Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Announcing the Elasticsearch Service Sink Connector for Apache Kafka in Confluent Cloud
We are excited to announce the preview release of the fully managed Elasticsearch Service Sink Connector in Confluent Cloud, our fully managed event streaming service based on Apache Kafka®. Our managed Elasticsearch Service Sink Connector eliminates the need to manage your own Kafka Connect cluster, reducing your operational burden when connecting across Kafka in all major cloud providers, including Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
Before we dive into the Elasticsearch Service sink, let’s recap what Elasticsearch Service is and does.
What is Elasticsearch Service?
Elastic Cloud is a set of SaaS offerings that make it easy to deploy, operate, and scale Elastic products and solutions in the cloud. Elasticsearch Service is the official Elasticsearch Service from the creators. You can spin up a fully loaded deployment on any cloud provider—AWS, GCP, and Azure—you choose.
Getting started with Confluent Cloud and Elasticsearch Service
To get started, you will need access to Confluent Cloud as well as Elasticsearch Service. You can use the promo code CL60BLOG to get an additional $60 of free Confluent Cloud usage.* If you don’t have Elasticsearch Service yet, you can sign up for a 14-day free trial.
When using the Elasticsearch Service Sink Connector, your Elasticsearch Service must be located in the same region as the cloud provider for your Kafka cluster in Confluent Cloud. This prevents you from incurring data movement charges between cloud regions. In this blog post, the Elasticsearch Service is running on GCP us-central1 and the Kafka cluster is running in the same region.
Once your Elasticsearch Service is running, store the Elasticsearch Service URL, username, and password to configure Elasticsearch Service Sink Connector.
Using the Elasticsearch Service sink
Building off of this food delivery scenario, when a new user is created on the website, multiple business systems want their contact information. Contact information is placed in the Kafka topic users for shared use, and we then configure Elasticsearch Service as a sink to the Kafka topic. This allows a new user’s information to propagate to a users index in Elasticsearch Service.
To do this, first create the topic users for a Kafka cluster running in Confluent Cloud (GCP us-central1).
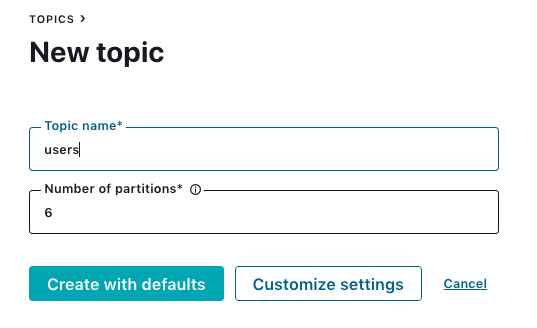
Use this Python script to populate sample records to the users topic, and check whether the records are available in the users topic.
Click the Elasticsearch Service Sink Connector icon under the “Connectors” menu, and fill out configuration properties with Elasticsearch Service. Make sure JSON is selected as the input message format. The connector will use the users topic as an index name. You can also use a CLI command to configure this connector in Confluent Cloud.

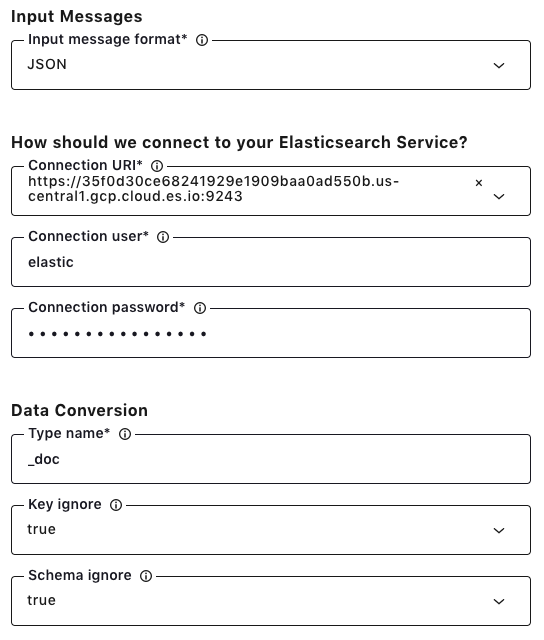
Once the connector is up and running, records for the users index will show up in Elasticsearch Service.

