Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Leveraging the Power of a Database ‘Unbundled’
When you build microservices using Apache Kafka®, the log can be used as more than just a communication protocol. It can be used to store events: messaging that remembers. This leads to a single source of truth that spans estates of many independent services. We discussed this in the last post.
But storage is just one piece of the puzzle. Adding stream processing into the mix allows a service estate to be rethought as a kind of distributed database: a database ‘unbundled.’ This has some interesting consequences, particularly for services that use datasets that are shared.
Databases Aren’t Built to be Shared
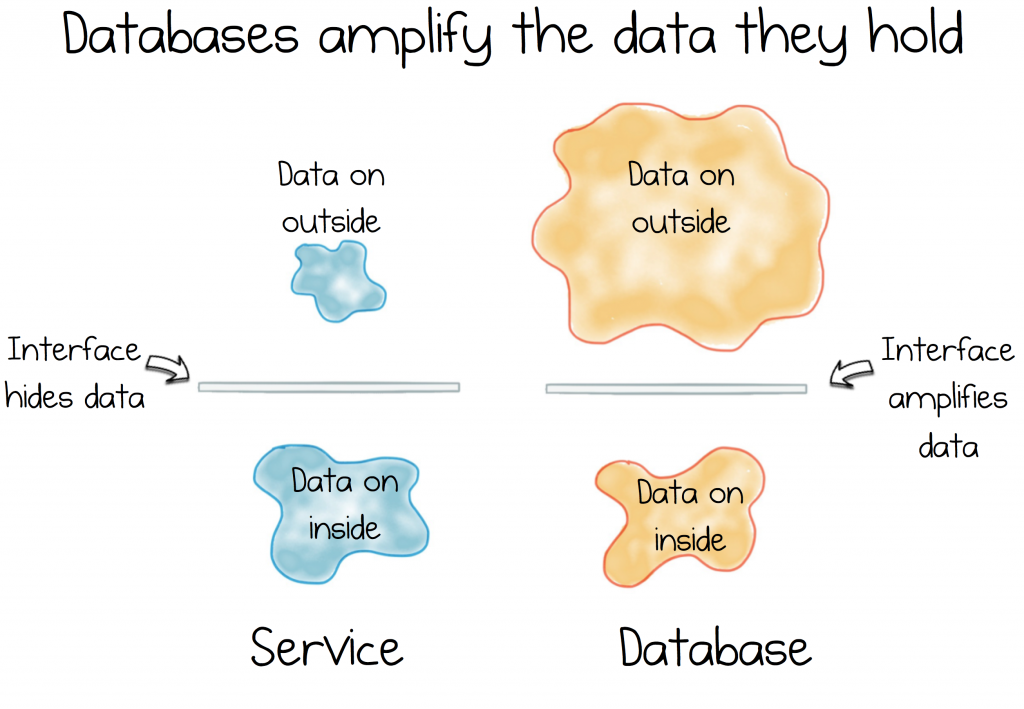
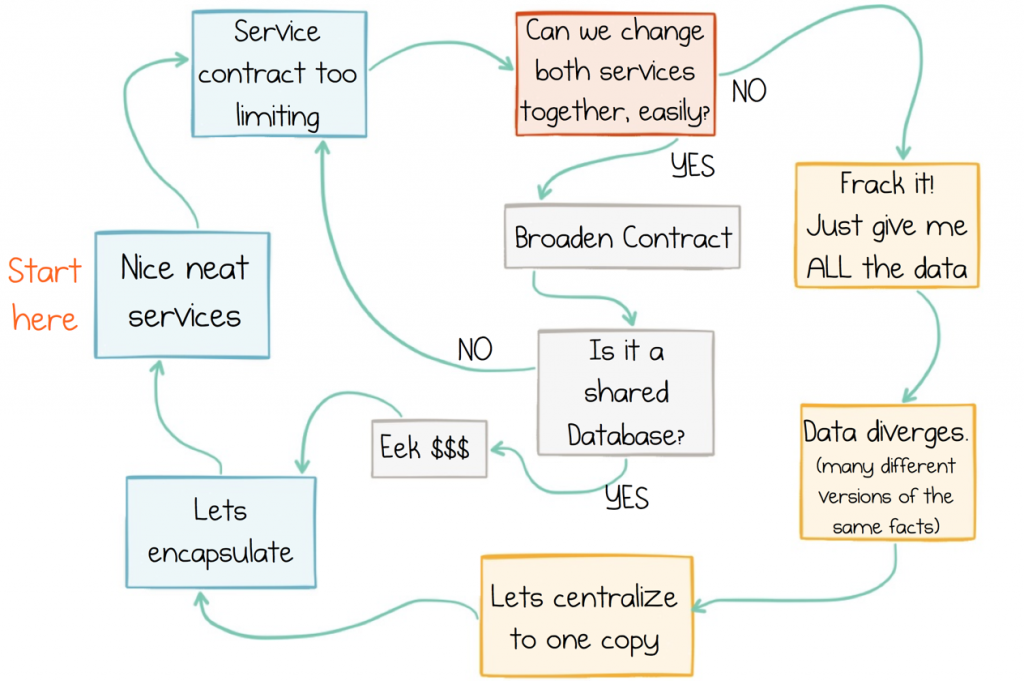
One of the problems with databases, at least in a microservices context, is that they cast an unusually rich type of coupling. This comes from the broad, amplifying interface that they expose to the outside world. So as services interact with this rich contract they get sucked in: service and database becoming tightly intertwined. This was covered in the first post, notably the cycle of data inadequacy.
