Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Why Scrapinghub’s AutoExtract Chose Confluent Cloud for Their Apache Kafka Needs
We recently launched a new artificial intelligence (AI) data extraction API called Scrapinghub AutoExtract, which turns article and product pages into structured data. At Scrapinghub, we specialize in web data extraction, and our products empower everyone from programmers to CEOs to extract web data quickly and effectively.
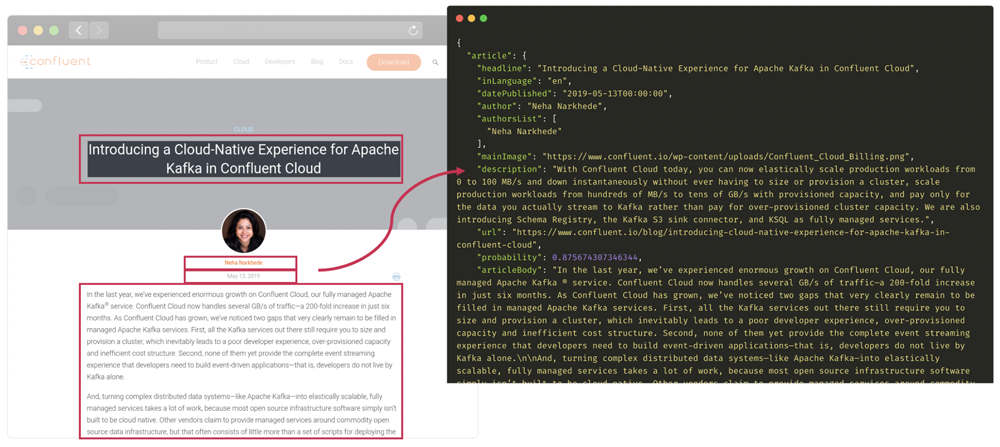
Example of article extraction on Introducing a Cloud-Native Experience for Apache Kafka® in Confluent Cloud
As part of our journey, we moved Scrapinghub AutoExtract to the cloud with Confluent Cloud. Being a small team, we wanted to offload as much of the infrastructure work to managed cloud services for ease and cost reasons.
Our use case
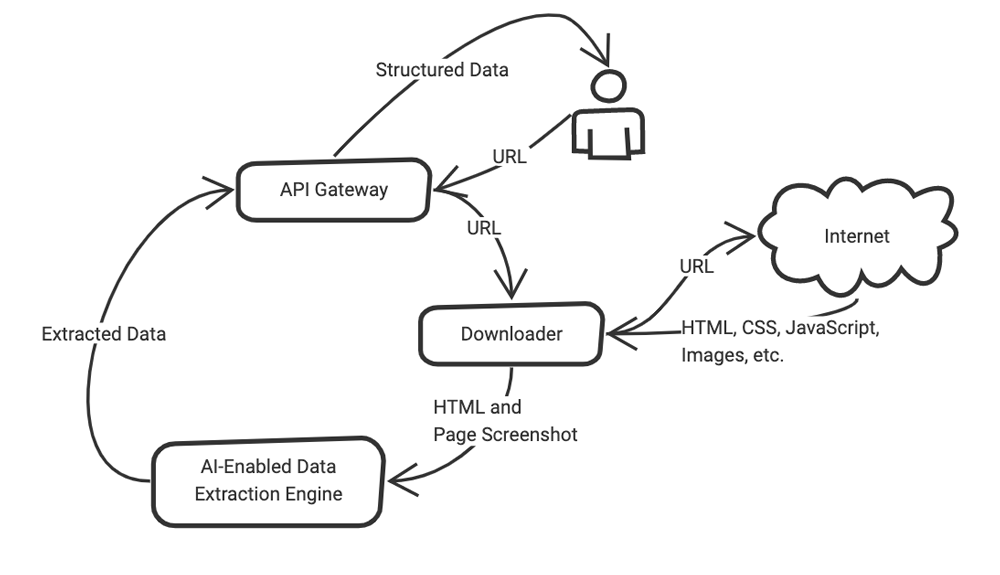
Simplified system overview
The goal of Scrapinghub AutoExtract is to enable users to extract content from a given URL without having to write any custom code. This means users don’t need to worry about site changes or their ability to scale their content extraction from various websites.
Our system receives a URL as an input from a user. This URL needs to be fetched, rendered, and screenshotted. However, it can be a complex procedure—is rendering required? Does JavaScript need to be evaluated? Does a proxy need to be used? How fast does the site load? Do pop-ups appear? As you can imagine, this can become a bottleneck for the system. By using Kafka, we partition the workload and process each partition in parallel by a separate instance of our downloader component.
