Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
The Future of ETL Isn’t What It Used To Be
In his book Design Patterns Explained, Alan Shalloway compares his car to an umbrella. After all, he uses both to stay dry in the rain. The umbrella has an advantage of being light and foldable, but the car has wheels and can protect more than one person. The car has a disadvantage of requiring fuel. You can see how a detailed list of features and limitations, while accurate, is missing some essential context about the use-cases that drove the design. A car is not a heavy umbrella with wheels.
People often think of Apache Kafka® as an ETL or data integration solution. If you think of Kafka this way, it makes sense to compare it to other ETL solutions—both traditional tools like Informatica or newer ETL tools. In a recent blog post, Slim Baltagi compares Kafka Connect to Streamsets. On the whole, his evaluation of Connect is accurate enough, and we are planning on addressing some of the limitations he mentioned. But we feel this type of feature-by-feature comparison misses the larger point.
Apache Kafka is more disruptive than merely being faster ETL. The future of how data moves in the enterprise isn’t just a real-time Informatica. Data streams are, in many ways the very core of a modern digital business, and they deserve an infrastructure platform that makes them a first class citizen. ETL tools see data pipelines as a by-product of moving data from one database to another, and as a result they can’t integrate all of the event streams that exist between business applications. In order to build ETL for a modern business, we need to turn ETL inside-out—to put the streams of events at the center.
Most businesses run using both off-the-shelf software and an increasingly large set of apps developed in-house. Traditionally, all software interacted with the database directly and therefore moving data between databases was a key activity. These days, event-driven and stream-processing software will interact directly with the streams of events, so a complete streaming platform must connect both applications and databases. It must provide a complete solution that makes streams a first-class construct for publishing, subscribing, and processing streams of events across an entire company. ETL solves part of the problem, but it isn’t a platform and doesn’t have the APIs and libraries necessary for building stream processing and event-driven applications. Many companies solve this by having one framework for integrating applications (a data bus or other EAI solution) and another for ETL. But having two systems rather than one is inefficient and challenging to operationalize. Kafka is one streaming data platform that can combine event streams from both applications and databases.
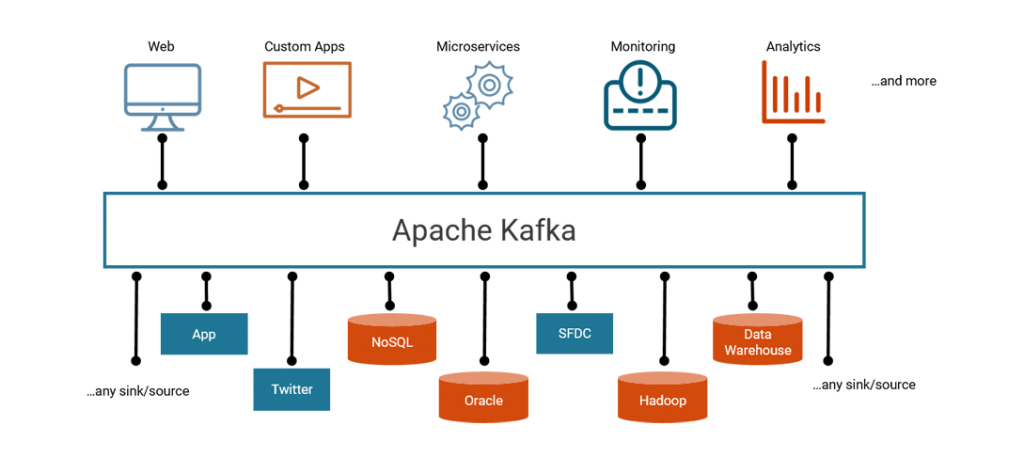
Using a streaming platform for ETL means you get more than just real-time ETL. The main advantages are:
1. Integrate databases, stream processing and business applications
As mentioned above, ETL tools force you to separate the streams of events that move between databases from the events that move between applications. Increasingly, we see event driven applications that need to combine both streams of events and data from databases. As long as these are treated as two different types of data, stuck in different architectural silos, combining both in an application will be more difficult than it needs to be. Furthermore, the line between applications and ETL is blurring. A recommendation system will involve collecting data from both applications and databases, generating recommendations and storing them in a key/value store where it feeds into the customer’s browsing experience. It looks a bit like ETL, but it has the SLA and business implications of transactional applications. Without APIs for producing and consuming streams directly and an open protocol that allows integration from all programming languages, ETL tools remain a partial solution at best.