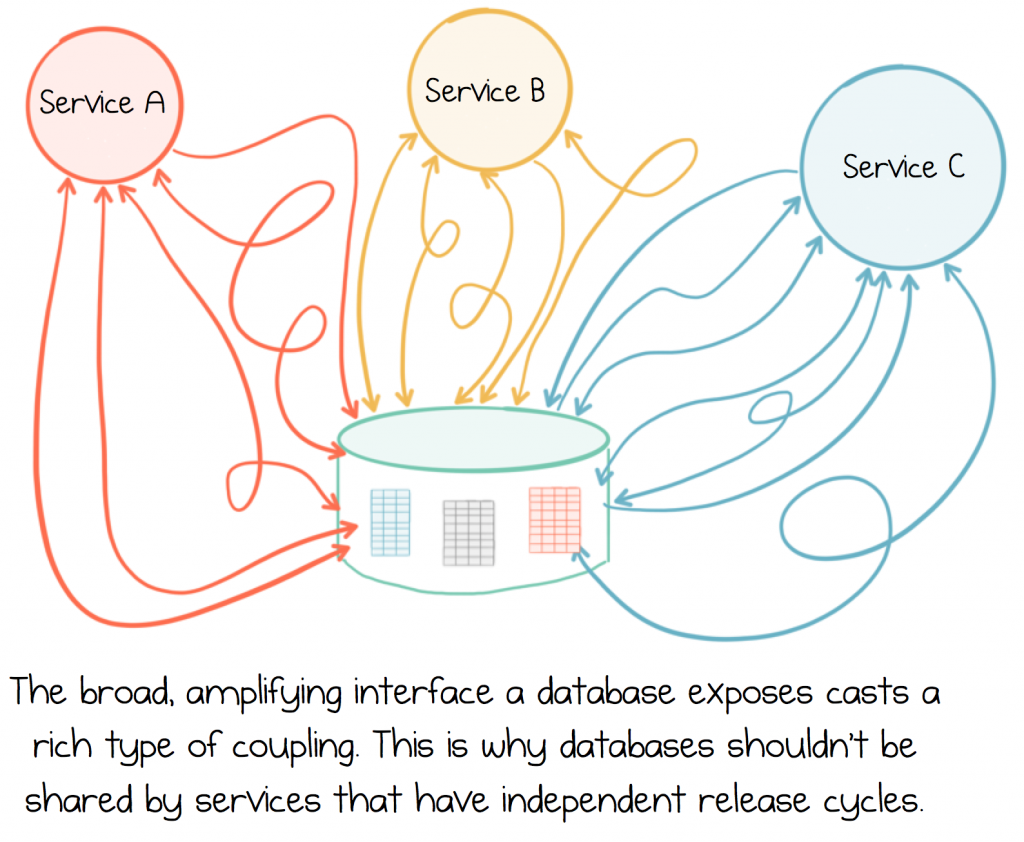
In the old days of monoliths, this didn’t matter. There were no nasty side effects, because when you released an application you released the database too, so it didn’t matter if the application was tightly coupled to the database or not: they both changed together.
