Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Enterprise Mainframe Change Data Capture (CDC) to Apache Kafka with tcVISION and Confluent
Users with business-critical data locked in mainframes want to exploit this data by using Confluent to deploy in either a public cloud, multicloud, on-premises, or hybrid infrastructure. In collaboration with Confluent, Treehouse Software’s tcVISION replicates data in real time between mainframes and Confluent, allowing for these new use cases and truly setting data in motion.
Why mainframe modernization? Benefits and use cases
Mainframe data stores often hold large amounts of complex and critical data in proprietary legacy formats, making this data difficult to extract and incompatible with modern databases, data types, and data tools.
Enterprises are looking to take advantage of the latest cloud services, such as analytics, artificial intelligence (AI) and machine learning, scalable storage, security, high availability, etc., or move data to a variety of newer databases. Additionally, many customers want to modernize their application on a cloud or open systems platform without disrupting the existing critical work on the legacy system.
How tcVISION syncs legacy data for the cloud
tcVISION is a data replication software product that performs real-time synchronization of mainframe data sources and cloud and open systems, allowing critical mainframe data to be consumed by a variety of leading cloud services.
tcVISION supports many mainframe data sources for both online and offline scenarios. Data can be replicated from IBM Db2 z/OS, Db2 z/VSE, VSAM, IMS/DB, CA IDMS, CA Datacom, or Software AG ADABAS. tcVISION can replicate data to many targets including Confluent Platform, Apache Kafka®, AWS, Google Cloud, Microsoft Azure, PostgreSQL, Snowflake, etc. To learn more, see the complete list of supported tcVISION sources and targets.
This blog focuses on tcVISION’s connectivity to Confluent Cloud.
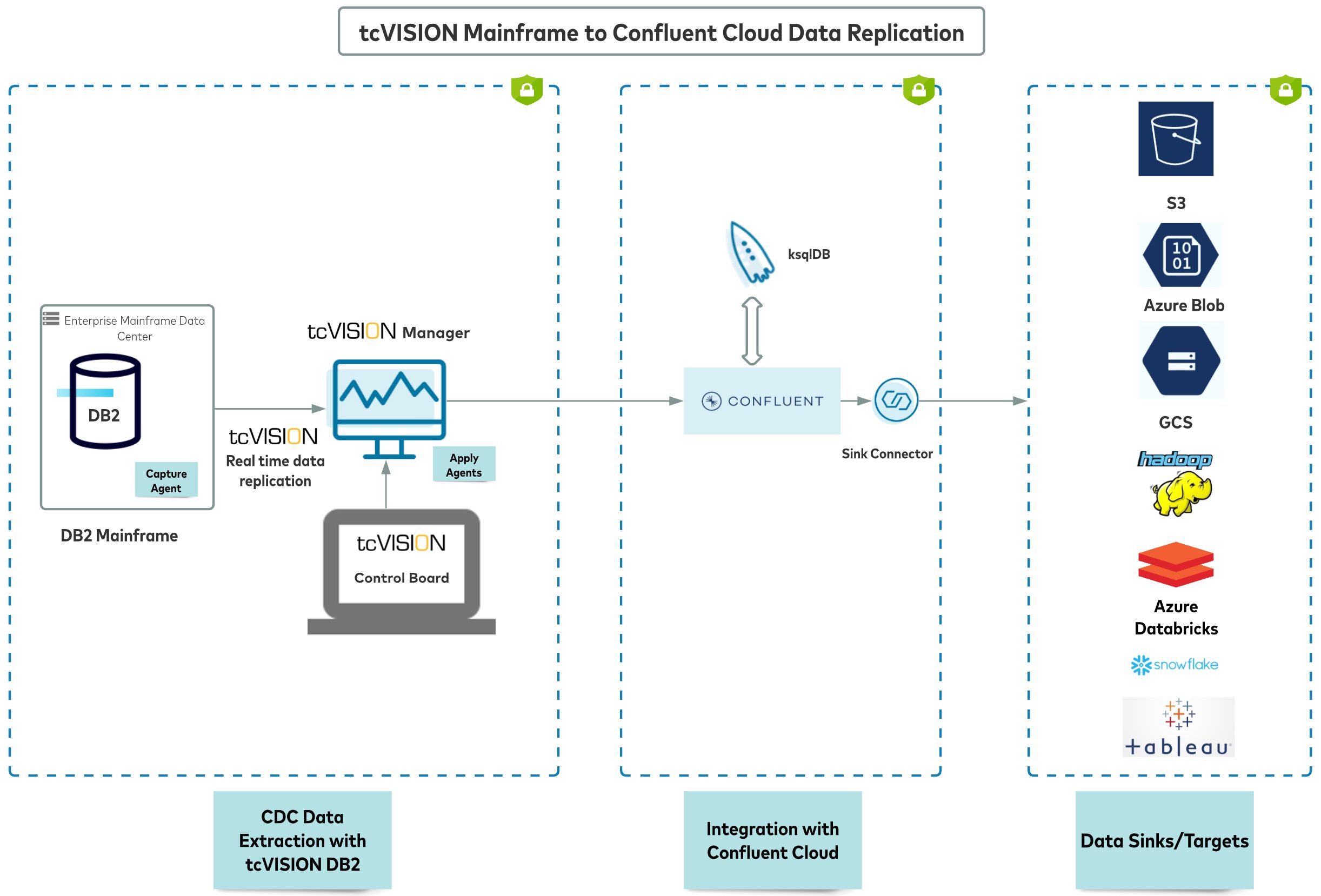
tcVISION focuses on CDC (change data capture) when transferring information between mainframe data sources and cloud and open systems databases and applications. Through innovative technology, changes occurring in any mainframe application data are tracked and captured, and then published to a variety of cloud and open systems targets.
tcVISION stores metadata in a relational database and the tcVISION manager components are administered by the tcVISION control board, a Windows GUI interface, which can be installed on premises or in the cloud. This allows tcVISION users to create metadata, create and control replication scripts, and control database interactions. tcVISION’s architecture is designed to minimize mainframe resource utilization.
Using the tcVISION control board, the most complex transformations can be specified, and it facilitates the mapping of the mainframe copybooks, redefines, data dictionaries, data catalogs, codepages, data type mapping, and more via the user-friendly interface. The repository editor allows users to control data transformations.
What is Confluent?
Confluent Cloud is a real-time data in motion platform that can be deployed in any public cloud, in any region of your choice. It comes with an SLA and uptime of 99.95%, and fully managed components like ZooKeeper, Kafka brokers, 120+ Kafka connectors, Schema Registry, and ksqlDB so you can leverage it on any cloud without having to worry about how it runs and scales.
Kafka Connect, Connect API, connectors, and tcVISION IBM Db2 connector
Kafka comes with three core APIs:
- Kafka producer/Consumer API
- Connect API
- KStreams API
Kafka Connect is a tool for scalably and reliably streaming data between Kafka and other data systems. It makes it simple to quickly define connectors that move large data sets into and out of Kafka. Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency. Kafka Connect connects APIs under the hood with fully managed connector support in Confluent Cloud.
Step-by-step guide on how to use tcVISION and Confluent
This example discusses the integration of tcVISION replication of data from Db2 to Confluent Cloud.
Set up tcVISION access to Confluent
Create an account with Confluent to make a Confluent user ID/password; the user ID is generally your email address. To sign on to Confluent, go to the Confluent Cloud login and enter your user ID:
Then, enter your password:
When you log in, you’ll be in a Confluent environment called “default”:
A Confluent environment is a type of container that holds clusters which in turn hold topics. If you are familiar with messaging systems, Confluent/Kafka will seem familiar. A cluster will need to be created to serve as a target for the data produced by tcVISION. The first attribute to be selected is the type of cluster. Confluent offers three types: Basic, Standard, and Dedicated. For the purposes of this demonstration, Basic will be used. A Basic cluster does not incur charges for simply existing, but does for data transmission and data storage.
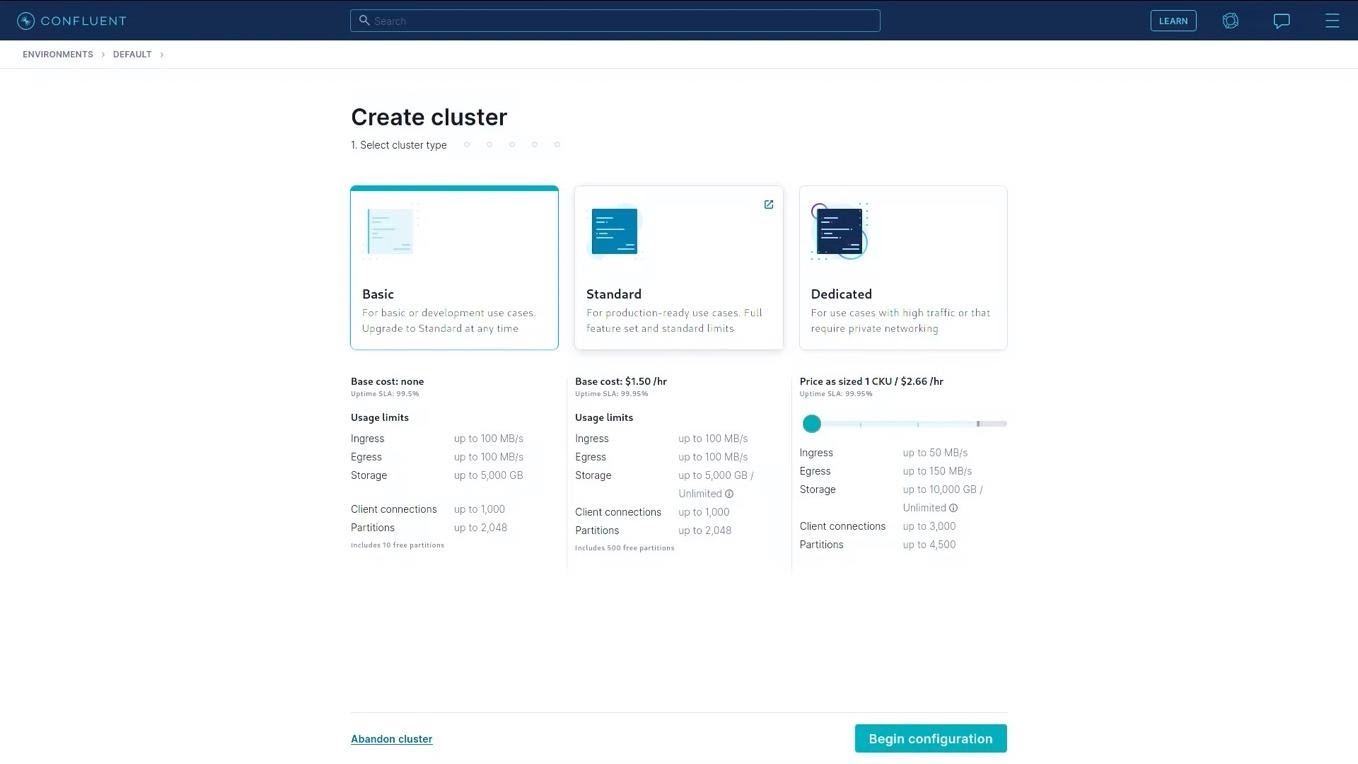
Select Begin configuration.
