Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Why ZooKeeper Was Replaced with KRaft – The Log of All Logs
Why replace ZooKeeper with an internal log for Apache Kafka® metadata management? This post explores the rationale behind the replacement, examines why a quorum-based consensus protocol like Raft was utilized and altered to become KRaft, and describes the new Quorum Controller built on top of KRaft protocols.
Why replace ZooKeeper?
In 2012, work was underway to begin implementing the current existing Kafka controller for intra-cluster replication. Since then, the controller design has mostly remained the same: Each cluster has a single node acting as a controller, which is elected by ZooKeeper watchers. It doesn’t only store topic partition logs and handle consume/produce requests like other brokers, but it also maintains cluster metadata like broker IDs and racks, topic, partition, leader and ISR information, and cluster-wide and per topic configs, as well as security credentials. It persists this information in ZooKeeper as a source of truth, and as a result most of ZooKeeper’s read and write traffic is done by the controller.
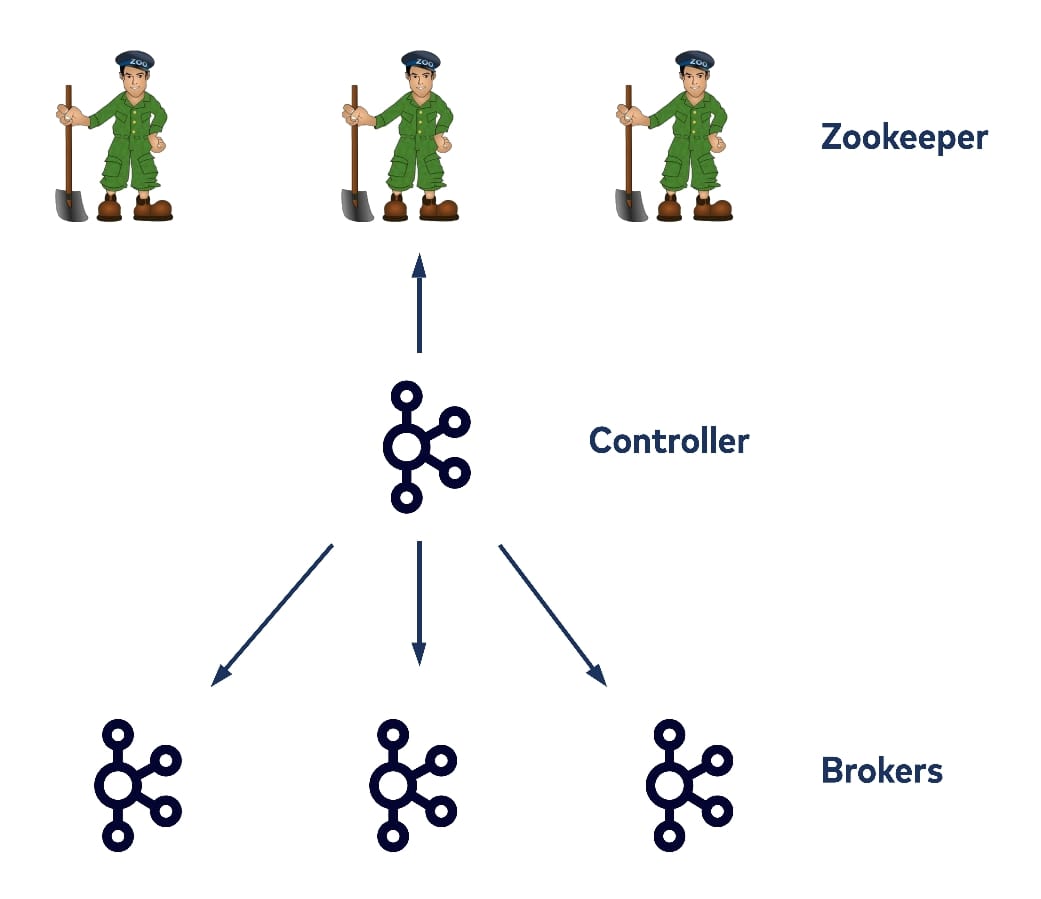
Non-controller brokers also talk to ZooKeeper directly from time to time, for example when the leader updates the ISR information. As a result, the controller registers watchers on ZooKeeper for any metadata changes. The metadata changes can be made either by the controller itself, by other brokers, or by the clients, who can also write directly to ZooKeeper as well.
In most cases, when such a watcher fires, the controller handles it with a single-threaded loop and propagates the updated metadata to all other brokers. If you are familiar with the history of Kafka development, you may be aware that in the past other clients such as consumers could also talk with ZooKeeper directly. Today that access has been replaced by talking with the brokers instead. The main reason this was done was to reduce the read/write load on the ZooKeeper servers. However, even with most ZooKeeper access done by only a single controller today, as the number of brokers and the number of topic partitions that we’d like to host within a cluster increases, there are still some scalability bottlenecks related to the read and write traffic on ZooKeeper—because it is still used as Kafka’s source of truth for metadata.
(Old) controller scalability limitation: broker shutdown
To illustrate such scalability limitations, consider a broker shutdown with the old controller. Assume there is just one topic partition with three replicas on brokers one, two, and three. All three replicas are in sync so all are in the ISR list. The left-hand side broker is the current leader but wants to shut down. To do this, it needs to send a request to the controller. The controller will figure out which topic partitions the broker currently hosts and then will try to update the metadata. It also needs to select a new leader for those hosted topic partitions on the old leader. The updated ISR information is then written to ZooKeeper and after that, the controller will propagate the new metadata to all remaining brokers. Thus we have two types of requests sending from the controller: UpdateMetadata (updating the local metadata cache for all brokers) and LeaderAndISR (for all replicas of the corresponding partitions, in the interest of updating their new leader and ISR list).