But if you are building a system of independently deployable services, all sharing a single database, when it comes to releasing one of them the broad, shared contract makes it hard to work out what effect your changes will have. In addition, as estates grow, databases become a central bottleneck meaning they get increasingly hard, and costly, to scale. Finally they represent shared mutable state. This leads to unpredictability. It also concentrates consistency into a single place. So sharing a database, in a service estate, is widely considered to be an antipattern[1].
Why would you want a Shared Database? You have Service APIs
Service APIs provide a better option, but they come with problems of their own. They’re not good at wholesale data movement or anything remotely data intensive.
Say you’re building a dashboard that displays order information, and each row involves a call to the Payment Service, the Orders Service, and the Customer Service. It’s probably going to be pretty sluggish as the user scrolls up and down.
So what do you do? You might bring the data together ahead of time, caching it in memory or maybe using a database, but that leads to a bunch of issues around keeping this cache up to date and managing the process of polling the various data services.
Another common solution is to have one database where everything ends up. This is usually given an ‘analytics’ or ‘warehousing’ badge, but the tight coupling a database emits is still there, so it remains a tricky resource to share as the number of services grows.
So you really need a tool that brings together data so that it can be manipulated, while at the same time, not getting too entangled with other services. Let’s look at this idea of a database ‘unbundled.’
A Database ‘Unbundled’
A database is really a few concepts rolled into one: storage, indexing, caching, a query API, and sometimes transactionality to tie it all together. Unbundling a database is the idea that you can split these various concerns out into different layers, and there is benefit found in doing so. Jay Kreps described this back in 2013:
“There is an analogy here between the role a log serves for data flow inside a distributed database and the role it serves for data integration in a larger organization… if you squint a bit, you can see the whole of your organization’s systems and data flows as a single distributed database. You can view all the individual query-oriented systems (Redis, SOLR, Hive tables, and so on) as just particular indexes on your data. You can view the stream processing systems like Storm or Samza as just a very well-developed trigger and view materialization mechanism. Classical database people, I have noticed, like this view very much because it finally explains to them what on earth people are doing with all these different data systems—they are just different index types!”
This idea comes up in other areas too. The Clojure community talk about deconstructing the database. There are overlaps with event sourcing as was discussed in the last post. Martin Kleppmann also recast the concept, bringing it to life as a database turned inside out.
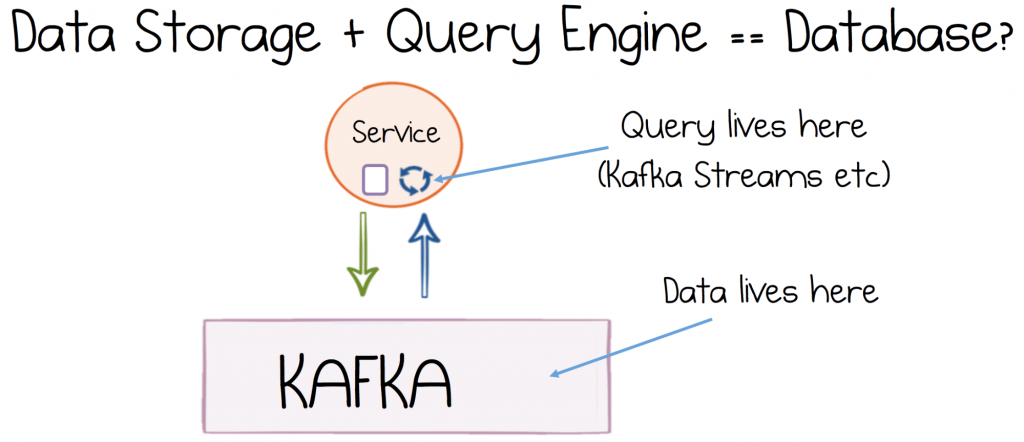
The essence of this idea is twofold: you break out the various concepts found inside a database, these are then recomposed in a way that is more sympathetic to the system you are trying to build.
So rethinking your systems in this way pushes them away from the black-box-style data management we get with traditional databases, where we route everything towards a single shared entity. Instead you’re encouraged to create independent, data-enabled components that can be composed alongside, or directly within your services. A good example is the materialised view.