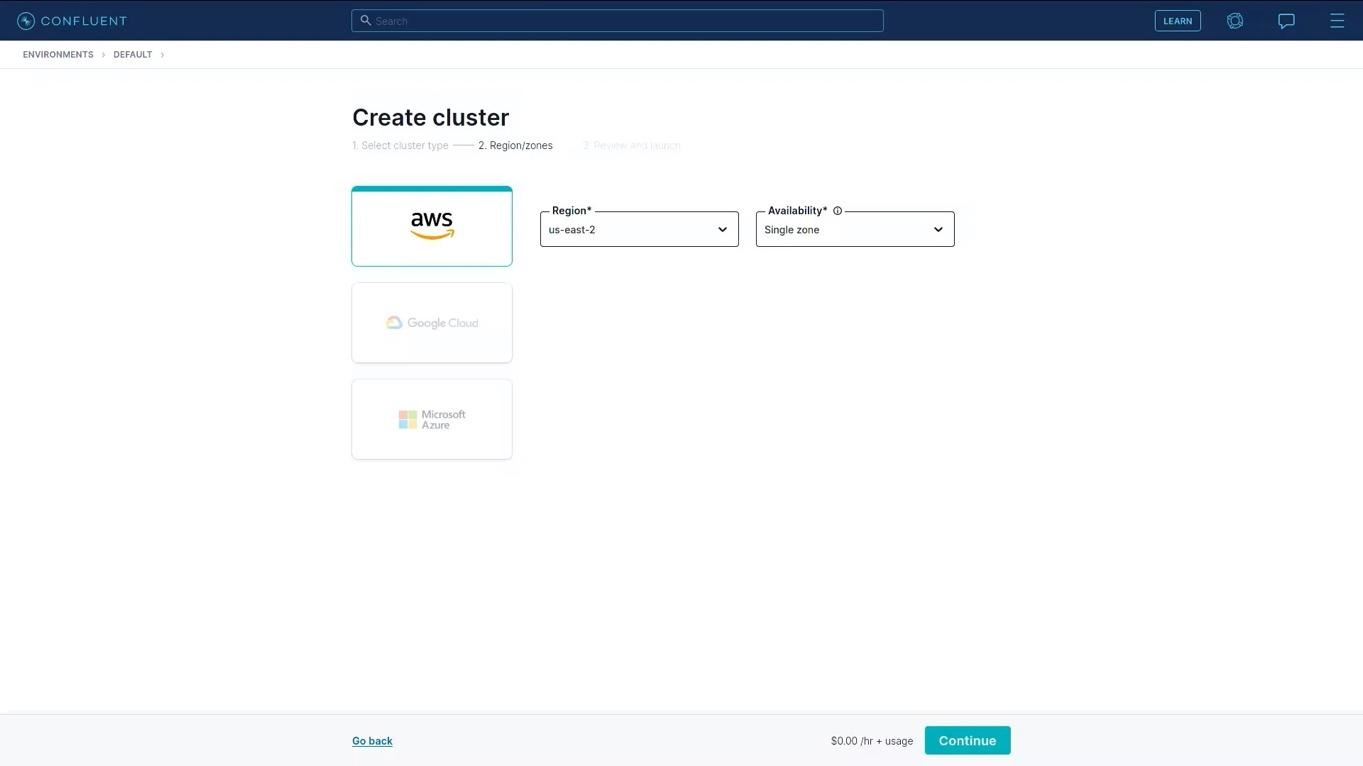
Here, a cloud provider can be chosen—AWS, Google Cloud, or Microsoft Azure. For this example, AWS is used. Select Continue and the characteristics of the new cluster are displayed, which we’ve named “tcVISION_cluster_0”:
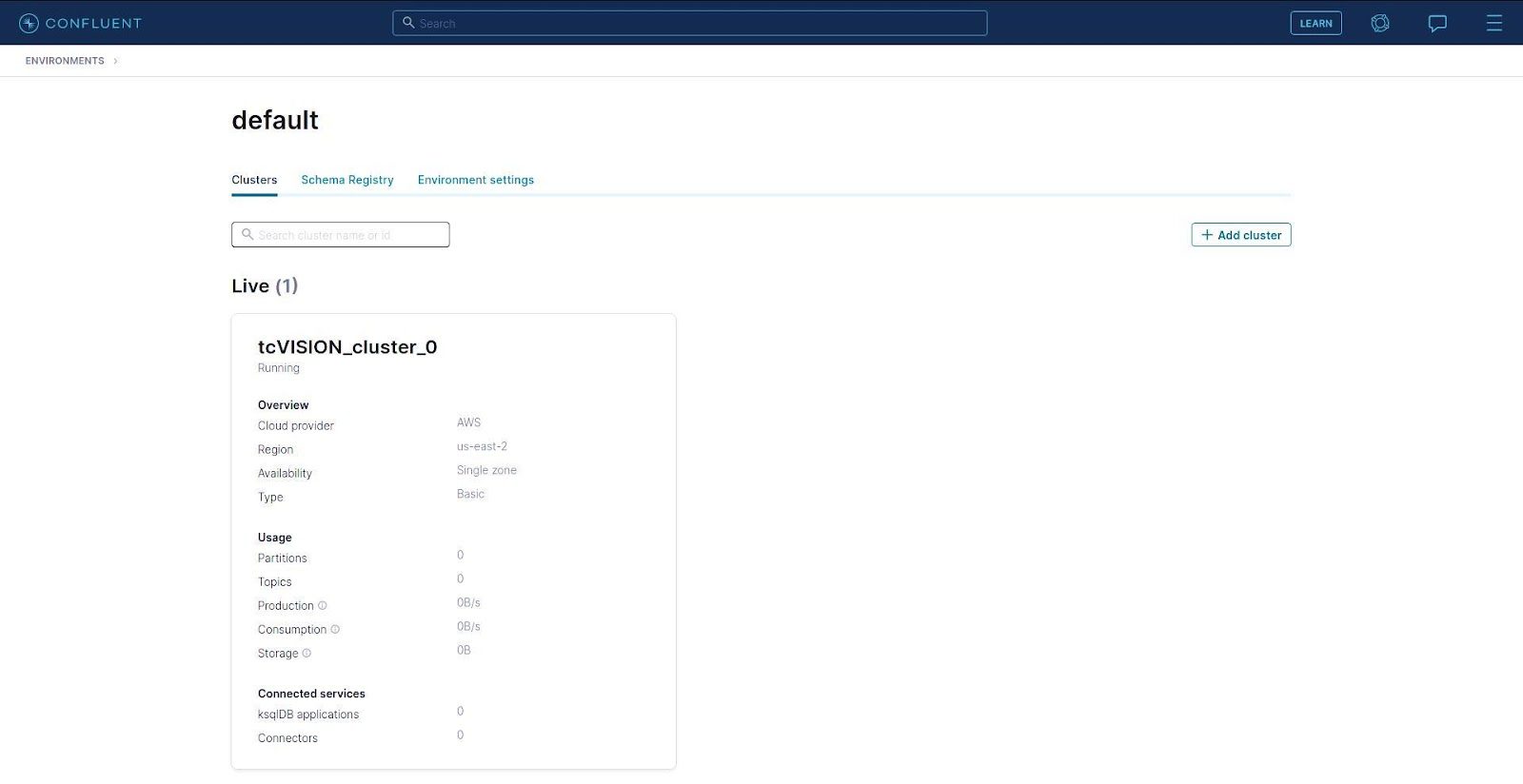
After entering your payment information (not shown), you can click on the cluster name to launch the cluster overview.
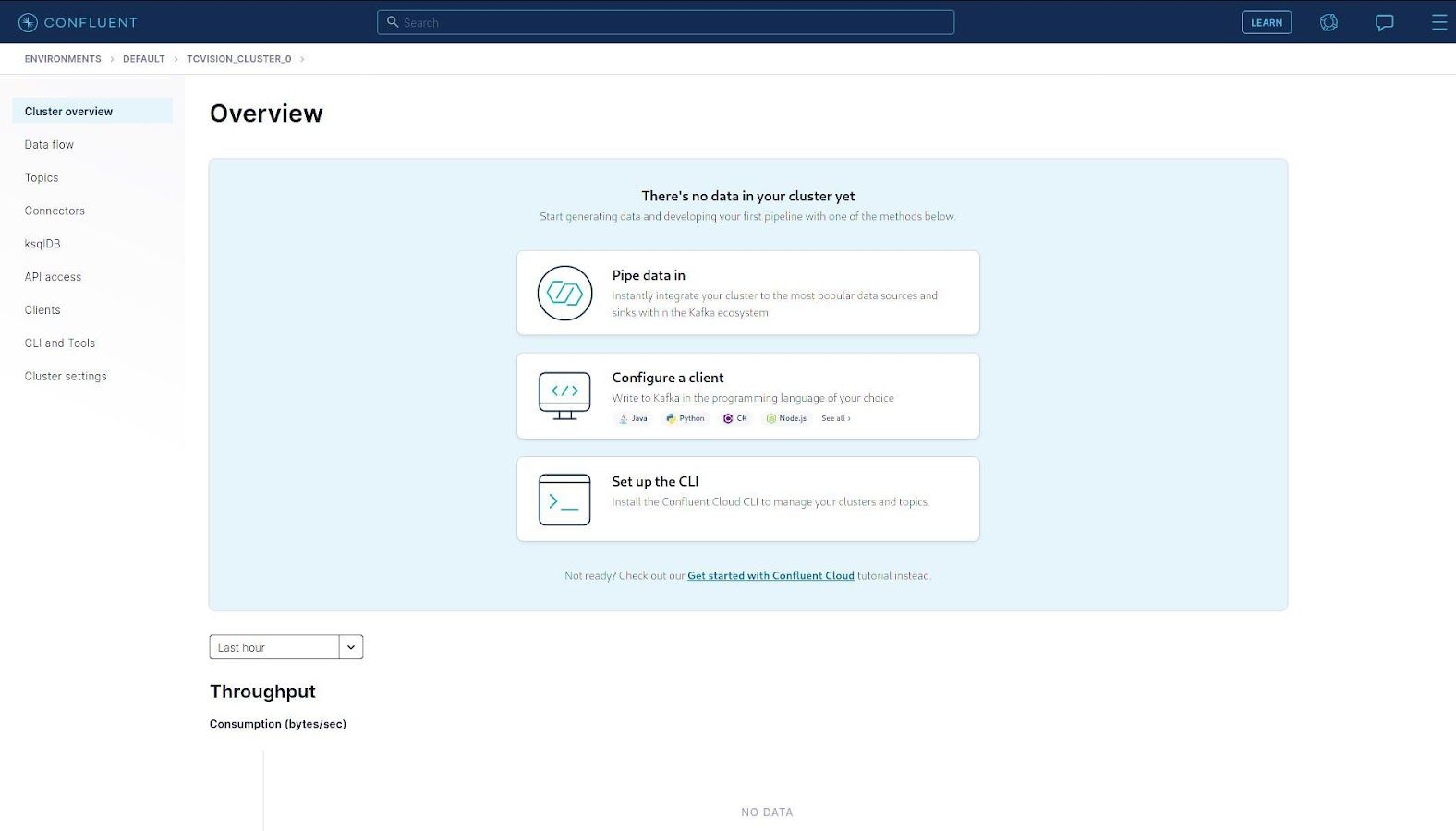
In order to use Confluent with tcVISION, the user must provide tcVISION with information about the cluster they intend to use. Specifically, the user must supply the hostname and port of the Confluent AWS virtual machine, and the credentials needed to access the cluster.
