Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Confluent Cloud: Making an Apache Kafka Service 10x Better
People often imagine that to provide a cloud service for a piece of open source software is a simple matter of packaging up the open source and putting it in Kubernetes. We knew when we set out to build Confluent Cloud that a true cloud-native offering of Apache Kafka® as a service would be much, much more than that.
The reality is that the value of a good cloud service isn’t about getting the software started up on some AWS instances; it’s about taking a core capability and providing it as a true elastic utility. This may sound similar, but is actually much more. It means taking data capabilities that are fragile, scarce, and constrained and making them something every team can consume as much or as little as they need, whenever they want. To do this, though, the underlying infrastructure has to transform quite dramatically.
It’s easy to miss how significantly different a design problem a true managed service is, but it is something I think we as an industry are beginning to get a feel for. By way of analogy, from the surface, Teradata and Snowflake might seem pretty similar—after all, they both provide a SQL interface for data analytics. However, in how they are designed, how they are operated, how they can be consumed, and most importantly how they deliver value, being a managed service is a very different thing to build and operate.
A similar dynamic is true in the streaming space. Kafka is built to be easy to get started with, and easy enough for a reasonably skilled team to manage. It provides one cluster and needs to run well enough across the large variety of environments in which it might be installed and operated.
As we were building Confluent Cloud, we knew it would be a substantially different animal. It would need to provide tens of thousands of clusters, operate massively multi-tenant, run highly optimized on a limited but heavily tuned set of cloud environments, scale elastically, have automatic self-protective limits on every operation, and be designed for highly automated data-driven operations. In practice, this transforms virtually every layer in the stack, from how data is routed over the network, how requests are processed, how data is stored, where data is placed and when it is moved, and how all of this is controlled and observed at scale. It is very much the difference between a Teradata and a Snowflake.
Confluent Cloud still offers Apache Kafka’s protocol and is 100% compatible with the open source ecosystem, but by being built for the cloud it offers us the ability to provide a service that is substantially better. On a number of dimensions, Confluent Cloud is now 10x better than self-managed open source Kafka or semi-managed services that just install Kafka on some machines. This blog is the first in a series in which we dive a little into some of the work we’ve done to build this service.
This has been quite a journey. Our first version of Confluent Cloud was pretty far from 10x Kafka. It was barely 1x Kafka! We managed Kafka for you, but didn’t do much more. But over the last five years, we’ve poured more than 3 million engineering hours into making this service excellent.
What does this mean for you? Well, it has helped us build an offering that we think is unmatched in three dimensions.
Cloud native
Confluent Cloud is offered as a true software as a service. It is always on the latest version. It is always secure and has the latest patches. It doesn’t just expose a bunch of low-level knobs to you, and make you build out an operations team to turn them. Instead, it provides end-to-end, world-class operations with an industry-leading 99.99% SLA.
