Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Ensure Data Quality and Data Evolvability with a Secured Schema Registry
Organizations define standards and policies around the usage of data to ensure the following:
- Data quality: Data streams follow the defined data standards as represented in schemas
- Data evolvability: Schemas can evolve without breaking applications
While data stewards are driving these data quality and data evolvability goals, they should also be thinking about how this works end to end in a production environment.
Assuming an Apache Kafka® based architecture, this blog post is for data stewards and solution architects who are targeting a Confluent Schema Registry service in a production environment. These production environments can leverage, and often mandate, security features including service HTTPS endpoints, Schema Validation, mTLS, and Role-Based Access Control (RBAC) for authorization, along with administrative tools and a monitoring and management UI.
Before jumping in, I highly recommend reviewing the following resources to get up to speed on Schema Registry fundamentals and to get hands-on experience:
- For deeper understanding on why Schema Registry is important, read the blog post Schemas, Contracts, and Compatibility. Schema Registry has become even more compelling now that it supports Avro, Protobuf, and JSON Schema formats, and allows you to add your own custom formats.
- Familiarize yourself with Schema Registry basics such as producing and consuming Kafka data using schemas, checking compatibility, and evolving schemas. The best way to get started is the Schema Registry Tutorial, which is available for both on premises and Confluent Cloud.
The features described in this blog post are demonstrated in a rich tutorial called  cp-demo, which shows you how to configure a secured Kafka cluster along with many services including Schema Registry. cp-demo demonstrates how features work end to end across the entire platform. These core security features also correspond to current and upcoming features in the fully managed Schema Registry in Confluent Cloud.
cp-demo, which shows you how to configure a secured Kafka cluster along with many services including Schema Registry. cp-demo demonstrates how features work end to end across the entire platform. These core security features also correspond to current and upcoming features in the fully managed Schema Registry in Confluent Cloud.
HTTPS endpoints and mTLS
In a production environment, it is strongly recommended to configure a Schema Registry HTTPS endpoint that forces all client communication to be encrypted. Configure the Schema Registry with the following parameters, with an optional truststore if ssl.client.auth=true:
listeners=https://0.0.0.0:8085 # configurable port
ssl.truststore.location=/etc/kafka/secrets/kafka.client.truststore.jks ssl.truststore.password=<password> ssl.keystore.location=/etc/kafka/secrets/kafka.client.keystore.jks ssl.keystore.password=<password> ssl.key.password=<password>
To aid in the creation of the certificates used for TLS encryption and authentication, cp-demo runs a script that generates a self-signed certificate authority (CA). For each individual service, it creates certificates signed by the CA and a keystore and truststore (typically your security team would help create the certificates). The general workflow in the demo is as follows:
- Create host keystore
- Create the certificate signing request (CSR)
- Sign the host certificate with the CA, which is self-signed for the example purpose of cp-demo
- Sign and import the CA cert into the keystore
- Sign and import the host certificate into the keystore
- Create truststore and import the CA cert
- Create PEM files and keys used for Schema Registry HTTPS testing
For more information on how to use keytool and openssl commands to create the TLS certificates for your Kafka services, refer to the Security Tutorial.
Schema Validation
Schema Validation is a server-side data governance feature that gives you the ability to enforce some data correctness. With Schema Validation enabled, Confluent Server verifies that the data produced to a Kafka topic is using a valid schema ID in Schema Registry that is registered according to the subject naming strategy.
| ℹ️ | Note: each message in a Kafka topic has a key and value, and each of them can have a distinct subject: ${TOPIC}-key and ${TOPIC}-value. As a result, the features discussed in this blog post can be configured independently for the key and value. |
Enabling Schema Validation involves two steps:
- Configure the brokers (which must be running Confluent Server 5.4 or later) with connection information to the Schema Registry. In a secured environment, the configuration would look something like this:
confluent.schema.registry.url=https://schemaregistry:8085 confluent.basic.auth.credentials.source=USER_INFO confluent.basic.auth.user.info=<username>:<password> confluent.ssl.truststore.location=/etc/kafka/secrets/kafka.kafka1.truststore.jks confluent.ssl.truststore.password=<password>
- Enable Schema Validation on a per-topic basis using the configuration parameter confluent.key.schema.validation for the key or confluent.value.schema.validation for the value. For example, using the kafka-topics administrative tool, perform the following:
kafka-topics \ --bootstrap-server kafka1:9092 \ --command-config \ --topic users \ --create \ --replication-factor 3 \ --partitions 6 \ --config confluent.value.schema.validation=true
Thus, when Schema Validation is enabled on the broker, it will first validate any message that a Kafka client attempts to produce to a Kafka topic that has Schema Validation configured. If the message does not use any schema at all (e.g. uses String format), references a schema ID that does not exist in Schema Registry, or tries to use a schema that does not map to the subject naming strategy, then the Kafka broker will reject the message:
ERROR Error when sending message to topic users with key: null, value: 5 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback) org.apache.kafka.common.InvalidRecordException: This record has failed the validation on broker and hence be rejected.
