Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Modernize Your Business with Confluent’s Connector Portfolio
To win in today’s digital-first world, businesses must deliver exceptional customer experiences and data-driven, backend operations. This requires the ability to react, respond, and adapt to a continuous, ever-changing flow of data from across an organization in real time. However, for many companies, much of that data still sits at rest in silos across their organizations.
 Confluent helps unlock legacy data to enrich real-time customer experiences and data-driven operations
Confluent helps unlock legacy data to enrich real-time customer experiences and data-driven operations
Many organizations have on-premises data that need to be set in motion or monolithic application architectures that need to be transformed to a real-time paradigm. Those in financial services, insurance, healthcare, and the public sector also have regulatory requirements that mandate controls for certain data, systems, and applications to stay within their own isolated environments. Confluent’s vast connectors portfolio plays a critical role, liberating siloed data from on-premises legacy technologies to build modern, cloud-based applications. Ultimately, this helps companies accelerate their efforts to modernize their data infrastructure and seamlessly harness the flow of data across all key pieces of their organization: between applications, databases, SaaS layers, and cloud ecosystems.
Confluent’s portfolio of 120+ pre-built, expert-certified connectors enables customers to easily transition to new cloud-native ecosystems and applications like AWS, Azure, Google Cloud, Snowflake, Elastic, and MongoDB, while unlocking data and divesting from both legacy systems (e.g., MQs, ESBs, ETL, and mainframes) and expensive on-premises vendors (e.g., Oracle, SAP, IBM, Teradata, and Splunk). These cloud-based capabilities are key to running modern data platforms, and Confluent can help serve as the central nervous system to bridge wherever an organization’s data and applications reside.
With this in mind, many customers choose Confluent to connect their data systems and applications across any environment—in their cloud of choice, across multiple cloud providers, on-premises, or hybrid environments. Confluent is tapped to meet them where they are across past, present, and future technologies to help them bridge this old world of legacy systems to the new world of cloud-native technology stacks.
Bridge from legacy data infrastructure to modern, cloud-based technologies: Enabling real-time data streams for modern, cloud-based applications
A rich ecosystem of 120+ pre-built connectors
One of our main goals at Confluent is to boost the productivity of and make life easier for Apache Kafka® developers. This means delivering capabilities that help developers spend more time building real-time applications that drive the business forward and less time developing and maintaining foundational data infrastructure tools, like connectors and other integrations.
If you are a developer or architect working with Apache Kafka, you have three main options for connecting valuable data sources and sinks:
- Develop your own connectors using the Kafka Connect framework: The challenge with this approach is the time, effort, and resources required to design, build, test, and maintain each connector. Typically this process can take up to ~3–6 engineering months for each connector depending on its complexity, not to mention the technical debt created in terms of additional custom tools for your team to maintain and support.
- Leverage existing open source connectors already built by the community: The risk with this approach is that these connectors lack enterprise-level vendor testing and support, which is unacceptable for the vast majority of mission-critical applications. If you work at an organization deploying unsupported connectors into production, this is a gamble that you cannot afford to make in order to avoid downtime, data loss, and business disruption.
- Use Confluent’s expert-built and supported connectors: Confluent has an extensive library of 120+ ready-to-use connectors across the most popular data sources and sinks. These connectors are designed, built, tested, and maintained by our Kafka experts and come with our industry-leading, committer-led support.
For companies looking to modernize their data infrastructure cost effectively, while de-risking their business and freeing their developers to work on higher-value activities that drive the business forward, many of them choose option 3. That’s why Confluent has embarked on this journey to build a robust portfolio of connectors across both legacy and cloud-based applications and ecosystems. And we continue to gather extensive customer feedback to prioritize building the connectors that you need, including Elasticsearch, MongoDB, Snowflake, Microsoft SQL Server, Salesforce, Oracle CDC, cloud provider object stores (Amazon S3, Azure Blob Storage, Google Cloud Storage), and many more.
For context, in early 2019, we started with fewer than 10 connectors. Now, we have over 120 expert-built and tested connectors to help customers rapidly, reliably, and securely connect to sources and sinks across their organization. This also includes 30 connectors (and counting) available as fully managed connectors in Confluent Cloud to eliminate and free you from the operational burdens and risks of running your own connectors.
Key benefits for customers
In summary, our expert-built and tested connectors enable you to:
- Modernize your technology stack: Our connectors portfolio spans both legacy (e.g., MQs, Oracle, SAP, IBM, Tibco, and Splunk) and modern, cloud-based technologies (e.g., AWS, Azure, Google Cloud, Snowflake, Elastic, and MongoDB). This enables organizations to modernize their technology stack as they can instantly connect to popular data sources and sinks to build modern, cloud-based solutions and deliver exceptional customer experiences with data-driven, backend operations. This is critical for organizations as they compete to innovate and win in a digital-first world.
