Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
The Confluent Q3 ’22 Launch: Confluent Terraform Provider, Independent Network Lifecycle Management, and More
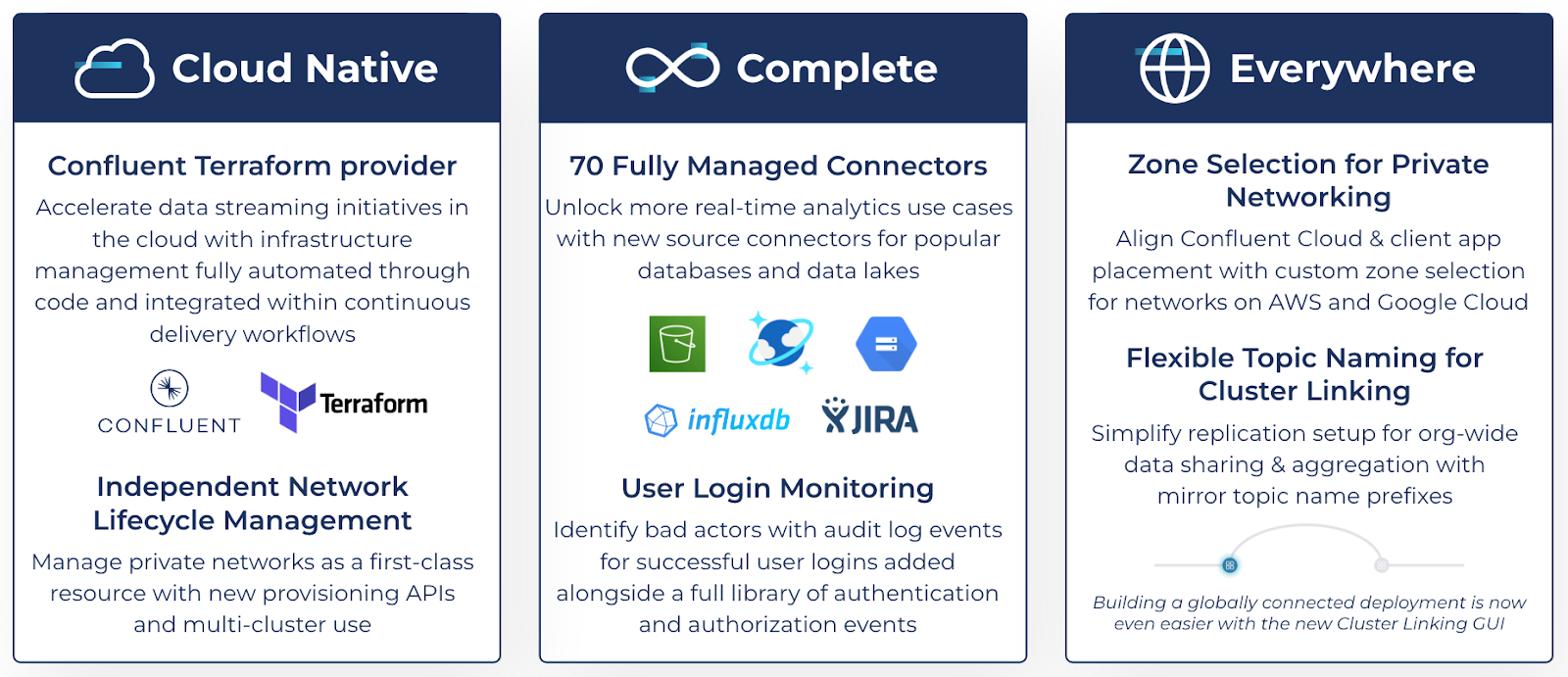
The Confluent Q3 ‘22 Launch, our latest set of Confluent Cloud product launches, is live and packed full of new features to help your business innovate quickly with real-time data streaming. This quarter, you’ll find new features designed to enhance developer productivity when working with real-time data streams through the automation of infrastructure management, separation of networking from cluster workflows, and much more.
Here’s an overview of everything you’ll find in the launch—read on for more details:
- The Q3 ‘22 Launch Features:
- See new features in action in the Q3 Launch demo webinar
Improve developer productivity and easily work across clouds with Confluent’s Q3 ‘22 Launch
Fully automate data streaming infrastructure management with the Confluent Terraform provider
Managing infrastructure through code with Confluent’s Terraform provider, built in partnership with Hashicorp, allows businesses to accelerate development while avoiding the high operational costs of manual resource provisioning and risks tied to custom-built automations. This strategy is typically represented by GitOps, an operational framework that takes DevOps best practices used for application development such as version control, compliance, and CI/CD tooling, and applies them to infrastructure automation.