Confluent refers to the hostname and port as a bootstrap server. There can be multiple bootstrap servers for the purpose of load balancing, but a single server is used for this demonstration.
To find bootstrap server information, click Cluster Settings on the left-hand side:
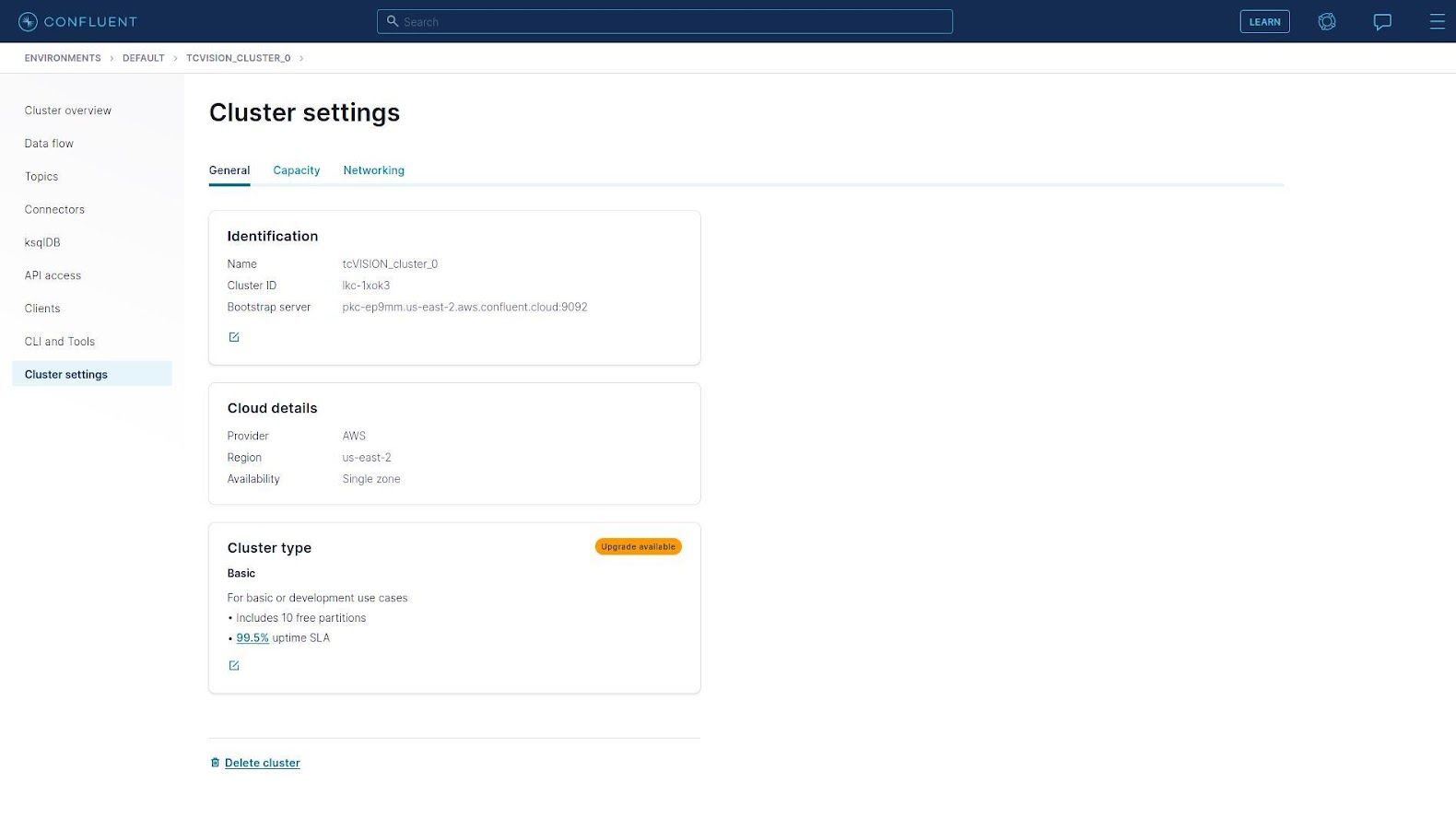
The bootstrap server will be listed under “Identification,” and includes both the AWS hostname and the port.
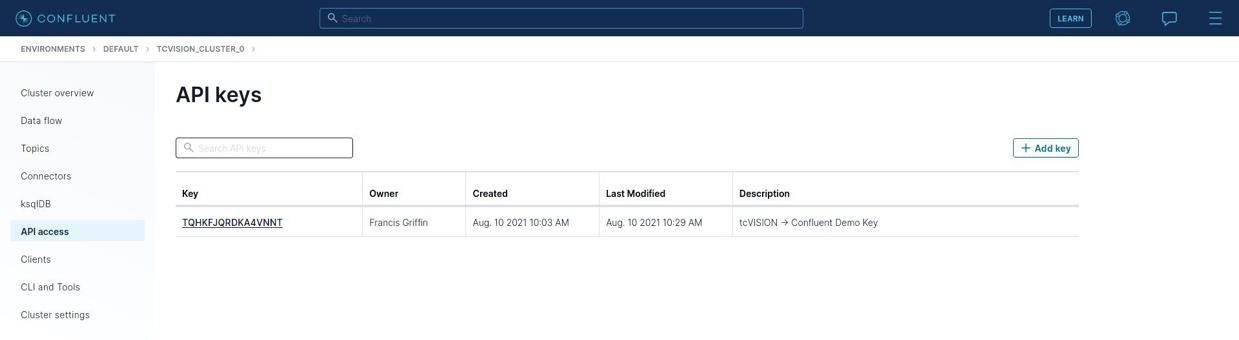
Credentials in Confluent consist of an API Key and an API Secret. These are generated for the cluster and take the place of the Confluent user ID and password used to log in. To generate a key/secret pair, click API Access on the left:
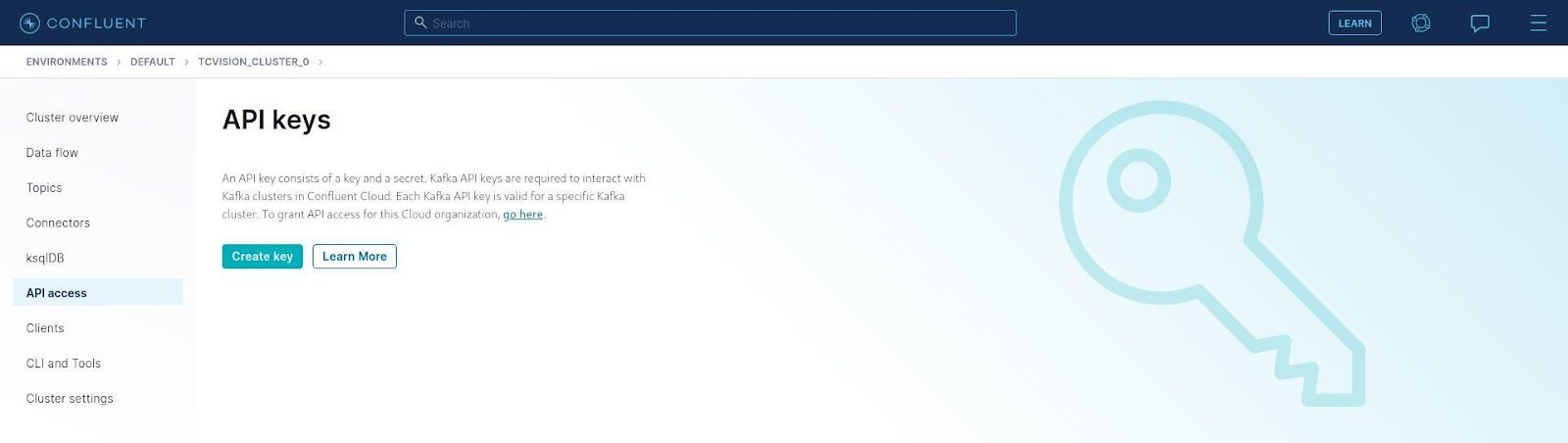
Followed by Create Key:
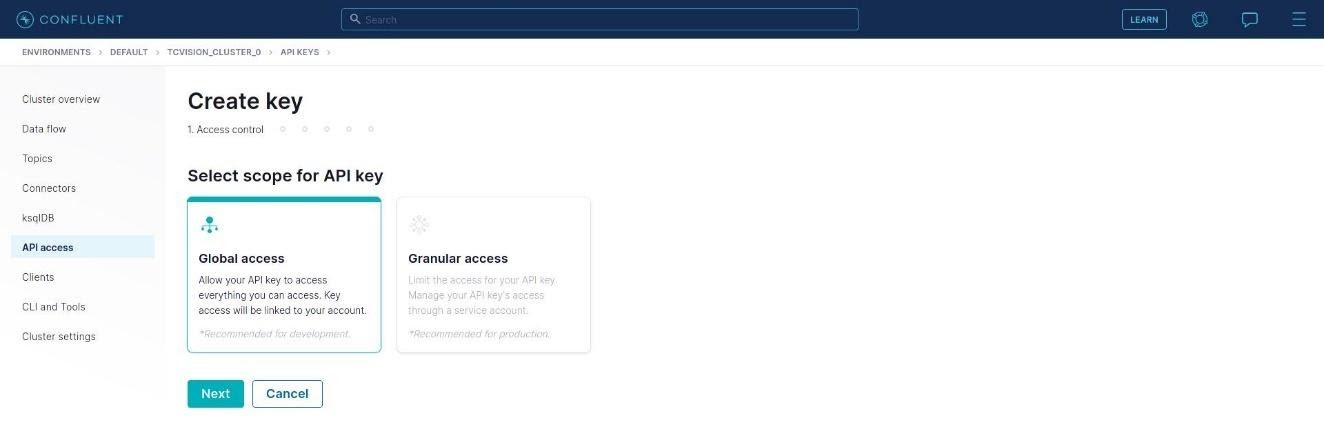
For this example, we use “Global Access” here, so click Next:
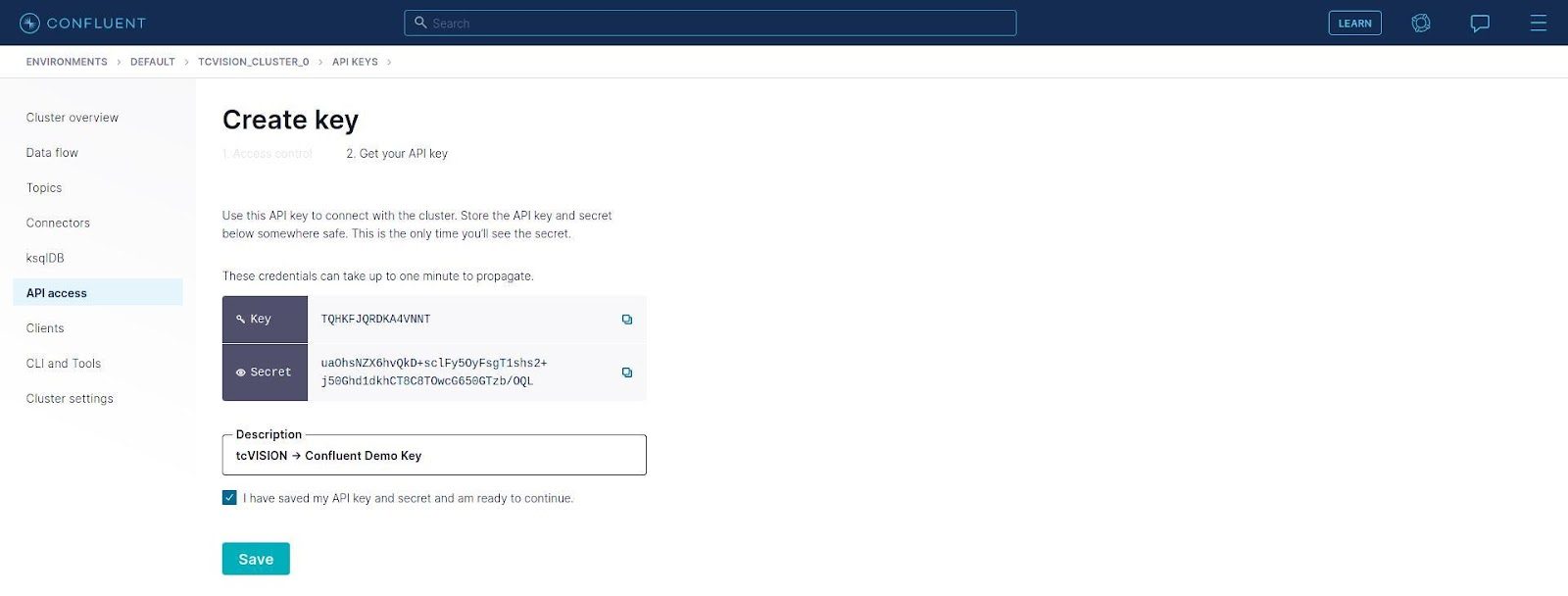
Pay particular attention to the tip about saving the key and secret somewhere safe, because once this panel is exited, there is no way to display the secret again. A descriptive string for this key/secret pair can be filled in. The key or secret text to be copied can be selected, or use the convenient icons at the end of the field to copy. Once the key/secret has been safely stored, check the box that says it has been done, and click Save. You will return to the “API Keys” panel, and the key is now displayed:
Set up Confluent and define the topic
The last thing to do is define a topic within the cluster. Confluent producers have the capability to define their own topics within a cluster, but this capability can be disabled by a Confluent configuration and is disabled in the configuration used here.
Go back to the cluster Overview:
On the left sidebar, click Topics:
Then Create Topic:
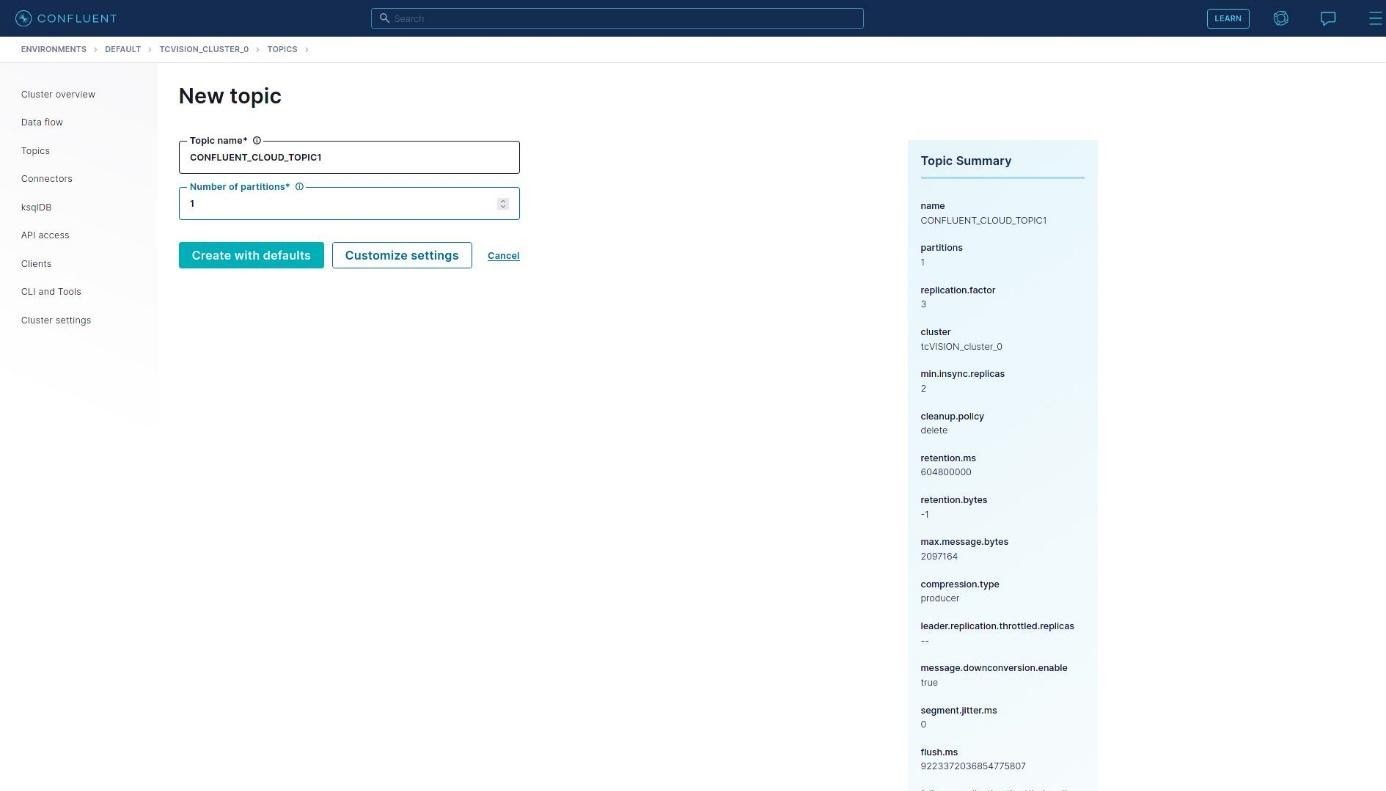
The topic name is filled in (“CONFLUENT_CLOUD_TOPIC1”), overriding the number of partitions from 6 to 1, since that is what the Confluent demo uses. Click Create with defaults:
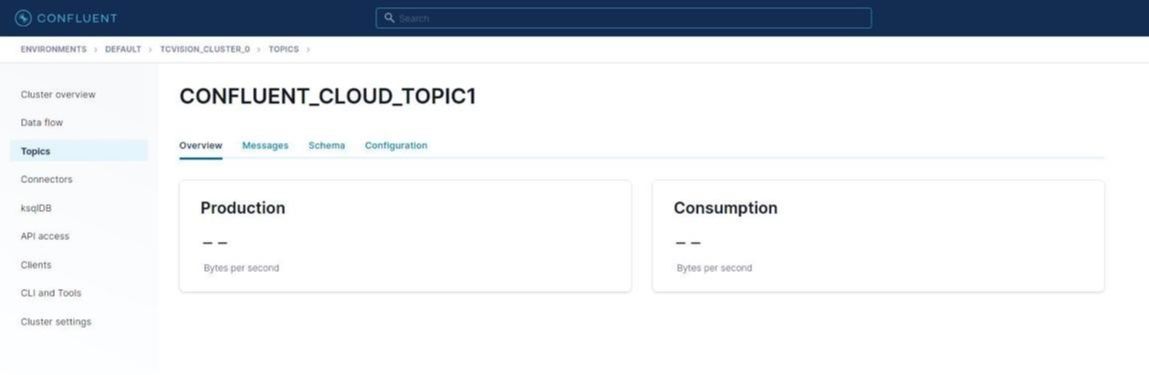
A topic is now available, which can be populated with Db2 data.
Set up tcVISION and run a bulk load of Db2 data
tcVISION’s control board is a Windows graphical user interface (GUI) that allows users to configure the replication stream between various database platforms, including the IBM mainframe and Confluent. Using the control board and built-in wizards, users can define the metadata and the mappings between the mainframe and target.
The following sequence of screens shows the steps required to create the tcVISION metadata and scripts for replicating mainframe Db2 z/OS data to Confluent.
