if we’re honest, most people’s experience of using Kafka doesn’t live up to the standard set by modern cloud data systems. Kafka, like most distributed systems, involves lots of complexity: tuning servers, finding trained people to run it, managing Apache ZooKeeper™, and all the challenges of at-scale operations. These challenges aren’t the core problem most companies are solving and not where they want their best people focused.
Last month, we announced a set of features around elasticity. We showed how you can dynamically create Kafka clusters and expand them elastically in Confluent Cloud (or on prem in Kubernetes). We also talked about the progress that has been made on removing ZooKeeper, Kafka’s biggest bottleneck.
This month, we’re focusing on another aspect of cloud data systems: cost effectiveness. In the days of on-prem datacenters, we were often stuck guessing far in advance as to the capacity needs of our applications, and trying to overprovision capacity to avoid collapse if load happened to spike. In addition to this waste of hardware resources, we’d have to build large teams of software engineers and SREs to orchestrate, operate, and, well, babysit the complex distributed systems they hosted. We all know the result: oceans of underutilized servers, and large staffs of overworked engineers busy on the low-level upgrades, resizings, and tuning. All of this represents a continual drag of focus and money into a layer of the stack that doesn’t differentiate the business.
The cloud can change all this, but to get the benefit it isn’t enough to just shift workloads unchanged. You need to move to data systems that are fully managed, where you can pay for just what you use.
This focus is particularly important at the present moment. Shelter in place and coronavirus have simultaneously increased the importance of focusing on the digital side of the business as well as putting pressure on the budgets organizations have to deliver those digital services.
Let’s talk a bit about the feature set in Confluent Cloud to support this and what we’re announcing this month as part of this cost-effective focus.
Scaling Kafka down
Rightly or wrongly, Kafka is viewed as a “heavy-duty” component, one where you have to ask, “Do we really really need it?” and wait until you have several use cases to justify adoption. Until then people often abuse other systems or try to get by as best they can without first-class support for events in their infrastructure. This is unfortunate, and we want to change it! A log of events is a fundamentally better abstraction and the ecosystem around Kafka is phenomenal. Limiting this to only large-scale users and big tech companies does a disservice to the small apps and use cases that are often some of the best uses of the technology.