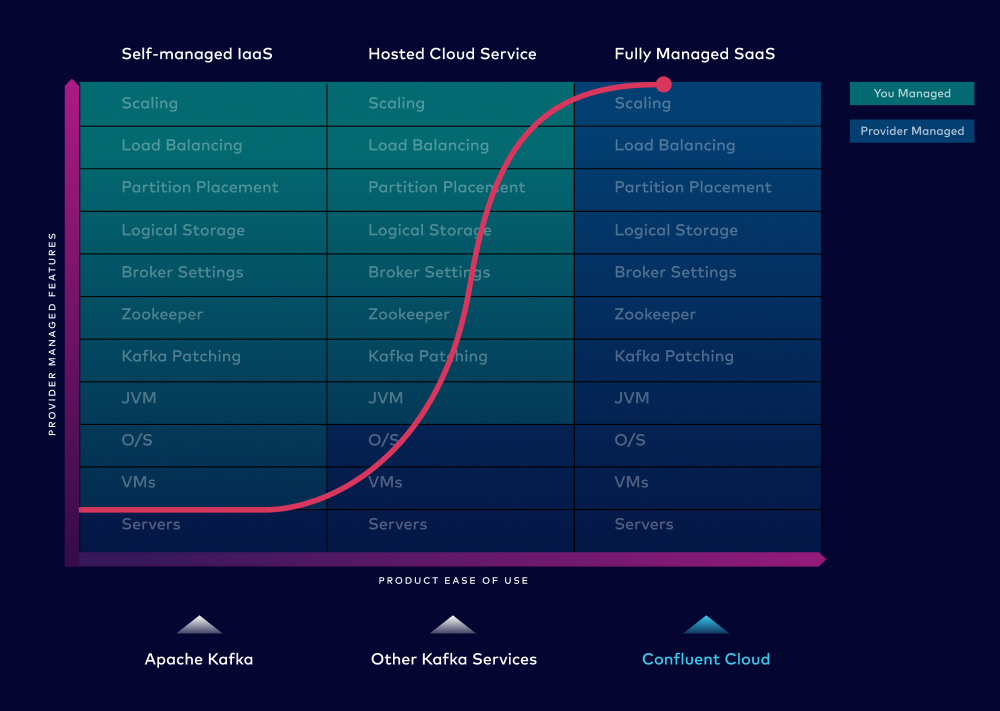
Confluent Cloud offers the only fully managed Kafka service that delivers a cloud-native, serverless experience
Complete
Second, Confluent Cloud brings together and manages not just Kafka, but the full ecosystem of components you need to automatically pull in streams of data from other systems, build intelligent real-time applications around that data, and secure and govern these streams across a complex organization.
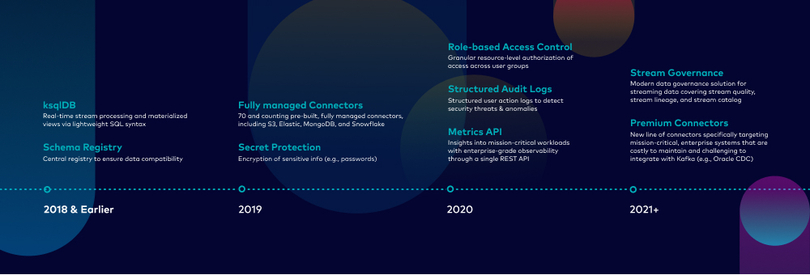
All the essential enterprise-grade tools we built for a complete data streaming platform over the last few years
Everywhere
Finally, we offer this as a fully managed cloud service in AWS, GCP, and Azure across a vast array of regions, and also provide Confluent Platform for customers who need to plug into on-premises data centers.
Beyond this, Confluent Cloud offers Cluster Linking that transparently links together clusters across these environments, so you can have one unified fabric for data in motion spanning all the parts of your company.
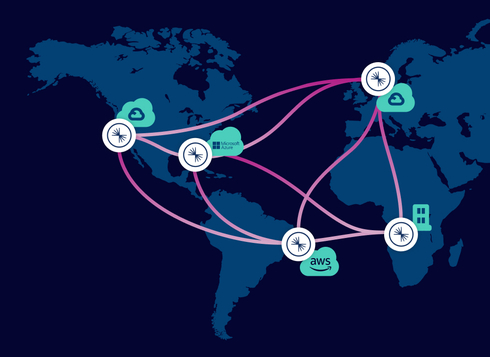
Cluster Linking: Simplify geo-replication and multi-cloud data movement of global Kafka deployments and unify cloud environments
Hear about how we made Confluent Cloud a 10x better Apache Kafka service directly from our developers
In the months ahead we’ll be talking a little more about some of the work that has gone into making this service do what it does.
The first blog post in this series talks about how we allow faster elastic expansion by building intelligence into the storage management layer. Over the next few months, we’ll run through some of the engineering in a few other key areas including storage, resiliency, and more.
And for those who want to skip all the internals, you could also just try it out for yourself right away.
More posts in this series
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.