Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
비교하기
Confluent Cloud vs. Amazon MSK: Apache Kafka® 비용 및 기능 비교
Apache Kafka®의 가치를 완전히 실현하려면 전용 엔지니어링 리소스와 분산 시스템에 대해 상당한 전문 지식을 갖추고 있어야 합니다. 규모가 커질수록 Kafka를 자체 관리하는 일은 불가능에 가까워져 결국 필요 이상으로 프로비저닝된 클러스터에 대한 비용을 지불하거나, 아니면 예기치 못한 다운타임을 감수해야 하는 상황에 직면하게 됩니다.
이 심층적인 Confluent Cloud와 Amazon MSK 비교에서는 각 솔루션이 확장성, 복원력, 플랫폼 기능에서 어떻게 다른지 보여주고, Confluent가 자체 관리형 Kafka의 총 소유 비용을 40~70% 절감하는 방법을 설명합니다.
Self-managed 호스팅 Apache Kafka®에 비해 70% 더 효율적으로 운영하세요
실시간 데이터 파이프라인을 구축하든 AI 에이전트를 구축하든, Kafka는 이상적인 선택입니다. 분산형 설계는 고처리량, 저지연 워크로드를 처리할 수 있도록 구축되었지만, 많은 비용이 소요되는 과도한 프로비저닝이나 중단 위험 없이 대규모의 관리, 보안 및 최적화를 위해서는 심층적인 전문 지식이 요구됩니다.
Apache Kafka®의 원제작자들이 설립한 Confluent는 Kafka를 클라우드에서 최대 70% 더 효율적으로 운영하도록 재설계하는 데 300만 엔지니어링 시간을 투자했습니다. 그 결과, 다음과 같은 특성으로 당사의 완전 관리형 데이터 스트리밍 플랫폼을 지원하는 클라우드 네이티브 Kafka 엔진, Kora가 탄생했습니다.
-
인프라 비용을 절반 이상 절감할 수 있는 서버리스 자동 확장 클러스터
-
리소스 효율이 3배 더 높은 self-managed 단일 테넌트 클러스터
-
Self-managed 솔루션 대비 약 50% 단축된 클러스터 지연 시간
-
네트워크 비용을 절감하는 최적화된 라우팅 및 API 통합
오늘날 Kora는 AWS, Google Cloud, Microsoft Azure에서 매일 3조 개 이상의 메시지를 처리하는 30,000개의 Confluent Cloud 클러스터를 운영합니다.
MSK Zookeeper 마이그레이션: 중요한 업데이트를 전략적 기회로 바꾸세요
Kafka의 ZooKeeper 지원이 2026년 5월에 종료됨에 따라, ZooKeeper 기반 클러스터를 사용하는 모든 Kafka 사용자는 구버전의 Kafka 운영을 피하기 위해 KRaft로 전면적인 마이그레이션을 해야 합니다.
이는 MSK 고객에게 어떤 의미일까요?
-
ZooKeeper 기반 클러스터는 오픈소스 커뮤니티로부터 보안 패치와 버그 수정 등 핵심 업데이트를 더 이상 받을 수 없습니다. 이는 MSK 고객이 잠재적인 보안 및 관리 문제가 있는 자체 관리형 Kafka 버전을 사용하게 됨을 의미합니다.
-
MSK는 인플레이스 업그레이드 경로를 제공하지 않습니다. MSK 고객은 KRaft를 지원하는 새 클러스터를 설정하고 데이터와 워크로드를 수동으로 마이그레이션해야 합니다.
-
MSK Express 마이그레이션은 원활하지 않습니다. MSK Provisioned Standard에서 MSK Express로 이동하는 데에도 추가적인 노력이 필요합니다.
왜 Confluent로 마이그레이션해야 할까요?
이번 필수 마이그레이션은 전략을 재평가할 수 있는 완벽한 시점입니다. 단순히 기존 서비스를 유지하기 위해 복잡한 작업을 수행할 필요가 있을까요? 완전 관리형 데이터 스트리밍 플랫폼으로 전환해 고급 기능과 비용 절감 효과를 모두 누려 보세요.
-
완전 관리형 & 클라우드 네이티브: Kafka 라이프사이클 전체(프로비저닝, 업그레이드, 확장, 파티션 균형 조정)를 자동화하여, 사용자가 운영이 아닌 애플리케이션에 집중할 수 있도록 합니다.
-
탁월한 지원: 전문가 수준의 1차 Kafka 지원과 전체 스트리밍 플랫폼을 포함하는 99.99% SLA를 제공합니다. 이는 MSK보다 10배 더 우수한 수준입니다.
-
풍부한 통합 & 에코시스템: AWS 서비스 통합을 포함한 가장 방대한 관리형 커넥터 라이브러리를 제공하며, 멀티클라우드 및 SaaS 솔루션도 지원합니다.
-
데이터 거버넌스: 데이터 품질과 일관성을 보장하고 모든 데이터 스트림의 단일 진실 원본을 제공하는 Schema Registry 등 종합적인 거버넌스 기능을 갖추고 있습니다.
-
범용성: AWS, Azure, Google Cloud를 포함한 멀티클라우드 배포와 클라우드 및 온프레미스 환경을 아우르는 하이브리드 아키텍처를 지원합니다.
-
TCO 절감: PNI(Private Network Interface) 및 자동 확장 기능을 활용하여 Confluent Cloud로 마이그레이션하면 Confluent가 AWS MSK의 가격과 같거나 더 낮은 가격을 보장합니다.
"[Confluent 덕분에] 예상 연간 비용을 69% 절감했습니다. 또한 회의와 계절별 예측에 투입해야 했던 계획 수립 시간을 몇 달이나 [절약]했습니다."
Justin Dempsey, SAS Cloud 부문 수석 관리자
"Confluent를 기반으로 글로벌 IPV4 스캐닝 플랫폼 Horus를 구축한 이후, 오픈 소스 Kafka 또는 MSK와 비교하여 100만 달러 이상을 절감했습니다."