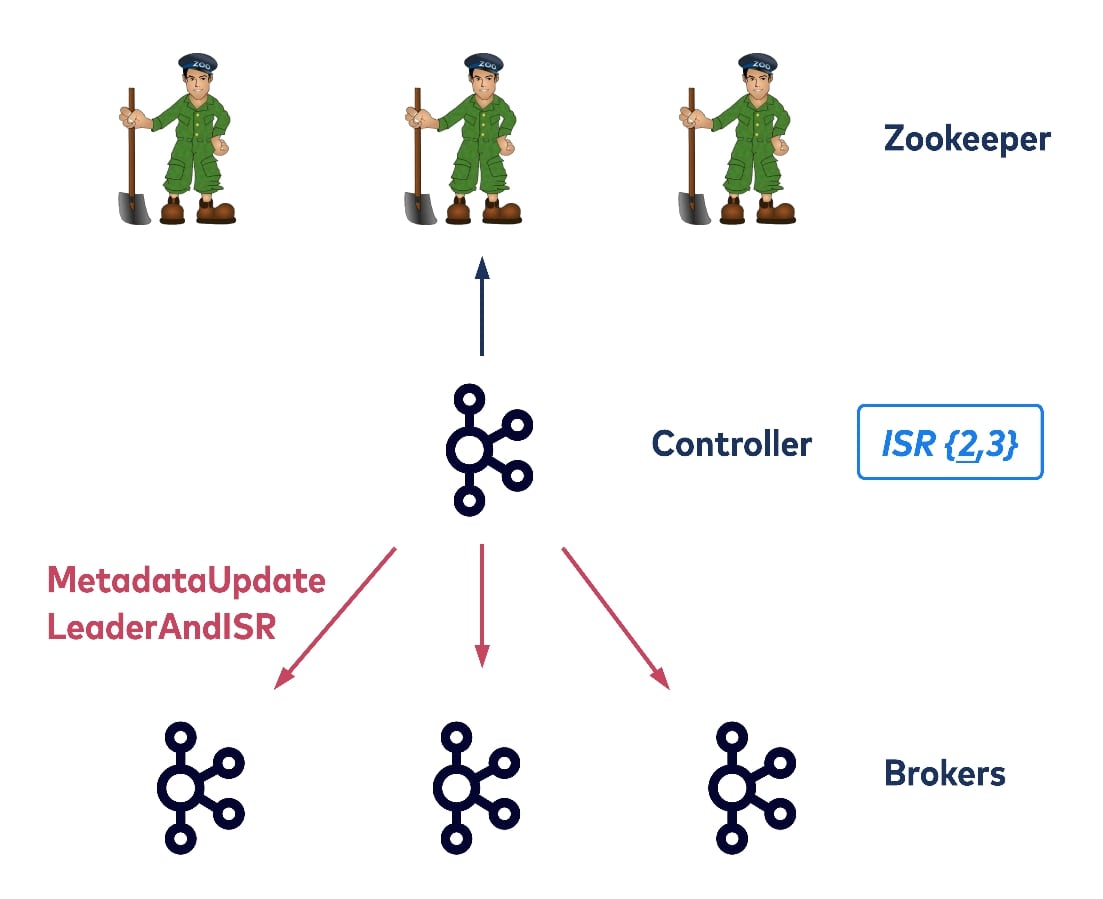
So after the controller has removed broker one from all of the topic partitions that it currently hosts, it can then allow broker one to shutdown. In this example, the shutting down broker only hosts one partition, but in practice it could host thousands of partitions, and the controller would need to write to ZooKeeper to update the metadata for each of the hosted partitions. This could take seconds or even more. In addition, the controller would need to propagate the changed metadata to all of the other brokers, one at a time. Finally, if clients are trying to find the new leader by randomly consulting the brokers, they may or may not succeed, depending on whether the latest information has reached the broker they consulted. This could cause the client’s request to time out.
(Old) controller scalability limitation: controller failover
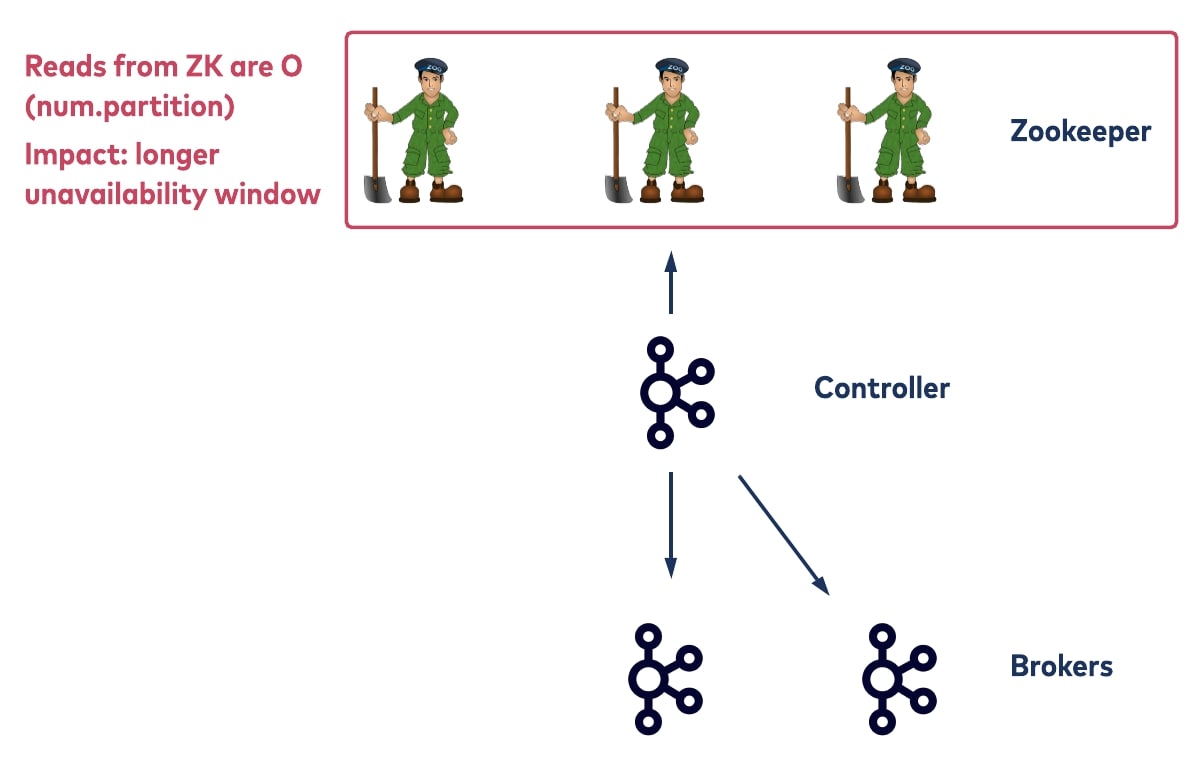
For another scalability limitation, consider a scenario where the old controller unexpectedly crashes. When this happens, the registered ZooKeeper watcher will fire, and all brokers will be notified. Upon notification, the other brokers will try to register themselves with ZooKeeper and whoever gets there first will become the new controller. The first thing the new controller will do is to fetch metadata from ZooKeeper, including all of the topic partition information across all of the ZooKeeper paths. After that, it will update all of the topic partition metadata that the crashed controller used to host and will write the new metadata back to ZooKeeper. Then it will propagate the new metadata to the other brokers.
In this procedure, the primary bottleneck is the time the new controller needs to fetch the metadata from ZooKeeper. This is linear to the total number of topic partitions that the cluster currently has. Before this bootstrap process is done, the new controller is not able to handle any admin requests such as partition rebalancing. This means a long unavailability window.
