Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
How Confluent Completes Apache Kafka and Sets Data in Motion Everywhere
For businesses to survive and thrive in today’s digital-first world, it’s become table stakes to offer rich, digital customer experiences and leverage data-driven, backend operations. Delivering on these initiatives requires a modern platform for data in motion, a category of data infrastructure that connects, processes, and reacts to data in real time. Apache Kafka® has become the industry standard for this infrastructure, leveraged by over 70% of the Fortune 500 today.
However, Kafka doesn’t offer all the capabilities that modern enterprises require to implement data-in-motion use cases end to end, especially as they need to move increasingly more business-critical applications safely and quickly to production. Security features for access control, encryption, and auditing need to be custom built in order to safeguard sensitive data and workloads. Connectors need to be developed, tested, and maintained for a growing number of applications and data systems across your organization. Disaster recovery tools and application failover logic have to be created to protect your business against downtime, data loss, and their considerable costs. The list goes on.
What does this all mean for your business? Escalating total cost of ownership, delayed time to value, increased risk, and lower ROI as you try to fully realize the value of your mission-critical Kafka projects and modernize your data infrastructure.
Confluent’s product differentiation revolves around three core pillars
Confluent helps solve these challenges by offering a complete, cloud-native distribution of Kafka and making it available everywhere your applications and data reside, across public clouds, on-premises, and hybrid environments. With Kafka at its core, Confluent offers a holistic set of enterprise-grade capabilities that come ready out of the box to accelerate your time to value and reduce your TCO for data in motion. Rather than needing to spend costly development cycles building and maintaining foundational tooling for Kafka internally, you can immediately leverage features built by the world’s foremost Kafka experts to deploy to production quickly and confidently. That means freeing your teams to focus on developing the real-time applications built on top of Kafka that drive your business forward.
Let’s explore what Confluent’s capabilities on top of Kafka can deliver for your business, particularly around the complete and everywhere pillars of our platform. If you’d like to learn more about the cloud-native pillar, be sure to check out the prior blog post on this subject.
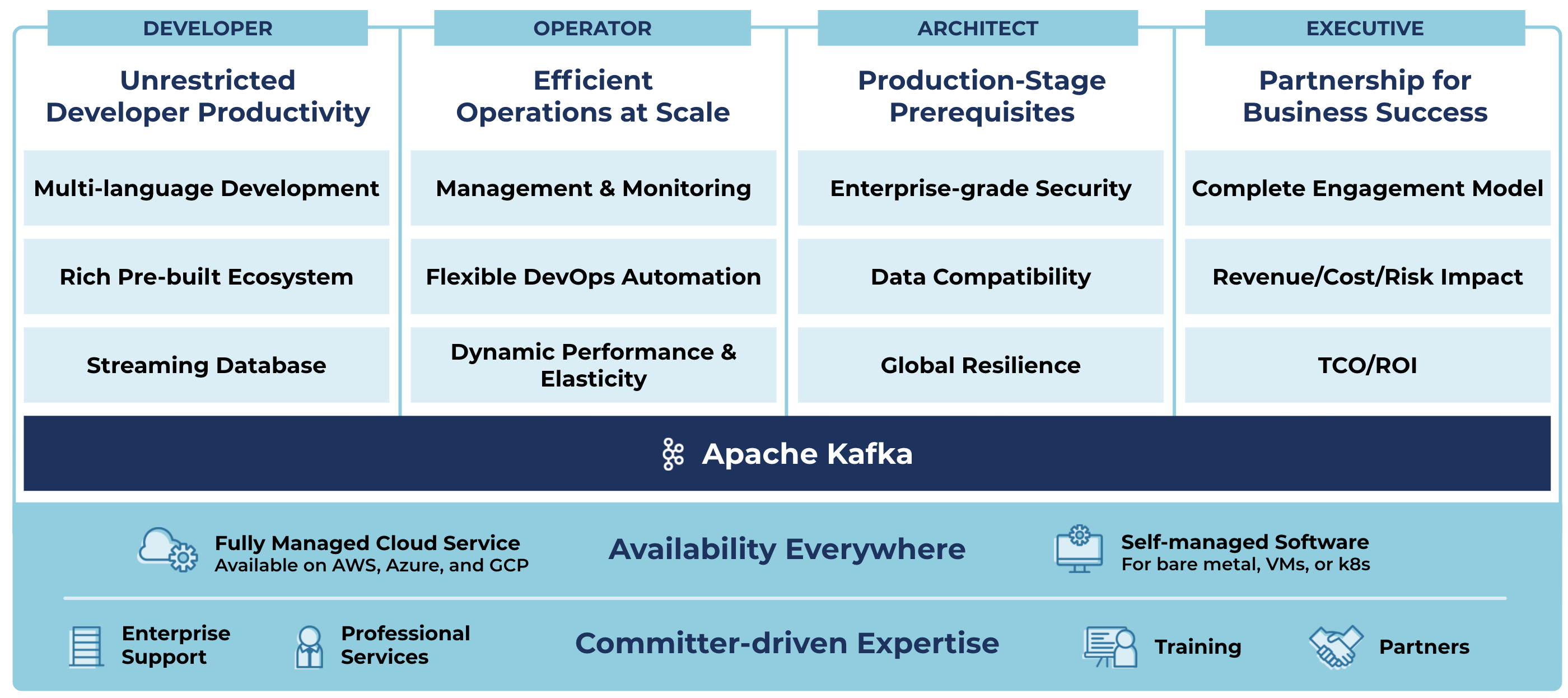
Confluent completes Apache Kafka
Unrestricted developer productivity