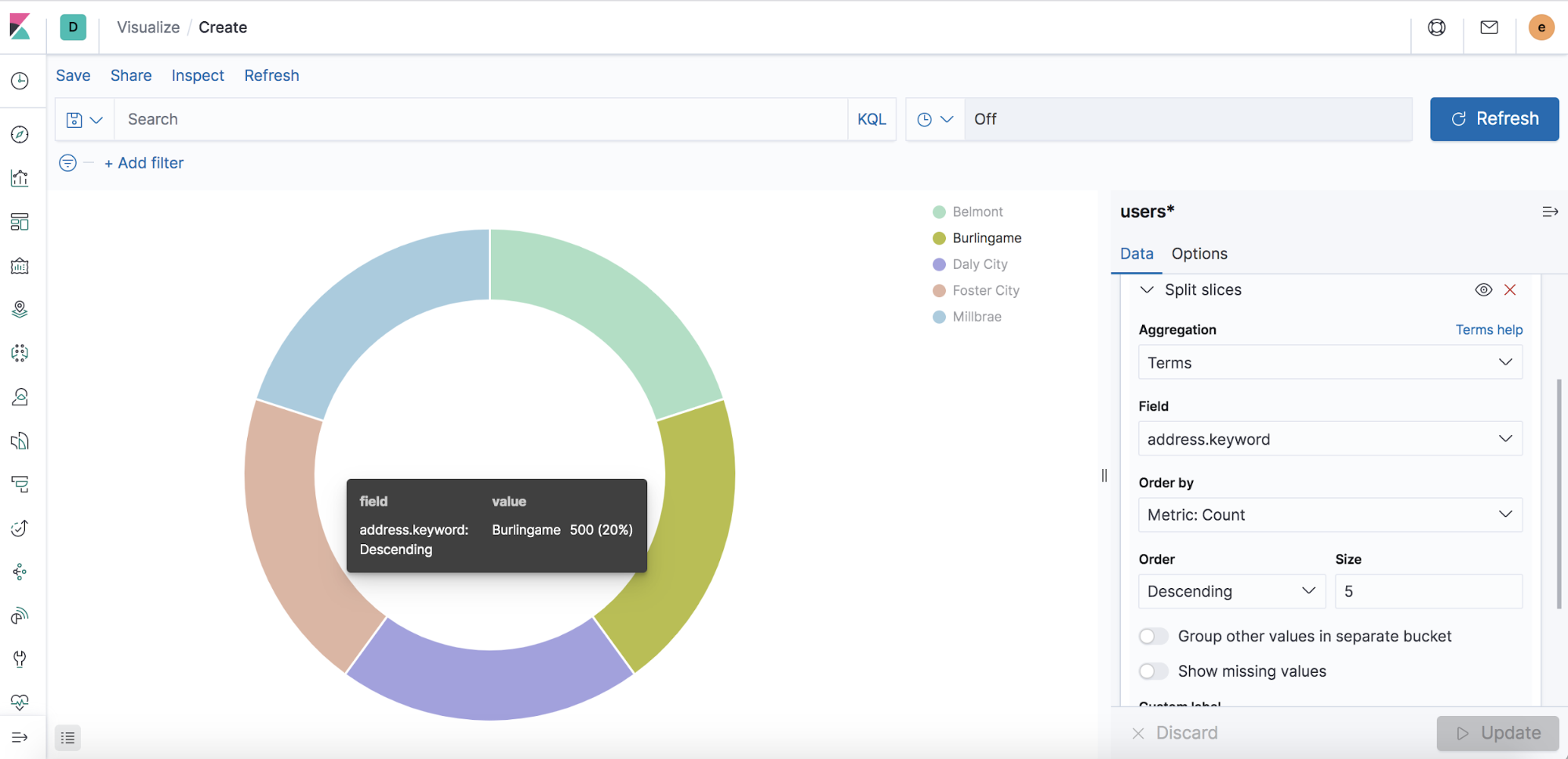
You can use a Kibana dashboard in Elastic Cloud to visualize the distribution of users’ locations.
Learn more
If you haven’t tried it yet, check out Confluent Cloud, a fully managed Apache Kafka and enterprise event streaming platform, available on Microsoft Azure and GCP Marketplaces with the Elasticsearch Service sink and other fully managed connectors. Enjoy retrieving data from your data sources to Confluent Cloud and sending Kafka records to your destinations without any operational burdens.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.