Access the tcVISION control board:
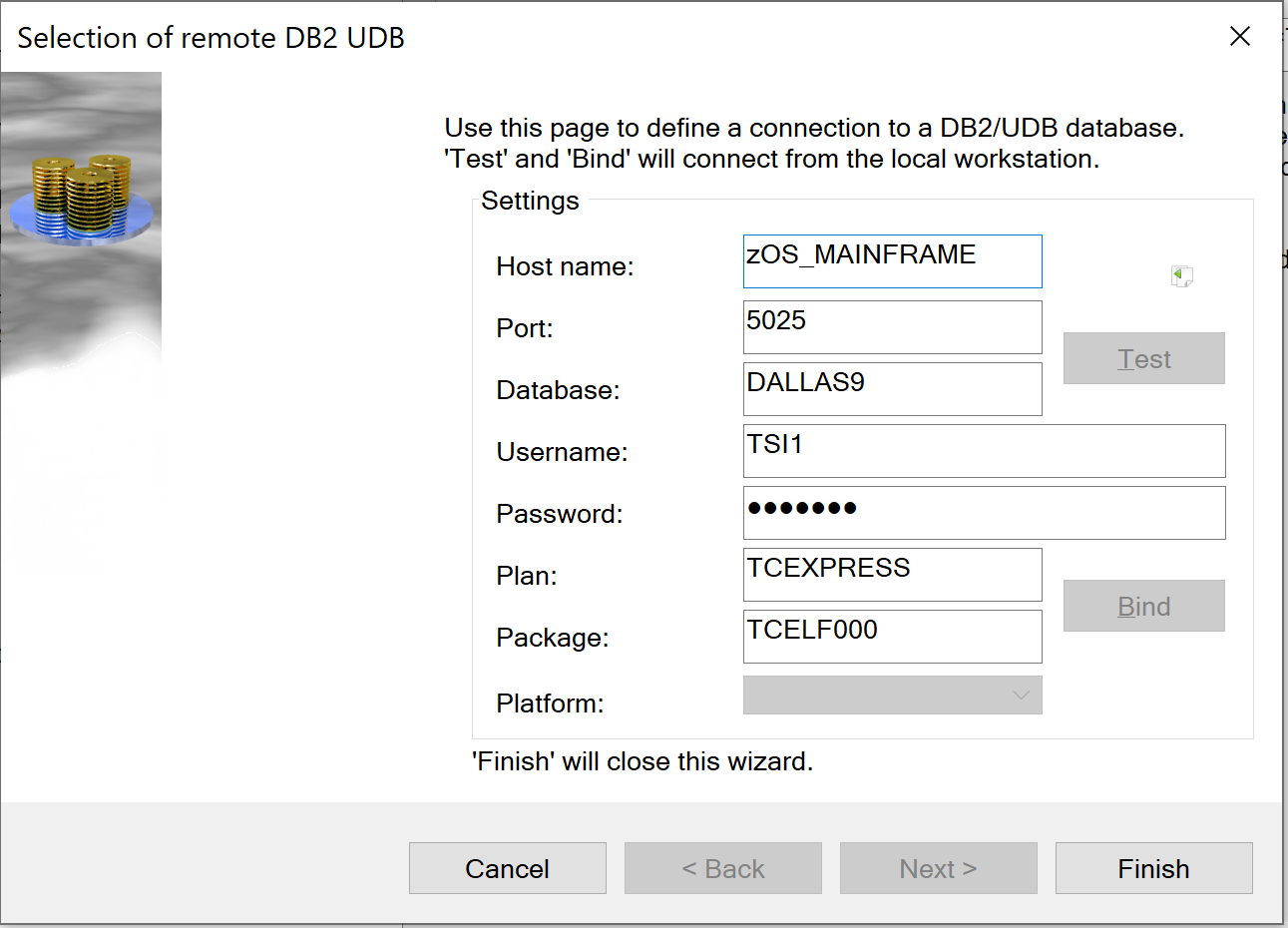
Log on to Db2 z/OS:
Create metadata that is specific to the input (Db2) and output (Kafka) and the replication definition. In this example, the Db2 table is mapped to the Confluent Cloud Kafka topic using JSON:
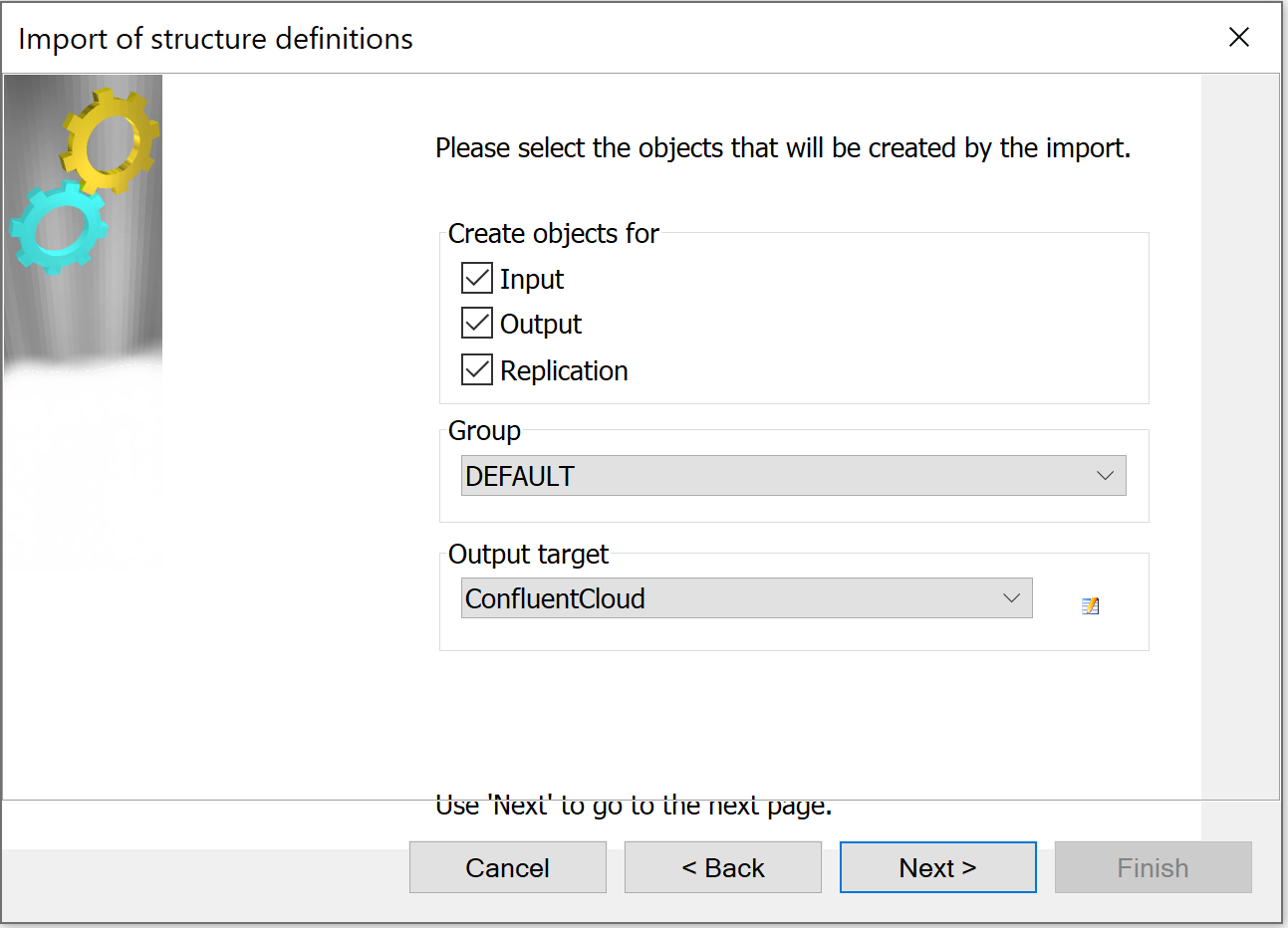
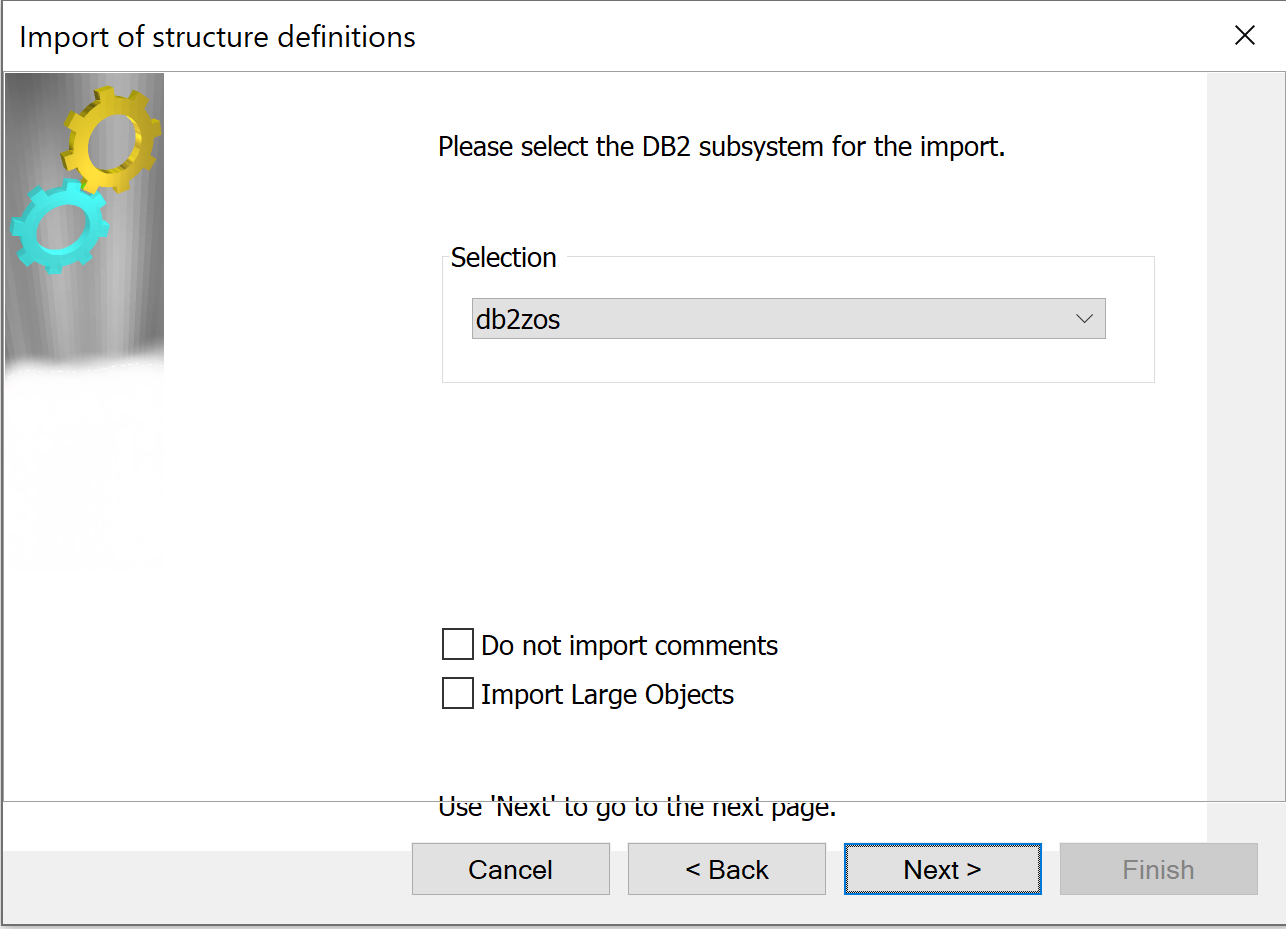
The tcVISION metadata wizard asks for the information required for the replication of the mainframe database to Confluent Cloud. For Db2 z/OS, it asks for the mainframe Db2 subsystem:
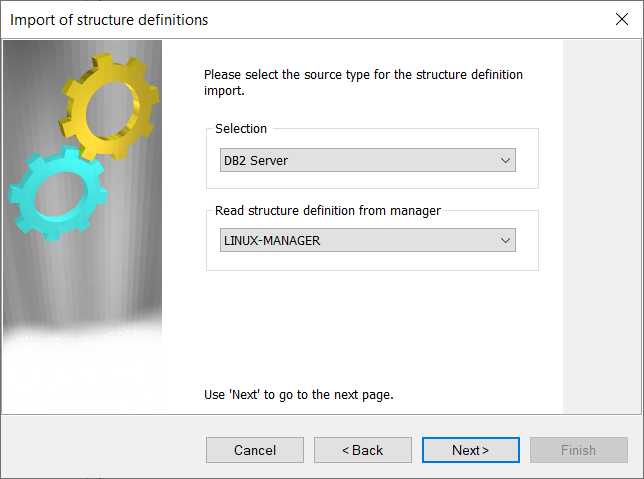
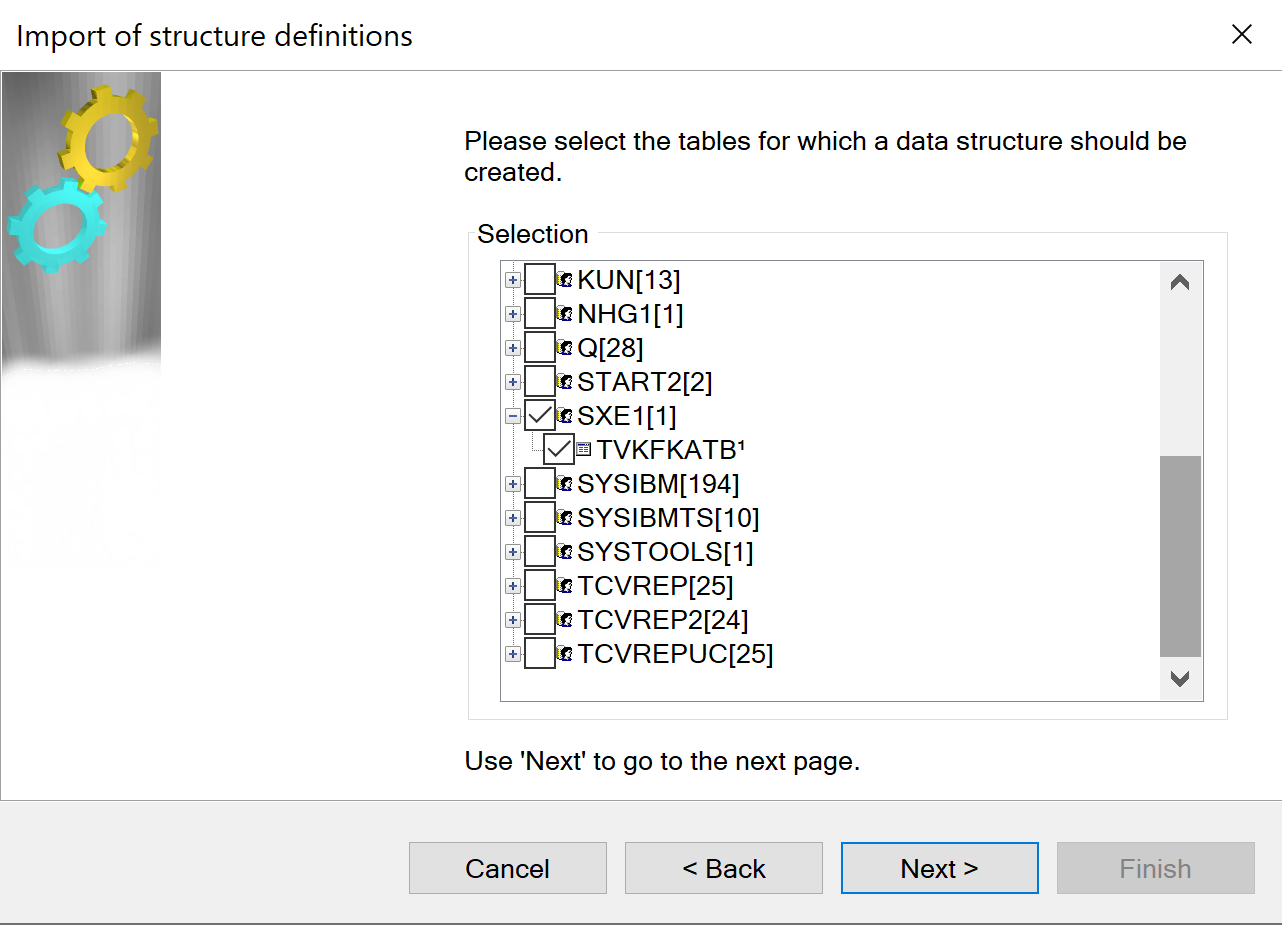
tcVISION presents the tables contained in the Db2 z/OS catalog on the mainframe. Select the schemas and associated tables for replication:
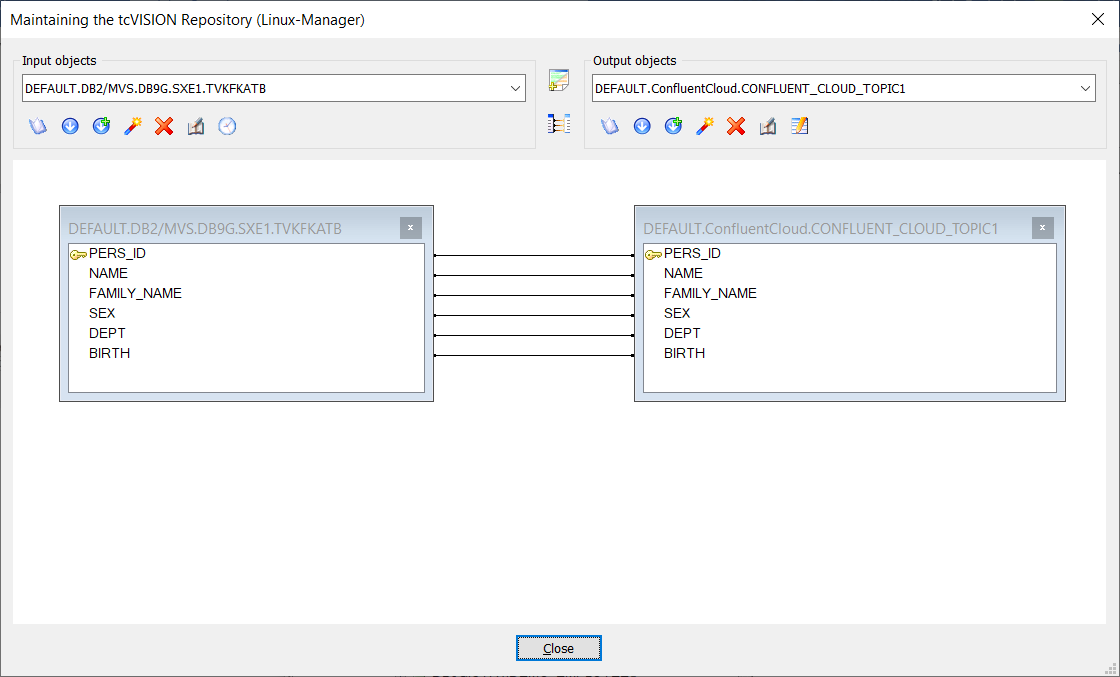
Once the required tcVISION wizard-based screens are completed, the tool automatically defines the mappings between the source and target. tcVISION’s metadata import wizard creates a default mapping that handles data type conversion issues, such as EBCDIC to ASCII, Endianness conversion, codepages, redefines data types, and more:
tcVISION data scripts are created through wizards. Data scripts control the replication of data from the source (Db2 z/OS) to the target (Confluent Cloud Kafka JSON). tcVISION bulk load scripts are a type of data script that performs the initial load of the Kafka topic. The following script shows data being accessed directly from the mainframe Db2 z/OS database. Another alternative to reduce MIPS consumption is to read the data from a Db2 image copy.
