Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Compare
Comparing Confluent vs. Google Pub/Sub for Your Data Stack
Are you architecting a real-time data system on Google Cloud, are trying to decide between Confluent vs. Google Pub/Sub? That’s a common question customers have: "When should I use Apache Kafka® vs. a streaming platform with serverless Kafka like Confluent Cloud vs. your cloud service provider’s native solution, Google Cloud Pub/Sub?"
Although both are capable of real-time messaging, the two are not interchangable—one is a persistent, continuous integration layer and the other a rapid, elastic notification service. And in use cases like hybrid cloud integration or real-time analytics, organizations often use both in their data stack.



When Should You Choose Confluent vs. Google Pub/Sub?
Powered by a cloud-native Kafka engine, the Confluent data streaming platform (DSP) treats data as a continuous, replayable log that connects disparate systems across any environment (AWS, Azure, GCP, or on-premises). In contrast, Google Pub/Sub acts as a global messaging middleware, optimized for "fire-and-forget" simplicity and seamless integration specifically within the Google Cloud ecosystem.
Ultimately, the right choice depends on your specific workload patterns and operational philosophy. Here’s a high-level overview of the advantages of each real-time system and its ideal use cases.
Architectural Comparison Matrix – Confluent vs. Google Pub/Sub
|
Feature |
Confluent (Kafka) |
Google Pub/Sub |
|
Core Architecture |
Distributed Commit Log (Partitioned) |
Global Message Queue (Sharded) |
|
Ordering |
Strict (Guaranteed per partition) |
Best-Effort (or "Ordering Keys" with limits) |
|
Data Retention |
Persistent (Infinite / Tiered Storage) |
Ephemeral (7-31 Days Max) |
|
Delivery Model |
Pull (Consumer controls pace) |
Push or Pull |
|
Processing |
Native (Flink, Kafka Streams, ksqlDB) |
External (Dataflow / Cloud Functions) |
|
Multicloud |
Native (Unified Plane) |
GCP-Centric |
|
Use Cases |
Complex Microservice Architectures, Fraud Detection, Real-Time Personalization, Streaming Data Pipelines |
Microservice Integration, Event Ingestion, Logging & Monitoring |
Choose Confluent when you need a robust data streaming platform that acts as the definitive source of truth for your organization.
-
Strict Ordering: Essential for workloads where sequence is critical, such as financial ledgers or transaction processing.
-
Complex Stream Processing: Allows for in-flight data manipulation, such as joins and aggregations, before the data reaches storage.
-
Data Replayability: Enables the re-processing of historical data, allowing new applications to learn from past events.
-
Multicloud Portability: Decouples data from specific infrastructure, allowing consistency across AWS, Azure, and GCP.
-
Granular Control: Offers deep performance tuning capabilities for teams that understand how Kafka works and need to optimize for latency.
-
Persistent Architecture: Ideal for building a long-term event-driven architecture where data retention matters.
Choose Google Pub/Sub when your priority is lightweight service decoupling and seamless integration within the Google Cloud ecosystem.
-
Serverless Simplicity: Abstracts away partitions and clusters, removing operational overhead entirely.
-
GCP-Native Integration: The ideal "glue" for fanning out messages to services like Cloud Run, Dataflow, or Cloud Functions.
-
Massive Auto-Scaling: Automatically handles bursty or unpredictable workloads without manual provisioning.
-
Availability Over Ordering: Best for scenarios where high throughput is more critical than strict message sequencing.
-
Task Queues: Perfect for "fire-and-forget" patterns where the focus is on the destination endpoint processing the task, rather than the intelligence of the pipe.
Understanding where each technology fits within a modern data architecture will help you decide whether your workload requires the strict ordering and replayability of a log-based platform or the lightweight, serverless flexibility of a cloud-native messaging queue.
What Is Confluent and When Is It Typically Used?
At a high level, Confluent is a fully managed, Kafka-native platform designed to act as the central integration and event streaming layer for your data infrastructure. (For those who need a refresher on the underlying engine, you can review the Kafka fundamentals or Kafka architecture course on Confluent Developer to understand how the log-based architecture works.)