Authentication and authorization
When a client communicates to Schema Registry’s HTTPS endpoint, Schema Registry passes the client credentials to Metadata Service (MDS) for authentication. MDS is a REST layer added to the Kafka broker within Confluent Server, and it integrates with LDAP so that it can authenticate end users on behalf of Schema Registry and other Confluent Platform services. As demonstrated in cp-demo, clients must have predefined LDAP entries.
Once a client is authenticated, it is critical to enforce that only those who are authorized have access to the permitted resources. Schema Registry has long supported ACL authorization, but since last year, it additionally supports Role-Based Access Control (RBAC). RBAC provides finer-grained authorization and a unified method for managing access across Confluent Platform, including services such as Kafka Connect, Confluent Control Center, and ksqlDB. For these reasons, cp-demo uses Schema Registry with RBAC. MDS has centralized role bindings that define the set of actions (roles) users and groups can perform on which resources. If a client has no role bindings authorizing them access to the subject in Schema Registry, then the client is not granted access.
The combined authentication and authorization workflow for a Kafka client connecting to Schema Registry is shown in the diagram below. Notice that the client only communicates with Schema Registry for the request to access its subjects, and the authentication and authorization happens on the backend. For authentication (green boxes below): MDS communicates with the LDAP server to verify that the user is in LDAP, the search filters allow its return, and the user’s password is valid. For authorization (blue boxes below): MDS verifies the RBAC role bindings that grant the client access to the subjects.
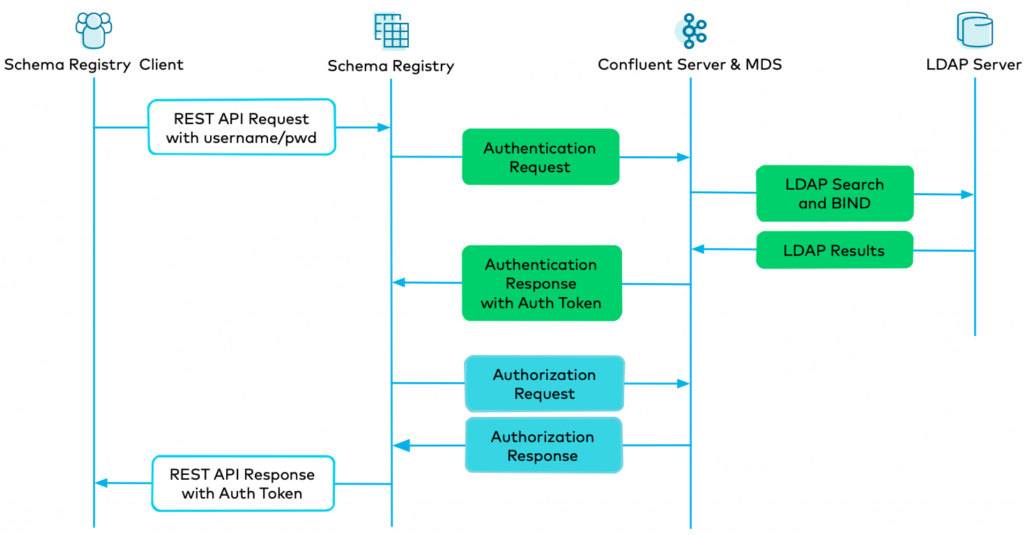
It is beyond the scope of this blog post to walk through the entire administrative workflow to configure MDS, integrate the brokers with LDAP, configure Schema Registry, etc., because there are many configuration commands, plus required role bindings. However, cp-demo is kept up to date with the latest Confluent Platform release and covers all the required configurations, providing a full end-to-end deployment guide.
Kafka client configuration
Kafka clients—the end users of the Schema Registry—need access to the subjects, schemas, and schema IDs. These clients are any Kafka producer, Kafka consumer, Kafka Streams application, administrative tool, or service producing or consuming Kafka data that is serialized or deserialized with schemas stored in Schema Registry. When your deployment has the aforementioned encryption, authentication, and authorization security features, how should the Kafka clients be configured to communicate with the secured Kafka cluster and Schema Registry?