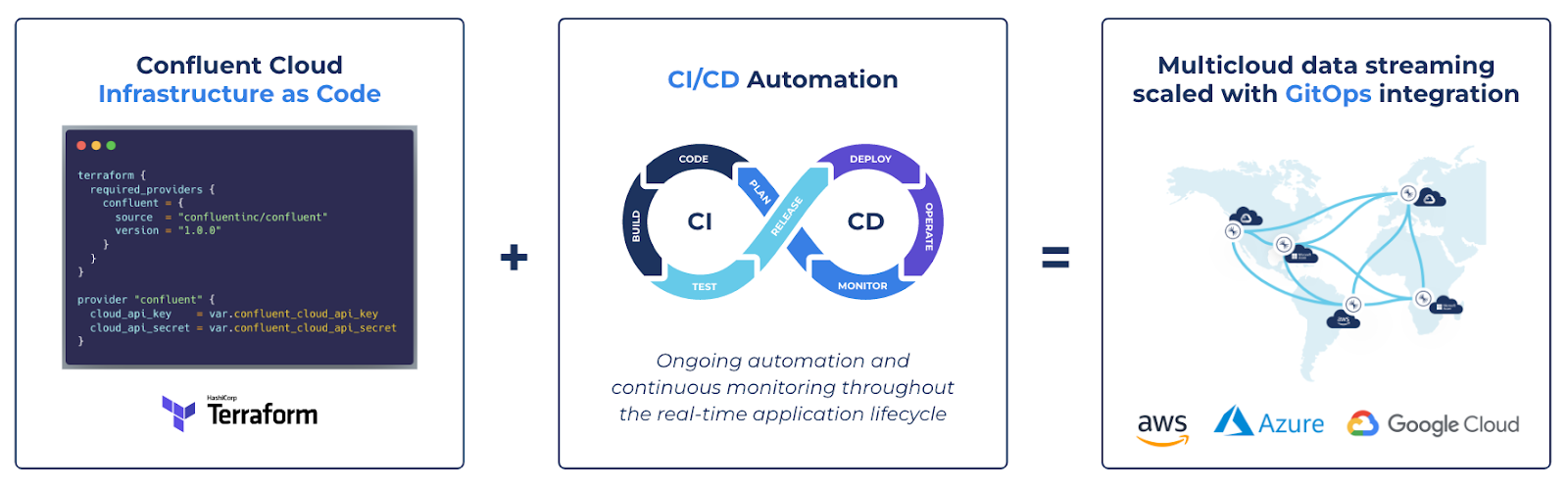
GitOps, a prescriptive approach to the modern practice of DevOps, can often be boiled down to a simple equation of Infrastructure as Code (IaC) plus CI/CD automation
All together, the approach gives developers safe, reliable access to the infrastructure resources they need with an easy means of comprehending and contributing back to the projects they are touching. At the same time, operators can confidently offload day-to-day provisioning requirements to version-controlled automations and focus on other projects truly requiring their hands-on attention.
Now generally available for Confluent Cloud, the new Terraform provider allows businesses to:
- Reduce complexity and risk with infrastructure managed as code and deployed through automated GitOps integration
- Increase developer autonomy and productivity with consistent, version-controlled access to data streaming environments, Kafka clusters, private networks, connectors, RBAC, and more
- Integrate Confluent within existing cloud workflows on AWS, Azure, and Google Cloud using standardized resource management tooling, pipelines, and processes
“Helping our customers save time and money with smart, real-time inventory management solutions is dependent upon widespread use of real-time data streaming throughout our entire business. With Confluent’s Terraform provider, we’re able to completely automate our infrastructure deployments as code with no sacrifice on quality or security. With consistent, version-controlled deployments managed through a tool our teams already know, we’re able to move quickly and maintain focus on new, value-add projects.” – Rolando Berrios, Director, Engineering at Odeko
Fully automated provisioning of a Kafka cluster and corresponding data streaming resources on Confluent Cloud via Terraform
From Kafka clusters to private networks and service accounts to ACLs, teams now have easy access to the full set of APIs they need to successfully scale Apache Kafka and Confluent throughout an enterprise. And with exposure of the new API Keys REST API, you can programmatically manage the lifecycle of your Confluent Cloud credentials and deploy end-to-end provisioning flows. Check out the full list of Confluent resources you can manage through Terraform.
Get started with Confluent’s Terraform provider by visiting the Hashicorp Terraform registry or downloading the open source provider via GitHub.
Manage private networks as a first-class resource with REST APIs, UI, and Terraform
Confluent Cloud represents an important part of our customers’ data infrastructure, with networking at the forefront of security and connectivity concerns. The networks can host dedicated Confluent Cloud clusters, managed connectors, and ksqlDB applications with private network connections. Confluent Cloud networks support private network connectivity via AWS PrivateLink, Azure Private Link, VPC peering, VNet peering, or AWS Transit Gateway connectivity types.