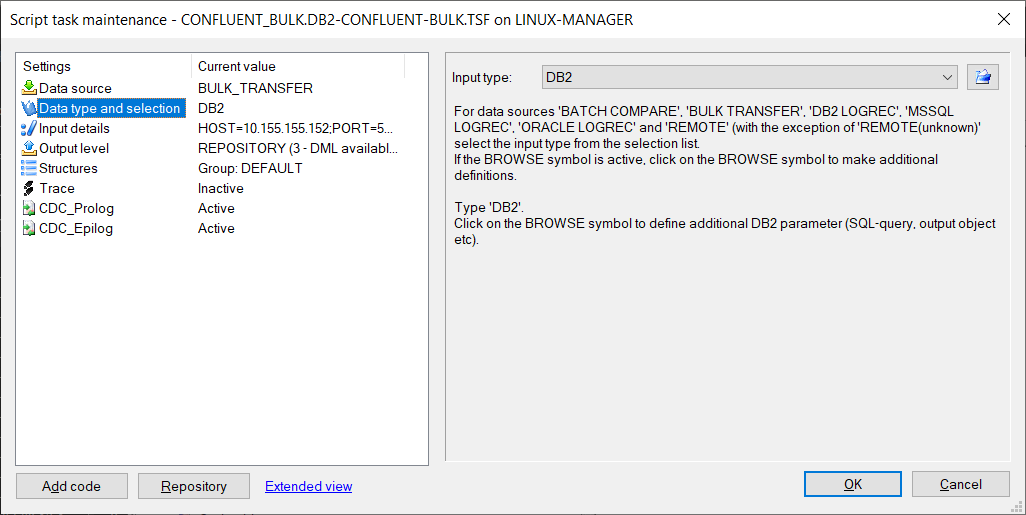
Bulk load script running:
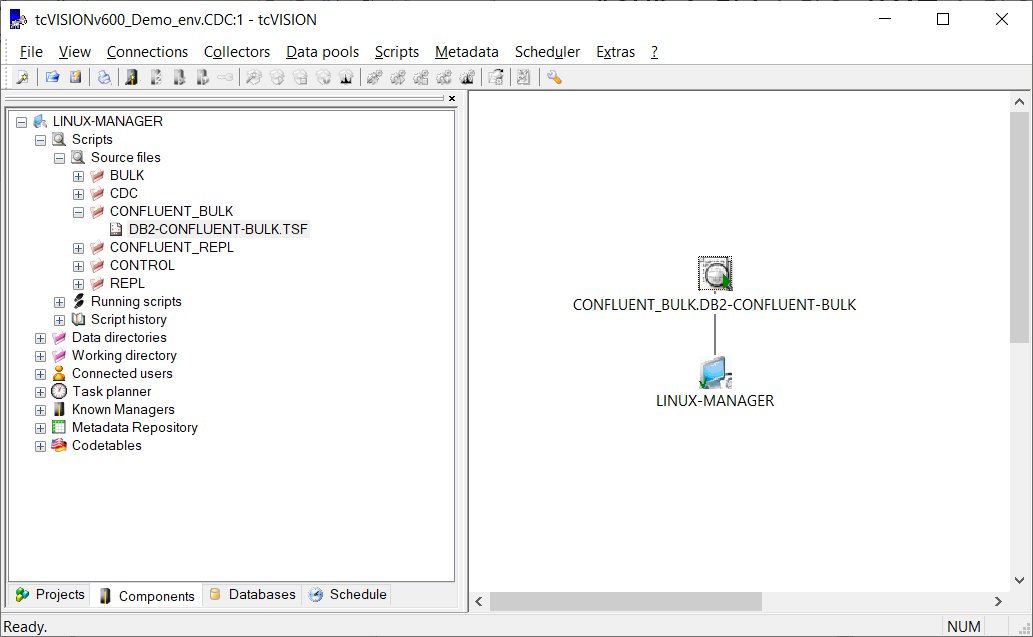
After execution of the bulk load script, replication statistics of the Db2 bulk load into the Confluent Cloud Kafka topic can be viewed:
Now that the topic has been loaded with data from Db2, it can be displayed in Confluent. To do this, navigate to the topics panel again:
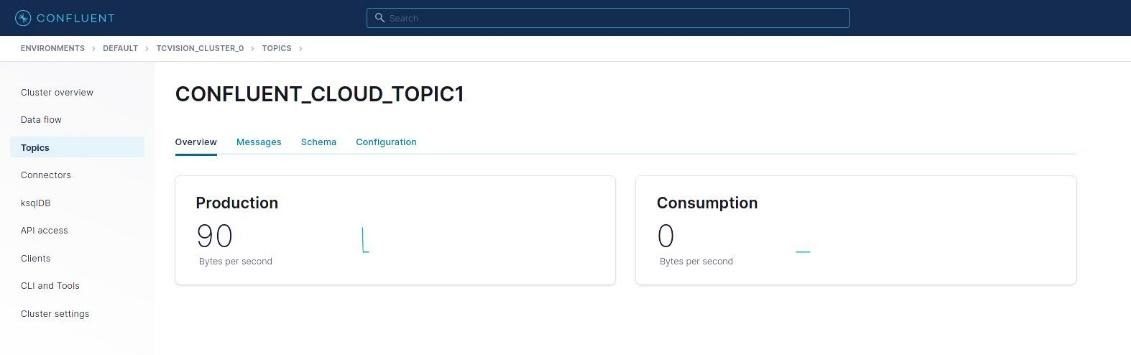
Notice that there are now statistics indicating that the tcVISION producer uploaded some data to the topic. On the horizontal menu, switch from “Overview” to “Messages” to display the messages (data records) that the tcVISION bulk load placed in the topic. The display can be filtered in various ways, but for this example, the default is used: “Jump to Offset,” which says “start displaying sequentially from this offset.” Here, an offset of 0 (start at the beginning) is specified, since we just want to verify that the Db2 data uploaded by tcVISION was actually delivered:
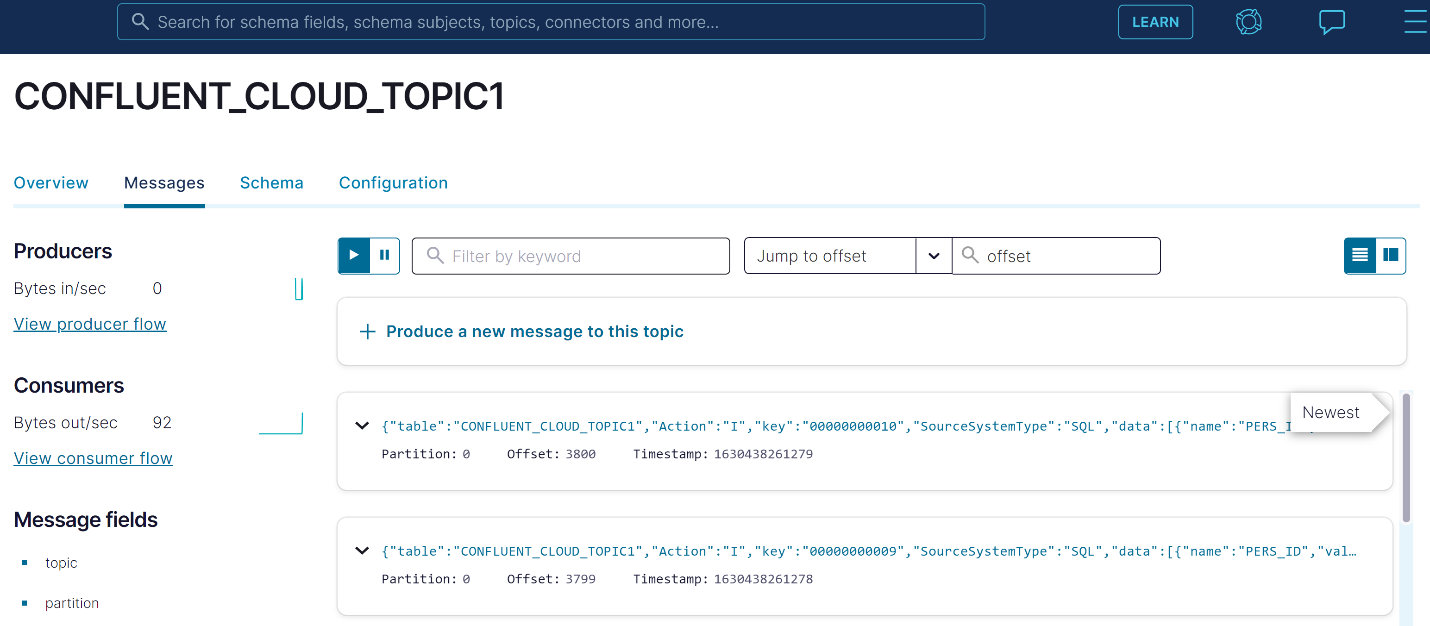
Run a change script in tcVISION to show the changes in Confluent
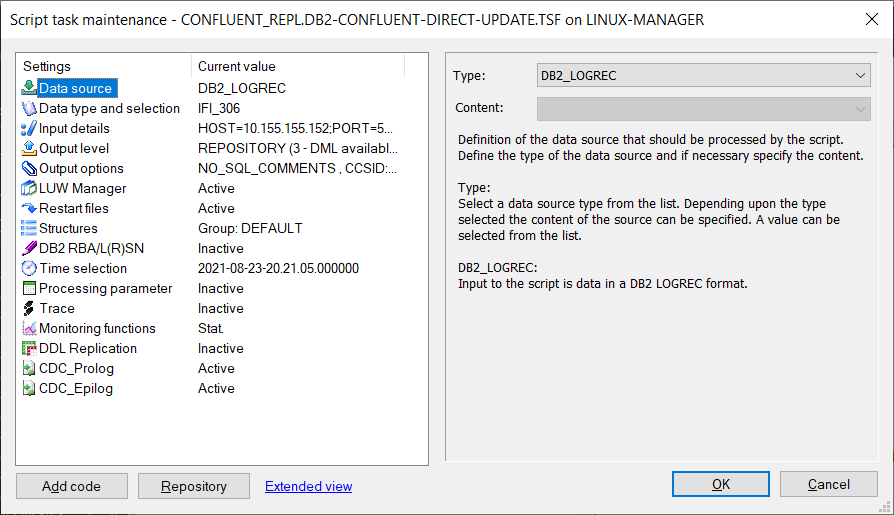
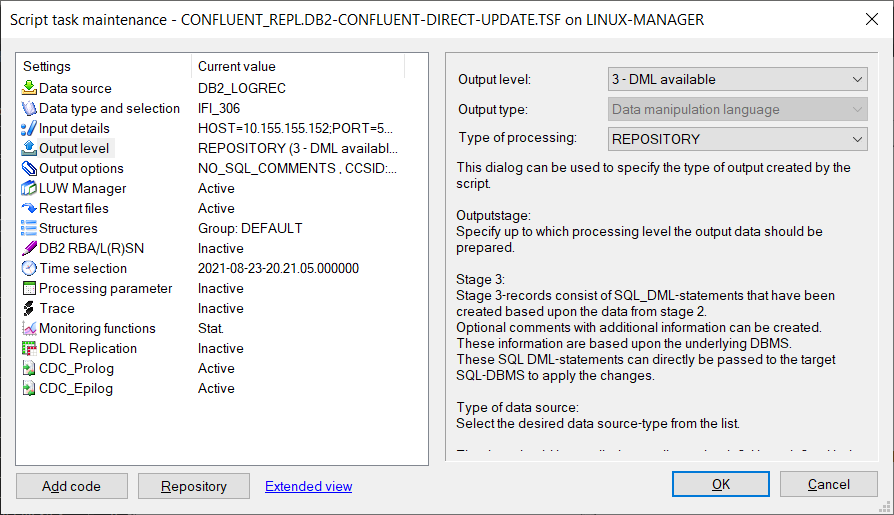
To capture ongoing changes to Db2 in real time, a Db2 z/OS CDC replication script is created.
This script captures the changes on the Db2 z/OS side and applies them into the repository where the output target is Confluent Cloud topic.
