Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Online, Managed Schema Evolution with ksqlDB Migrations
Making changes to a database schema is a natural part of software development. Often, it’s important to carefully manage the timing of changes and keep track of them over time. For example, your database schema may need to update in tandem with application source code when a new feature is released. Ideally, your CI/CD system can automate such workflows, and your team can coordinate database changes against version control.
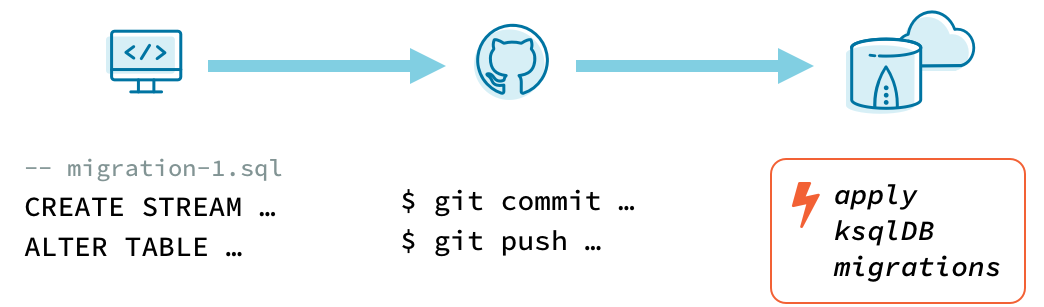
What about stream processing applications? If you want to evolve the flow of data in motion, must you set aside these familiar migration patterns? Let’s say your multi-node ksqlDB cluster is processing real-time, production data—can your team evolve running queries based on commits to GitHub?
Manage the evolution of your stream processing apps
Now you can!
Starting in standalone version 0.17.0 and Confluent Platform 6.2, ksqlDB includes tooling to make database migrations a simple, natural part of building and evolving stream processing applications. The new tools are compatible with all ksqlDB servers managed by Confluent, plus self-managed ksqlDB servers starting at version 0.15.0 or Confluent Platform 6.2.0.
$ ksql-migrations -c ./ksql-migrations.properties create initialize_order_events_stream Created V000001__initialize_order_events_stream.sql # edit V000001__initialize_order_events_stream.sql to create a new stream
$ ksql-migrations -c ./ksql-migrations.properties apply Applying migration version 1: initialize order events stream Successfully migrated Execution time: 1.2320 seconds
Let’s dig in.
The basics of ksqlDB migrations
The units of change are versioned files containing SQL commands, which we call migrations. Each migration is an incremental change that, when combined in order, allows you to create (or recreate) the database schema at a particular version.
To illustrate, imagine you are developing an order-tracking system for a fast-food chain that uses ksqlDB in Confluent Cloud to process data. Let’s call it “Real-Time Tacos.”
You have the following stream of order events and an application built on top of it that notifies each restaurant when they receive an order.
| order_events | |
| orderid | string |
| name | string |
| items | array<string> |
| cost | decimal(6, 2) |
| ordertime | timestamp |
At first, the only way to order was from the Real-Time Tacos website, but now you plan to offer deliveries through a third-party app. As part of the restaurant team, you need to update the tracking system to track these app orders as well.
Some changes are needed because the new app sends data in the following format:
| app_order_events |
|
| id | bigint |
| name | string |
| items | array<string> |
| price | decimal(6, 2) |
| ordertime | bigint |
The steps that you plan to take are:
- Create two new streams called APP_ORDER_EVENTS and ALL_ORDER_EVENTS
- Stream the data from ORDER_EVENTS and APP_ORDER_EVENTS into ALL_ORDER_EVENTS
- Update the order tracking system to read events from ALL_ORDER_EVENTS instead of ORDER_EVENTS
You could just run each of these changes all at once and get the desired result, but you would lose valuable information on the steps you took to reach the current state. Having a tool to automatically apply and keep track of migrations allows you to recreate a schema from scratch, integrate with a CI/CD system, or see what a previous version of a schema looked like .
At a high level, the ksql-migrations tool works by reading SQL files containing migrations and running them one by one, while tracking progress in a ksqlDB stream and table.

Let’s take a closer look at how this tool might be used by the Real-Time Tacos team.
Tutorial: ksqlDB migrations basics
Start off by setting up your ksqlDB application to use migrations. Running the following command creates a new directory called orders, which contains an empty directory called migrations and a file named ksql-migrations.properties.
ksql-migrations new-project orders <server-url>
ksql-migrations.properties can be edited to include configurations such as authentication information for accessing your ksqlDB server and other options specific to the migrations tool. For a ksqlDB server running on Confluent Cloud, add the following configurations to ksql-migrations.properties:
ksql.auth.basic.username=<CCLOUD_KSQLDB_APIKEY> ksql.auth.basic.password=<CCLOUD_KSQLDB_APIKEY_SECRET> ksql.migrations.topic.replicas=3 ssl.alpn=true
The migrations directory will contain all of the migration files.
Next, initialize the ksqlDB stream and table used by the tool to track migration metadata.
ksql-migrations initialize-metadata -c orders/ksql-migrations.properties
Our ksqlDB cluster now contains a stream called MIGRATION_EVENTS and a table called MIGRATION_SCHEMA_VERSIONS. Now you can start building the order_events stream. Run the following:
ksql-migrations create initialize_order_events_stream -c orders/ksql-migrations.properties
This creates an empty file in the migrations directory called V000001__initialize_order_events_stream.sql.