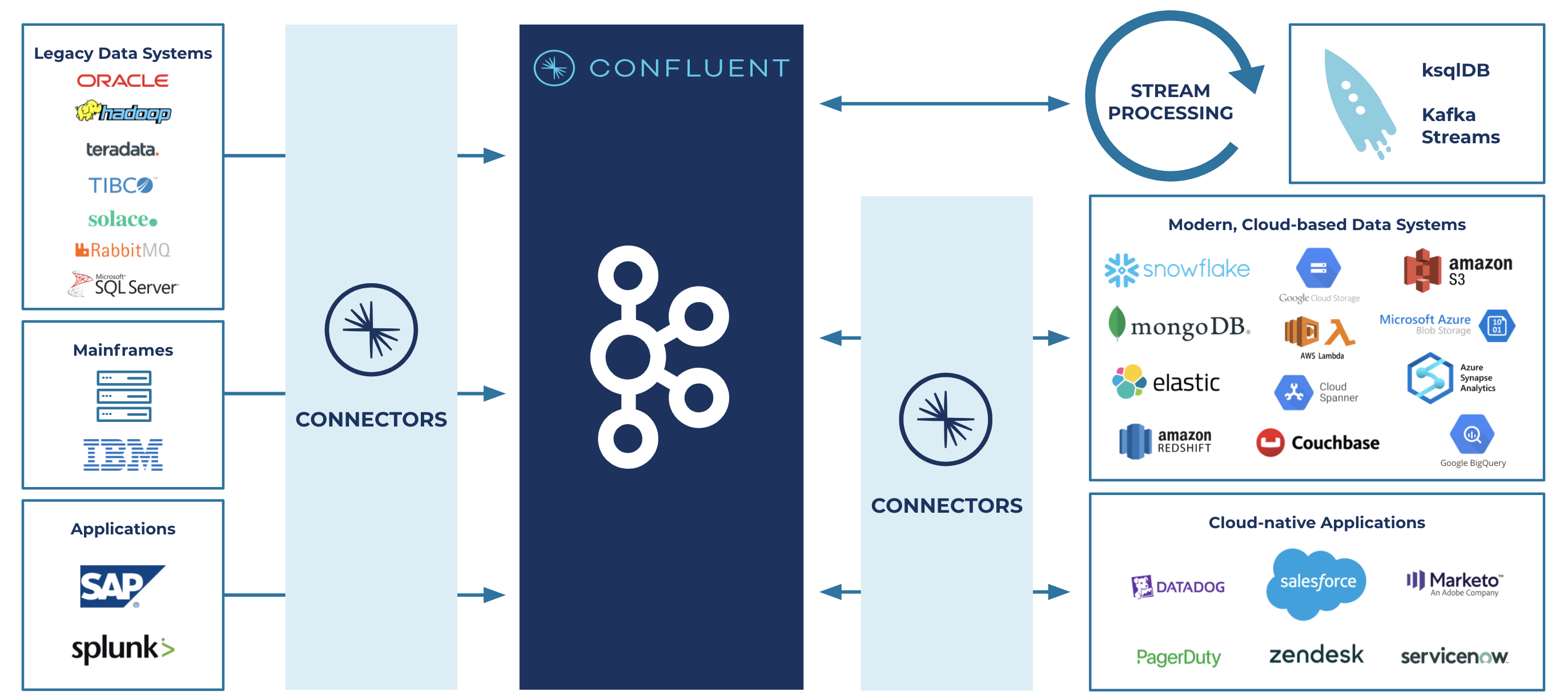 Moving from legacy systems to a modern, cloud-based tech stack
Moving from legacy systems to a modern, cloud-based tech stack - Boost developer productivity and cost effectiveness: On average, each of our connectors can save up to ~3–6 engineering months of development and maintenance efforts per connector. This includes continuous improvements in both the usability and availability of fully managed connectors for Confluent Cloud, along with the new Oracle CDC Premium Connector in Confluent Platform. Free your developers to spend their valuable time building applications that deliver business value rather than building and maintaining foundational infrastructure tools and integrations.
- Accelerate and de-risk time-to-value: Our expert-built connectors enable developers to rapidly, reliably, and securely connect to popular data sources and sinks out of the box. They guarantee data compatibility and governance, along with Role-Based Access Control (RBAC) for granular access to specific connectors. Moreover, our connectors are Kafka-native and come with our industry leading, enterprise-grade support to help you further avoid downtime, data loss, and business disruption.
Get started today!
We encourage you to explore our connectors portfolio, which features a full list of 120+ connectors, where you can find the right Kafka connectors for your use cases to modernize your data infrastructure and set your data in motion.
If you’re a Confluent Cloud customer, you can get started in three easy steps:

- Choose your connector(s): Log in to Confluent Cloud, open your cluster, and select “Connectors” from the left-side navigation, where you can view and select from our fully managed connectors spanning a variety of data systems and applications
- Configure your connector(s): Add topic and output details, along with credentials to configure the connector(s)
- Launch your connector(s): Verify the details and launch the connector to start connecting your apps and data
In addition, here’s a tutorial to help guide you through how to set up a connector in Confluent Cloud, along with our Cloud connectors documentation with quick start guides for each connector.
For those who have not yet started with Confluent, you can sign up for Confluent Cloud and receive $400 to spend within Confluent Cloud during your first 60 days. You can also use the promo code CL60BLOG for an extra $60 of free Confluent Cloud usage.*
If you’re a Confluent Platform customer, please visit Confluent Hub to download your connectors and get started today.**
**Subject to Confluent Platform licensing requirements for certain Commercial/Premium connectors
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.