(Old) controller scalability limitations summarized
- Most of the metadata change propagations between the controller and the brokers are linear with the number of topic partitions involved.
- The controller needs to write updated metadata to ZooKeeper in order to persist it, which is also linear to the amount of metadata to be persisted.
- There are other challenges with using ZooKeeper as the metadata store, such as a size limit on Znodes; a maximum number of watchers; and extra validation checks for brokers because each broker maintains its own metadata view, which can be divergent when updating is delayed or reordered.
- It’s a pain to secure, upgrade, and debug. Simplifying distributed systems adds to their longevity and stability.
Why choose KRaft?
The goal is to construct a solution that will stand up to thousands of brokers and millions of partitions. But first, we need to step back and look at what we are actually storing with ZooKeeper.
At first glance, it looks like we are storing the current snapshot of metadata from various ZooKeeper paths. However, with all of the watchers and the path versions, what we are really keeping track of is a sequence of the metadata change events, aka a metadata log. In fact, behind the ZooKeeper APIs, all written data is maintained as a transaction log as well.
Implementing a metadata log
So instead of keeping this metadata log behind the scenes in Zookeeper, why not store the log in Kafka itself where we can access it directly? After all, logs are the one thing Kafka is really good at. What about letting the controller maintain this metadata log directly as another internal Kafka topic? This would mean that multiple operations that are chained to metadata could be naturally ordered by the offsets of the appended log entries, and batched together with asynchronous log I/Os to achieve better performance.
The metadata change propagation would be done by brokers replicating the metadata changelog instead of via RPCs. This means you wouldn’t need to worry about divergence anymore, since each broker’s locally materialized view of the metadata would be eventually consistent as they are from the same log, and also versioned at a given time by the offset of the metadata log they have kept pace with.
Another benefit is that this would separate the controller’s metadata log management from the other data logs (isolate control plane from data path)—with separate ports, request handling queues, metrics, threads, etc.
Finally, by forming a small group of brokers to synchronously replicate the metadata log, we could end up with a quorum of controllers instead of a single controller. In this model, when the current lead controller fails over to another controller within the quorum, we would only need a very short bootstrap time for the new controller since it would already have the replicated metadata log as well. Thus, this metadata log, managed by a quorum of controllers and replicated by all brokers, would become the core metadata log of all other data logs.
Primary-backup vs. quorum replication
Now let’s think about how we should keep this “log of all logs” in sync within replicas. Kafka’s existing data log replication leverages the “primary-backup” replication algorithm, where a single leader replica takes all of the incoming writes and tries to replicate them to other replicas, as its followers. After the followers have acknowledged replicating the write, the leader considers it committed and returns to writing to its client. So one option is to follow the same idea for replicating the meta log as well, i.e., waiting for all replicas to get the write before committing/acknowledging back to the writer.
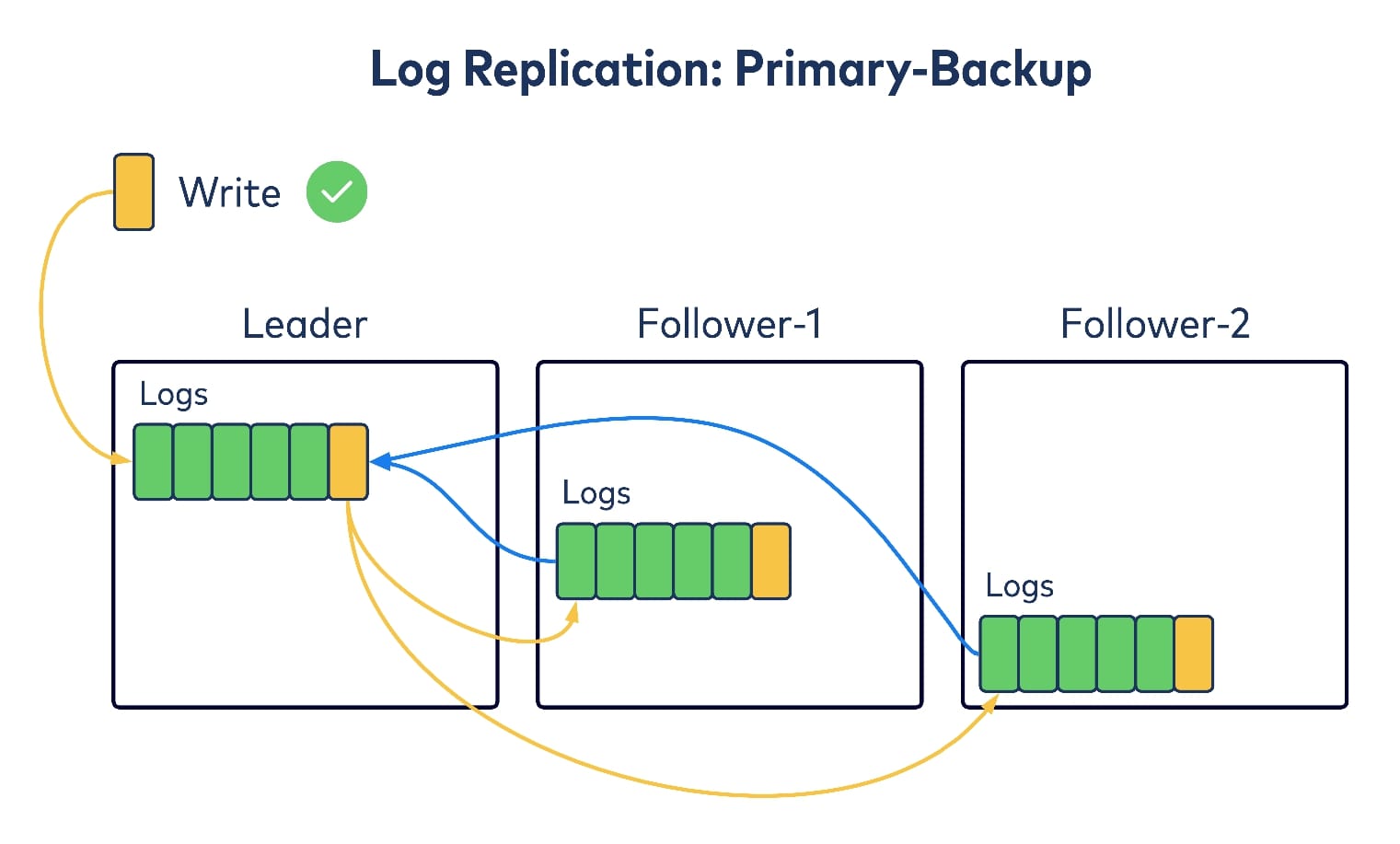
There is another commonly used replication algorithm in the literature: quorum replication. In this case, there is still a single leader trying to take writes, and then replicating to followers. But instead of waiting for all of the followers to ack on replication, it only waits for the majority of replicas, including itself. This is referred to as a quorum and after receiving one, the leader will consider the write as committed and will return to writing to the client. There are many well-known consensus algorithms in the distributed systems literature, such as Paxos and Raft, that follow this mechanism.