The general configuration requirements are as follows: First, clients authenticate to the brokers with mTLS, so the client application must have a configured truststore and keystore with appropriate certificates. Next, the client application provides authentication credentials for Schema Registry, and the client application must have an LDAP entry whose username/password is represented in the schema.registry.basic.auth.user.info configuration parameter, as this is authenticated via MDS and its integration with LDAP.
A full client configuration resembles the following (as sourced from the client configuration in cp-demo—the same configuration parameters translated to Docker environment variables). Note the HTTPS endpoint in the example below:
# mTLS authentication to Kafka brokers using TLS certificates bootstrap.servers=kafka1:9092 ssl.truststore.location=/etc/kafka/secrets/kafka.appSA.truststore.jks ssl.truststore.password=<password> ssl.keystore.location=/etc/kafka/secrets/kafka.appSA.keystore.jks ssl.keystore.password=<password> ssl.key.password=<password> security.protocol=SSL
# Authentication to Schema Registry using LDAP credentials schema.registry.url=https://schemaregistry:8085 schema.registry.ssl.truststore.location=/etc/kafka/secrets/kafka.appSA.truststore.jks schema.registry.ssl.truststore.password=<password> basic.auth.credentials.source=USER_INFO basic.auth.user.info=appSA:appSA
Finally, there must be a role binding that grants the client permission to access the Schema Registry subject(s). The example below grants the ResourceOwner permission (which encompasses read, write, create, and delete) to the Schema Registry Subject resource that begins with the name ${TOPIC}. Because the command uses the --prefix argument, it encompasses the subjects for both the key and the value: ${TOPIC}-key and ${TOPIC}-value.
confluent iam rolebinding create \
--principal $PRINCIPAL \
--role ResourceOwner \
--resource Subject:${TOPIC} \
--prefix \
--kafka-cluster-id $CLUSTER_ID \
--schema-registry-cluster-id $SCHEMA_REGISTRY_CLUSTER_ID
To see all the role bindings used in a validated end-to-end example, please see the reference role bindings created in cp-demo.
Some Confluent Platform services also have embedded Kafka clients that need to be authenticated and authorized for Schema Registry. For example, underneath ksqlDB is a Kafka Streams application that embeds producers and consumers. Likewise, source connectors use embedded producers and sink connectors use embedded consumers. Therefore, for any service with embedded Kafka clients to use Schema Registry, they need at minimum the same set of five configuration parameters (though the prefix may vary depending on the service) plus the respective RBAC role bindings.
Here are two additional reference examples from cp-demo:
- ksqlDB: See the configuration for the ksqldb-server Docker service in the docker-compose.yml file.
- Connectors: For instance, cp-demo streams live web data by running a Server-Sent Events (SSE) source connector from Confluent Hub that pulls from Wikimedia’s EventStreams, real-time edits happening to real wiki pages. The subset of configuration parameters that enable the connector to use Schema Registry for the message value are as follows (note the connector credentials must exist in LDAP):
value.converter=io.confluent.connect.avro.AvroConverter value.converter.schema.registry.url=https://schemaregistry:8085 value.converter.schema.registry.ssl.truststore.location=/etc/kafka/secrets/kafka.client.truststore.jks value.converter.schema.registry.ssl.truststore.password=<password> value.converter.basic.auth.credentials.source=USER_INFO value.converter.basic.auth.user.info=connectorSA:connectorSA
REST proxy also integrates with Schema Registry so that the end clients can produce and consume data with schemas. The cp-demo tutorial demonstrates which role bindings clients need to access the Schema Registry subject, Kafka topic, and consumer group.
Management and monitoring
With proper authorization in place, users can log in to the Confluent Control Center to manage schemas (or log in to the Confluent Cloud UI if you are using the fully managed Confluent Cloud Schema Registry). You can view the current schema and schema history for each topic, and evolve the schema by editing it within the UI itself. Control Center will automatically check compatibility with the previous version(s).