Jared Smith, SecurityScorecard Threat Intelligence 부문 수석 총괄
"Confluent를 통해 저희는 블랙 프라이데이와 같은 대규모 소매업체 이벤트나 대형 신규 고객과 계약할 때 확장에 필수적인 진정한 탄력성을 얻을 수 있으며, 이 모든 것이 더 높은 SLA로 뒷받침됩니다."
lan Compton, RevLifter 기술 이사
Kafka 소유 비용 – MSK 대 Confluent
내부 채택이 증가하고 Kafka의 사용 범위가 확장됨에 따라 팀은 다음에 더 많은 시간과 자원을 투입해야 합니다.
-
클러스터 프로비저닝 계획, 크기 조정 및 관리
-
소프트웨어 패치 및 업그레이드
-
장애 조치 설계 및 가용성 계획
-
고위험 거버넌스 및 보안 공백 메우기
-
신뢰성을 위한 계획 및 최적화
-
수동 부하 분산
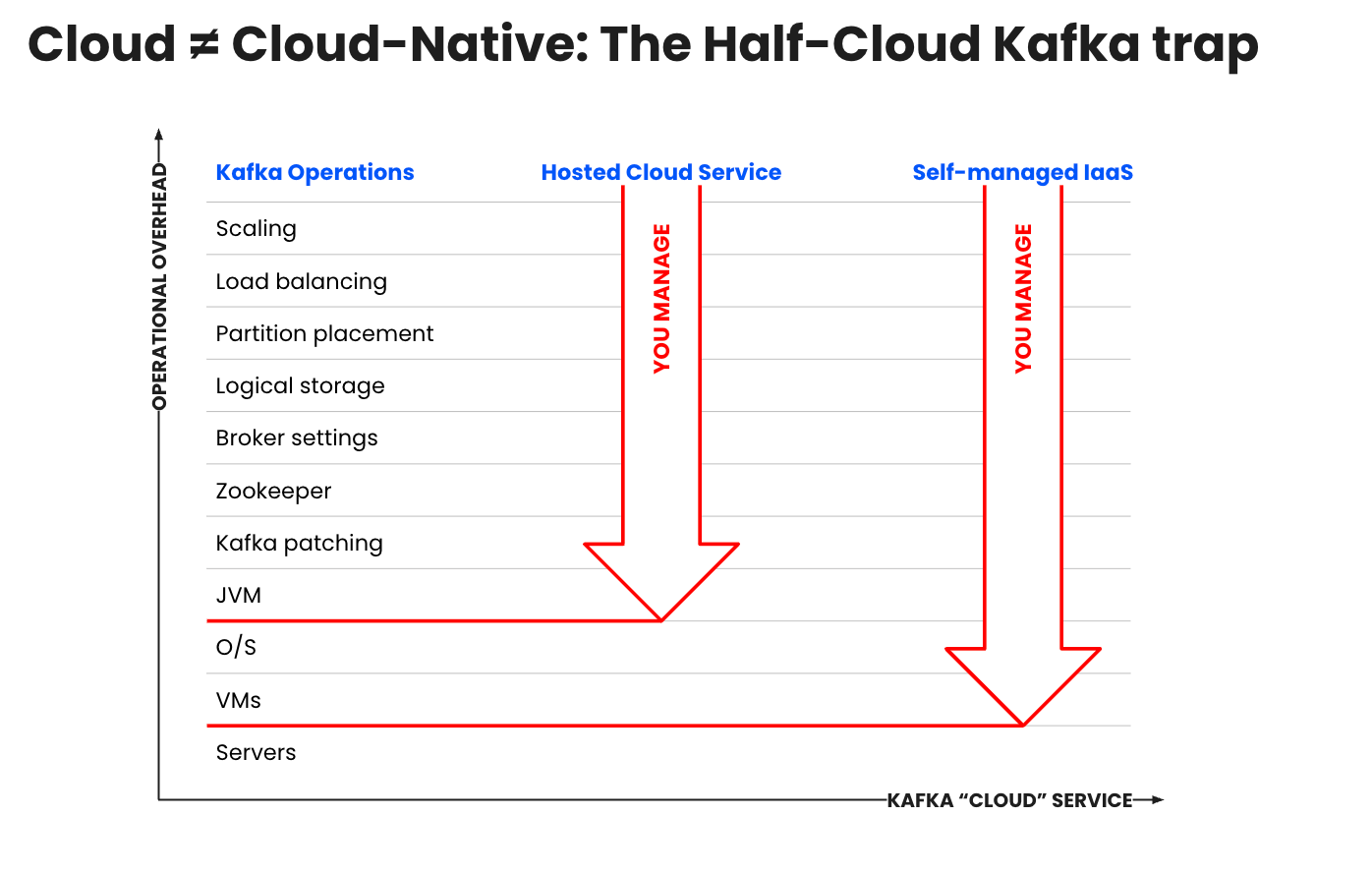
Kafka의 전체 가치를 실현하려면 상당한 재정적 및 기회 비용이 초래됩니다. 대규모 생산에 도달하는 데 평균 2년 이상이 걸리고, 플랫폼 개발 및 운영 비용으로 300~500만 달러가 소요됩니다. Confluent Cloud와 Amazon MSK는 모두 이 운영 부담의 경감을 약속합니다. 그러나 “관리형” Kafka 서비스는 모두 동일하게 만들어지지 않았으며, 클라우드 서비스 제공업체와 함께 호스팅된 Kafka를 선택하더라도 모든 중요한 작업은 팀이 처리해야 합니다.