One of our customers’ most common goals is to make Kafka widely accessible to all developers across their business, regardless of their preferred programming language. Confluent comes with a set of tools to enhance developer agility and enable more of your teams to easily build real-time applications that leverage data in motion. While other Kafka solutions only support the Java client, Confluent provides a broad set of battle-tested clients for popular programming languages, including Python, C/C++, Go, and .NET. We also provide ksqlDB, a streaming database to build end-to-end applications on top of Kafka with the ease and familiarity of SQL. By enabling your developers to work in the language with which they are most comfortable, Confluent helps accelerate your time to value for new data-in-motion use cases across your entire organization.
Confluent’s 120+ pre-built, expert-certified connectors further enhance developer productivity in two primary ways. First, our extensive connector portfolio enables customers to easily transition to new cloud-native ecosystems and applications like AWS, Azure, Google Cloud, Snowflake, Elastic, and MongoDB, while unlocking data and divesting from both antiquated, legacy systems (e.g., MQs, ESBs, ETL, and mainframes) and expensive on-premises vendors (e.g., Oracle, SAP, IBM, Teradata, and Splunk). These cloud-native systems simplify and accelerate application development, while abstracting away significant operational tasks for engineering teams to enable developers to build at top speed. Second, rather than spending the 3–6 engineering months typically needed to build and maintain each of these connectors in-house, your teams can spend those valuable development cycles building real-time applications that drive competitive advantages for your business.
Efficient operations at scale
Kafka can be immensely complex and difficult to operate, particularly at scale as it supports more and more business-critical applications. DevOps and platform teams are required to deploy, secure, monitor, upgrade, and scale the platform, along with ensuring that any Kafka-related fire drills are resolved quickly and efficiently to minimize business disruption. This wide set of responsibilities distracts and inhibits these teams from focusing on higher value activities that better align with strategic business initiatives, such as modernizing other parts of their tech stack.
Confluent helps our customers safely and reliably run Kafka while eliminating their team’s day-to-day operational risks and burdens. For workloads in the public cloud, Confluent Cloud enables you to offload Kafka management entirely to the world’s foremost experts. With our fully managed, cloud-native Kafka service, your business no longer has to make the significant investments in engineering resources to manage and maintain foundational infrastructure for your data-in-motion use cases.