While open source Kafka provides the core messaging engine, Confluent wraps its cloud-native distribution in a complete set of enterprise-grade capabilities and ecosystem integrations. Confluent abstracts away the complexity of managing that engine, while also offering pre-built connectors, real-time stream processing tools, and enterprise security out of the box.
Instead of taking on significant engineering work to plug an open source component into their data estate, Confluent customers have a secure, scalable data streaming platform that runs everywhere—spanning on-premises data centers, hybrid environments, and multiple public clouds (AWS, Microsoft Azure, and Google Cloud).
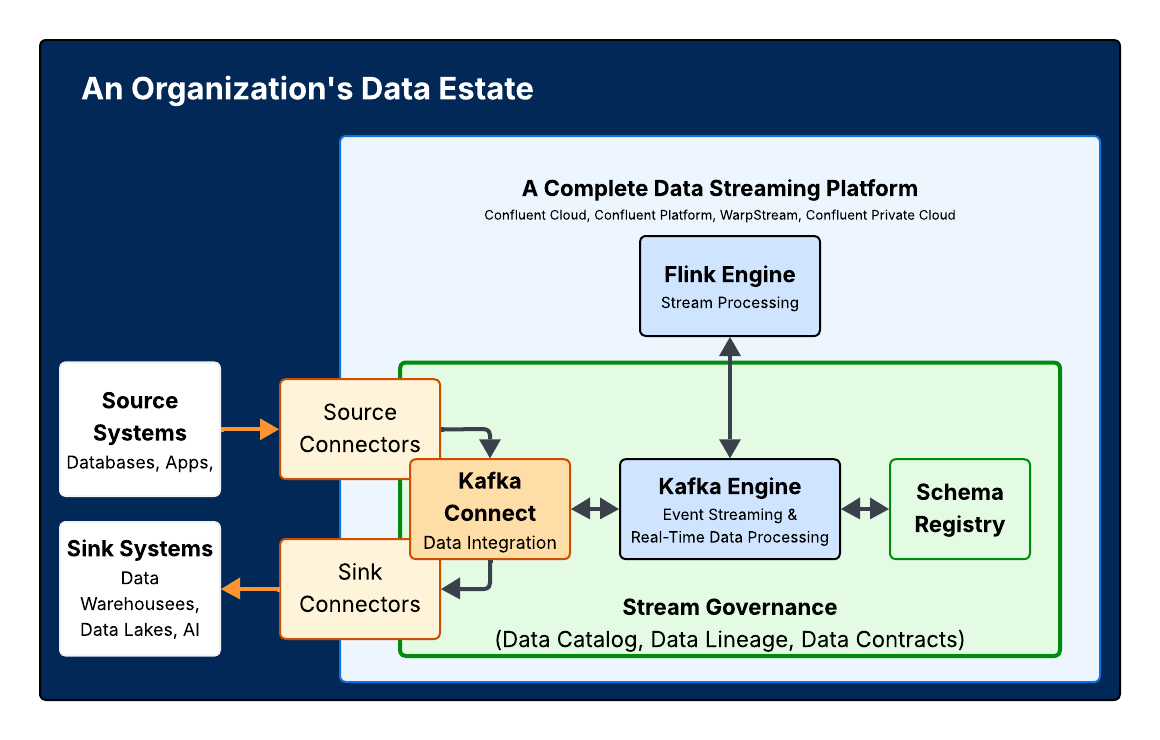
Confluent is typically used when teams need:
-
Kafka Compatibility: Seamless migration for existing Kafka applications without rewriting code
-
Streaming Maturity: Advanced stream processing (using Flink or ksqlDB) and complex event-driven architectures
- Hybrid and/or Multicloud Reliability: A consistent data plane that spans a mix of AWS, Azure, Google Cloud, private cloud, and on-premises environments
What Is Google Cloud Pub/Sub and When Is It the Right Fit?