Reinventing Materialized Views and Embedding them Inside your Services
In a database a materialised view is a query which the database runs and then caches. Whenever any of the underlying data changes, the materialised view is updated too. Database people use these to optimise read performance. This works because a view precomputes your query to get the data in exactly the right form for your use case. So when it comes to querying the view, all the heavy lifting has been done upfront. Pretty neat!
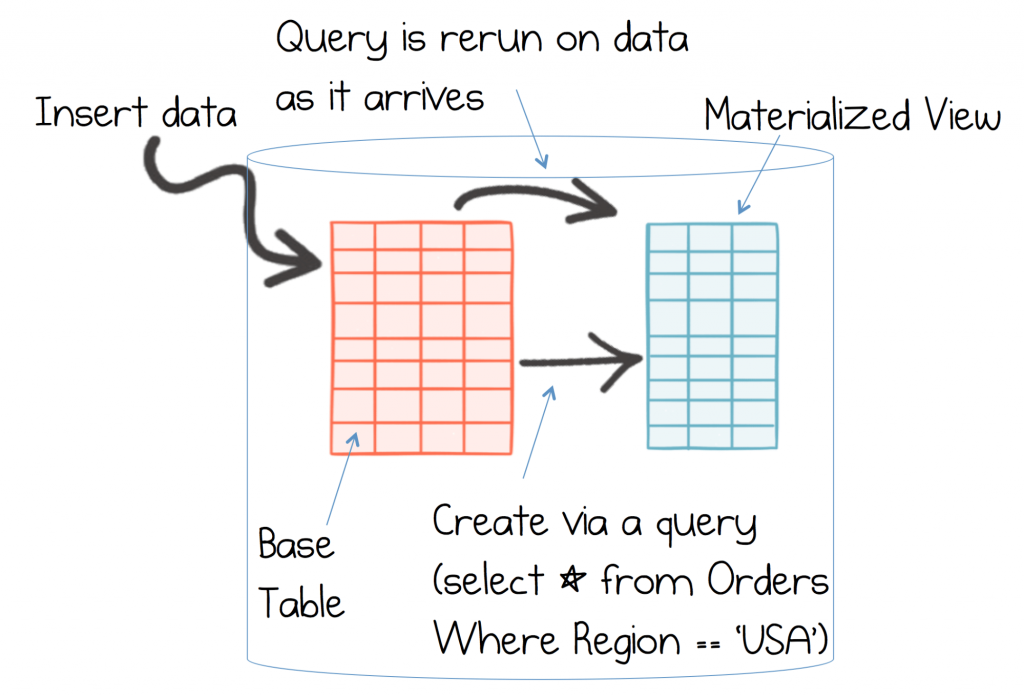
The problem is that the materialised view only exists inside the database. But if you could pluck this concept out of the database and into your services you would have a continuously updated cache. Caches are used heavily in modern applications, so this seems like a powerful idea. It is also exactly what streaming platforms do.
To unbundle a materialised view into a continuously updating cache we need three separate things: a mechanism for writing transactionally, a log that maintains an immutable journal of these writes, and a query engine that turns the journal into an index or view.
Kafka plays the role of the journal and handles atomic writes, the Streams API plays the role of the query engine. But unlike a traditional materialised view these three elements are decentralised: they operate as independent entities.
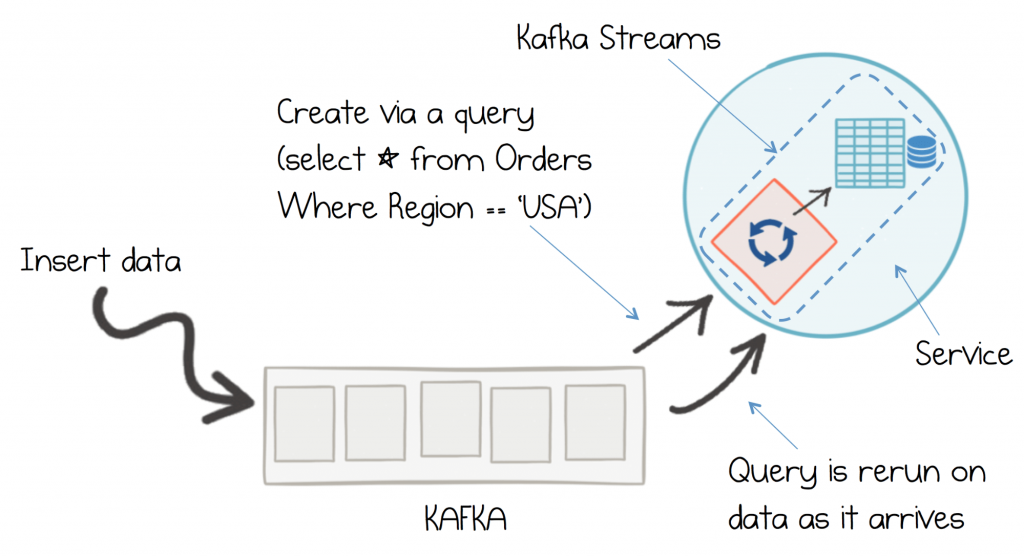
Being decentralised means the views can be placed anywhere. They might be a standalone entity. They might be embedded inside a service. The view can take any form you want, and can be regenerated on a whim.