For workloads that need to stay on-premises, our self-managed software offering, Confluent Platform, can also reduce risk and costly resource investments for Kafka. The platform dramatically simplifies your operational burden by providing a suite of ready-to-use, enterprise-grade features geared toward DevOps and platform teams, including GUIs for management and monitoring, infrastructure-as-code tooling to automate key lifecycle tasks (leveraging Kubernetes-native tooling where applicable), and significant enhancements to Kafka’s performance and elasticity to meet any data-in-motion workload. Rather than needing to build out these components in-house, Confluent provides you with everything needed to build your own private cloud Kafka service for real-time streaming use cases across their entire lifecycle.
Production-stage prerequisites
Enterprises are expected to meet stringent security, data governance, and availability requirements across all elements of their data architecture. Failure to meet these requirements comes with significant costs, from regulatory fines and audits to lost revenue from outages of business-impacting applications to permanent customer distrust and reputation loss. Naturally, any data system moving into production and supporting Tier 0/1 use cases must have the complete set of capabilities to avoid these costs and de-risk your data infrastructure efforts and investments.
Confluent ensures you can meet stringent architectural requirements to prevent the inevitable risks and threats to your mission-critical applications. On top of Kafka, we provide enterprise-grade security features for access control, auditing, and encryption to properly protect all of your data flowing through Kafka, along with governance features to programmatically ensure the quality and consistency of that data. Additionally, we provide several state-of-the-art disaster recovery and high availability features to dramatically reduce downtime and data loss beyond what is possible with open source replication tools.
For most enterprises, building security, data governance, and availability capabilities internally comes with too much risk and significant delays in project timelines, not to mention the opportunity cost of allocating highly valuable teams to developing and maintaining non-differentiating infrastructure tooling. With Confluent, you can rest easy knowing that these must-have capabilities are built, maintained, and supported by the foremost Kafka experts. You can also accelerate new applications and use cases to market by saving the years of development and maintenance time needed to build these capabilities in-house.
Partnership for business success
In addition to the robust, enterprise-grade feature set for practitioners, Confluent also provides a complete engagement model to ensure your business’s success with Kafka, from the first project to the creation of your organization’s central nervous system across multiple lines of business. As more and more data starts flowing through Kafka, we help customers transition from supporting 1–2 individual use cases to leveraging the platform to connect applications and data systems across their entire organization. We also help our customers identify and realize value from new use cases for data in motion and provide guidance on best practices to ensure that they maximize revenue, reduce costs, and minimize risk for their business.
Through a combination of our expert-led engagement model and complete cloud-native platform, we’ve also helped many of our customers reduce their overall Kafka total cost of ownership (TCO) by up to 40–60% to maximize their ROI on data in motion. Kafka has significant costs that stem from the underlying compute and storage infrastructure required to run the platform, the engineering resources needed to develop and operate the platform, and the risk of security incidents, downtime, and data loss. With Confluent, you can ensure these costs are minimized and your best talent can focus on high-value application development rather than putting out Kafka fires all day.