Open this file and add the following command:
CREATE STREAM ORDER_EVENTS ( orderid STRING, name STRING, items ARRAY<STRING>, cost DECIMAL(6, 2), ordertime TIMESTAMP ) WITH ( kafka_topic='order_event', partitions=1, value_format='json' );
Apply the migration by running the following:
ksql-migrations apply -a -c orders/ksql-migrations.properties
You now have a stream called ORDER_EVENTS. The -a option in the command instructs the tool to apply all migration files, which in this case is just V000001__initialize_order_events_stream.sql.
To obtain the same result, we could have also used the option -n, which applies the next unapplied migration file, -u 1, which applies all migrations up to and including version 1 or -v 1, which applies version 1.
Evolving a ksqlDB application
Let’s upgrade our ksqlDB application to use the new data from the delivery app. We will do this over two migrations—one to create the new streams and one to write data to ALL_ORDER_EVENTS. Run the following commands:
ksql-migrations create create_new_streams -c orders/ksql-migrations.properties ksql-migrations create populate_all_order_events -c orders/ksql-migrations.properties
This creates two blank migration files called V000002__create_new_streams.sql and V000003__populate_all_order_events.sql. Write the following commands into V000002__create_new_streams.sql:
CREATE STREAM APP_ORDER_EVENTS ( id BIGINT, name STRING, items ARRAY<STRING>, price DECIMAL(6, 2), ordertime BIGINT ) WITH ( kafka_topic='app_order_event', partitions=1, value_format='json' );
CREATE STREAM ALL_ORDER_EVENTS ( orderid STRING, name STRING, items ARRAY<STRING>, cost DECIMAL(6, 2), ordertime TIMESTAMP, purchase_method STRING ) WITH ( kafka_topic='all_order_events', partitions=1, value_format='json' );
And write the following commands into V000003__populate_all_order_events.sql:
INSERT INTO ALL_ORDER_EVENTS SELECT orderid, name, items, cost, ordertime, 'WEBSITE' AS PURCHASE_METHOD FROM ORDER_EVENTS;
INSERT INTO ALL_ORDER_EVENTS SELECT CAST(id AS STRING) AS ORDERID, name, items, price AS COST, FROM_UNIXTIME(ordertime) AS ORDERTIME, 'APP' AS PURCHASE_METHOD FROM APP_ORDER_EVENTS;
Running ksql-migrations apply -a -c orders/ksql-migrations.properties results in both files being applied.
We can see metadata about the migrations by running ksql-migrations info -c orders/ksql-migrations.properties:
-------------------------------------------------------------------------------------------------------------------------------------------------- Version | Name | State | Previous Version | Started On | Completed On | Error Reason -------------------------------------------------------------------------------------------------------------------------------------------------- 1 | initialize order events stream | MIGRATED | <none> | 2021-03-31 12:18:39.080 PDT | 2021-03-31 12:18:39.446 PDT | N/A 2 | create new streams | MIGRATED | 1 | 2021-04-04 13:27:02.210 PDT | 2021-04-04 13:27:02.404 PDT | N/A 3 | populate all order events | MIGRATED | 2 | 2021-04-04 13:29:45.447 PDT | 2021-04-04 13:29:45.682 PDT | N/A --------------------------------------------------------------------------------------------------------------------------------------------------
Create a ksqlDB staging environment
One useful application of migrations is to create copies of a ksqlDB application to use for testing or development. In our example, we had some streams running in a ksqlDB application in Confluent Cloud, but if we want to run tests or experiment with some queries, we probably don’t want to do that with an application used for production.
Instead, we could start another ksqlDB instance, make a copy of the orders directory, edit the properties file to point to our new server, and run ksql-migrations apply -a -c <path-to-new-config-file>. That would create a representation of our production ksqlDB application that we can use in isolation. Changes could be staged and verified in the new environment, then promoted to the production application.
Version control and CI/CD
Managing migrations can be further automated by integrating with a CI/CD system. Suppose that Real-Time Tacos uses Git for version control and GitHub Actions to manage builds, for example.
With the migrations directory committed to the repository, we can ensure that new commits don’t change the content of migration files that have already been applied to our ksqlDB server. To accomplish this, configure GitHub Actions to run ksql-migrations validate --config-file <path-to-migrations-config> whenever a change is pushed.
Now that the state of the repository is validated against ksqlDB, the GitHub Actions workflow can run ksql-migrations apply -a --config-file <path-to-migrations-config> to apply any new migrations.
With this system in place, the Real-Time Tacos team can manage application changes across their website, order-handling logic, and ksqlDB schema. Looking across commit history, they have unified snapshots of their digital product as it evolves to put data—and tacos—in motion.
Check out this sample repository for a functional demonstration of the CI/CD workflow described above.
Next steps
For more information on the migration tool, read the documentation. To get started, try ksqlDB today via the standalone distribution or with Confluent.
We’d love to hear your feedback about the migrations tool. Join the community to ask a question and get involved.
The ksqlDB team wishes to extend gratitude to community member Jens Günther for creating ksqldb-migrate-cli and sharing foundational ideas and inspiration with the team.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.