Google Cloud Pub/Sub is a fully managed, real-time messaging service designed for asynchronous communication between independent applications. It adopts a publish-subscribe pattern, where senders (publishers) emit events and receivers (subscribers) react to them, decoupling services and allowing them to scale independently.
As a global, serverless offering, Pub/Sub automatically handles infrastructure provisioning, scaling, and reliability so teams can focus on building features rather than managing message brokers. Google Cloud Pub/Sub is an excellent choice for developers building cloud-native applications that require reliable, scalable messaging without operational overhead. It is particularly well-suited for:
-
Event Fan-Out and Notification: When a single event needs to trigger multiple, independent downstream actions—such as updating a database, sending a user notification, and logging a metric simultaneously.
-
Serverless Architectures and Cloud Triggers: Serving as the glue for serverless eventing patterns within Google Cloud, Pub/Sub can automatically trigger Cloud Functions or Cloud Run services in response to events, enabling highly reactive and scalable applications.
-
Data Ingestion and Streaming Analytics: Acting as the entry point for real-time analytics pipelines, Pub/Sub reliably buffers data from sources like IoT devices or application logs before ingesting it into processing engines like Dataflow or storage destinations for Pub/Sub to BigQuery pipelines.
- Asynchronous Workflows: Decoupling critical user-facing services from background tasks. For example, an ecommerce application can publish an "order placed" event, allowing the checkout process to complete quickly while a separate service handles inventory updates and shipping labels asynchronously.
How Do Confluent and Pub/Sub Differ Architecturally?
While both move data from point A to point B in real time, their architectural philosophies differ significantly. The fundamental architectural difference lies in how data is stored and accessed.
-
Confluent’s Kafka engine is a distributed commit log. It writes events to disk sequentially in "partitions." Consumers "pull" data from specific offsets (points in time), allowing them to replay history or process data at their own pace.
-
Google Pub/Sub is a global message queue that accepts messages and "pushes" them to subscribers (or allows pulling). Once a message is acknowledged, it is typically gone. Ideally, the system holds no state.
Is Google Pub/Sub Kafka-Compatible?
No. Unlike Confluent, Google Pub/Sub uses a proprietary API (gRPC/REST) and does not speak the Kafka protocol natively.
-
Confluent: Fully compliant with the Apache Kafka standard. Any tool, driver, or library in the vast Kafka ecosystem works out of the box.
-
Pub/Sub: Requires Google-specific client libraries. To connect Kafka-based apps to Pub/Sub, you typically need "connectors" or bridges (e.g., Kafka Connect), which adds architectural complexity.
Note: Google also offers its Managed Service for Apache Kafka but that is a distinct product from Pub/Sub.
How Do Google Pub/Sub and Confluent’s Data Retention Model Differ?
-
Confluent: Designed for long-term storage and replayability. You can retain data for days, months, or infinitely (using Infinite Storage), allowing new applications to "replay" historical data to build state.
-
Pub/Sub: Designed primarily for ephemeral messaging. While it now supports seek and replay capabilities, it is architecturally optimized for processing messages quickly and then deleting them after acknowledgement, rather than serving as a long-term system of record.
How Does Processing Differ on Confluent vs. Google Cloud?
-
Confluent: Improved support for stream processing logic via Kafka Streams and products like Confluent Cloud for Apache Flink®, allowing you to join, filter, and aggregate streams within the platform.
-
Pub/Sub: Focuses on delivery. Complex processing logic is typically offloaded to downstream services like Dataflow (Apache Beam) or Cloud Functions.
Ecosystem: Multicloud vs. GCP-Native
-
Confluent Is Cloud-Agnostic. The Confluent DSP provides a unified data plane. A topic in AWS looks and behaves exactly like a topic in GCP. This is critical for event streaming vs messaging strategies that span hybrid clouds.
- Pub/Sub Is GCP-Native. It is tightly woven into the Google Cloud fabric. Global routing, IAM roles, and monitoring are effortless if you stay within GCP, but integrating external clouds requires public internet traversal or VPNs/Interconnects.
What Scenarios Make Confluent the Right Choice?