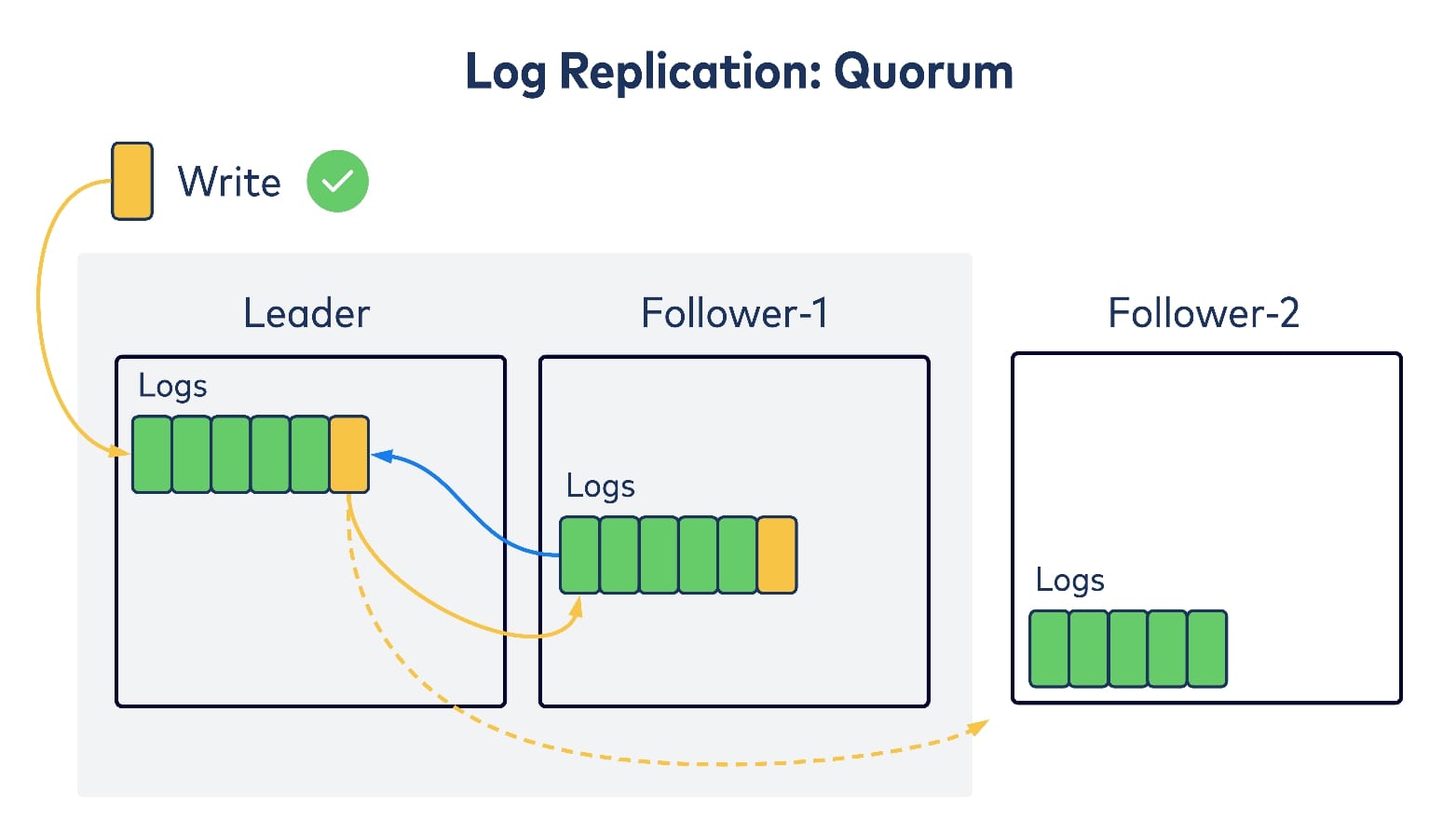
Compared with Kafka’s primary-backup replication algorithm, quorum replication trades on availability guarantees for better replication latencies. More concretely, Kafka’s failure mode is f + 1, which means that to tolerate f consecutive failures, you need to have at least f + 1 replicas, whereas quorum replication’s failure mode is 2f + 1.
KRaft – Kafka Raft implementation
For the new controller metadata log, quorum replication will be used instead of the primary-backup algorithm. The motivations are:
- In practice we could afford to have more in-sync replicas for this core metadata log compared with other data logs, to achieve higher availability.
- We are more sensitive to metadata log append latency since it would be a hotspot for the whole cluster.
As a result, we’ve implemented a new replication module, KRaft, which follows the Raft algorithm to achieve quorum replication, while at the same time piggybacks on Kafka’s existing log utilities such as throttling and compression. This way we can use similar tooling and troubleshooting protocols for the new log.
Since we no longer have ZooKeeper to elect a new leader for the metadata log with the new controller, a separate leader election protocol is needed. Such an election protocol needs to prevent multiple brokers being recognized as the leader at the same time, and also needs to prevent any gridlock scenarios, where no brokers are recognized as the leader for an extended period of time, due to certain conditions.
Leader election
In KRaft, we leverage on the existing Kafka leader epochs to guarantee that only one leader is elected within a single epoch. More specifically, a broker in the current cluster has one of the following roles: leader, voter, or observer. The leader and the other voters together form the quorum and are responsible for keeping the replicated log in consensus, and for electing new leaders when needed. All other brokers in the cluster behave as observers, which only passively read the replicated log to catch up with the quorum. Each record appended into the log is associated with the leader epoch.
Upon startup all of the brokers within the preconfigured quorum initialize as voters, and they set their current epoch from the local logs. In the diagram below, let’s assume we have a quorum of three voters. Each has six records in their local logs from epoch one and two, with colors green and yellow respectively.
