Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Consistent Metastore Recovery for ksqlDB Using Apache Kafka Transactions
This is the second of a series of posts (part 1 | part 3) that dive deep into key improvements made to ksqlDB to prepare for production availability in Confluent Cloud.
This post assumes familiarity with ksqlDB and ksqlDB’s interactive deployment mode. Familiarity with transactions in Apache Kafka® is also helpful. If you need some background, check out the following:
This post talks about some of the work that’s gone into preserving the integrity of ksqlDB’s internal state in interactive mode. This is important for ksqlDB in the cloud since all servers are deployed in interactive mode.
In interactive mode, ksqlDB servers that belong to the same cluster share the same ksql.service.id and command topic. The command topic is a Kafka topic containing all the statements that modify the ksqlDB metastore, the set of streams, tables, and queries present on a server. All data definition language (DDL) statements such as Create Stream, Create Table, and query-creating statements are enqueued onto the command topic before the server executes it. Users constantly add/delete new streams/tables and start/stop queries, and each of these actions requires writing statements to the command topic. When users submit these statements, they only submit to one server, so the command topic is used to ensure that all servers execute the same DDL statements and remain in sync.
Each ksqlDB server runs a Kafka consumer that polls the command topic for new records. When a new statement is written to the command topic, each server eventually consumes the record with the statement, and then the statement is validated and executed on each server. By executing the same set of DDL statements, every server in the cluster is able to maintain a consistent set of streams, tables, and queries.
The name for this Kafka topic is derived from the ksql.service.id. A newly deployed ksqlDB server or a restarted server checks to see if a command topic associated with its ksql.service.id exists during startup. If it exists, the server processes the statements in the command topic in order to recreate the metastore. This mechanism allows servers to be provisioned and restarted while keeping all DDL statements intact during the downtime.