You should choose Confluent when your organization views data streaming as a strategic platform rather than just a messaging utility. Consider if your workload fits the following scenarios:
-
You need a unified data layer across clouds and self-managed environments: Unlike Pub/Sub, which is tethered to Google Cloud, Confluent provides a unified data plane that spans AWS, Azure, Google Cloud, and on-premise environments. This is critical for hybrid architectures where data must move reliably between legacy systems and modern cloud applications.
-
You are building real-time pipelines for analytics and AI: Real-time analytics engines and AI models need fresh, contextual data. Confluent allows you to process and enrich data streams in flight (using its Flink service), making it the ideal engine for feeding real-time AI pipelines and retrieval-augmented generation (RAG) architectures where latency matters.
-
You are implementing complex microservices: For advanced microservices and event-driven patterns, you often need more than "fire-and-forget" delivery. Confluent guarantees strict ordering and persistent logs, ensuring that services remain decoupled but synchronized—vital for sagas and transactional workflows.
-
You want to offload data lake and data warehouse costs: Instead of dumping raw, messy data into storage, Confluent allows you to clean, filter, and aggregate data in the stream. This capability is the foundation of a streaming lakehouse, ensuring that only high-quality, valuable data lands in your downstream analytics tools, significantly reducing storage and compute costs.
-
You require strict governance and data lineage: If you are in a regulated industry (e.g., finance, healthcare) and need to prove exactly where a data packet came from and who modified it, Confluent’s Stream Governance suite offers schema enforcement and data lineage that simple message queues cannot provide
What Scenarios Make Google Pub/Sub the Right Choice?
You should choose Google Pub/Sub when you need a lightweight, fully managed messaging service that integrates seamlessly with the Google Cloud ecosystem. If you are asking, "Is Pub/Sub the right fit if my architecture is fully on GCP?", the answer is yes—it is the native choice for connecting services without the operational overhead of managing clusters or partitions.
Consider Pub/Sub if your workload fits the following scenarios:
-
You need "fire-and-forget" asynchronous messaging: If you need to decouple a fast-moving user interface from slow background processes (e.g., a user clicks "Sign Up" and you need to send a welcome email later), Pub/Sub accepts the message instantly and guarantees delivery to the background worker, ensuring your app stays snappy.
-
You are building serverless applications: Google Pub/Sub is the invisible glue for serverless eventing patterns. It can automatically trigger Cloud Functions or Cloud Run services in response to events (like a file upload to Cloud Storage), allowing you to build highly reactive systems that scale to zero when idle.
-
You need massive event fan-out: When a single event (e.g., "New Product Listing") needs to notify multiple downstream systems simultaneously—such as updating the search index, clearing the cache, and notifying the analytics engine—Pub/Sub handles this one-to-many distribution effortlessly without you needing to code complex routing logic.
-
You want simple ingestion for analytics: For teams ingesting logs or IoT data directly into BigQuery, Pub/Sub acts as a shock absorber. It buffers massive bursts of incoming data and smooths out the flow before it reaches your data warehouse or Dataflow pipelines.
Can Confluent and Google Pub/Sub Be Used Together? Common Integration Patterns
Many enterprises use a hybrid approach: Kafka or a solution like Confluent acts as the heavy-duty event streaming & integration layer, while Google Pub/Sub handles the "last mile" delivery to GCP-native tools. This pattern allows you to leverage the specific strengths of both platforms without locking yourself into a single operational model.