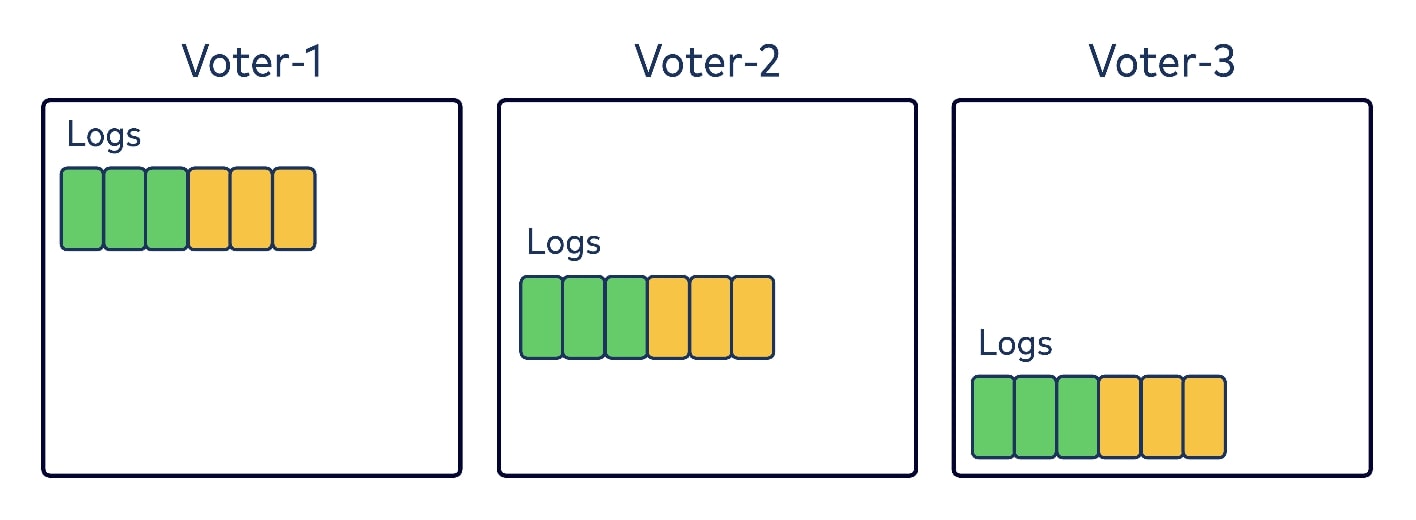
After a certain period of time has elapsed without finding a leader, a voter could bump up to a new epoch and transition to a temporary role as a leader candidate. It would then send a request to all other brokers in the quorum asking them to vote for it as a new leader in this epoch.
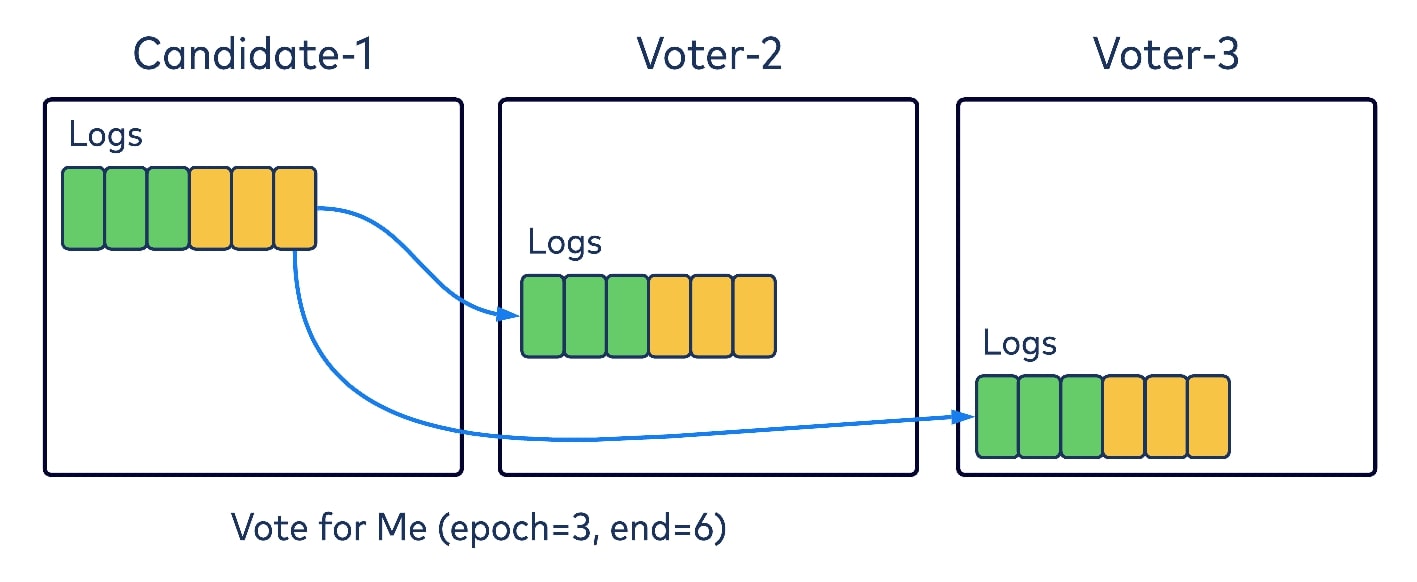
The vote request will contain two key pieces of information: the epoch for others to vote for, and the offset of the candidate’s local log. Upon receiving the request, each voter will check if the provided epoch in the request is no larger than its own epoch; if it has voted for the provided epoch already; or if its own local log is actually longer than the provided offset. If none of these are true, it will grant its vote to the candidate for the given epoch. Votes are persisted locally, so quorum brokers will not forget about the granted vote, even after it starts. When the candidate has received enough votes from the majority of the quorum, including itself, it can consider that the voting procedure has completed successfully.
Note that if a candidate cannot get enough votes within a preconfigured voting timeout, it will consider the voting procedure as failed and will try to bump up its epoch again and retry. To avoid any gridlock scenarios such as multiple candidates asking for votes at the same time, and thus preventing one other from getting enough votes for a bumped epoch, we also introduced a randomized backup time before retries.
Combining all of these condition checks and the timeout mechanism on voting, we can guarantee that at most one leader will be elected for a given epoch on KRaft, and also that this elected leader will have all of the committed records up to their elected epoch.
Log replication
Like Kafka, KRaft aligns with a pull-based replication mechanism rather than the push-based model introduced by the original Raft paper. In the diagram below, let’s say that Leader-1 one has two records (in red) in Epoch 3 and Voter-2 is fetching from it.