It’s critical that every node in the cluster has the exact same view of the current streams, tables, and queries. This means that every node has to execute, in the same order, the exact same commands on every run of the command topic. To ensure this always holds true, a protocol has been implemented between the server endpoints and command topic consumers based on Kafka transactions.
Exploring the past design
Let’s explore the flaws in the old protocol by issuing the following DDL statement:
CREATE STREAM CLICKSTREAM (USERID BIGINT, PAGEID STRING) WITH (TOPIC='CLICKSTREAM’, VALUE_FORMAT='JSON');
- The user sends the DDL statement in a request to the ksqlDB REST API.
- We don’t want to update the metastore before the request makes it to the command topic, so a snapshot of the server’s metastore is created when the request arrives. The server’s engine uses the snapshot to validate the statement by executing the statement against the snapshot. Examples of validations include checking for an existing stream/table of the same name and ensuring the underlying Kafka topic exists. If an exception is thrown, the error is returned as a response to the user.
- If validation succeeds, the statement is produced to the command topic.
- The server consumer polls the command topic and consumes new statements. Statements are then validated and executed in the engine against the metastore. Validation needs to be done again since there can be multiple statements concurrently produced to the command topic.
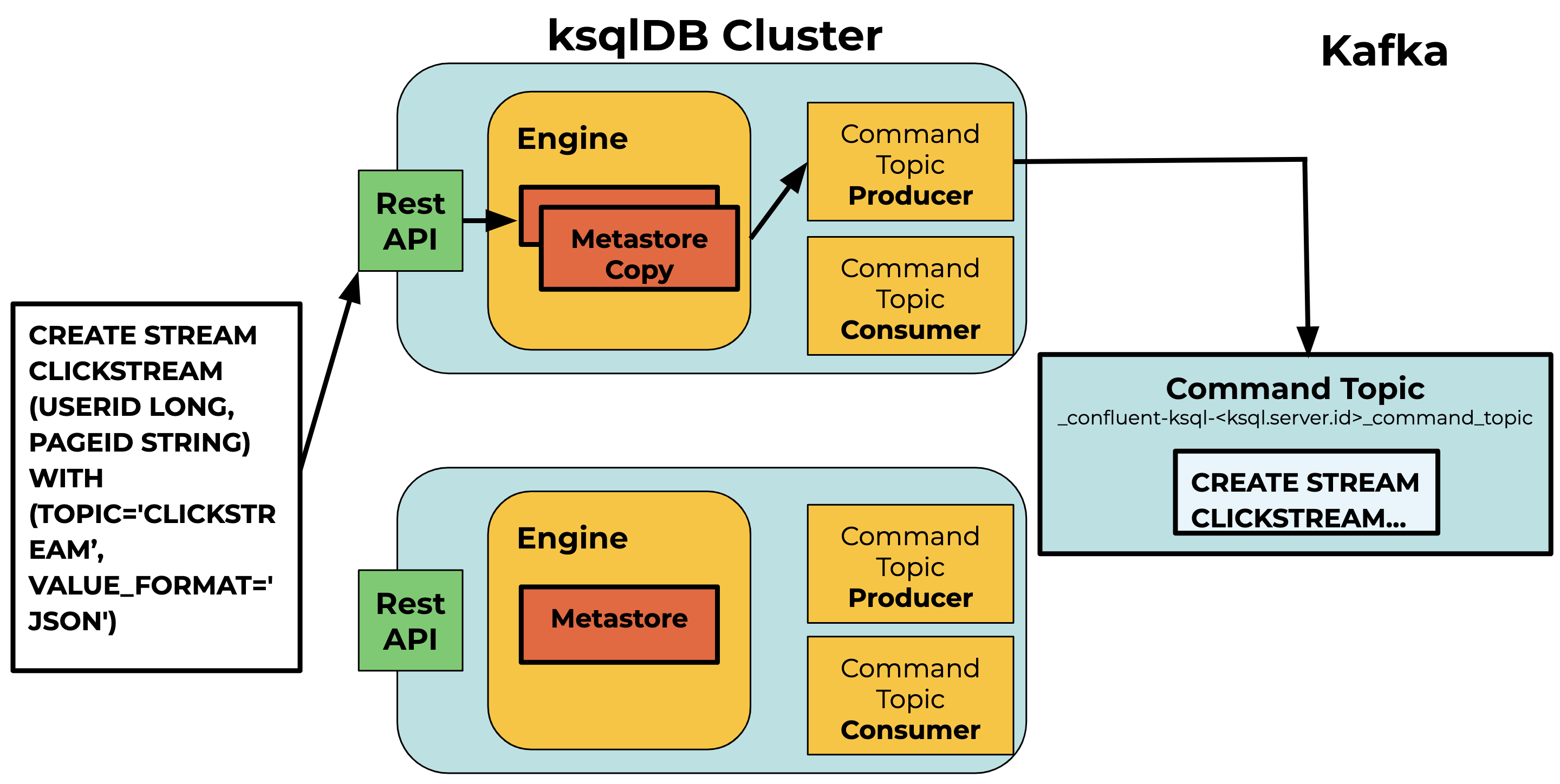 Figure 1. Producing to the command topic
Figure 1. Producing to the command topic
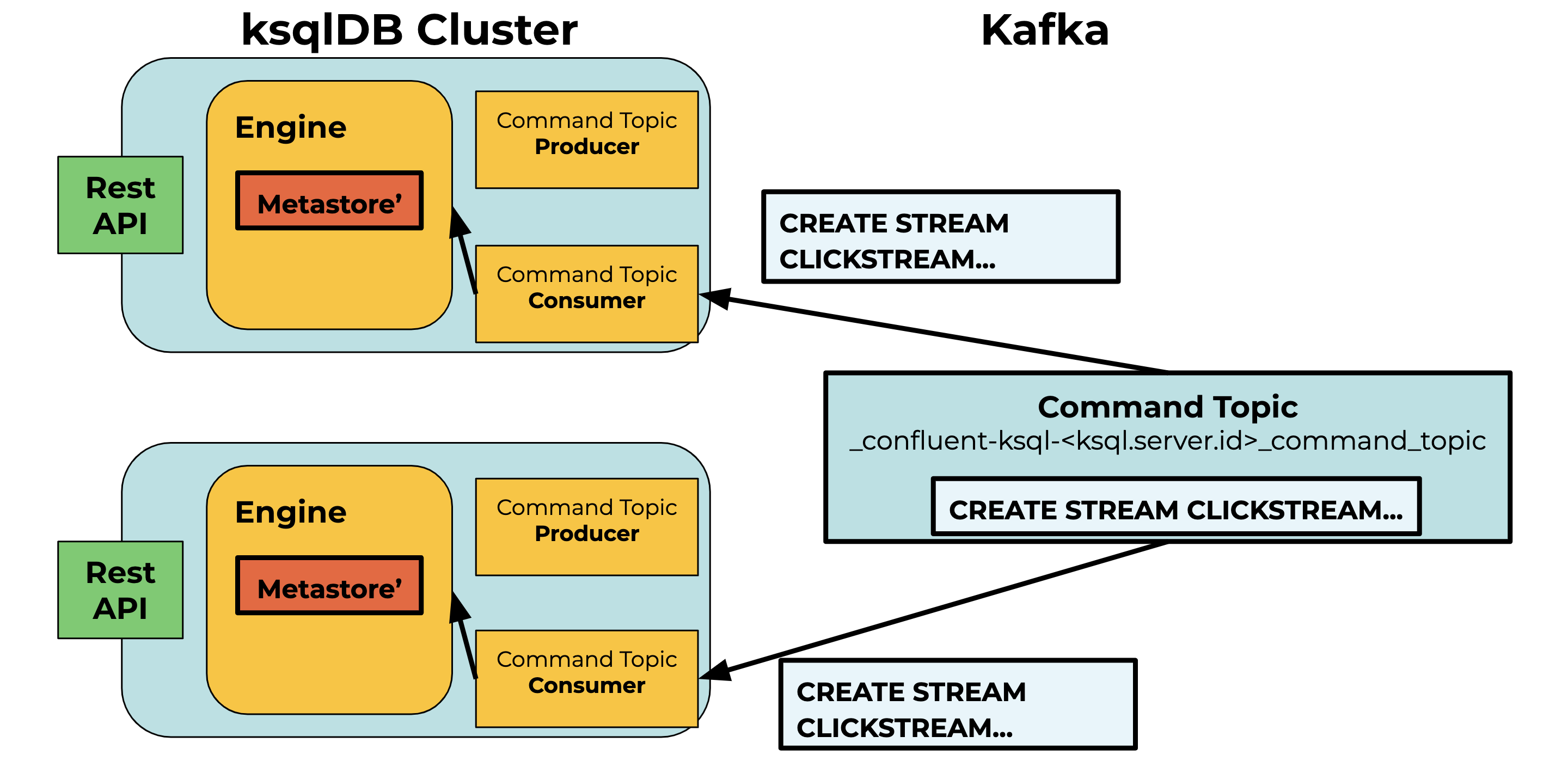 Figure 2. Consuming from the command topic
Figure 2. Consuming from the command topic
The interactive deployment mode design treats the command topic as both a request queue and a log.
- Request queue: The command topic contains statements from different servers that will eventually be executed. The execution may or may not succeed depending on the state of the server and external systems (e.g., Kafka) at the time of execution.