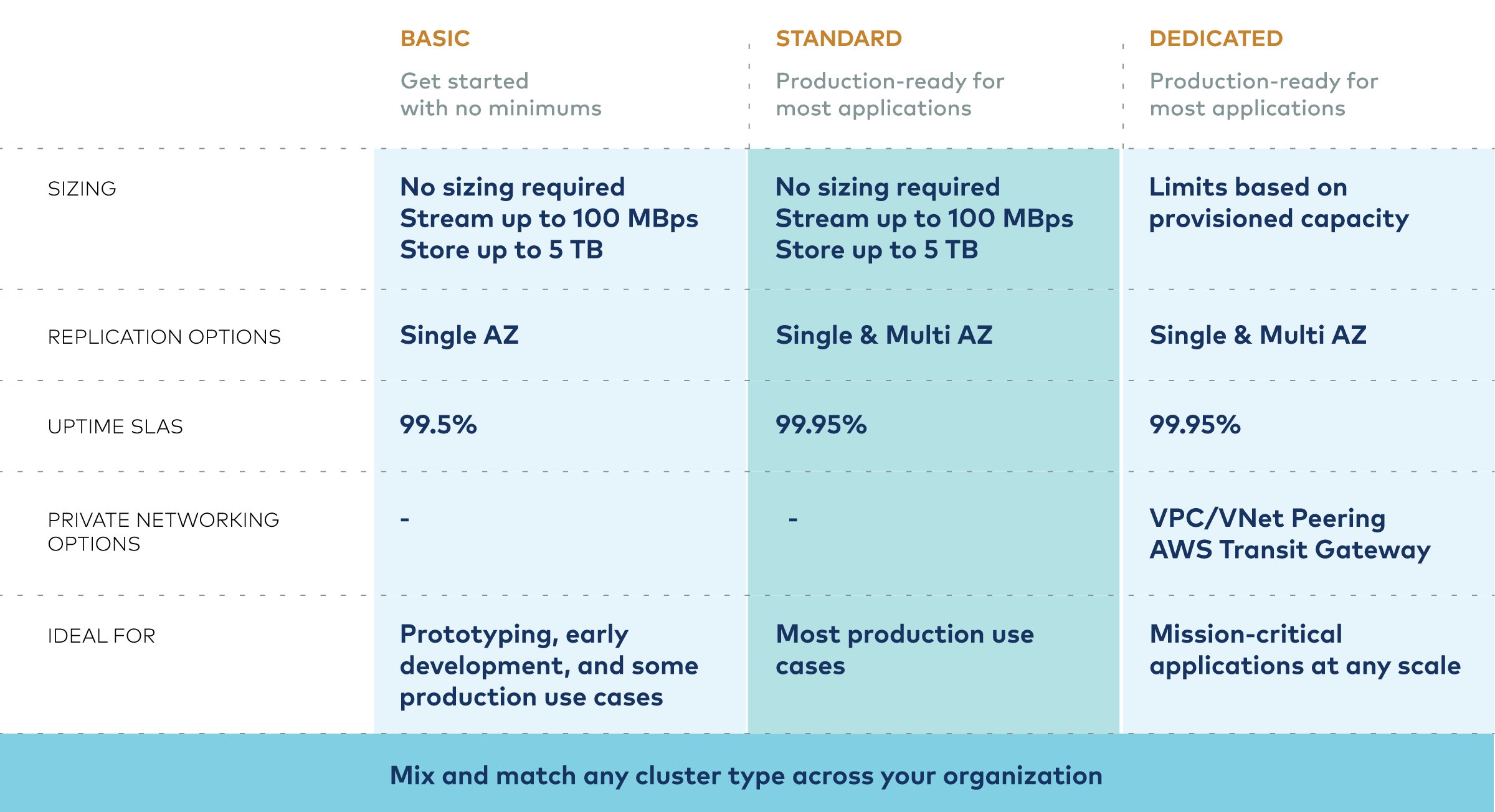
We’re changing that. We offer three types of clusters, optimized for the type of use case. Our Basic cluster type allows you to just pay for the amount of Kafka you use with no cost at all for allocating an unused cluster. This scales down to zero cost and scales up very gradually. You can literally use a few dollars a month of Kafka with no additional operational overhead. This makes Kafka a very lightweight option, at very low cost, for even the smallest of use cases. This offering is also ideal for development and test environments, even for those using Dedicated clusters for their production environments.
To make small-scale use cases even better, we’re strengthening our offerings in the following ways:
- 99.5% SLA on Basic. Our Dedicated and Standard offerings have always had a 99.95% SLA. Today we’re adding an SLA to our Basic offering as well to make this low-cost offering available for production usage.
- We’re more than quadrupling the free usage for new Confluent Cloud customers who want to try any of our offerings, taking it to $400. Since writes start at $0.11/GB, this buys quite a fair amount of usage to get you going.
- We’ve added support to pay for Confluent Cloud with Azure or Google Cloud Marketplace accounts (AWS is coming soon) so you can easily buy Confluent out of your existing cloud provider account.
Scaling Kafka up cost effectively
What about the big stuff? Running Kafka yourself at scale can be very expensive. We find organizations running on their own often have big teams, lots of hardware, and poorly tuned clusters that are either underutilized, overutilized, or both (depending on the time of day).
Confluent Cloud serves these large-scale use cases with our Dedicated cluster offering. We’ve done deep work in every part of the stack to make this offering of Kafka hyper-efficient across the major clouds. This allows us to cost effectively serve very large-scale use cases in a way that is far cheaper in the infrastructure usage than DIY open source.
Having the operations and support provided for you frees up your best people to work on the business, instead of having them managing low-level infrastructure. You still get fantastic support working hand-in-hand with your team, if there is an issue it escalates right up to the people who wrote the code.