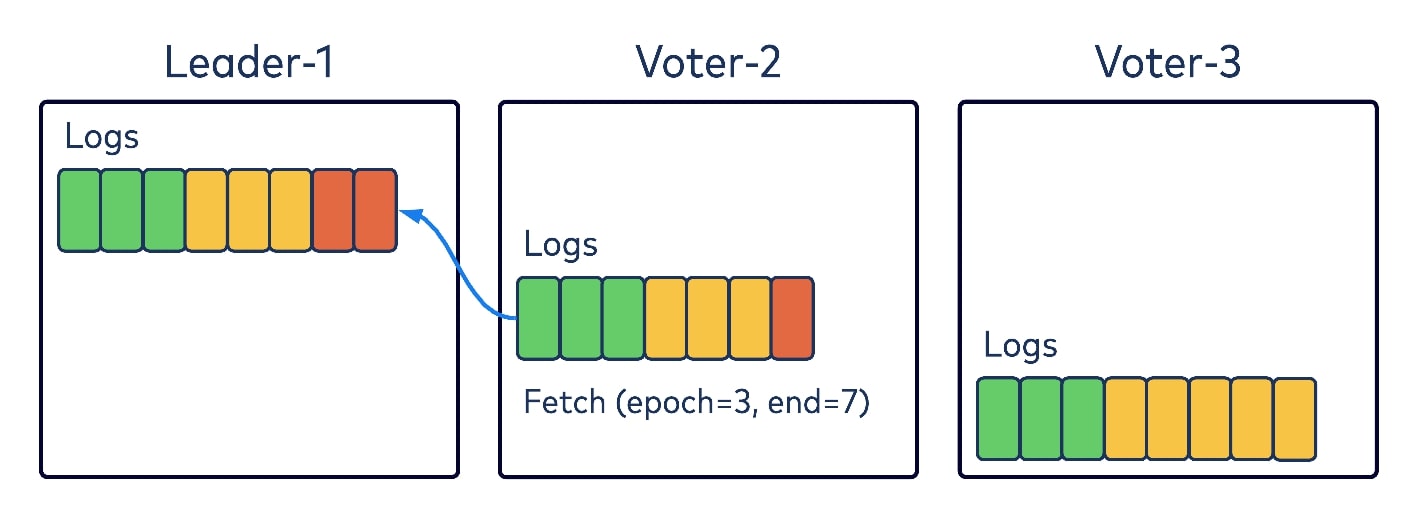
Like the existing replica-fetching logic in Kafka, Voter-2 would encode in its fetch request two pieces of information: the epoch to fetch from, and its log and offset. Upon receiving the request, Leader-1 would check the epoch first, and if it’s valid, would return the data starting with that given offset. The fetching Voter-2 would append the returned data to its local log and then start fetching again with the new offset. Nothing new here, just normal replica-fetching protocols.
But let’s say another voter has diverged from the log entries. In our diagram, Voter-3, which was the old leader on Epoch 2, has some appended records on its local log that have not been replicated to the majority of the quorum, and hence are noncommitted. When realizing that the new epoch has started with Leader-1 as the leader, it will send a fetch request to Leader-1 with Epoch 2 and the log and offset. Leader-1 will validate and find that this epoch and offset are not a match, and hence will return an error code in the response, telling Voter-3 that Epoch 2 has only committed records up to offset 6. Voter-3 would then truncate its local log to offset 6.
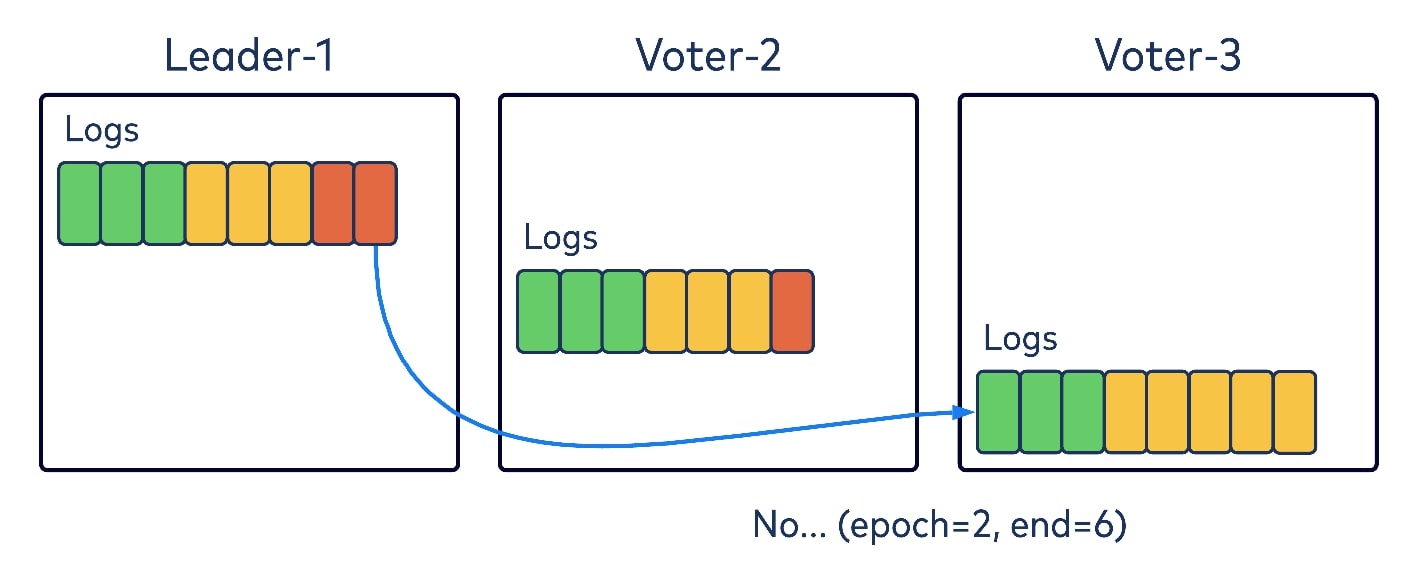
Then Voter-3 would resend the fetch again, this time with Epoch 2 and offset 6. Leader-1 could then return the data from the new epoch to Voter-3, which would learn about this new epoch from the returned data while appending to its local log.
Note that if Voter-2 and Voter-3 cannot successfully fetch responses from Leader-1 within a predefined time, it can bump up its epoch and try to elect as a new leader for Epoch 4. Therefore we can see that this fetch request is also leveraged as a heartbeat to determine the liveness of the leader.
Pull vs. push-based replication
Compared with the push-based model in the Raft literature, pull-based log replication in KRaft is more effective in log reconciliation, since the fetching voters are able to truncate directly to the feasible offset before resending the next fetch. In a push-based model, more “ping-pong” round trips are needed, since the leader, who is pushing the data, needs to determine the correct log position to send data to.
Pull-based KRaft is also less vulnerable to destructive servers, i.e., old voters unaware that they have already been removed from the quorum due to, for example, member reconfiguration. If these old voters continue to send fetch requests to the leader in the pull-based model, the leader can respond with a special error code telling them that they have been removed from the quorum, and that they can transition to observers. Conversely, in the original push-based Raft algorithm, the leader pushing data may not know which removed voters will become disruptive servers. Since the removed servers aren’t getting push data any more from the leader, they will try to get elected as the new leader, hence disrupting the process.