- Log: The command topic has all the statements that must be executed for the ksqlDB servers to recover.
When a statement from the command topic fails validation/execution, the error is categorized as either a statement validation error or non statement validation error. In the previous design, non statement validation errors were considered transient (e.g., something timed out) and the statement was retried, while statement validation errors were skipped. There are two kinds of statement validation errors that can occur:
- External errors: The statement conflicts with the external state, such as changes in Kafka.For example, the command topic could contain:
CREATE STREAM PAGEVIEWS_STREAM (USERID LONG, PAGEID STRING) WITH (TOPIC='PAGEVIEWS’, VALUE_FORMAT='JSON'); CREATE STREAM PAGEVIEWS_COPY AS SELECT * FROM PAGEVIEW
During an execution of the command topic, the streams PAGEVIEWS_STREAM and PAGEVIEWS_COPY are both successfully created. In the future, the server is restarted, but this time the Kafka topic PAGEVIEWS has been deleted before the restart. As a result, PAGEVIEWS_STREAM fails to be created. In addition, PAGEVIEWS_COPY isn’t created since it depends on PAGEVIEWS_STREAM existing.
- Internal errors: The statement conflicts with ksqlDB’s internal state. Statements could be validated with a metastore that’s out of sync with the command topic. Some reasons for this include consumer lag in processing the command topic or the consumer encountering errors while polling the command topic. Multiple servers writing to the command topic at the same time leads to race conditions since servers can independently validate and produce statements to the command topic.For example, server A could receive:
CREATE STREAM CLICKSTREAM (USERID LONG, PAGEID STRING) WITH (TOPIC='CLICKSTREAM’, VALUE_FORMAT='JSON');"
While at the same time, server B receives:
CREATE STREAM CLICKSTREAM (ACCOUNTID STRING) WITH (TOPIC='CLICKSTREAM’, VALUE_FORMAT=AVRO);"
Since the stream CLICKSTREAM doesn’t exist yet on server A or server B, they both validate and produce the statement they received to the command topic. Assuming that server A’s statement was produced first, server B’s statement would fail validation when executing the command topic since stream CLICKSTREAM already exists.