이 관리형 Kafka 서비스 비교에서 진정한 관리형 서버리스 Kafka를 사용하여 얼마나 더 많은 작업을 수행하고 비용을 절약할 수 있는지 확인하세요. 257%의 투자 수익률을 선사하는 데이터 스트리밍 플랫폼으로 6개월 내에 투자 비용 회수가 가능합니다.
| Confluent Cloud | Amazon MSK | |
|---|---|---|
| 요약 | Confluent는 자동화된 기능을 통해 Kafka Cluster와 Connectors 인스턴스의 확장을 위한 대부분의 수동 작업을 줄입니다. | Amazon MSK는 심지어 MSK Serverless 클러스터에도 배포 작업에 대해 제한된 자동화 기능만 제공하기 때문에 여전히 큰 운영 부담이 따릅니다. |
| 자동화된 제품 기능과 수동 작업 및 맞춤형 개발의 비교 |
Self-managed
모든 클러스터에서 자동화됨:
사용자 지정:
*모든 Confluent Cloud 클러스터에서 지원 |
Self-managed
사용자 지정:
자동화:
*MSK Serverless 클러스터에서만 지원 |
| 선택의 자유 | AWS, Google Cloud 및 Microsoft Azure에서 사용 가능 | AWS에서만 사용 가능 |
Confluent Cloud와 Amazon MSK의 관리, 모니터링 및 유지 관리 비교
MSK도 운영상의 격차를 일부 해소해 주지만, 여전히 제한이 많습니다. 호스팅된 Kafka를 자체 관리하거나 사용하면 다음을 포함한 상당한 직간접적 비용이 발생합니다.
- 과도하게 프로비저닝된 클러스터로 인한 높은 인프라 비용 지출: 변동하는 수요를 지원하기 위해 필요한 과도한 프로비저닝, 계산 증가 없이 스토리지 확장 불가, 수동 구성, 리밸런싱, 업그레이드 및 패치로 인한 성능 저하
-
운영 오버헤드 및 제한된 리소스: 프로비저닝, 용량 계획, 업그레이드 및 모니터링에 소요되는 높은 시간 및 리소스 비용과 비즈니스 차별화 비용, Kafka에 숙련된 인재를 채용, 고용 및 유지하는 데 드는 비용
-
예상치 못한 운영 중단: Kafka가 더 많은 사용 사례, 애플리케이션, 데이터 시스템, 팀 및 환경을 아우를수록 많은 비용이 소요되는 다운타임과 보안 침해의 위험이 증가합니다.
이러한 비용이 누적되면 가치 실현 시간이 지연되고 총 소유 비용(TCO)이 증가하며, 예기치 못한 다운타임, 보안 침해, 데이터 손실로 인한 수익 손실 위험이 높아집니다.
운영 부담을 줄이고 자주 발생하는 Kafka 문제를 해결하는 방법에 대해 Confluent Cloud와 Amazon MSK를 비교해 보세요.
Kafka와 Confluent, MSK를 비교한 백서 읽기
| 서비스 | Confluent Cloud | Amazon MSK | MSK 서버리스 |
|---|---|---|---|
| 프로비저닝 | 셀프 서비스, 주문형. Kafka, Schema Registry 및 Flink용 | 셀프 서비스, 주문형. Kafka 전용 | 셀프 서비스, 주문형. Kafka 전용 |
| 자동 확장 | 모든 워크로드에 적합한 크기로 자동 확장되는 서버리스 클러스터 | 수동 확장 | 제한된 할당량으로 탄력적으로 확장(200/400MBps) |
| 클러스터 유형 | 모든 작업 부하 및 사용 사례에 적합한 유연하고 비용 효율적인 클러스터 유형 | 수동 확장이 필요한 Standard 및 Express 클러스터 | MSK Serverless 클러스터는 예측할 수 없는 중요한 작업에 적합한 MSK의 사전 프로비저닝된 클러스터임 |
| Infrastructure as Code(IaC) | 제어 계층 및 데이터 계획용 | 제어 플레인 전용 | 제어 플레인 전용 |
| 인프라 모니터링 | 선제적 모니터링 | 수동 모니터링 | 선제적 모니터링 |
| 토픽 모니터링 | 사전 집계된 메트릭 무료 제공 | 토픽 수준 메트릭은 추가 비용 발생 | 기본 모니터링 무료 |
| 업그레이드 | 항상 최신의 안정적인 버전 | 제한적인 버전 지원 | 제한적인 버전 지원 |
| 소프트웨어 패치 | 사전 예방적 수정사항 제공 | 사후 수정사항 제공 | 사후 수정사항 제공 |
| 클러스터 확장 | 탄력적인 확장성 | 수동 데이터 리밸런싱 | 탄력적인 확장성 |
| Connectors 확장 | 사전 구축 및 완전 관리형 | 직접 개발 및 관리형 | 직접 개발 및 관리형 |
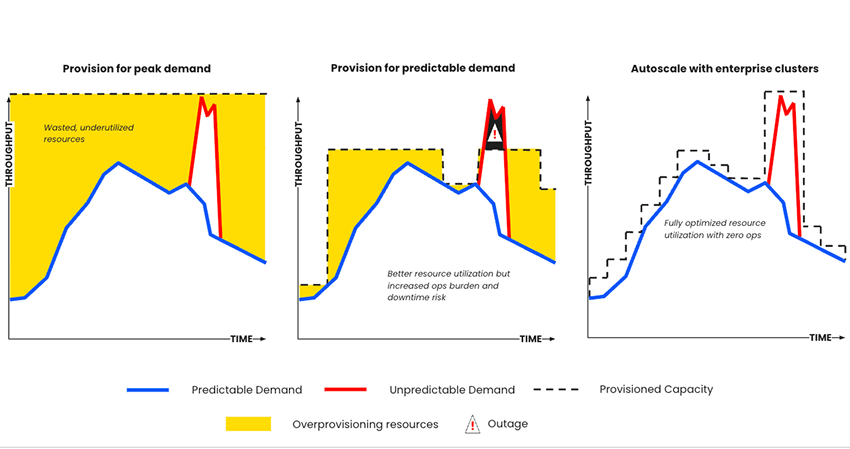
Confluent Cloud와 Amazon MSK는 클러스터 크기 조정을 어떻게 간소화하나요?