Beyond this inherent efficiency, the elasticity we announced last month further strengthens this story. Our usage-based model means you pay for just what you use and can dynamically scale up as you need to without interrupting running applications. This means you don’t have to over-provision in fear of load spikes but can wait until you need the capacity to pay for it.
We work with customers to help them analyze their own cost of using Kafka and find that Confluent Cloud is often 60% cheaper in terms of total cost of ownership than doing it yourself. At large scale, this can often amount to savings of millions of dollars. We’re happy to work through this analysis with you, contact our Business Value Consulting Team (bvc-team@confluent.io) or your account executive to get a free personalized TCO assessment.
Kafka is an ecosystem
At the end of the day, as much as we love Kafka, it doesn’t stand alone. It’s part of a much richer ecosystem. The benefits of getting a managed version of Kafka are lost if you have to self-manage everything around it to get to a complete event streaming platform.
This is another area where Confluent Cloud shines.
We offer Kafka Connect and a growing collection of fully managed connectors. These are a huge time saver versus building custom integrations to capture event streams in Kafka. Today, we’re announcing several new connectors to add to this collection:
New connectors available for preview usage:
- MongoDB
- Snowflake
- Elasticsearch
New connectors entering general availability:
- BigQuery
- Kinesis
- Pub/Sub
- Event Hubs
Confluent Cloud offers ksqlDB as a service with all cluster types, one of our fastest-growing offerings. Using ksqlDB you can quickly and easily build streaming applications and data pipelines using simple SQL that runs continuous stream processing on top of your Kafka data streams.
That isn’t all. Confluent Cloud includes schema management using Confluent Schema Registry.
These components are all fully managed, work under the same usage-based model as Kafka, and can be used with any of our cluster types.
On premises
Our product doesn’t only make Kafka cheaper in the cloud. Though no software offering can compete with the ROI of a fully managed offering, many of the cost-saving components are available on premises as well.
Confluent Platform, our software distribution, includes a number of critical components to make self-managed Kafka as cost effective as possible, both in terms of time from operations and development staff as well as by lowering your hardware costs.
These critical capabilities include the following:
- Confluent provides over 100 supported connectors that let you integrate with the other systems to produce and consume streams of events.
- Role-Based Access Control makes it possible to share a cluster across many use cases while maintaining strict security to control data access.
- Control Center makes it easy to manage Kafka as well as the rest of Confluent Platform.
- Multi-Region Clusters streamline disaster recovery architectures by stretching a single Kafka cluster across datacenters, avoid complex recovery coordination with automated failover, and minimize the cost of downtime and data loss with an active-active configuration.
- Tiered Storage (preview) reduces infrastructure costs by enabling Kafka brokers to offload older data to inexpensive object storage. You can minimize over-provisioning by decoupling the compute and storage layers.
- Self-Balancing Clusters (coming soon) fully automate partition rebalancing to optimize Kafka’s resource utilization, minimize over-provisioning, and eliminate complex manual operations.
This advanced feature set works together to help reduce hardware needs, drive better utilization, support multi-tenant operations, and reduce the operational workload on your operations engineers. Taken together, Confluent Platform can reduce the total cost of ownership of your on-prem clusters by up to 40%.
Understanding and managing your total cost of ownership
If you are running Kafka in the public cloud and want to get an analysis of your cost of operations and the potential ROI of a managed service, we provide this analysis free of charge. Disentangling the costs specific to Kafka from a complex cloud infrastructure bill can be a bit like sorcery.
We can help you work through what your Kafka setup costs would be and how a fully managed version of Confluent Cloud would compare. Whether or not you are interested in our product, just understanding your own cost structure is a useful exercise and we can provide a number of cost-saving tips to make either approach better. This analysis takes about an hour and comes with no commitment whatsoever to buy our product or anything from Confluent.
Contact us if you’d be interested in conducting this analysis with one of our cost management experts.
To learn more, check out the Cost-Effective page dedicated to this announcement.
Further reading
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.