Another big motivation for choosing a pull-based Raft protocol is that Kafka’s backbone log replication layer is already in the pull-based model, and hence allowed the reuse of more of the existing implementation.
The benefits come with a cost, though: The new leader needs to call a separate “begin epoch” API to notify the quorum. Whereas in the Raft model, this notification can be piggybacked with the leader push data API. In addition, to commit records from the majority of the quorum, the leader needs to wait for the next fetch request from the voters to advance its offsets. These are worthy tradeoffs to tackle the disruptive servers issue. Additionally, leveraging on the existing Kafka pull-based model for data replication (aka “not reinventing the wheel”) has saved thousands of lines of code.
To learn more about other details of the KRaft implementation design such as metadata snapshots and the state machine API built on top of the KRaft log, make sure to read the reference documents for KIP-500, KIP-595, and KIP-630.
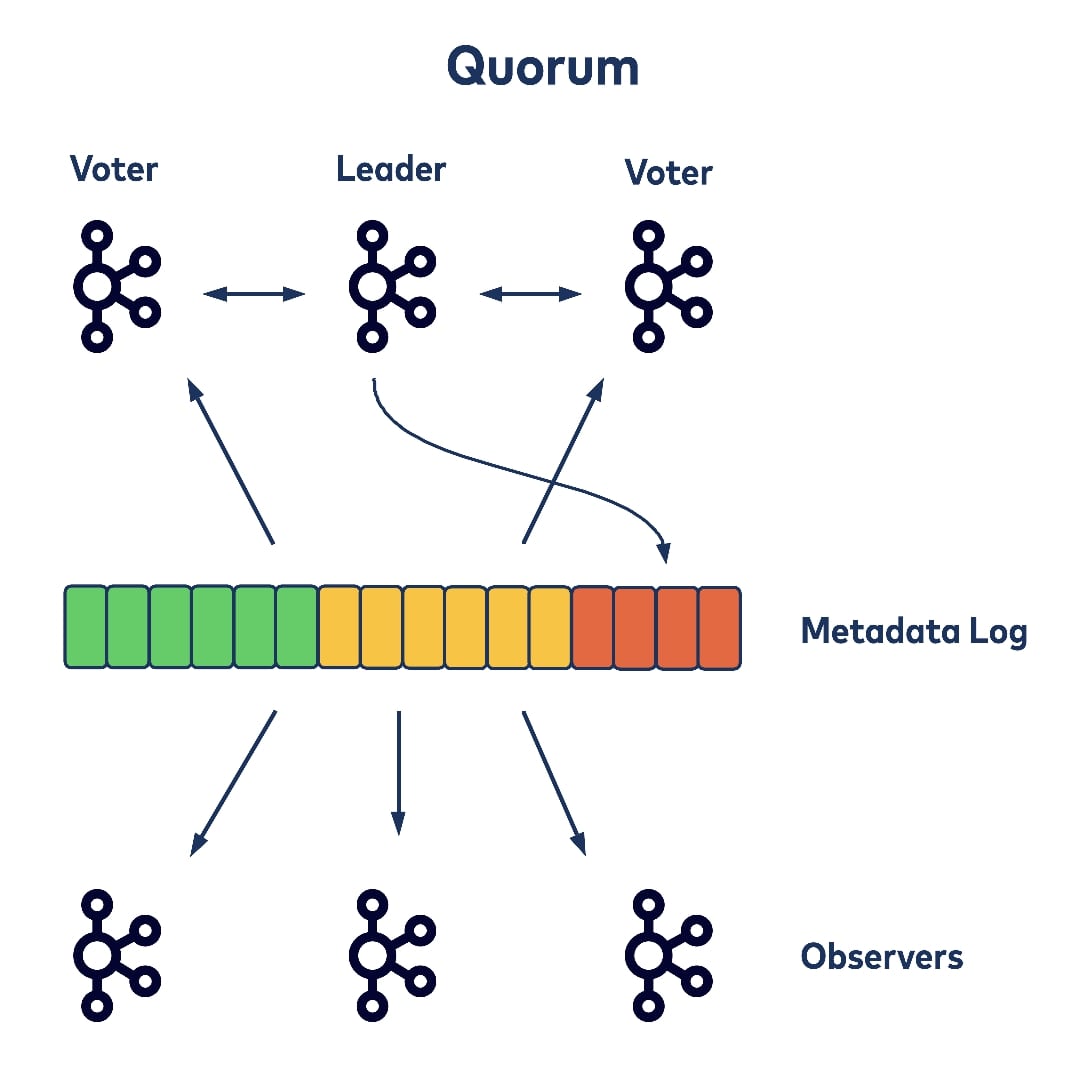
Now we can talk about the new controller (we call it the Quorum Controller) design without Zookeeper dependency. The Quorum Controller is built on top of the KRaft protocol above. When starting up Kafka brokers within a cluster using the new model, a small subset of the total number of brokers get configured as a quorum. The brokers in the quorum follow the KRaft algorithm to elect a leader among themselves, which acts as the quorum’s controller.
The controller is responsible for taking new broker registrations, detecting broker failures, and taking all requests that would change cluster metadata. All of these operations can be pipelined and ordered by the time when their corresponding change events were appended to the metadata log. Other voters within the quorum actively replicate the metadata log so that newly appended records get committed.
Thus a state machine built on top of the cluster that represents the cluster’s current metadata snapshot can also be updated. Other brokers that are not configured as part of the quorum are the observers of the metadata log, only fetching the committed records from the quorum to update their own metadata caches. This way all local metadata snapshots are naturally versioned by the fetched log offset, and it’s easy to reason about metadata staleness and fix any potential divergences.
The Kafka cluster here can be as small as a single broker, which could also act as the controller. And when more brokers are added to that cluster, they will discover the controller and will register themselves with it. Then the controller can write their entries to the metadata log accordingly. The controller can also fence the newly added brokers from being accessed until they have completed moving assigned topic partitions and are ready to serve client requests. This incurs less risk of timeouts, for example, if the newly joined brokers are lagging behind.
(New) quorum controller: broker shutdowns and controller failover
Now let’s revisit the two scenarios discussed earlier—broker shutdowns and controller failover— and consider them in relation to the new quorum controller.
The quorum controller receives the liveness of all registered brokers with heartbeats. When an existing broker is shutting down, it can piggyback its intention within a heartbeat request and the controller can remove it from all of its partitions as usual, but also batch all of the partition movement events when appending them to the metadata log. (This largely reduces shutdown latencies as well.)