Availability everywhere
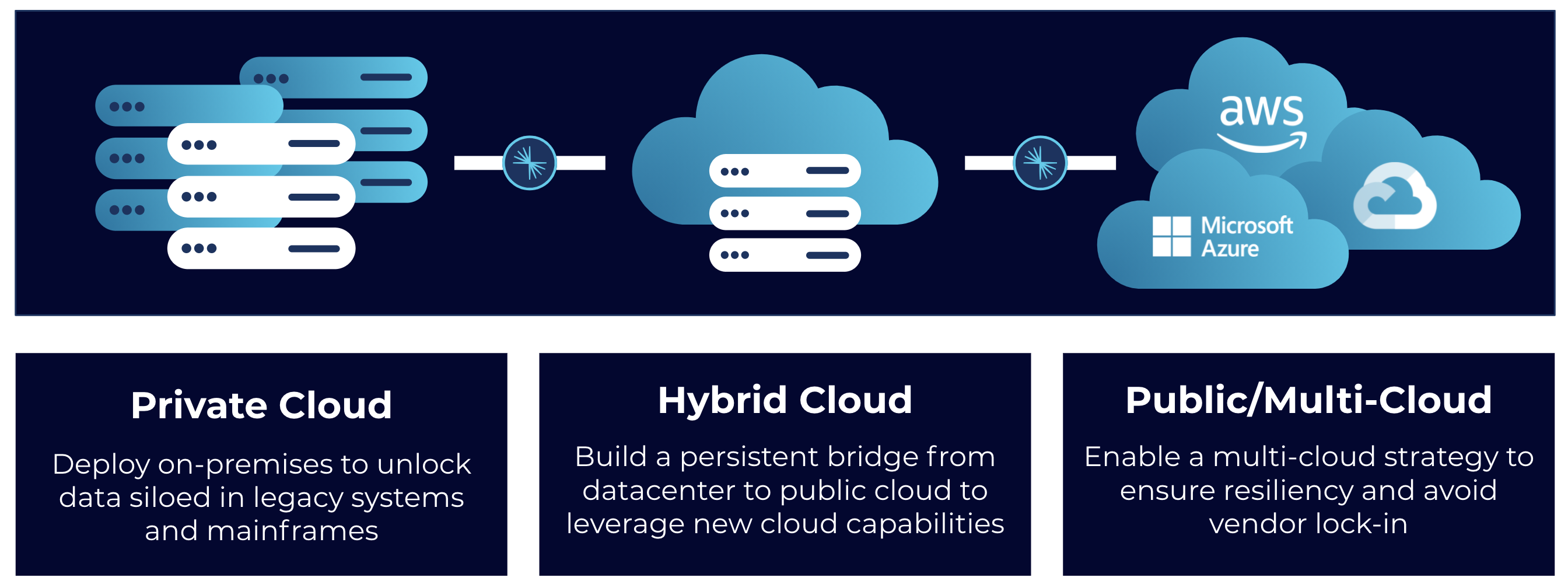
Confluent exists everywhere you need it
Kafka was built to streamline digital architectures, simplify complex point-to-point integrations, and break data silos by connecting and syncing data systems and applications in real time. To truly meet that goal, you need Kafka to bridge your entire architecture and span all of your different environments. If you operate across a multitude of on-premises and cloud environments, other Kafka solutions can only support a subset of your data architecture. This limits your ability to break data silos and build a consistent data layer across your entire enterprise.
Confluent helps by offering our solution everywhere your applications and data reside, both today and in the future. We provide you the freedom to leverage a fully managed cloud service on all the leading public clouds (AWS, Azure, and Google Cloud) and self-managed software that you can deploy for workloads that remain in your private infrastructure, whether on bare metal, virtual machines, or private clouds powered by Kubernetes. Best of all, it’s simple to securely connect and share data across different Confluent clusters regardless of their deployment model, enabling you to seamlessly pursue hybrid and multi-cloud strategies, while building the data architecture that best supports your business.
Committer-driven expertise
Many organizations that plan to implement Kafka for business-critical applications need the peace of mind and backing from an expert vendor that can provide enterprise-grade support and services. Confluent was founded by the original creators of Apache Kafka and has over 1 million hours of experience building and supporting the technology, enabling us to provide a fundamentally different level of expertise than other vendors. We don’t just help you with break-fix issues; we offer guidance, Professional Services, training, and a full partner ecosystem to serve your needs with expert-backed best practices throughout the entire application lifecycle.
Simply put, there is no other organization better suited to be an enterprise partner for your Kafka projects and no other company that is more focused on ensuring your success with data in motion.
Migrate to Confluent today
Whether you’ve been running Kafka for years or are just getting started with the transformational technology, Confluent’s complete and secure enterprise-grade distribution of Apache Kafka helps accelerate and maximize the value that you get from setting data in motion throughout your organization.
Interested in learning more? Contact us today to see how Confluent can help ensure your success with Kafka and data in motion.
Ready to try Confluent? Get started for free today!
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.