Independent Network Lifecycle Management promotes Confluent Cloud networks as first-class resources allowing for the separation of concerns between network infrastructure management and application development teams within an organization. With this release, organizations can now provision networks without the operational burden through:
- Flexibility in allocating multiple clusters per Confluent Cloud network thereby improving ease of use by reusing network connections for multiple clusters
- Programmatic management of Confluent Cloud network lifecycle using a collection of REST APIs or Terraform, extending critical infrastructure as code capabilities provided by the Confluent Cloud Terraform and REST API portfolio
- Granular access control of Confluent Cloud network resources by network administrators through the new NetworkAdmin role
Expand your streaming use cases with 70 fully managed connectors
Since our announcement of 50+ fully managed connectors just earlier this year, we’ve continued to expand our cloud connectors portfolio, now offering 70 expert-built connectors ready to launch with just a few clicks. A subset of our newest additions are source connectors for popular data systems like Google Cloud Storage, Amazon S3, and Azure Cosmos DB. These same connectors that are so popular as sinks for data are now available as source, setting data sitting in storage back into motion.
Upon ingestion, organizations can conduct a wide range of in-flight analyses using ksqlDB for stream processing. You can join data streams together from a variety of sources, transform them for consistency, compatibility, or use case requirements, and share the results with other data systems like a data warehouse using sink connectors. Developers can also leverage these object store and database source connectors to bridge multiple streaming use cases – Google Cloud Storage, for example, might be a target system for one use case but a starting point for the next one.
As with all of our fully managed connectors, the new connectors eliminate the operational burden of self-managing connectors, simplify configurations and deployment, and accelerate your time-to-value by helping you get started quickly.
Identify bad actors with new audit log events for successful platform logins
As a data streaming deployment grows, it becomes increasingly important to keep a close eye on who is accessing a platform and what those visitors are attempting to do with data. We’ve added new user login monitoring to the extensive library of auditable events, so potential breaches are easier to spot. Now, you can see a full list of all users who successfully log into a customer’s account. This allows organizations to quickly find the bad actors who would otherwise be hidden within the noise of expected activity and prevent costly breaches.