So we can summarise several benefits of this approach:
(a) The Streams API provides a powerful DSL to define what data should be indexed.
(b) The work to create the view is done upfront so it will be read optimised by default.
(c) The view is embedded right inside our service so it’s fast and local.
(d) Basing your system on a log, rather than a mutable database, avoids the unpredictability, or the concentration of consistency concerns, which come with shared mutable state.
(e) The log also provides better performance characteristics both for reads and for writes.
But unbundling goes one step further, when applied in a microservices context. It provides services with a kind of ‘database’ that they can share, one that avoids both an amplifying interface as well as shared mutable state.
Unbundled Databases can be Shared
Unlike a database, a log provides a low-coupling mechanism for sharing datasets. The loose coupling comes from the simple interface the log provides: little more than seek and scan, meaning the dominant source of coupling is the data itself.
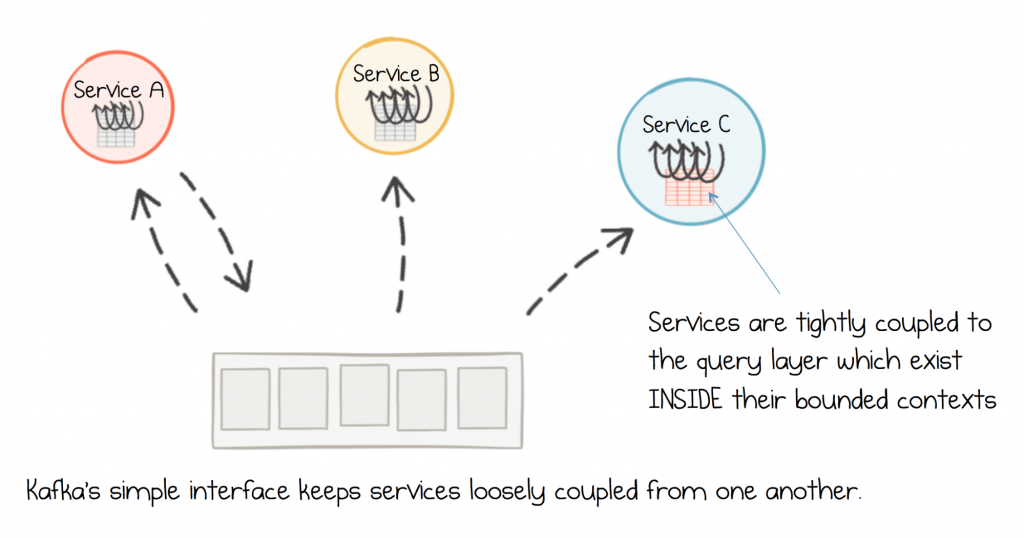
When a query layer is added on top of the log, say using Kafka Streams, services retain control of what queries are run, the hardware they run it on, what transformations are applied to create the views and most importantly: when and how these things are changed. It is this level of control, when compared to a traditional centralised database, that keeps services nimble and agile. When a service needs to release, all the highly coupled pieces are already inside it’s deployable unit. Only the data itself is shared. So an unbundled database has functional properties similar to a regular database, but without all of the bad parts.
Create Service-Specific, Needs-Focussed Views
One interesting consequence that comes with this style of system is that the views don’t need to be long-lived. If you take a copy of the product catalog and map it to your internal domain model, should that model change, you can just throw the view away and rebuild it.