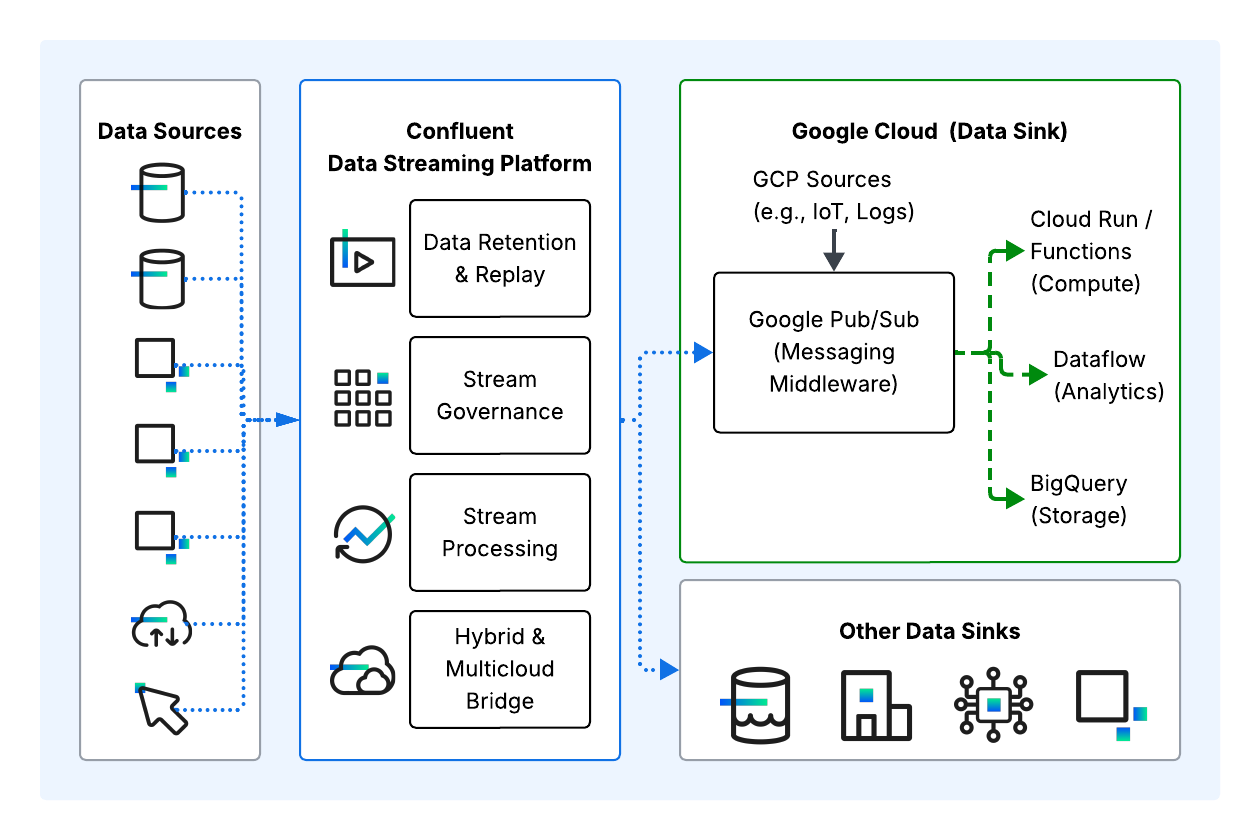
They are frequently deployed as complementary systems where each plays to its strengths: Google Pub/Sub handles the high-volume, ephemeral edge ingestion and serverless fan-out, while Confluent acts as the persistent, intelligent central nervous system that bridges multiple clouds and on-premise data centers.
By integrating them, you avoid vendor lock-in while still leveraging the native speed of Google Cloud's serverless ecosystem.