For external errors, it doesn’t make sense to corrupt ksqlDB’s state by skipping a statement due to a change in an external system. However, internal errors can’t be reconciled and need to be skipped. Unfortunately, skipping all statements that encounter statement validation errors was necessary since it was difficult to programmatically categorize the statement validation error as internal or external.
New protocol
In the new protocol, we treat the command topic as a log rather than a request queue by never skipping any statements. This requires two main changes.
- Performing validation before enqueueing to the command topic: As mentioned, it is best to avoid validating statements during execution since they could fail due to external systems. Therefore, validation should only be done before a statement is produced to the command topic. Removing validation from execution was a relatively straightforward process.
- Isolation during validation: Having multiple servers simultaneously validate and produce statements to the command topic could lead to conflicting statements in the command topic, which prevents executing every statement. To address this, we isolated the servers so that only one server could validate and produce to the command topic at a given time. This was a bit tricky since we needed a mechanism that could coordinate between all the servers in the cluster.
With these two changes, we are able to treat the command topic like a log by never skipping a statement during execution and therefore are always able to rebuild the same state.
Utilizing Kafka transactions
We realized that we could coordinate between ksqlDB servers by integrating Kafka’s transaction mechanism into the protocol that validates and produces statements to the command topic. One key feature of Kafka transactions is the use of the transactional.id for the Kafka producer. The main purpose for setting a transactional.id on a producer is to fence off leftover “zombie” producers from producing to the topic once a transaction has been initialized.
This functionality could also be leveraged to prevent multiple ksqlDB servers from writing to the command topic concurrently. We could augment the existing workflow by changing the existing producer to a transactional one by setting the ksql.service.id as the transactional.id. Since all the servers in the cluster have the same ID, every server in the cluster would have a producer with the same transactional.id, allowing the servers to fence each other off when starting a transaction. This is a big win for us since we don’t need to implement our own protocol for coordinating between the servers when validating and producing statements to the command topic.
The following is the new workflow for producing a statement to the command topic:
- The user sends the DDL statement in a request to the ksqlDB REST API.
- The server creates a new transactional Kafka producer.
- The producer ID is set to the ksql.service.id.
- Initialize the transactional producer with producer.initTransactions().
- The transaction coordinator closes any pending transactions with the ksql.service.id and transactional.id and bumps the epoch. Producers with the same ID are fenced off from producing to the command topic. This prevents race conditions from different servers writing to the command topic at the same time.
- A new producer is created for each statement since the initialization can only be done once per producer.
- Begin the transaction (producer.beginTransaction()).
- Get the end offset of the command topic.
- We can assume that no more records will come in during this transaction session, because if any new records get produced to the command topic, it means another server has initialized a transactional producer and this transaction will be aborted when attempting to commit it.
- Wait until the server’s consumer has consumed up to the offset.
- This ensures that the server metastore is up to date during validation.
- Create a snapshot of the metastore and use it to validate and execute the statement.
- Produce the statement to the command topic.
- Commit the transaction.
The command topic consumer’s isolation_level config can be set to read_committed, which only allows statements that were part of a successfully committed transaction to be returned by the consumer. Using Kafka transactions in this way guarantees that there’s only a single writer to the command topic at a given time, preventing conflicting statements from being written to the command topic.
By incorporating Kafka transactions into validation, there will be no conflicting statements present in the command topic and it will never skip a statement during execution. ksqlDB servers are now guaranteed to deterministically recreate the same metastore every time the command topic is processed. Users can be confident that their ksqlDB cluster can reliably stay in sync across restarts and scale ups.
Summary
It’s exciting to see how many improvements have been made to ksqlDB in the cloud since its original launch, and the team is always eager to provide new first-class features and ongoing improvements for our users. You can get a sneak peek of what the team is working on in our GitHub repository.
Future improvements that we’re looking to include:
- Enhancing the robustness of the protocol (e.g., retrying if a producer gets fenced off)
- Surfacing error messages about inconsistencies in ksqlDB with external state (e.g., the error message when a source topic is deleted for a stream or table)
- Compacting the command topic
We’re always open to community contributions, and if working on a hosted event streaming database sounds exciting to you, we’re hiring!
For further reading, check out:
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.