This is quite different to traditional messaging approaches where the messaging system is ephemeral, meaning any view you might create needs to be durable. It needs to be a system of record for that subscribing service. But with a distributed log messaging ‘remembers’, which means the views don’t have to. So the views can be ephemeral: simple caches that can be thrown away and rebuilt.
The implications of this change in workflow go a little deeper still. Services are encouraged to take only the data they need, at a point in time. This keeps the views small and lightweight. It also reduces coupling. We will dive into this consequence more fully in the next post.
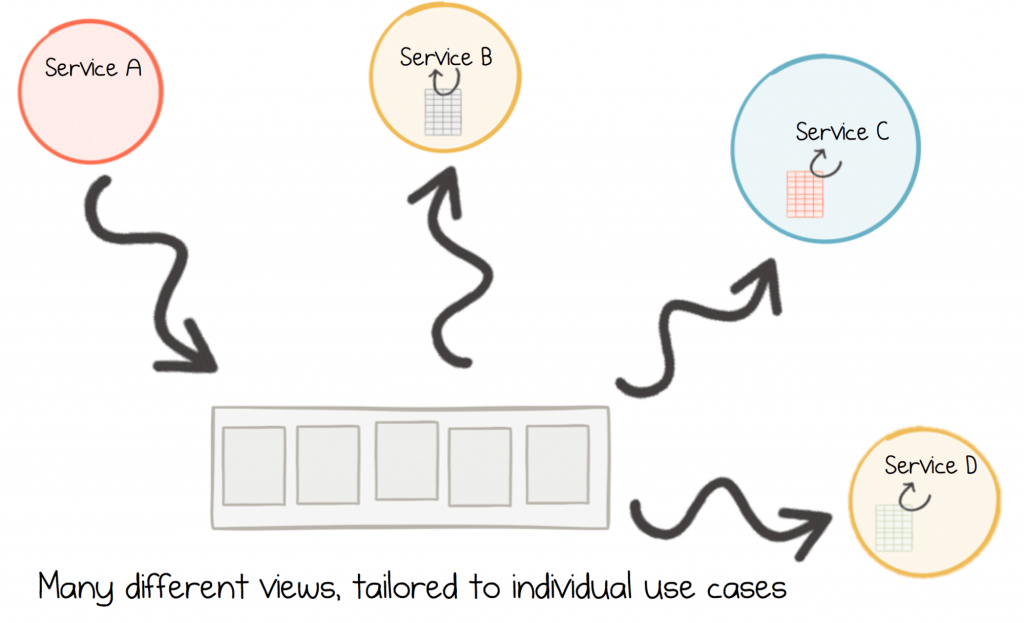
Finally, the ease of creating views in a streaming platform means you can create more of them, specifically targeted to the task at hand. So as you develop this style of system you find yourself creating many service-specific views. A stark contrast to funneling all queries into a single, centralised database or data service.
Example: Building an Embedded, Materialised Views using the Kafka Streams API
Imagine you have a service that needs to combine Order and Product information, to print the Order Note that accompanies packages when they are mailed out from the warehouse to customers.
The simplest way to do this would be to drive processing from new order events, enriching them by looking up the matching Product as they arrive. One option would be to call the Product service directly, but that would involve one network round trip per order. You can use Kafka’s Streams API to create a locally cached ‘materialised view’ so that you can look up products more efficiently. Once enriched the Order Note would be formatted, printed and mailed with the parcel.
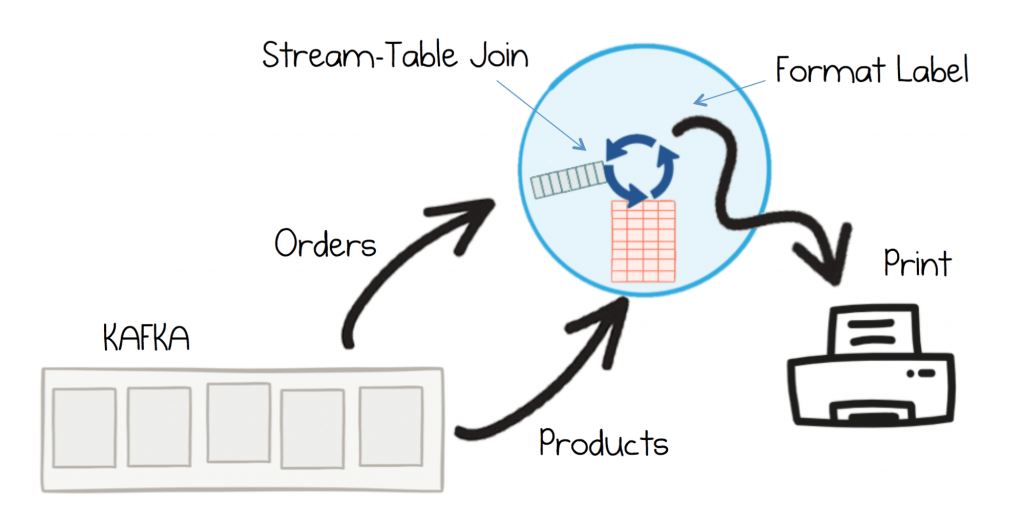
To implement such a view, you simply materialise the Products topic into a KTable. A KTable is a bit like a hashtable or dictionary mapping ProductId→Product.