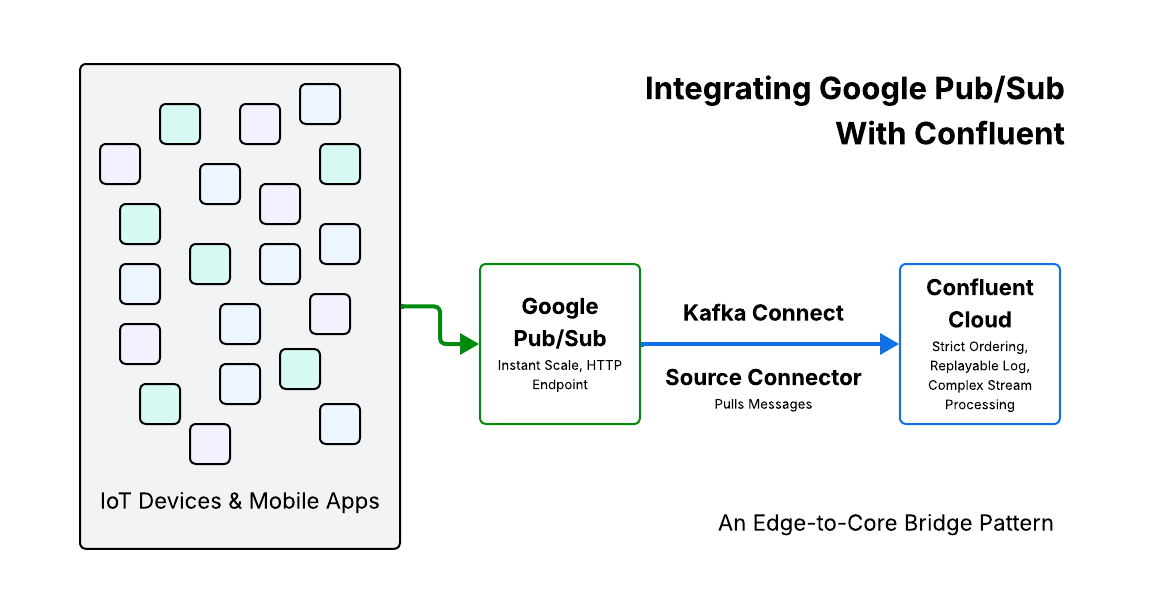
The "Edge to Core" Bridge
-
Scenario: You have millions of IoT devices or mobile apps generating logs.
-
The Flow: Devices push data to Google Pub/Sub (because it's an easy, HTTP-accessible endpoint that scales instantly).
-
The Bridge: A Kafka Connect Source Connector automatically pulls these messages from Pub/Sub into Confluent Cloud.
-
The Benefit: You get the "infinite" ingestion scale of Pub/Sub at the edge, but the data lands in Confluent for strict ordering, replayability, and complex stream processing before being sent to other clouds or data warehouses.
The "Core to Serverless" Fan-Out
-
Scenario: Your central transaction system (running on Confluent) processes a payment and needs to trigger 5 different GCP-native actions (update BigQuery, trigger a Cloud Function, email the user).
-
The Flow: Confluent processes the transaction and validates it.
-
The Bridge: A Kafka Connect Sink Connector pushes the validated event into Google Pub/Sub.
- The Benefit: Confluent guarantees the transaction is recorded and ordered, while Pub/Sub handles the messy work of fanning that message out to thousands of serverless functions efficiently.

How Do I Connect Kafka and Pub/Sub?
Pub/Sub cannot "talk" to Kafka on its own. However, using Kafka connectors, any Kafka-compatible system like Confluent can ingest data from Google Pub/Sub in real time, effectively allowing Pub/Sub to act as a producer for your Kafka topics.
You do not need to write custom code–the integration is handled by Kafka Connect, a tool included with both open source Kafka and Confluent.
-
To pull data from Pub/Sub: Use the Google Pub/Sub Source Connector. It treats a Pub/Sub subscription as a tape to read from, converting messages into Kafka records.
- To push data to Pub/Sub: Use the Google Cloud Functions Gen 2 Sink Connector or the generic HTTP Sink Connector V2 to push data to an API endpoint that then triggers a Pub/Sub publish action.
Take Your Next Step With Data Streaming
To dive deeper into building your streaming architecture, check out these resources:
Is Pub/Sub the same as Kafka?
No. Kafka is a distributed log platform designed for storage, replay, and stream processing. Pub/Sub is a message queue service designed for transient message delivery and global fan-out.
Which should I use for streaming?
If "streaming" means complex real-time analytics, windowing, and joining data streams, Confluent is better suited. If "streaming" means simply piping data from a producer to a consumer (like logging to BigQuery), Pub/Sub is highly effective.
Does Pub/Sub support Kafka APIs?
Not natively. While there are adapters, Pub/Sub uses its own gRPC/REST APIs. If your application expects the Kafka protocol, Confluent is the native solution.