Simplify replication setup for data sharing and aggregation with flexible topic naming and a new Cluster Linking GUI
Flexible topic naming further simplifies the setup of common Cluster Linking use cases including organizational data sharing, data aggregation, or even a multi-region active-active deployment. Now, a prefix identifying the source cluster can be automatically added to mirror topics within the destination cluster in order to ensure differentiation and easier identification. Topics of the same name from multiple source clusters can all be replicated to the same destination with a naming prefix (e.g,. “us.orders” vs. “apac.orders”) applied to distinguish each.
Additionally, building a globally connected deployment is now even easier with the new Cluster Linking GUI within Confluent Cloud. Available for use by destination cluster Admins, the update provides a simple, “drag-and-link” experience to set up geo-replication and hybrid/multicloud data movement.
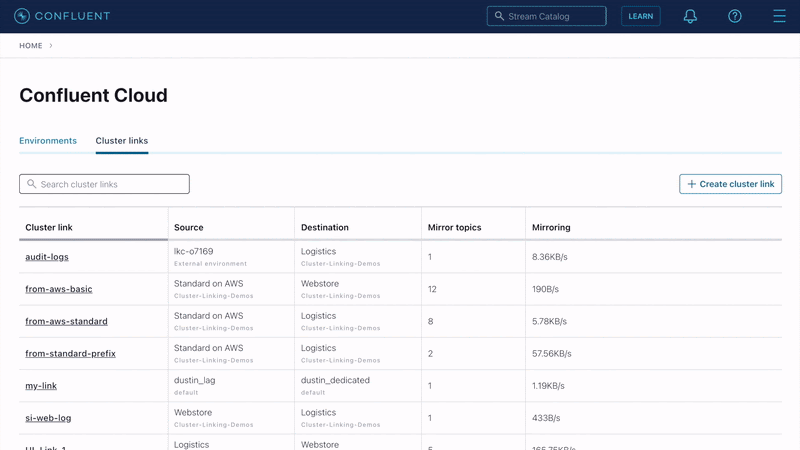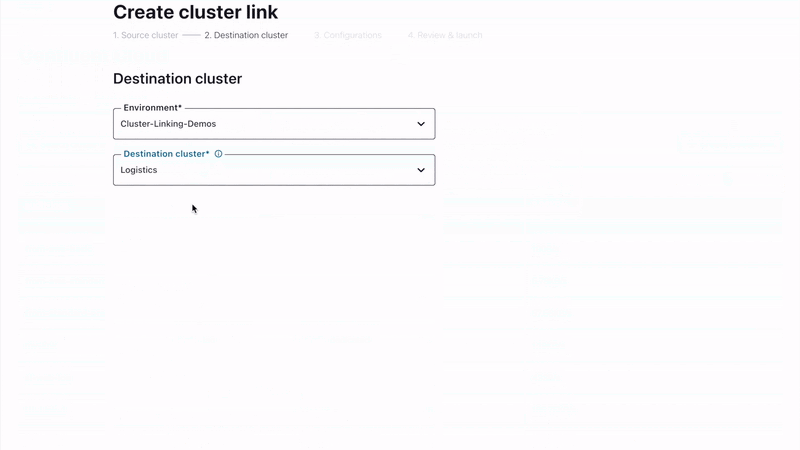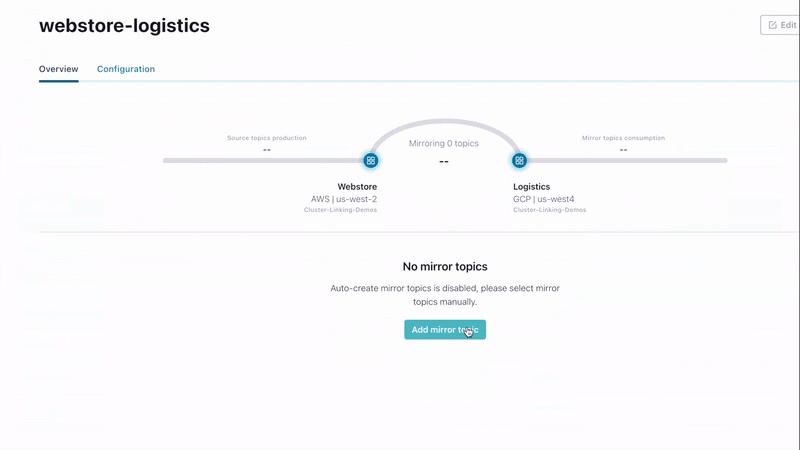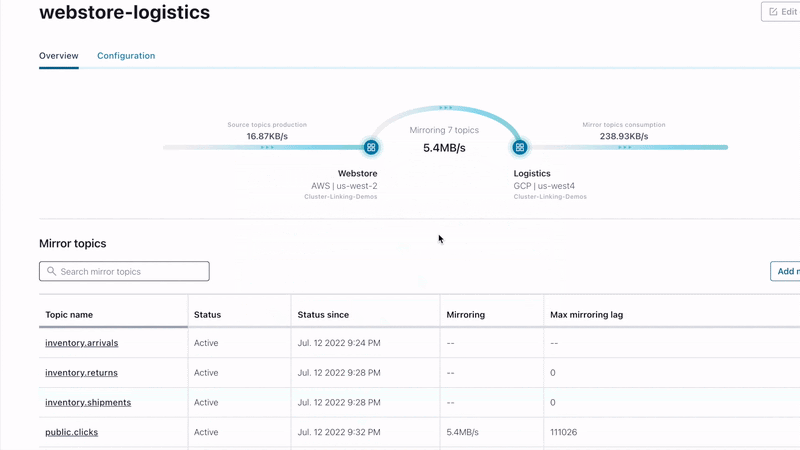
Building a globally connected data streaming deployment with linked clusters that sync in real time is now even easier with the new Cluster Linking GUI
Use new custom zone selection for networks on AWS and Google Cloud
Organizations now have the flexibility in selecting zones for networks on AWS and Google Cloud to get even more granular in aligning Confluent Cloud with their applications. Dedicated multi-zone clusters get placed in the same zones as that of the network. Zone selection fulfills high-availability requirements for customers needing zonal alignment for Confluent Cloud resources.
Start building with features in the Confluent Q3 ‘22 Launch
Ready to get started? Remember to register for the Q3 ‘22 Launch demo webinar where you’ll learn firsthand how to put these new features to use from our product managers.
Register for the Launch Demo Webinar
And if you haven’t done so already, sign up for a free trial of Confluent Cloud. New signups receive $400 to spend within Confluent Cloud during their first 60 days. Use the code CL60BLOG for an additional $60 of free usage.*
The preceding outlines our general product direction and is not a commitment to deliver any material, code, or functionality. The development, release, timing, and pricing of any features or functionality described may change. Customers should make their purchase decisions based upon services, features, and functions that are currently available.
Confluent and associated marks are trademarks or registered trademarks of Confluent, Inc.
Apache® and Apache Kafka® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by the use of these marks. All other trademarks are the property of their respective owners.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.