When the service starts, the Streams API will load the Products topic into the service and save it to a RocksDB instance (RocksDB is a small database used by Kafka Streams to create a view from a topic). The KTable is essentially a view over this RocksDB instance, embedded inside the service, and kept up to date as new messages come in. The code would look something like this:
//Build a stream from the orders topic KStream ordersStream = builder.stream(..., “orders-topic”);
//Build a table from the products topic, stored in a local state store called “product-store” GlobalKTable productsTable = builder.globalTable(...,“product-topic”,“product-store”);
//Join the orders and products to do the enrichment KStream enrichedOrders = ordersStream.leftJoin(productsTable, (id, order) -> order.productId ...);
In this case you’ve done an enrichment—combining orders and products—but it’s equally common to go the other way; culling data you don’t need or ignoring fields you don’t care about. This helps keep these local views lightweight and fast to regenerate.
Example: Handling Request Response with Queryable State
The previous example demonstrated how to look up Products from within a streaming service, in other words, from within the Kafka Streams processing thread, where you react to events and push your business processes forwards. But how do you manage queries that come from the outside: ‘what items are in my shopping basket?’, ‘what is the status of this order?”: problems that are inherently request-driven?
User Interfaces are good examples as they tend to involve both commands and queries. Imagine you extend the previous example so that an administrator can view what Orders are leaving the warehouse via a web-based UI. You still want to join Orders and Products topics together, but you want to query that view from a browser.
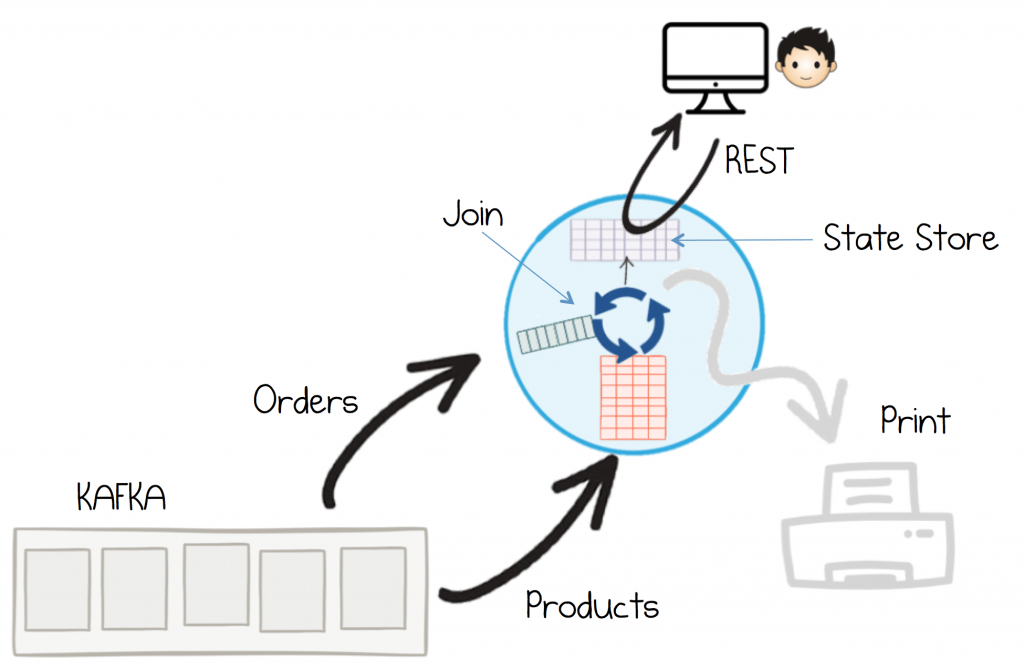
You would first fold the enriched orders into a table. This will flush them to a thing called a State Store. You can then query that state store using the Interactive Queries API.