-
Confluent Cloud는 처리량 기반 크기 조정을 사용합니다. 번거로운 성능 테스트를 생략하고, 사용한 만큼 비용을 지불하는 탄력적으로 확장 가능한 0으로 조정되는(scale-to-zero) 클러스터를 통해 인프라 비용을 절감할 수 있습니다.
-
MSK는 브로커 기반 크기 조정을 사용합니다. 성능 테스트를 진행하여 브로커 유형과 수를 선택하는 데 시간과 리소스를 할당해야 하며, 자동 확장 한도(하루에 작업 4개)로 인해 추후 복잡한 확장을 해야 하는 필요성을 줄이기 위해 인프라를 과할당해야 합니다.
-
MSK Serverless는 처리량 기반 크기 조정을 사용합니다. Kafka Cluster를 Glue Schema Registry 및 Flink와 함께 프로비저닝합니다. Connectors와 Kafka 프록시에 사용자 정의 작업이 필요합니다.
Confluent Cloud 또는 Amazon MSK는 프로비저닝 및 관리를 어떻게 자동화하나요?
-
Confluent Cloud는 전체 플랫폼에 대한 주문형 셀프 서비스 프로비저닝을 제공합니다. Schema Registry, Connect 및 Apache Flink®용 Confluent Cloud를 포함한 다른 Confluent Cloud 구성 요소와 함께 Kafka Cluster를 프로비저닝합니다. 또한 Terraform 공급자를 사용하여 클러스터 및 Schema Registry와 같은 제어 계층 리소스와 토픽 및 ACL 같은 데이터 계층 리소스를 자동으로 관리할 수 있습니다.
-
Amazon MSK는 주문형 셀프 서비스 프로비저닝을 Kafka 전용으로 제공합니다. MSK Provision과 MSK Serverless 모두에 대해 Connectors 및 Kafka 프록시에 필요한 Glue Schema Registry 및 Flink 사용자 정의 작업과 함께 Kafka 클러스터를 프로비저닝합니다. Terraform은 제어 계층 리소스만 배포하고 관리할 수 있습니다. 데이터 계층 리소스를 관리하려면 사용자 정의 운영자와 프로세스를 구축해야 합니다.
Confluent Cloud나 Amazon MSK는 기본적으로 모니터링 기능을 제공하나요?
-
Confluent Cloud는 선제적 인프라 모니터링과 토픽 모니터링을 위한 무료 집계 메트릭을 제공합니다. Kafka 전문가의 선제적 클러스터 모니터링 및 유지 관리를 통해 앱 개발에 계속 집중할 수 있습니다. 무한 스토리지로 디스크 공간 관련 장애의 위험을 줄이면서 클러스터 수준의 스토리지 사용 사례를 무제한으로 지원합니다. 추가 비용 없이 토픽과 클러스터 수준에서 사전 집계된 가장 중요한 메트릭을 이용할 수 있으며, Metrics API를 사용하여 사용자가 선택한 타사 모니터링 서비스를 메트릭과 함께 이용할 수 있습니다.
-
MSK Provisioned는 추가 비용으로 수동 인프라 모니터링과 토픽 수준 메트릭을 제공합니다. CPU 사용률과 같은 브로커 메트릭을 모니터링할 리소스를 할당하여 클러스터 성능을 선제적으로 관리합니다. 스토리지 용량으로 인한 장애를 방지하기 위해 디스크 공간을 모니터링하고 관련 경보를 생성합니다. 사용량 전체를 모니터링하기 위해 브로커별 및 토픽별 메트릭을 이용 및 수동 집계하는 유료 서비스를 제공합니다.
-
MSK Serverless 클러스터는 사전 인프라 모니터링과 무료 기본 토픽 모니터링을 제공합니다. 선제적 클러스터 모니터링 및 유지 관리를 통해 앱 개발에 집중할 수 있습니다. 무한 스토리지로 디스크 공간 관련 장애의 위험을 줄이면서 클러스터 수준의 스토리지 사용 사례를 무제한으로 지원합니다. AWS 제품 다수를 모니터링하는 별도의 도구인 CloudWatch 콘솔을 사용하여 토픽 수준 메트릭을 무료로 이용할 수 있습니다. 파티션 수준 메트릭 또는 Datadog 및 Dynatrace와 같은 인기 모니터링 도구와의 기본 통합은 포함되지 않습니다.
Confluent Cloud와 Amazon MSK에서 Kafka 유지 관리는 어떻게 진행되나요?
-
Confluent Cloud는 항상 최신 안정 버전으로 업데이트되며, 버그와 취약점은 선제적 및 적극적으로 수정됩니다. Kafka, 버그 수정, 패치 등을 포함하여 99.99%의 SLA가 제공됩니다.
-
Amazon MSK는 버전 지원 및 사후 수정에 제한이 있습니다. MSK는 Kafka 릴리스 중 일부만 지원하며, 예정된 Apache가 릴리스된 다음에 AWS가 지원을 추가하면 수동으로 업그레이드를 트리거해야 합니다. MSK는 99.9% SLA와 일부 버전의 Kafka만 제공합니다. Kafka 소프트웨어로 인한 장애는 MSK 가동 시간 SLA에 포함되지 않습니다. 릴리스가 일부만 지원되면 취약점 수정을 사후에 대응하는 방식으로 진행할 수밖에 없습니다. MSK Serverless 클러스터는 무중단 롤링 업그레이드의 일환으로 일체의 개입이 없습니다. MSK는 Kafka 릴리스 중 일부만 지원하며 최신 버전은 알려지지 않았고 완전히 추상화된 상태입니다.
Confluent Cloud와 Amazon MSK는 클러스터를 어떻게 확장하고 축소하나요?
-
Confluent Cloud는 클러스터에 리소스를 자동으로 확장하고 할당합니다. Confluent는 처리량이 GBps 규모로 증가하거나 감소할 때 전적으로 탄력적인 자동 확장 클러스터를 통해 소비자 지연을 관리하여 인프라 비용을 절반 이상 절감합니다. 클러스터 컴퓨팅의 과도한 프로비저닝을 제거하고 무한 스토리지를 통해 보존 한도를 직접 설정하세요.
-
Amazon MSK에서는 프로비저닝된 클러스터와 자체 개발된 self-managed Connectors에 대해 수동 데이터 재조정이 필요합니다. 브로커가 클러스터에 추가된 다음에 Cruise Control을 사용하는 수동 데이터 재조정 프로세스가 필요합니다. 계층형 스토리지를 사용할 수 있지만 브로커당 최대 16TB까지 확장 가능한 EBS 볼륨이 여전히 필요하며, 브로커는 30개로 제한됩니다. AWS의 명시적인 기술 지원 없이 자체 구축 또는 커뮤니티 구축 Connectors를 활용합니다. 기본 MSK Connect 인프라만 제공됩니다.
-
MSK Serverless 클러스터는 제한된 할당량 안에서 탄력적으로 확장할 수 있으며 self-managed Connectors가 필요합니다. 자동 클러스터 재조정을 통한 0~200MBps 범위의 손쉬운 확장 및 축소를 통해, 무한 스토리지를 사용하여 토픽 보존을 늘릴 때 클러스터 과잉 프로비저닝을 제거합니다.
Confluent의 완벽한 데이터 스트리밍 플랫폼과 AWS에서 호스팅되는 Kafka 비교
Confluent가 업계 전반에서 신뢰받는 이유는 무엇일까요? Confluent는 MSK의 기능을 뛰어넘는 엔터프라이즈급 기능을 통해 완전한 데이터 스트리밍 플랫폼을 제공하고, 수많은 스트리밍 사용 사례를 활용할 수 있도록 지원합니다.

| 서비스 | Confluent Cloud | Amazon MSK | MSK 서버리스 |
|---|---|---|---|
| Kafka UI | 완전 관리형 | 제공되지 않음 | 제공되지 않음 |
| 인증 | 광범위한 인증 | 광범위한 인증 | 제한된 인증 |
| 암호화 | 종단 간 암호화 | 지원되지 않음 | 지원되지 않음 |
| Connectors | 사전 구축 및 완전 관리형 | 맞춤형 구축 및 self-managed | 맞춤형 구축 및 self-managed |
| 데이터 거버넌스 | 완전 관리형 | 제공되지 않음 | 제공되지 않음 |
| 스트림 처리 | 완전 관리형 | 복잡성이 추가됨 | 복잡성이 추가됨 |
| 테이블로 스트림(Streams-to-Tables)을 위한 Zero-ETL | 이제 Tableflow로 사용할 수 있음 | 제공되지 않음 | 제공되지 않음 |
Confluent Cloud 및 Amazon MSK는 어떤 엔터프라이즈급 보안 기능을 제공하나요?
-
Confluent Cloud는 모든 클러스터 유형에 대해 광범위한 인증을 지원합니다. 인증된 클라이언트만 클러스터에 접근할 수 있습니다. Confluent Cloud는 SASL/PLAIN과 SASL/OAUTHBEARER(미리 보기)를 인증 메커니즘으로 지원합니다. Client-Side Field Level Encryption은 클라이언트의 민감한 데이터를 암호화하여 클라이언트와 서버에서 모두 보호하고, 생산자와 소비자 사이에서 데이터가 오가는 중에도 보안을 유지하여 보안을 강화합니다.
-
Amazon MSK는 MSK Provisioned 클러스터에 대해 광범위한 인증을 지원하고, MSK Serverless에 대해 제한된 인증을 지원하며, 암호화를 미지원합니다. 모든 MSK 클러스터가 인증된 액세스만 허용하지만, MSK Provisioned 클러스터는 SASL/SCRAM, mTLS 및 IAM을 인증 메커니즘으로 지원하며, MSK Serverless 클러스터는 IAM만을 인증 메커니즘으로 지원합니다.
Confluent Cloud 및 Amazon MSK는 어떤 종류의 Kafka Connectors를 제공하나요?
-
Confluent Cloud는 120개가 넘는 사전 구축된 Connectors와 80개가 넘는 완전 관리형 Connectors를 제공합니다. 사전 구축된 완전 관리형 구성 요소 또는 Confluent 지원이 적용되는 사전 구축된 구성 요소로, 120개 이상의 사용 가능한 Connectors로 지속적으로 성장하는 포트폴리오를 통해 온프레미스와 퍼블릭 클라우드 전반에서 Confluent와 최신 및 레거시 서비스를 쉽고 완벽하게 통합합니다.
-
Amazon MSK는 맞춤 구축형 self-managed Connectors만 지원합니다. 자체 Connectors를 구축하거나 커뮤니티에서 개발한 소규모 Connectors 세트에서 배포할 수 있는 옵션으로 Kafka를 사용하는 데이터 서비스와 통합합니다. 맞춤형으로 구축된 Connectors에는 유지 관리가 필요하며 Kafka 커뮤니티 Connectors에는 AWS 기술 지원이 적용되지 않습니다.
Confluent Cloud와 Amazon MSK는 어떤 거버넌스 기능을 제공하나요?
-
Confluent Cloud의 Stream Governance는 데이터 가용성, 무결성, 보안을 관리하는 완전 관리형 서비스 제품군을 제공합니다. Stream Governance는 Stream Lineage, Stream Catalog, Stream Quality라는 세 가지 주축을 기반으로 합니다. Data Quality Rules는 고품질 스트림을 보장합니다.
-
Amazon MSK 이용 시 Kafka 토픽 데이터 관리를 위해 지원이 없는 무료 커뮤니티 도구 또는 유료 타사 도구를 사용해야 합니다. MSK에는 계보 또는 카탈로그 기능이 없습니다. MSK와 MSK Serverless는 데이터 품질을 위해 Confluent 및 Glue Schema Registry와 통합합니다. 그러나 데이터 producers가 스키마 진화 제어에 Schema Registry를 사용하게 하는 브로커 측 스키마 검증, 데이터 스트림 안에서 개별 필드 값을 검증하고 제한하는 Data Quality Rules, 여러 환경에서 스키마를 동기화하는 스키마 연결이 부족합니다.
Confluent Cloud와 Amazon MSK는 어떤 스트림 처리 기능을 제공하나요?
-
Confluent는 서버리스 스트림 처리를 Apache Flink®용 Confluent Cloud와 함께 제공합니다. 사용자는 간단히 Flink 클러스터를 생성하고 SQL과 유사한 언어를 사용하여 스트림 처리를 시작할 수 있습니다. 또한 Confluent Cloud는 완전 관리형 AWS Lambda 서비스를 지원합니다.
-
Amazon MSK는 Flink를 사용한 스트림 처리를 제공하지만 복잡성이 증가합니다. MSK는 강력하지만 복잡성이 증가하는 Apache Flink용 관리형 서비스(MSF)를 지원합니다. 사용자가 네트워킹을 구성하고, MSF Studio 노트북을 생성하고, SQL 유사 구문을 사용하여 작업을 작성하고, 코드를 테스트 및 패키징하여 S3에 업로드하고, 업로드된 코드로 MSF 애플리케이션을 생성해야 한다는 점에서 강력하지만 더 복잡합니다.
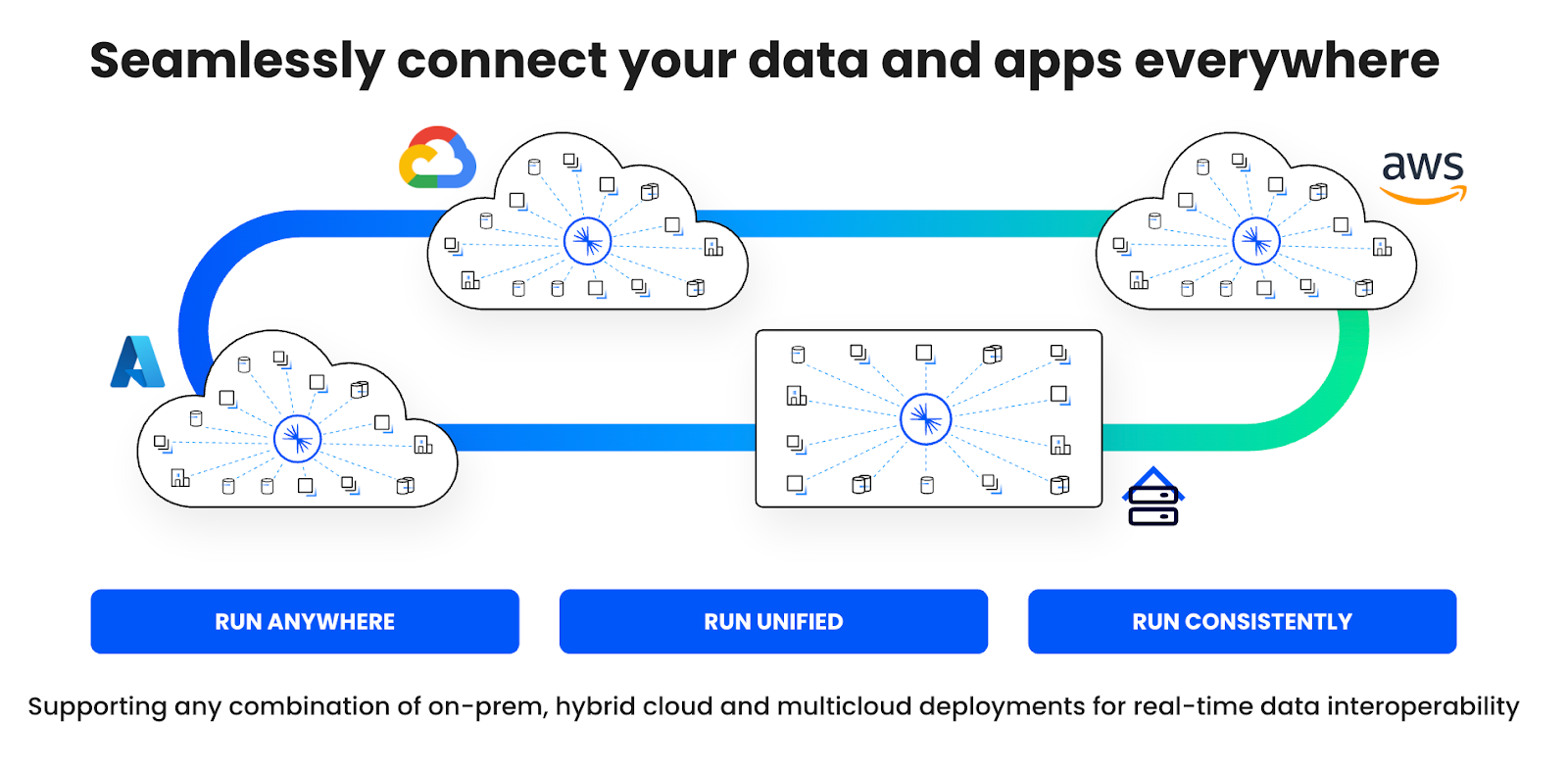
Confluent를 통한 하이브리드 및 멀티클라우드와 AWS 벤더 종속성의 비교
클라우드 네이티브 데이터 스트리밍을 통해 확장할 수 있도록 구축하세요. 그리고 하나의 클라우드 서비스에 얽매이지 마세요. Amazon MSK(AWS에서만 사용 가능)와 달리, Confluent는 진정으로 유연한 배포 기능을 제공하여 온프레미스, 하이브리드 및 멀티클라우드 아키텍처의 모든 조합을 지원하며, 원활한 데이터 상호 운용성을 보장합니다.
-
AWS, Microsoft Azure, Google Cloud에서 일관된 완전 관리형 서비스 제공
-
Confluent Platform을 사용한 클라우드 네이티브, self-managed 데이터 스트리밍
-
WarpStream BYOC을 통한 제어 및 비용 효율성
또한, Cluster Linking은 실시간으로 모든 환경 간에 데이터를 동기화하는 지속적 브리지를 제공합니다.
맞춤형 비용 절감 견적을 받아보세요
Confluent Cloud와 Amazon MSK의 맞춤형 비용 비교를 통해 절감 효과를 확인하세요. 문의 양식에 정보를 기입해서 보내주시면 저희가 연락을 드려 Confluent를 통한 비용 절감 효과 계산을 도와드리고 궁금하신 점에 답변해 드리겠습니다.
아직 영업팀과 상담할 준비가 되지 않으셨나요? 관련 리소스를 탐색하세요.
Confluent Cloud vs. Amazon MSK: FAQs
Is Confluent Cloud more cost-effective than Amazon MSK?
Yes, Confluent Cloud is more cost-effective than Amazon MSK because of cost savings from:
-
Reduced infrastructure costs: Confluent Cloud’s serverless, cloud-native architecture eliminates the need for over-provisioning that is common with MSK’s node-based pricing. Features like Infinite Storage and Tiered Storage decouple compute and storage, further reducing infrastructure spending. For example, SecurityScorecard saved over $1M in infrastructure and operational costs by migrating to Confluent Cloud
-
Lower operational overhead: Offloading complex and time-consuming operational tasks—such as capacity management, scaling, and upgrades—to Confluent Cloud allows you to reallocate valuable engineering resources to innovation instead of infrastructure management. One customer reported they would have needed to hire at least 10 more people to manage Kafka themselves.
-
Minimized downtime and risk: Confluent Cloud offers a 99.99% uptime SLA for production workloads. Compared to MSK (with a 99.9% SLA with exclusions for Kafka failures and customer configuration failures), Confluent’s SLA delivers higher reliability and reduces the substantial hidden costs associated with downtime.
Choosing Confluent Cloud can reduce your self-managed Kafka costs by 40-70%.
What are the main cost drivers of Confluent Cloud vs Amazon MSK?
The main cost drivers of Confluent Cloud are:
-
Usage based consumption: Confluent Cloud’s pay-as-you-go pricing is based on actual usage (e.g., throughput) rather than provisioned infrastructure. This pay-as-you-go model eliminates the need for over-provisioned, underutilized clusters that typically lead double the infrastructure costs for self-managed Kafka vs fully managed on Confluent.
-
Managed horizontal scaling: Elastic Confluent Units for Kafka (eCKUs) are a Confluent Cloud’s unit of horizontal scalability for billing. eCKUs autoscale up and down based on workload. The cost includes the complete management of the platform, from infrastructure and scaling to monitoring and support, which is designed to reduce or eliminate the separate operational and support costs customers would otherwise incur.
The main cost drivers of Amazon MSK are:
-
Higher infrastructure spend: MSK uses node-based pricing, requiring users to pay for provisioned compute and storage, which often leads to over-provisioning to handle peak loads. Networking, particularly cross-Availability Zone (cross-AZ) traffic, can also become a significant hidden cost, sometimes accounting for 80-90% of total infrastructure expenses.
-
Self-managed operations and management: Since MSK is not a fully managed Kafka service, significant engineering resources are required for manual tasks like sizing, scaling, rebalancing partitions, patching, and monitoring. This includes the cost of hiring and retaining specialized Kafka talent.
-
Custom development and maintenance: MSK requires significant custom platform development and maintenance, which can take 2+ years to bring to production and cost $3-5M or more in costs. Because MSK is a hosted service rather than a complete platform with essential components included out-of-the-box, engineering teams must spend valuable time and resources building and maintaining their own solutions for developer tools, DevOps automation, infrastructure enhancements for reliability and disaster recovery, monitoring, integration, security controls, and governance.
-
Unplanned downtime and higher business risk: MSK's 99.9% SLA excludes failures in the underlying Kafka software, as well as failures due to customer errors in configuration, leaving customers responsible for resolving failures that can easily turn into major outages. The risk of outages due to storage limitations, manual scaling errors, or unresolved bugs can lead to substantial hidden costs, including lost revenue and reputational damage.
What are the pros and cons of MSK Serverless vs Confluent Cloud?
Confluent Cloud pros and cons include:
-
Pro: Confluent Cloud offers a complete, serverless experience that automates all operational aspects, from capacity planning and elastic scaling (to GBps+) to upgrades and monitoring.
-
Pro: Confluent Cloud goes far beyond core Kafka, providing a rich ecosystem of 120+ connectors, serverless Flink for advanced stream processing, and an enterprise-grade Stream Governance suite.
-
Pro: Confluent Cloud delivers significant cost savings through cost-efficient autoscaling and usage-based consumption (which prevents overprovisioned and underutilized clusters and cuts infrastructure costs by 50%+), lowers TCO 40-70% compared to self-managed Kafka by eliminating $1M in development and operations costs over 3 years, and with a 99.99% uptime SLA that reduces business risk.
-
Con: For smaller teams, projects with predictable workloads, or organizations that already have in-house Kafka expertise, Confluent's fully managed service and advanced features may not present a clear upfront financial advantage.
MSK Serverless pros and cons include:
-
Pro: MSK Serverless addresses some of MSK's operational challenges with pre-provisioning
-
Pro: MSK Serverless can elastically scale to a given quota without the need for manual rebalancing.
-
Pro: MSK Serverless offers unlimited storage (with a per-partition quota) without the manual configuration required by MSK Standard brokers.
-
Con: MSK Serverless has a strict throughput limit of 200MBps ingress and 400MBps egress, with no upgrade path for workloads that exceed this.
-
Con: MSK Serverless lack many mission-critical components, including a rich connector ecosystem, integrated stream processing (like Flink), and comprehensive, enterprise-grade security and governance tools.
-
Con: MSK Serverless has the same weak 99.9% SLA as MSK Provisioned, which does not cover Kafka-related failures.
-
Con: Like all MSK offerings, MSK Serverless has no multicloud support and is locked into the AWS ecosystem.
How does Confluent Cloud autoscale throughput compared to MSK?
Confluent Cloud offers true elastic, automated scaling from 0 to GBps, while Amazon MSK's elastic scaling capabilities are more limited and manual:
-
Confluent Cloud provides fully managed, automated, and elastic scaling. It can automatically scale clusters up and down from 0 to GBps+ to meet demand without interruption. Its cloud-native Kora engine uses an intelligent control plane and self-balancing algorithms to manage capacity, rebalance partitions, and eliminate the need for overprovisioning and underutilizing clusters to avoid outages. As a result, customers can save 50% or more on infrastructure costs.
-
Standard clusters on MSK Provisioned require manual sizing, scaling, and rebalancing. While you can add brokers to scale up, you cannot easily scale down and are more likely to have a large number of overprovisioned clusters at any given time. Modifying storage capacity can take anywhere from 6 to 24 hours. Express clusters on MSK Provisioned offer faster scaling and rebalancing, but it is still a manual process.
-
MSK Serverless offers some autoscaling but only within a lower quota limit (up to 200 MBps ingress and 400 MBps egress). There is no solution to upgrade beyond this quota without moving to a different offering.
How do Confluent and MSK differ in cluster provisioning speed?
Confluent Cloud can provision clusters in minutes, whereas provisioning an Amazon MSK cluster can take from 30 minutes to over an hour.
Is Confluent Cloud more reliable and performant than MSK?
Yes, Confluent Cloud is architected to be more reliable and performant than Amazon MSK and significantly reduces the risk of unplanned downtime compared to MSK:
-
Confluent's Kora engine provides native resilience with continuous monitoring, proactive replacement of degraded nodes, and automatic rebalancing to maintain availability without operator intervention. MSK lacks these native self-healing capabilities, requiring customers to manually identify and replace failed brokers.
-
Confluent Cloud offers a 99.99% uptime SLA that covers all components, including Kafka-related failures. This translates to a maximum of 0.876 hours of downtime per year. Amazon MSK offers a 99.9% SLA (a maximum of 8.76 hours of downtime per year), but that SLA explicitly excludes failures caused by the underlying Apache Kafka or Zookeeper software, placing the burden of resolving these critical issues on the customer and significant increasing the actual maximum hours of downtime per year MSK customers may experience.
Which platform offers stronger developer tooling, Confluent Cloud or Amazon MSK?
Confluent Cloud offers significantly stronger and more comprehensive developer tooling than Amazon MSK:
-
Confluent Cloud provides a robust Terraform provider that allows developers to manage both control plane resources (like clusters and Schema Registry) and data plane resources (such as Topics and ACLs). This enables complete automation of infrastructure deployments as code. Amazon MSK offers more limited IaC capabilities, as its Terraform support can only manage control plane resources. Managing data plane resources requires building custom operators and processes.
-
Confluent Cloud offers a rich set of APIs for point-and-click operations and automation. It also provides a user-friendly and intuitive cloud UI that allows developers to easily manage and monitor their Kafka clusters and data streams. MSK does not have a dedicated Kafka UI and developers must often build their own tools on top of MSK’s APIs. For example, MSK lacks a native REST proxy for non-Java clients, a feature available in Confluent.
-
Confluent Cloud supports multi-language client development, providing client libraries for several non-Java languages including C/C++, Go, Python, and .NET. Users can generate the necessary configuration details (including cluster credentials and API keys) directly from the Confluent Cloud Console and paste them into client application code. Amazon MSK also supports non-Java clients but enabling them to interact with MSK requires some additional work when setting up and configuring the clients for authentication and authorization.
Does Confluent Cloud offer better support than Amazon MSK?
Yes, Confluent provides customers with guidance from the world's foremost Kafka experts. Confluent was founded by the original co-creators of Kafka, and its support and professional services teams have millions of hours of Kafka experience. MSK support is limited and does not have the same depth of Kafka-specific knowledge.
What are the feature differences around connectors and schema management?
Confluent Cloud provides 120+ pre-built connectors and 80+ fully managed connectors, enabling instant integration with a wide range of popular data sources and sinks both inside and outside the AWS ecosystem. In contrast, Amazon MSK has very limited connector support. It offers fewer than 10 direct or "half-supported" integrations and primarily provides just the underlying Connect infrastructure, requiring users to bring, manage, and maintain their own connectors. This results in additional operational burden and cost. In fact, Confluent offers instant, fully managed connectivity to more native AWS services than Amazon MSK does.
Confluent Cloud includes Stream Governance, a comprehensive, fully managed suite that provides Schema Registry, Data Portal, Stream Lineage, and Data Quality Rules. With features like broker-side schema validation and the ability to tag data containing personally identifiable information (PII), your data streams are discoverable, trustworthy, and secure. Amazon MSK integrates with AWS Glue Schema Registry but lacks a full suite of governance tools, such as schema validation, data lineage, or a data catalog.
Does Confluent Cloud support multicloud deployments?
Yes, Confluent Cloud supports multicloud deployments. It is designed for both multicloud and hybrid environments, whereas Amazon MSK is an AWS-only service. Confluent customers can use its fully managed Kafka service on all three major public clouds and use its Cluster Linking feature to replicate data across clouds.