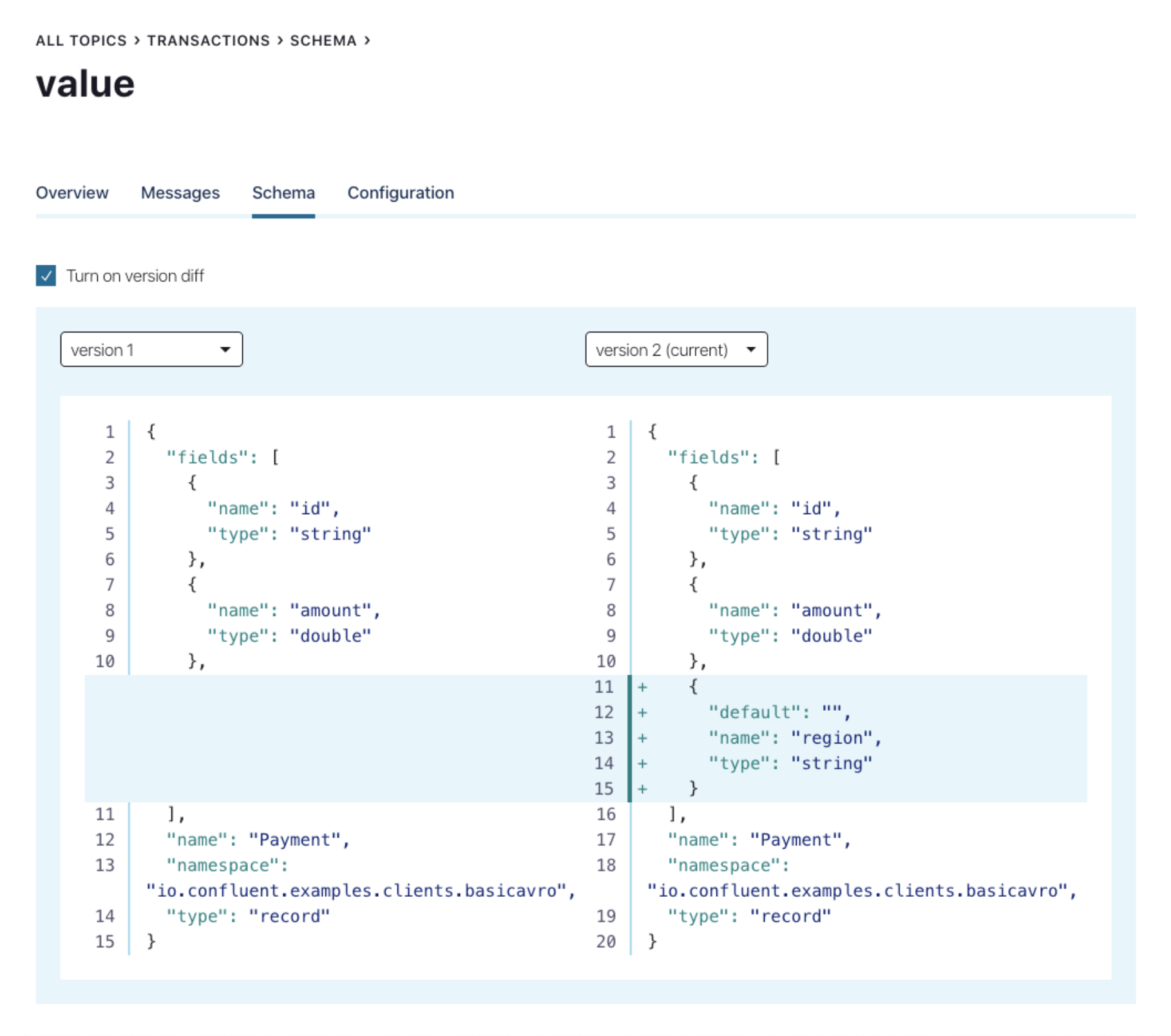
If you do not use Control Center, you can query the Schema Registry’s REST interface. Like any other client, you have to provide appropriate TLS certificates and authentication credentials. In the case of cp-demo, to register a new schema, the query would resemble:
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \
--tlsv1.2 \
--cacert /etc/kafka/secrets/snakeoil-ca-1.crt \
--data '{ "schema": "[ { \"type\":\"record\", \"name\":\"user\", \"fields\": [ {\"name\":\"userid\",\"type\":\"long\"}, {\"name\":\"username\",\"type\":\"string\"} ]} ]" }' \
-u ${USERNAME}:${PASSWORD} \
https://schemaregistry:8085/subjects/$TOPIC-value/versions
Summary
This blog post demonstrated how to use Schema Registry in a fully secured event streaming platform. As a next step, go through the cp-demo tutorial for a demonstration of how Schema Registry integrates into a Kafka-based architecture, and apply the concepts from this blog post to your own self-managed Kafka clusters.
If you are building cloud-native applications, you can use the fully managed Schema Registry in Confluent Cloud. Some of the security features discussed in this blog post are coming soon to Confluent Cloud Schema Registry. If you would like to get started, use promo code C50INTEG to get an additional $50 of free Confluent Cloud usage to try it out.* Bonus: Confluent Cloud Schema Registry is free to use with your Confluent Cloud cluster 🙂
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.