2. ETL with Microservices, not a Monolith
A streaming platform lets independent teams of developers build their own ETL into their applications. Many data-driven applications have to gather events from different data stores, which blurs the lines between applications and ETL. Submitting a request to the central ETL team and waiting few days or weeks for them to add an ETL job and get the data strains at the definition of what one might call agile. We want the application team to be able to work independently to get their events, with no impact on other teams. With a streaming data platform, developers can read and write streams of events directly. With Connect APIs, developers can bake ETL right into their own applications. This way, instead of a monolithic ETL system, you have microservices ETL. And developers can work faster with fewer dependencies.
3. Future-proof ETL
Stream processing is changing the nature of ETL. ETL developers and data engineers have the opportunity to use the streaming data platform for their workloads—especially workloads that require real-time transformations and diverse data stores. To build ETL in the modern world, you need to think like a developer, not a tool specialist. You need to worry about scale and efficiency, and also about latency, tests, source control, schema evolution, and continuous integration and deployment. A real-time streaming data platform handles many of the concerns you’d need to resolve manually with ETL tools or home-grown scripts and adds scalability, built-in connectors and transformations, and great APIs for real-time processing.
4. Scale and reliability of modern distributed system
The platform solves difficult problems software engineers and SREs deal with: horizontal scalability, fault-tolerance, observability, decoupling microservices, real-time processing questions, and management of streams of events, schemas, and metadata. Newer ETL tools claim to solve parts of the problem: real time processing and metadata management. But Kafka is proven at company-wide scale supporting hundreds of applications and thousands of engineers working independently with streams of trillions of messages. None of the newer ETL tools can claim the same.
Once you elevate event streams to first-class status in your architecture, the possibilities begin to open up in earnest. Even components seemingly distant from the concerns of data integration, like GUIs, become easy additions to the system. Independent teams can now build their own graphical tools fit to the unique needs of different people using the platform. A GUI becomes just another application running on the platform providing value to its users—not a control panel required to operate the framework, like we would see in a traditional ETL tool.
Graphical tools interoperate effortlessly with the platform, but ultimately, they serve different purposes than the platform itself. GUIs are optimized to be easy to learn and to make as many decisions for the user as possible. Stream processing platforms are rightly designed as general computation and high-performance messaging infrastructure. The two could not be more different; indeed, comparing the stream platform to a graphical tool is like comparing Excel to Oracle. Certainly Oracle and Excel can both be used to manage structured data, but no one would describe Excel as a flexible, general-purpose backbone of a data infrastructure on which an enterprise might be built. Put simply, nobody runs SAP on Excel.
Of course, we will always continue to improve Apache Kafka and the Confluent Platform, including our graphical monitoring and management application, our connectors, metadata management and the various clients. We hope to provide the best possible platform for building applications on streams of events—this includes ETL, stream processing, event-driven apps and everything in between. The focus on building a streams-first platform for data-driven business will continue to drive our decisions. This is why when you look at Confluent Platform as an ETL tool, it is a bit like looking at a car and wondering whether it would be a good umbrella.
As you can see, ETL as we have known it is under the same evolutionary pressures as any other part of the technology ecosystem, and is changing rapidly.
If you’re interested in a deeper discussion of the topic, watch the online talk, ETL is Dead; Long Live Streams, featuring Confluent co-founder and Apache Kafka co-creator Neha Narkhede. View the recording.
Our online talk series Streaming ETL – The New Data Integration is also available on demand.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Streaming Data Integration with Apache Kafka®
Streaming data integration supports enriched, reusable, canonical streams that can be transformed, shared ,or replicated to different destinations, not just one.



Data Streaming Platforms: The Cornerstone of Enterprise AI
Discover how a data streaming platform helps you unlock the full potential of your AI—and translates it into measurable business value.