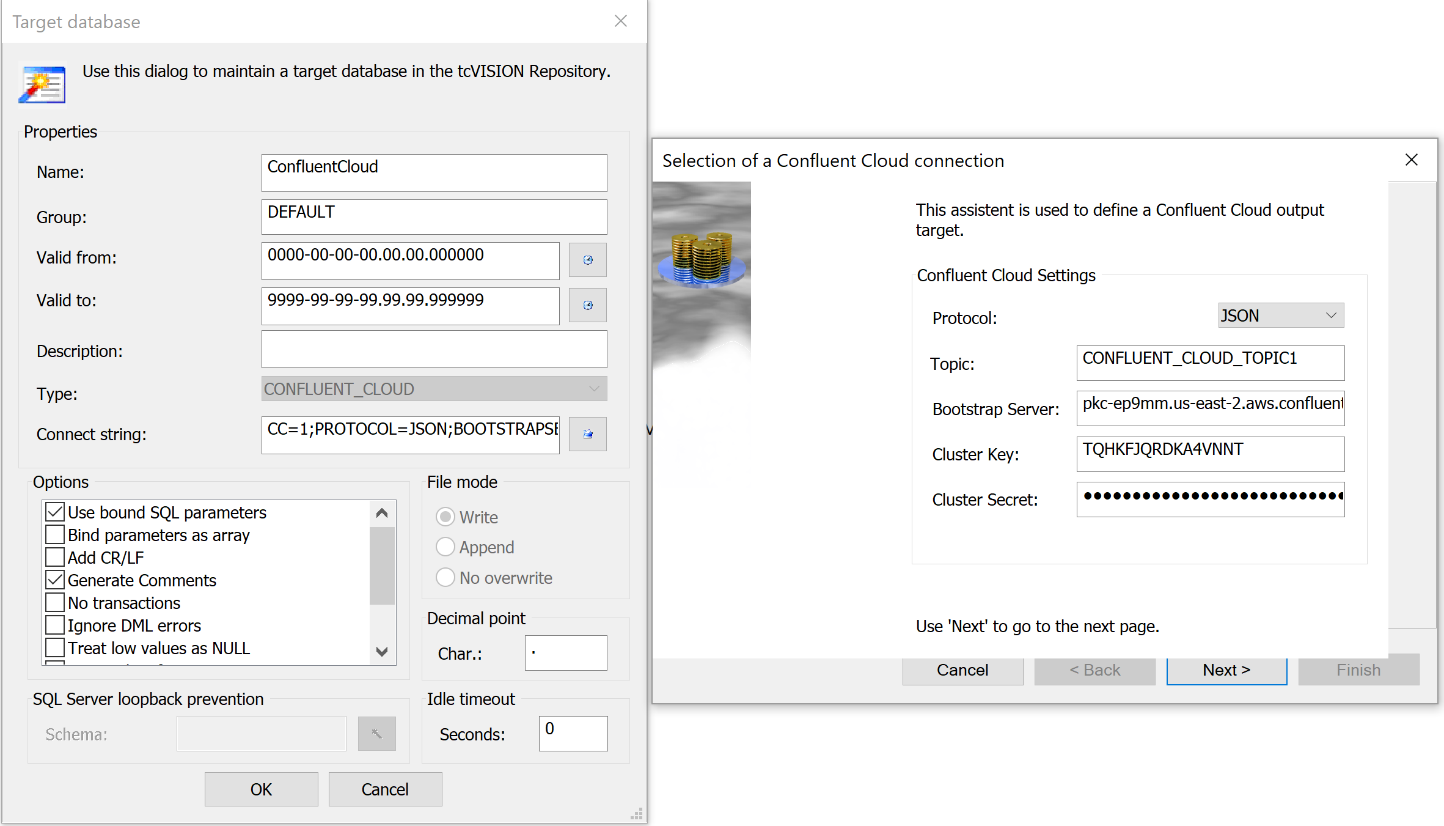
The CDC replication is initiated from the tcVISION control board. The tcVISION control board shows a graphical representation of the replication:
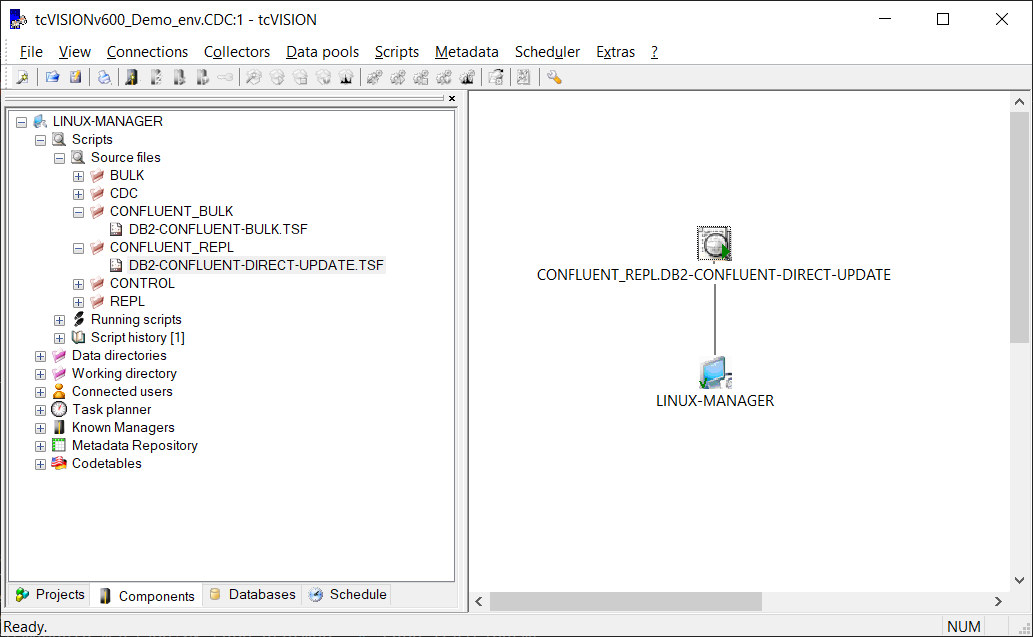
The CDC replication is now actively capturing and replicating data changes whenever they occur on the Db2 z/OS side. You can test it by making a change in the Db2 z/OS table:
********************************* Top of Data ********************************** ---------+---------+---------+---------+---------+---------+---------+---------+ UPDATE SXE1.TVKFKATB 00010004 SET DEPT = '696969' 00040029 WHERE PERS_ID = 5; 00050004 ---------+---------+---------+---------+---------+---------+---------+---------+ DSNE615I NUMBER OF ROWS AFFECTED IS 1 DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 0 ---------+---------+---------+---------+---------+---------+---------+---------+ --COMMIT; 00060019 ---------+---------+---------+---------+---------+---------+---------+---------+ DSNE617I COMMIT PERFORMED, SQLCODE IS 0 DSNE616I STATEMENT EXECUTION WAS SUCCESSFUL, SQLCODE IS 0 ---------+---------+---------+---------+---------+---------+---------+---------+ DSNE601I SQL STATEMENTS ASSUMED TO BE BETWEEN COLUMNS 1 AND 72 DSNE620I NUMBER OF SQL STATEMENTS PROCESSED IS 1 DSNE621I NUMBER OF INPUT RECORDS READ IS 4 DSNE622I NUMBER OF OUTPUT RECORDS WRITTEN IS 17 ******************************** Bottom of Data ********************************
This change is processed and replicated by tcVISION. The tcVISION control board shows the statistics highlighting that one update was performed:

Checking in Confluent, the Db2 z/OS change has successfully been propagated to the Confluent Cloud topic:
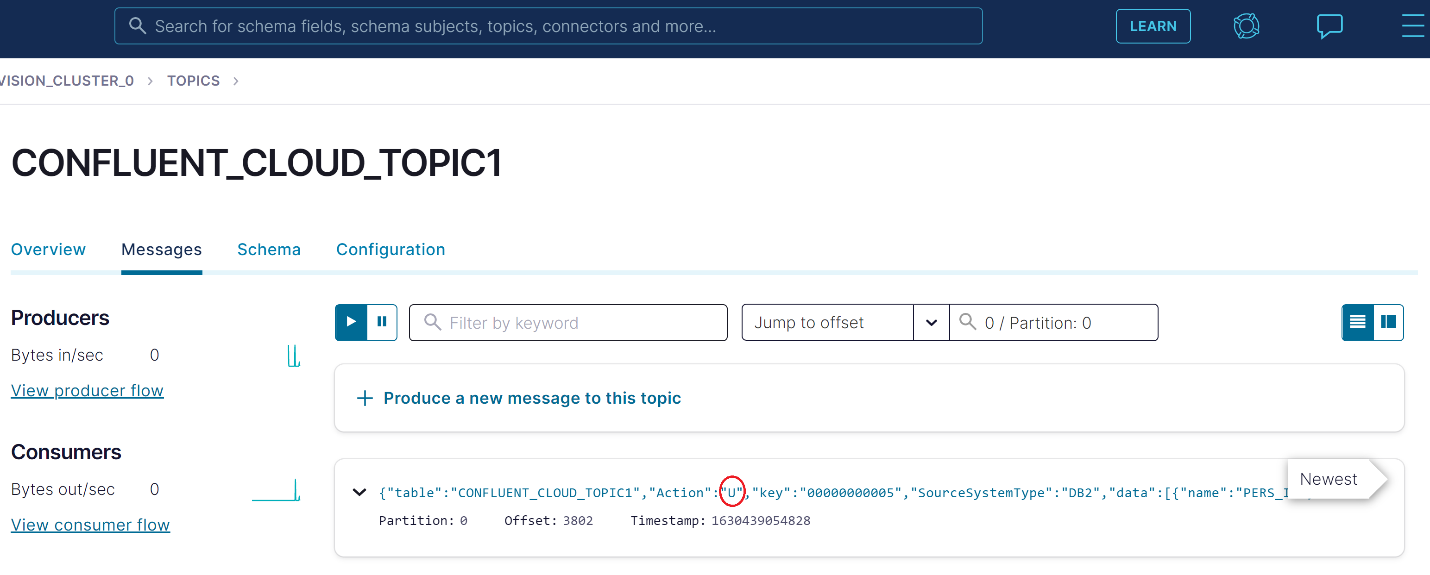
tcVISION and Confluent are better together
With tcVISION’s groundbreaking Db2 CDC connector and Confluent’s ability to serve as the multi-tenant data hub, this combination creates a very powerful solution to aggregate data from multiple sources and have data published into various Kafka topics. Sourcing events from any kind of Db2 via a connector into Confluent will set data in motion for the entire organization. Simplicity and agility are key elements of the tcVISION and Confluent “better together” story.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.