Once the page content has been acquired, it needs to be understood and transformed into structured data. Our AI-enabled data extract engine responsible for this, however, involves a resource-intensive process. Fortunately, Confluent Cloud allows the system to scale by distributing the workload out to several instances of our AI-enabled data extraction engine.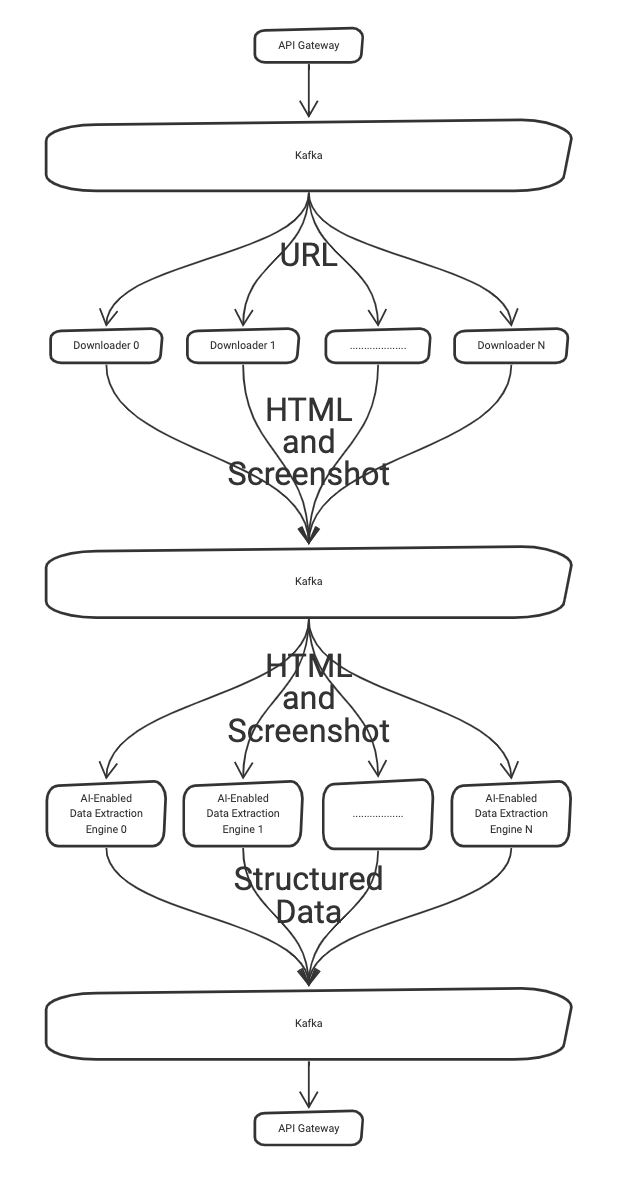
System overview showing how Kafka is used to scale and distribute requests
Why move to the cloud?
Moving the entire Scrapinghub AutoExtract stack to Google Cloud Platform (GCP) with Google Kubernetes Engine (GKE) lets us make use of on-demand instances to quickly and easily scale the system to meet customer demand. Additionally, using cloud services enables us to offload many responsibilities such as running a database, Kafka, or Kubernetes to a cloud provider, and allows our small team to focus on the product.
Choosing Confluent Cloud
For Scrapinghub, using Confluent Cloud for our Kafka needs has allowed us to offload the responsibility of running Kafka. It provides all the benefits of Kafka without requiring that we tune our cluster, manage broker upgrades, worry about encrypting data at rest and during transit, figure out the best way to run Kafka and ZooKeeper on Kubernetes, among many other things.
In addition, Confluent Cloud offers much more than reducing management overhead. The clever consumption-based pricing model enables us to only incur costs based on stored data and system activity. Confluent Cloud also provides vendor independence as the offering is based on open source Apache Kafka and is available on all major cloud providers (Google Cloud Platform, Microsoft Azure, and Amazon Web Services).
Reasons to choose Confluent Cloud
Before moving to Confluent Cloud, we looked at some alternatives, but none of them seemed to meet all of our needs.
Running Kafka on Kubernetes ourselves
Confluent provides Helm Charts, which make getting Kafka on Kubernetes up and running straightforward. We chose not to progress with this option as we wanted reliability and low maintenance overhead.
However, for times when we want more control over our Kafka brokers, such as testing how our application responds to a broker outage, we do make use of Helm Charts.
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a managed Kafka offering that comes as part of the AWS suite. We chose not to go with it for the following reasons:
- Vendor lock-in: Kafka clients must run on AWS infrastructure to access the Kafka cluster, so you do not have the vendor independence
- Pricing: AWS has provisioned-based pricing, meaning you will be charged even if the cluster isn’t in use
- Lack of important features: Amazon MSK only uses open source Apache Kafka, which doesn’t have features Confluent includes in their platform
- Support: AWS does not have the same Apache Kafka expertise as Confluent
- Basic Kafka: Amazon MSK does not offer the latest Apache Kafka version
Getting started with Confluent Cloud
After choosing Confluent Cloud, we first got started by getting our staging environment to operate successfully against Kafka. This process was simple. We created a cluster using the Confluent Cloud UI and updated our application with the configuration provided. No other work was involved.

Nothing changed about how we created our Kafka topics. Using the above configuration, we were able to use the kafka-topics script to create topics, just like we used to do before with our own Kafka cluster.
As our final test, we load tested our system with maximum capacity for 24 hours. Confluent Cloud held up just fine—we didn’t experience any latency issues, and our throughput didn’t go beyond the provided 100 MBps.
To move our production environment over, all we needed to do was create another Kafka cluster on the Confluent Cloud UI and change the application configuration.
As with all managed services, there are always some tradeoffs to be made. Given that Confluent Cloud is a multi-tenant system, access to ZooKeeper isn’t provided. This doesn’t prove to be a large issue as most of the Kafka tooling no longer requires ZooKeeper. Besides, compared to running ZooKeeper yourself, this is not a bad compromise. Still, there are some popular tools which have yet to be updated, such as Kafka Manager and Burrow.
For our team, the Confluent Cloud UI provides enough functionality that not having Kafka Manager isn’t a large issue. Initially, the absence of Burrow caused an issue as it was used to feed consumer metrics into our Prometheus-based monitoring system. We switched to a consumer metrics exporter that uses the Kafka API to work around this.
Although our system can generate some large messages, this didn’t prove to be an issue while running on Confluent Cloud. In our experience, the system limits are very generous.
Interested in more?
If you’re interested in experiencing hands-off Kafka, you can sign up for Confluent Cloud today with no commitments and only pay for what you use. If web scraping also piques your interest, ScrapingHub offers a 14-day trial of AutoExtract.