//Extending the example above (in the streams thread) push orders into their own topic. enrichedOrders.through(“enriched-orders-topic”);
//Now build a table from that topic, which will be pushed into the “enriched-orders-store” KTable enrichedOrdersTable = builder.table(..., “enriched-orders-topic”, “enriched-orders-store”);
//Inside our request-response thread (e.g. the webserver’s thread) ReadOnlyKeyValueStore ordersStore = streams.store(“enriched-orders-store”,...); ordersStore.get(orderId);
This allows services to query the views that Kafka Streams creates. In the figure the view is made accessible as a REST endpoint, but you could plug in whatever communication protocol you like: gRPC, Websockets, GraphQL, Thrift etc.
It’s also possible to scale a materialised view out horizontally, if there is too much data or if the network throughput is too high for a single server. When running in a distributed configuration Kafka Streams provides the discovery information necessary to route requests for a key to the appropriate server.
Getting Started with Streaming Services
The best way to get started with these patterns is to check out the KafkaMusic example. This is a little more complete than the ones described in this post. It creates a ‘streaming view’ of pop songs, along with how many times they have been played. The resulting ‘streaming view’ is exposed over a REST endpoint.
To get started just download the Confluent Examples and use maven to install the various dependencies. There is a test which boots a Kafka cluster, so it’s easy to have a quick play around.
Leveraging the Power of a Database and the Decoupling of an Event Stream
At the heart of unbundling sits a simple idea. Rather than using a database, where you go to a single place for all your data needs, it is often preferable to break a database apart, then compose a solution from its constituent pieces, each finely tuned to do a certain job. The reason this is appealing is that the systems we build are much like this themselves: compositions of services that sit alone, typically do one thing well and form individual pieces of a more holistic puzzle.
Kafka’s distributed log is a good example. Logs are a core element of most databases, although they’re not typically exposed to users. Their simplicity makes them fast and scalable. In a services context it also makes them well suited to sharing data: there is little to couple to, other than the data itself, and its immutability makes them predictable.
In practice we may push the log into an indexed view, where many of the log’s benefits will be lost, but new ones will be gained. The value comes from being able to choose not just when, but also where this happens. This gives us flexibility. We might create a view that a browser can query; leveraging the ease with which we can shape the dataset to make the query fast and efficient. We might embed a materialised view close to some of our business logic, so we have an in-process, self-updating cache. We might use such a view because it gives us control, meaning a service can evolve and adapt without other services getting involved.
So ‘unbundling’ is not about rethinking the database as such—databases are what they are—it’s about rethinking our programs and our data in the context of a distributed world. Remaining decoupled, but also keeping the ability to adapt and change.
In the next post we’ll look at how we build a more fully fledged and stateful streaming application.
Posts in this Series:
Part 1: The Data Dichotomy: Rethinking the Way We Treat Data and Services
Part 2: Build Services on a Backbone of Events
Part 3: Using Apache Kafka as a Scalable, Event-Driven Backbone for Service Architectures
Part 4: Chain Services with Exactly Once Guarantees
Part 5: Messaging as the Single Source of Truth
Part 6: Leveraging the Power of a Database Unbundled
Part 7: Building a Microservices Ecosystem with Kafka Streams and KSQL (Read Next)
Find Out More:
Loose Coupling and Architectural Implications by Frank Leymann
Turning the Database Inside Out by Martin Kleppmann
The Log: What every software engineer should know about real-time data’s unifying abstraction by Jay Kreps
Deconstructing the Database by Rich Hickey
Stream Data Platforms by Jay Kreps
The Kafka Streams Music Example
Building Microservices by Sam Newman
Confluent Resources:
Apache Kafka® for Microservices: A Confluent Online Talk Series
Apache Kafka® for Microservices: Online Panel
Microservices for Apache Kafka white paper
Kafka Streams API Landing Page
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.


{kind=link}
{kind=link}

How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.