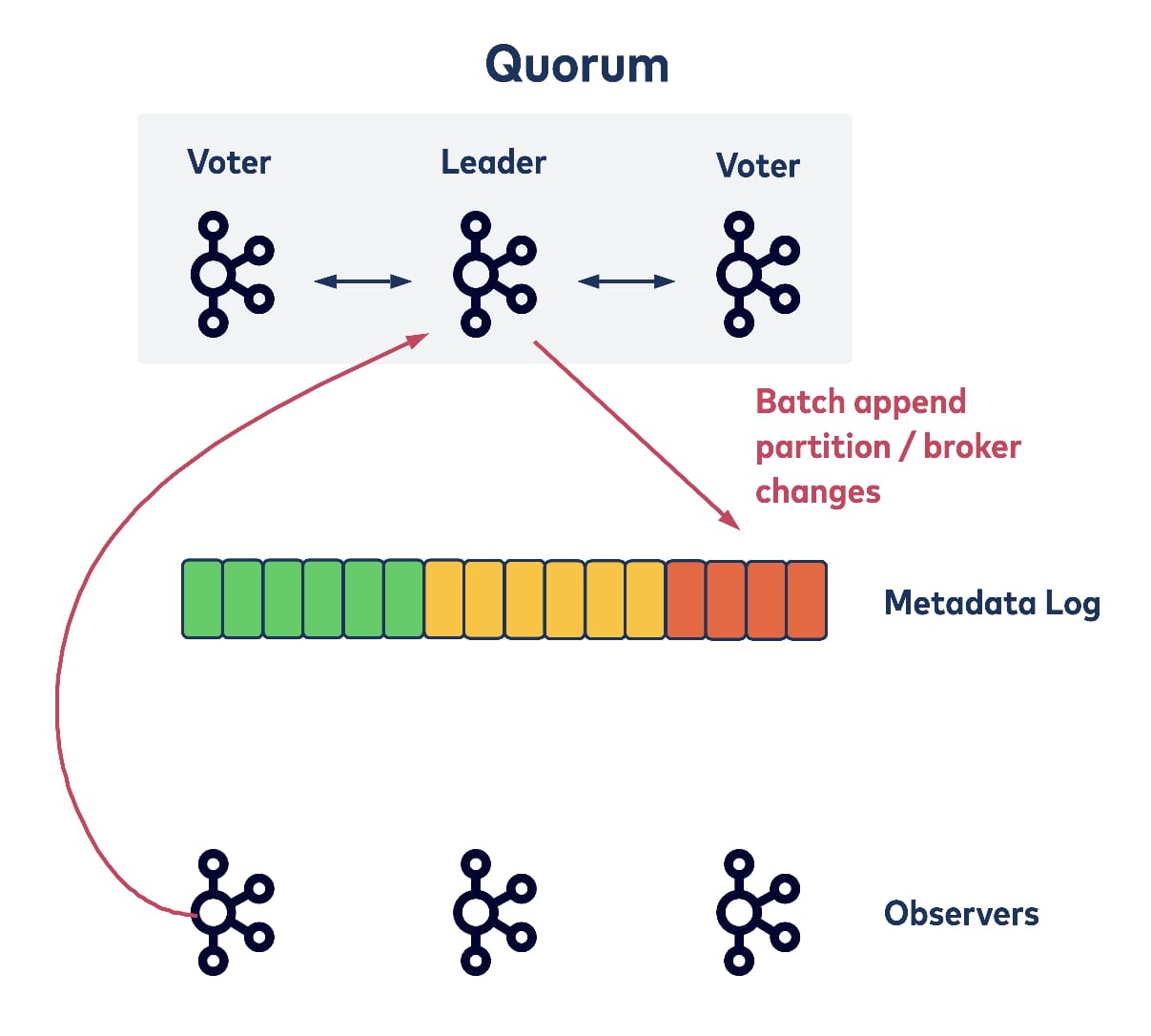
Similarly, for controller failover, one of the voters could take over as new leader and directly start committing data with a bumped epoch. This is because the elected new leader would already have replicated all of the committed records up to the new epoch and thus wouldn’t need any time to bootstrap from the metadata log.
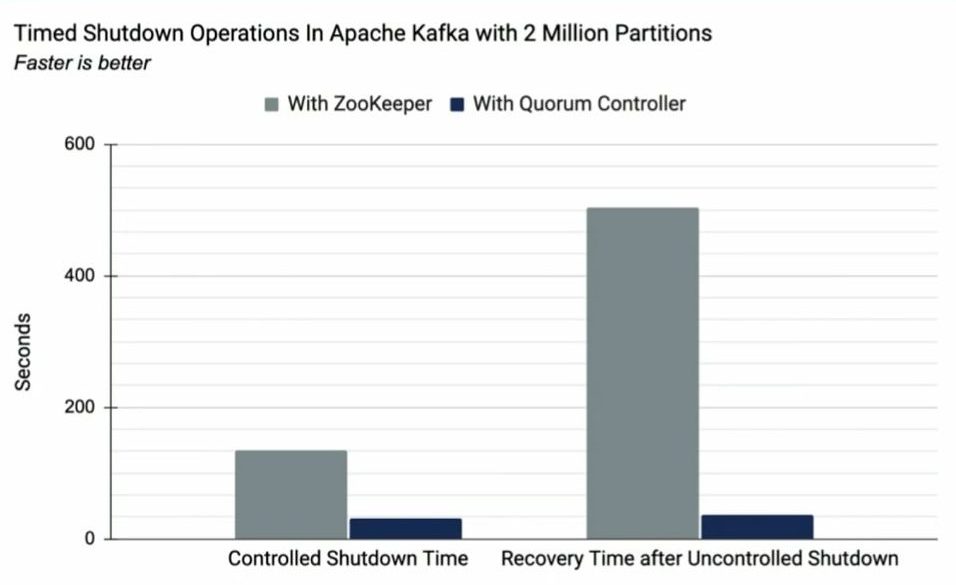
An Experiment: ZooKeeper vs. Quorum Controller
To illustrate the benefits of the Quorum Controller, we did experiments comparing the old ZooKeeper-based controller with the new Quorum Controller. The experiment was done with two million topic partitions hosted on a single Kafka cluster. As you can see in the diagram below, for both controlled shutdown and uncontrolled failover, the latency was largely reduced with the Quorum Controller.
For more details, see our blog post Apache Kafka Made Simple: A First Glimpse of a Kafka Without ZooKeeper.
In conclusion, there are two key points you might take away from this post:
- It’s more efficient to maintain metadata as a log of events, just as we do with all other data in Kafka.
- When building the new Quorum Controller on top of this metadata log, we can largely lift our scalability bottlenecks and go beyond thousands of brokers and millions of partitions within a single Kafka cluster.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent





