Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
How Confluent Can Help Optimize and Modernize Your SIEM for Better Cybersecurity
In the last few years, we’ve seen hugely impactful cyberattacks that have grabbed the attention of the media, the security community, and the IT industry. The WannaCry attack, for instance, aimed at extorting money from its victims, with an estimated total financial impact of over $4B in losses across the globe. The SolarWinds breach in 2019, which attacked the network management systems of many organizations including the U.S. Treasury Department, the Department of Defense, and over 425 Fortune 500 companies, caused massive disruption and leaks of substantial private information. And in 2021, we saw a slew of disruptive attacks on some of the nation’s largest organizations like CNA Financial, Colonial Pipeline, Kaseya, crippling enterprise operations and disrupting business continuity.
Cyberthreats to citizens and organizations have become so grave that the current U.S. administration issued an executive order in 2021 entitled Improving the Nation’s Cybersecurity noting that “recent cybersecurity incidents such as SolarWinds, Microsoft Exchange, and the Colonial Pipeline incident are a sobering reminder that U.S. public and private sector entities increasingly face sophisticated malicious cyber activity from both nation-state actors and cyber criminals.”
According to the most recent annual report by IBM, the average cost of a single security incident hit $4.24 million—the highest cost in the 17-year history of the report. If that cost doesn’t scare you enough, the same report declares that it takes an average of 287 days to identify and contain a data breach.
Over the last 15+ years, many organizations have relied on Security Incident and Event Management (SIEM) tools to protect their environment and improve security operations. However, since threat vectors are creative and elusive, the existing tools struggle to detect and respond to new threats in a timely manner and cannot always be effectively integrated end to end in order to respond to new threats as early as possible, and at scale. While SIEM platforms have proven their worth and have a definite place in your cybersecurity strategy, there’s still a real need to incorporate and integrate data beyond their capabilities. Confluent has established itself as a critical component for SIEM strategies, providing the means for integrating disparate data across many systems in real time.
The need for SIEM modernization
SIEM tools aggregate data from multiple log sources, enabling search and investigation of security incidents and specific rules for detecting attacks. Popular SIEM offerings include Splunk, ArcSight, Elastic, Exabeam, and Sumo Logic. These systems work by collecting event data from a variety of sources like logs, applications, network devices, servers, and firewalls, using proprietary collection agents to bring it all directly into their centralized platform.
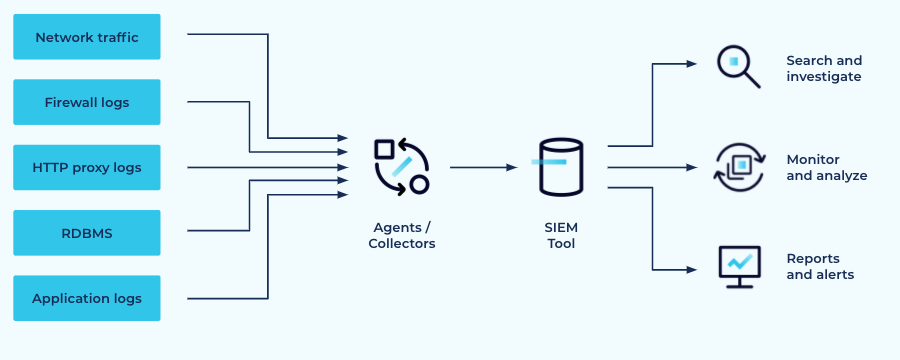
Architecture of a typical SIEM platform
There are a number of deficiencies with existing real-world SIEM solutions. The top three include fragmentation of operations, a lack of incident response agility, and high costs due to big data scale. Let’s take a look at each one of these.
Multi-platform fragmentation
Cybersecurity is one of the biggest priorities for most enterprises, but there are often multiple groups sharing the responsibility. This, coupled with differing capabilities and cost, has resulted in the frequent adoption of multiple SIEM tools in many enterprises. Standardizing on a single tool can be difficult and sometimes, even impractical. This leads to a fragmented solution to the more general problem of cybersecurity, making it difficult for security operations teams to obtain a coordinated security view.
When you factor in the frequent use of multiple SIEM tools the architecture looks more like this:
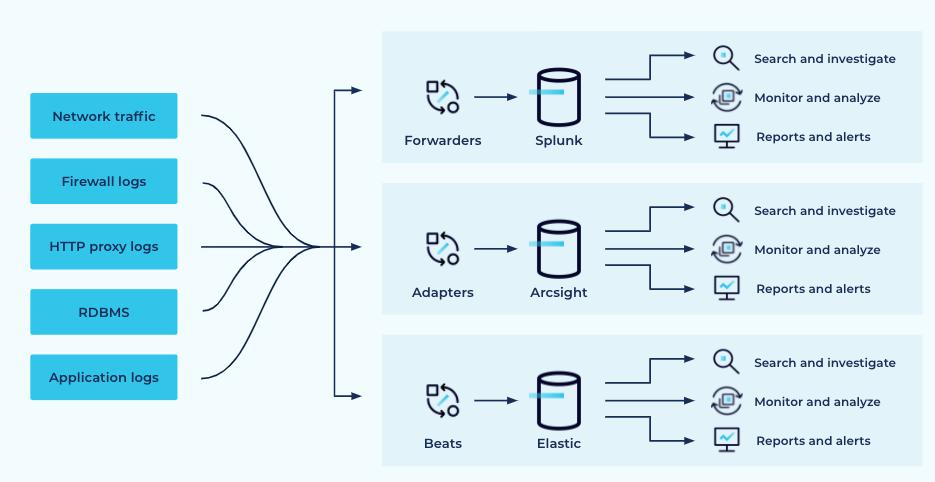
More than one SIEM platform is usually in use
Indeed this picture is highly simplified since the lines are neatly symmetrical, going to all the agents. In reality, the different data sources will be mapped to different tooling, the level of coverage will be different, and not all data sources will be covered.
The fragmentation of SIEM platforms and data causes a number of issues. It’s difficult to use data across vertical SIEM instantiations. Data engineering work needs to be done separately for each tool which leads to duplication of effort in both development and maintenance. Bringing new tools to bear is even harder, creating yet another fragment each time. Plus, shifting workloads from one tool to another is difficult. For example, suppose you decide that you want to send all the DNS data to Elastic rather than sending it to Splunk, there’s no real easy way to accomplish this.
Batch-oriented architectures preclude real-time insights
Traditional SIEM tools are based on data at rest batch-oriented architectures. While batch operations are good for collecting data and running complex searches to find threats and vulnerabilities against a historical corpus, they are not designed to provide an up-to-date picture of what’s going on right now. This means organizations solely relying on these tools simply lack the real-time insights to quickly mount an effective security response.
This article specifically discusses the problem of delayed events going unnoticed, the impact of it, and how to detect it. Reading between the lines, care must be taken to implement the special approaches discussed there, and when that care isn’t taken, significant events can be missed. It’s better to apply an architecture that’s built for event streaming and can natively handle datasets that may arrive out of order but where timeliness is important.
Lack of incident response agility
Fragmentation combined with insufficient observability leads to lack of agility in the face of an evolving threat landscape. Cyberattacks and vulnerabilities are unpredictable and therefore hard to proactively plan for. Data relevant to security can live anywhere from filesystems, to general purpose databases to transient network packets, and their relevance varies highly at any given time depending on the threat vector. Each of these data sources need to be integrated into an end-to-end modernization effort, to allow for recombination of data for threat analysis. Additionally, incorporating new data sources must be quick and easy, to access previously uncaptured data for use in resolving live incidents.
Capturing and integrating data is only one piece of the response. You must also be able to incorporate new rules and machine learning models to detect both environmental vulnerabilities and ongoing cyberattacks. But in a fragmented SIEM environment, each individual tool uses its own set of agents and rules, not only resulting in noisy alerts but also making operational agility difficult to achieve. In addition, search, discovery, and implementation is further compromised by the SIEM-specific fragmented storage.
Big data scale drives up costs
SIEM relevant data can come from anywhere and signs of a vulnerability can span any volume of data. This can translate to a massive “big data” problem where the need to keep tabs on large data volumes and heterogeneous data sources drive up costs when integrated with a traditional SIEM product, often as a result of the consumption-rate, volume-based pricing model. While there is definitive incentive to send more data to SIEM tools to maximize the benefits that these tools deliver, the more recklessly you collect and analyze data in SIEMs the more financially unviable they become. As a result, many organizations end up compromising on the data they collect. They leave out high-volume sources and hope that their SIEM operations would still be just as robust, forcing a difficult balancing act between cost and security.
Confluent augments your SIEM strategy
Confluent lets you maximize your investment in your preexisting SIEM infrastructure by helping you incorporate data from different sources for threat detection in real time. This exposes potential threats for analysis at different levels of granularity for multiple tools. By providing each SIEM tool with all of the data it needs for a comprehensive analysis, your security response team can focus their efforts on detecting threats and analyzing suspicious patterns instead of simply trying to get access to the data. Confluent also provides you with a powerful stream processing platform to let you nimbly detect threats in real time.
Augment your SIEM platforms with Confluent for a better cybersecurity posture
Confluent’s solution for SIEM optimization augments your cybersecurity platforms to break down silos and deliver contextually rich data to be more situationally aware. With a broad selection of connectors, our platform offers the solution to the fragmentation problem, allowing you to ingest real-time data streams from the relevant data sources, and write enriched streams to any sink. Stream processing within Confluent allows businesses to develop and deploy new threat detection rules to these data streams on the fly, improving operational agility. Plus, the overall lower TCO of Confluent can help expand the coverage of your SIEM tools while minimizing costs.
How to build a SIEM and observability pipeline with Apache Kafka® and Confluent
Confluent enables organizations to bridge the gap between old-school SIEM solutions and next-gen offerings by consolidating, categorizing, and enriching all data (such as logs, network data, telemetry and sensor data) and real-time events from relevant data sources for real-time monitoring, security forensics, and an enhanced cybersecurity posture. It serves as the curation fabric to ingest, aggregate, transform, filter, and clean a broad set of data streams, so that the plethora of analytic processors can consume just the right amount of data depending on the use case.
Our contemporary SIEM solution achieves the following goals:
- Enables organizations to move from batch to real time at scale by serving as the real-time data pipeline for SIEM data. This enables faster iteration and response.
- Stream processing from Confluent provides agility and incident detection by enriching event data in flight with additional context.
- Stream processing also enables threat detection in live streams of data that are too cost prohibitive to store and index in the SIEM, reducing data indexing, analysis and storage costs, and mitigating the trade-offs between cost and visibility.
- The increased flexibility offered by Confluent helps organizations improve the return on investment in the tools that work best for them.
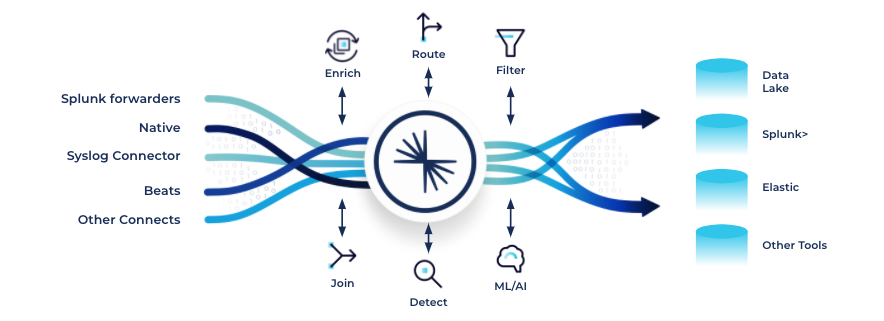
Confluent capabilities used for SIEM
Embed Sigma rules into your event streams with Confluent Sigma
There’s a gap between the analysis required by a security operations center (SOC) and generic real-time stream processing offered by Confluent out of the box. ksqlDB and Kafka Streams are highly capable but generic stream processing engines with no SIEM-specific logic baked in.
The Sigma project provides a robust language for describing patterns in network data designed to be used on any platform. Sigma is a generic and open signature format to describe relevant log events in a straightforward manner. As a domain specific language, Sigma provides a way of exchanging known threat detection patterns across and between organizations.
To bridge that gap, and at the behest of some of our customers, Confluent’s field team created the open source community project Confluent Sigma. Confluent Sigma natively understands Sigma rules and executes them using Kafka Streams, applying the rules to real-time streams of observability data in Kafka. Sigma rules themselves are published into Kafka and are picked up immediately by Confluent Sigma. This approach means that as new patterns are observed or existing ones are changed they will immediately take effect, minimizing response time.
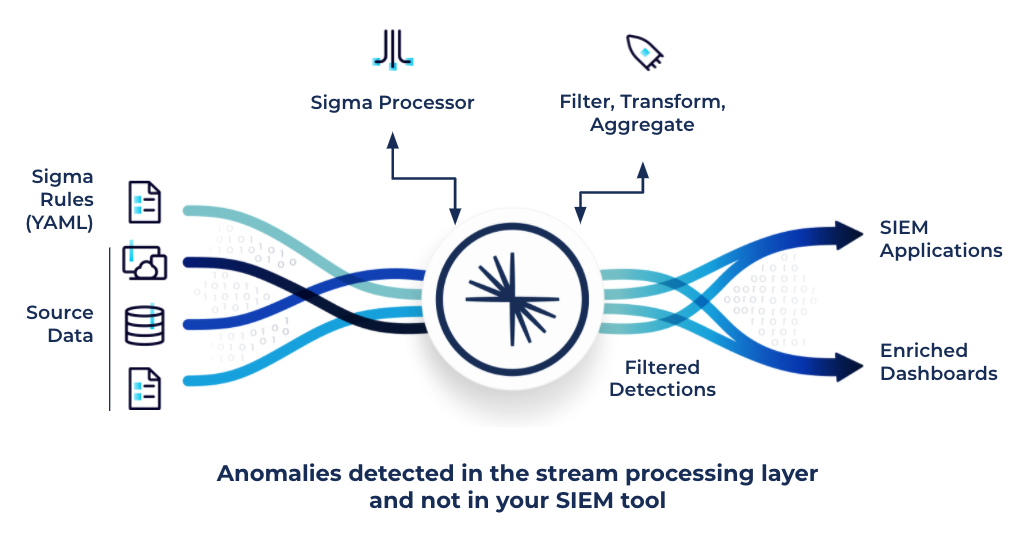
This presentation provides a detailed walk-through of Confluent’s applicability to SIEM, introduces Confluent Sigma, shows an end-to-end demo of it in action for real-time threat detection, and illustrates how you can bridge the gap between old-school SIEM solutions and a next-gen architecture.
You can also try this demonstration out yourself either in-browser using Gitpod or from Docker.
Let’s take a quick look at the example from the presentation on Confluent’s role in a cybersecurity use case in flagging suspicious activity in the DNS logs of the TCP replay.
Step 1: Connect your data to Confluent
The first thing you need to do is ensure you have your data sources connected to Confluent. For example, data can be sourced from Splunk, syslogs, and elsewhere. In the figures below (excerpted from the presentation), we ingest data from Splunk and syslog using our Splunk S2S and syslog connectors:
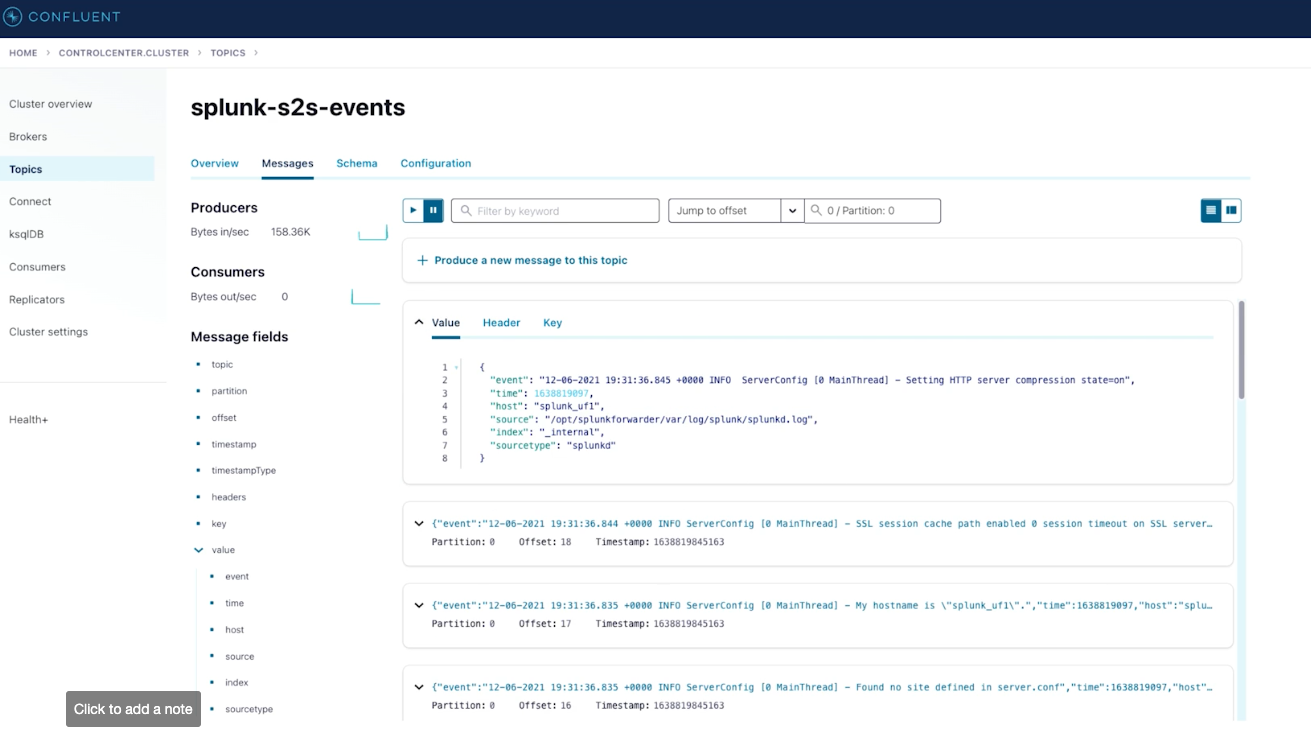
Data from Splunk S2S after ingestion by Confluent
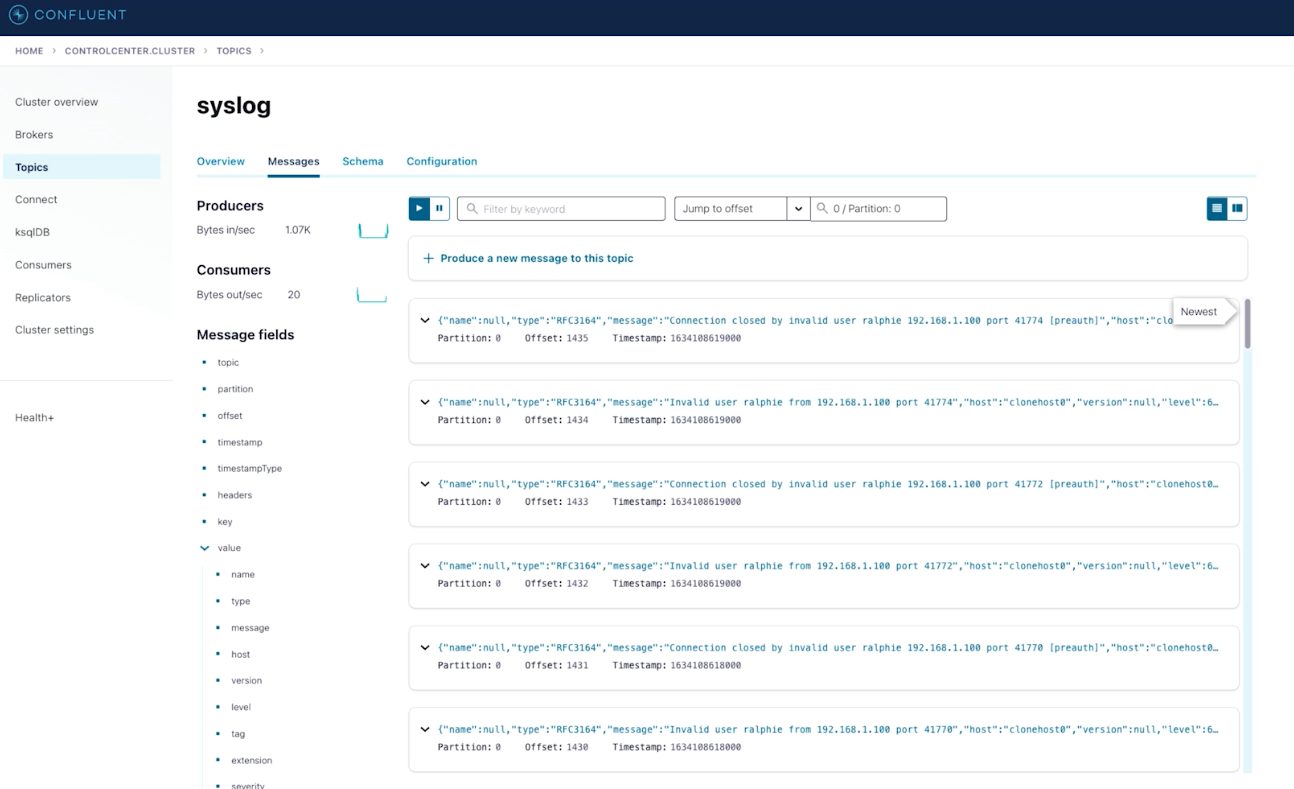
Syslog data as ingested by Confluent
Step 2: In-flight stream processing
These data streams from different and unrelated sources can be combined and processed together in flight using ksqlDB. This is shown below:
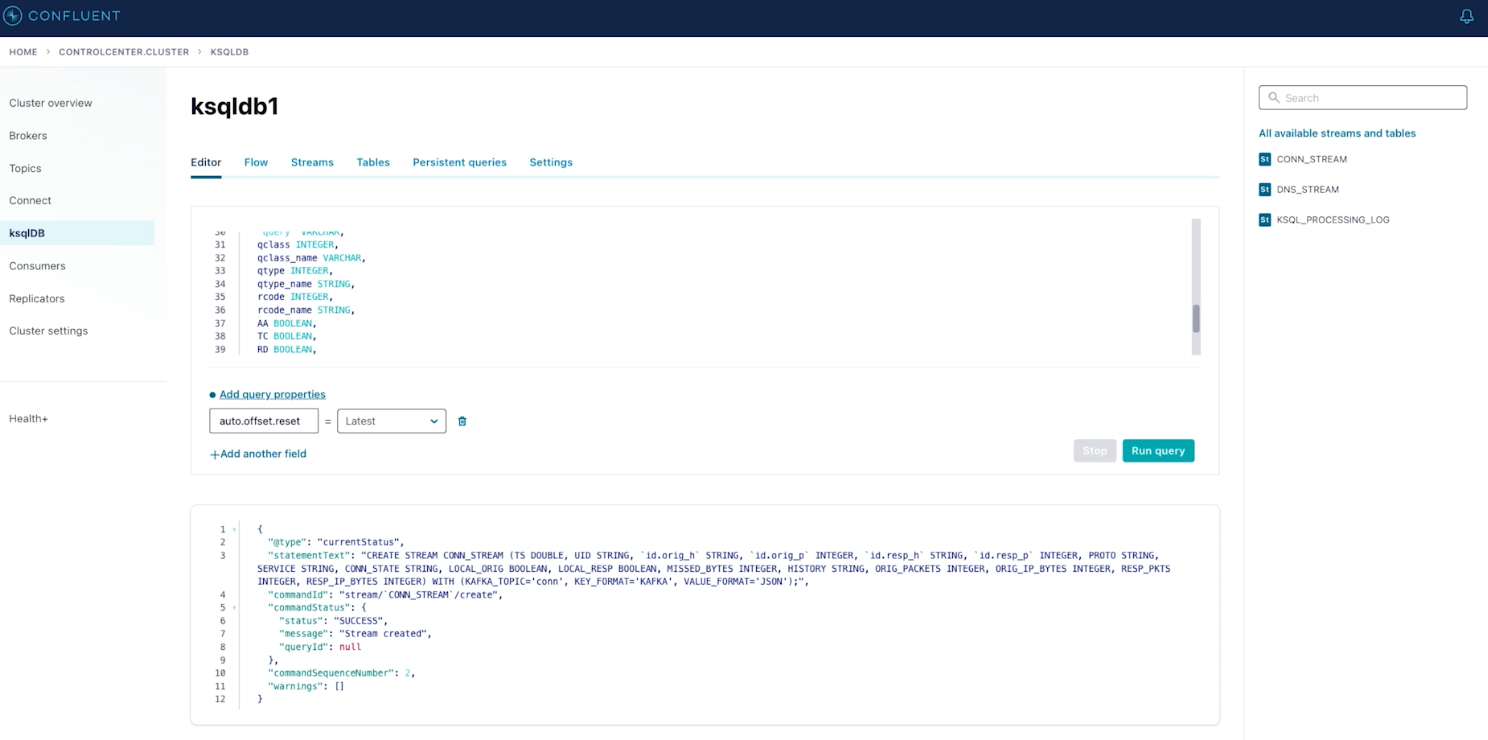
ksqlDB processing disparate streams together
Step 3: Design your Sigma rules
The project provides a basic UI to specify rules, although they can also be specified by CLI:
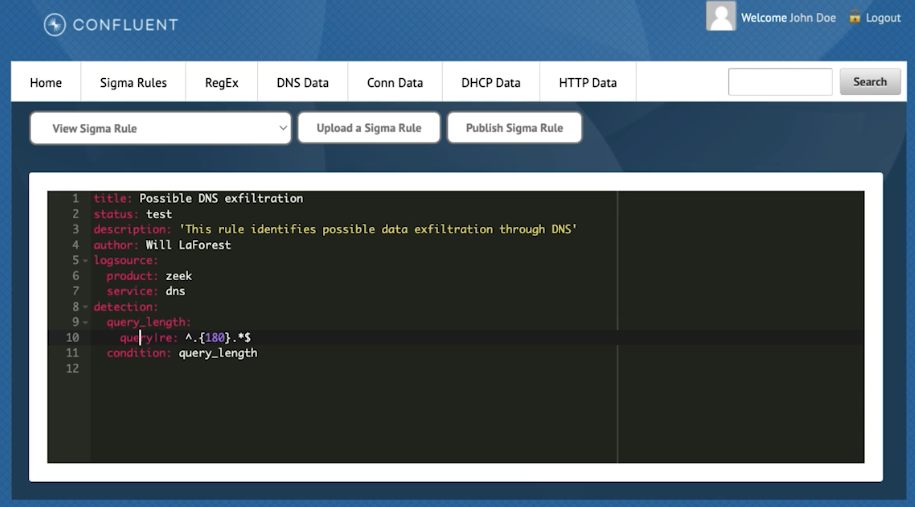
Confluent Sigma rule as seen through a viewer
In the example, Confluent Sigma is used to specify rules to flag suspicious activity in the DNS logs of the TCP replay. We tweak the sensitivity of the filter during the demo to show how we can nimbly iterate on development of the detection rules as the incident unfolds. Then the enriched and flagged data is surfaced in different levels of granularity to both Splunk and Elastic for analysis by different teams.
Step 4: Execute the rules
Sigma rules are published to a Kafka topic where they are parsed and executed by the stream processor. In this case we look at DNS query traffic for suspicious messages:
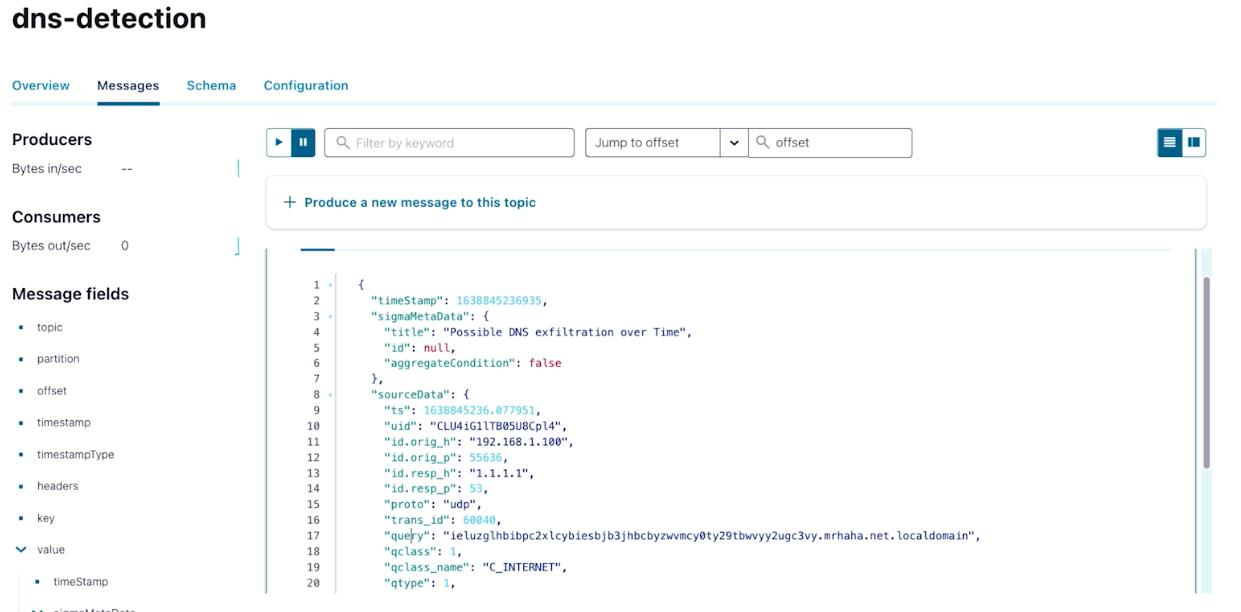
Executing a Confluent Sigma rule stored in a Kafka topic
ksqlDB is used again to flag specific data from Splunk for individual analysis in Elastic:
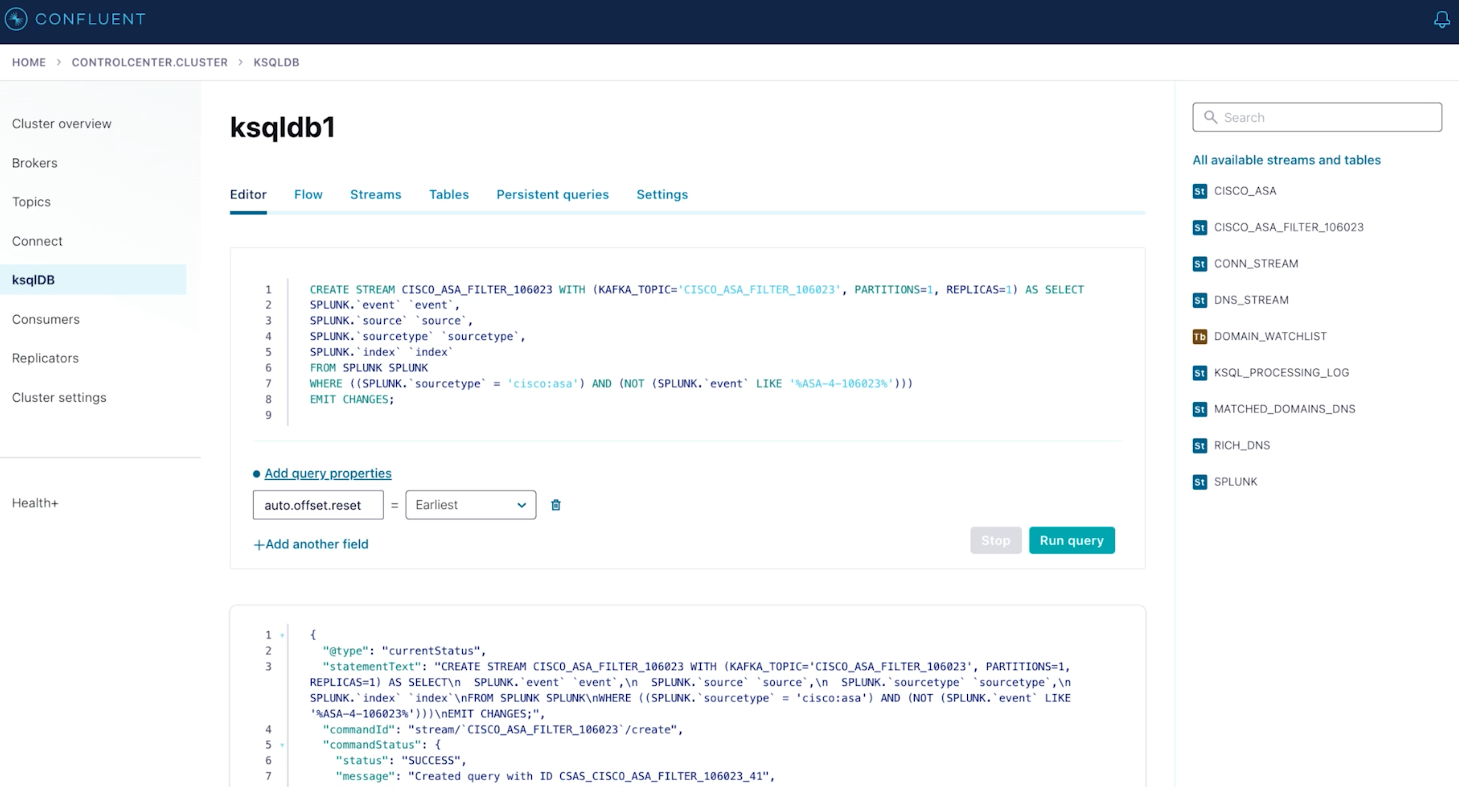
Selecting specific events from Splunk in ksqlDB for downstream analysis in Elastic
Sink connectors to Elastic and Splunk are used to export the flagged data as well as granular enriched network traffic data.
Here is the Splunk interface showing this data:
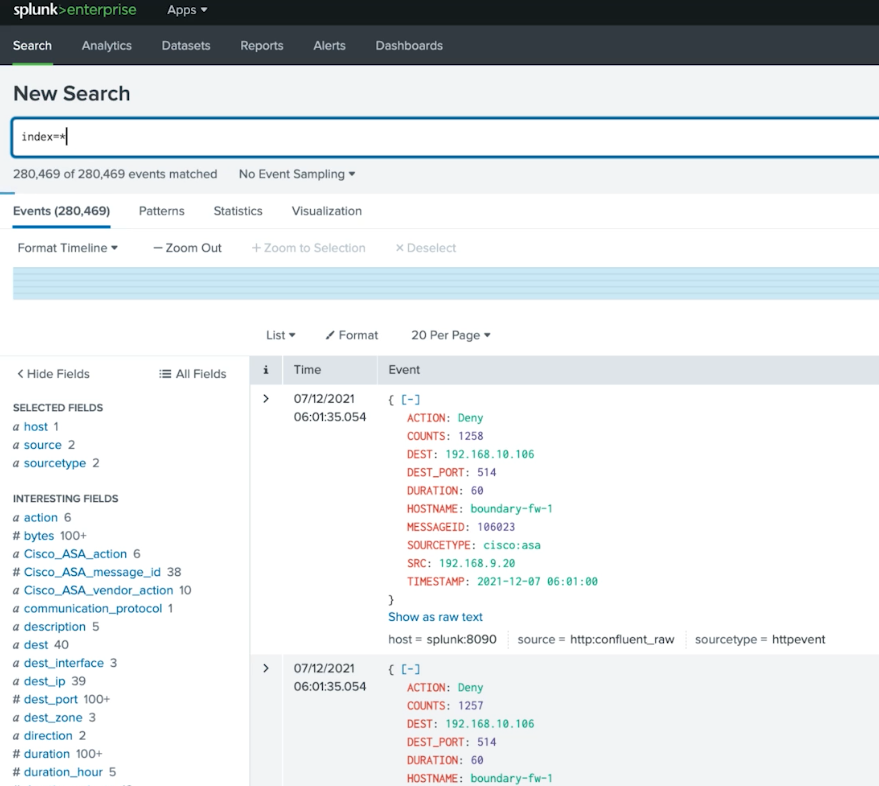
After data is synthesized in Confluent, it’s sent to Splunk
And Elastic:
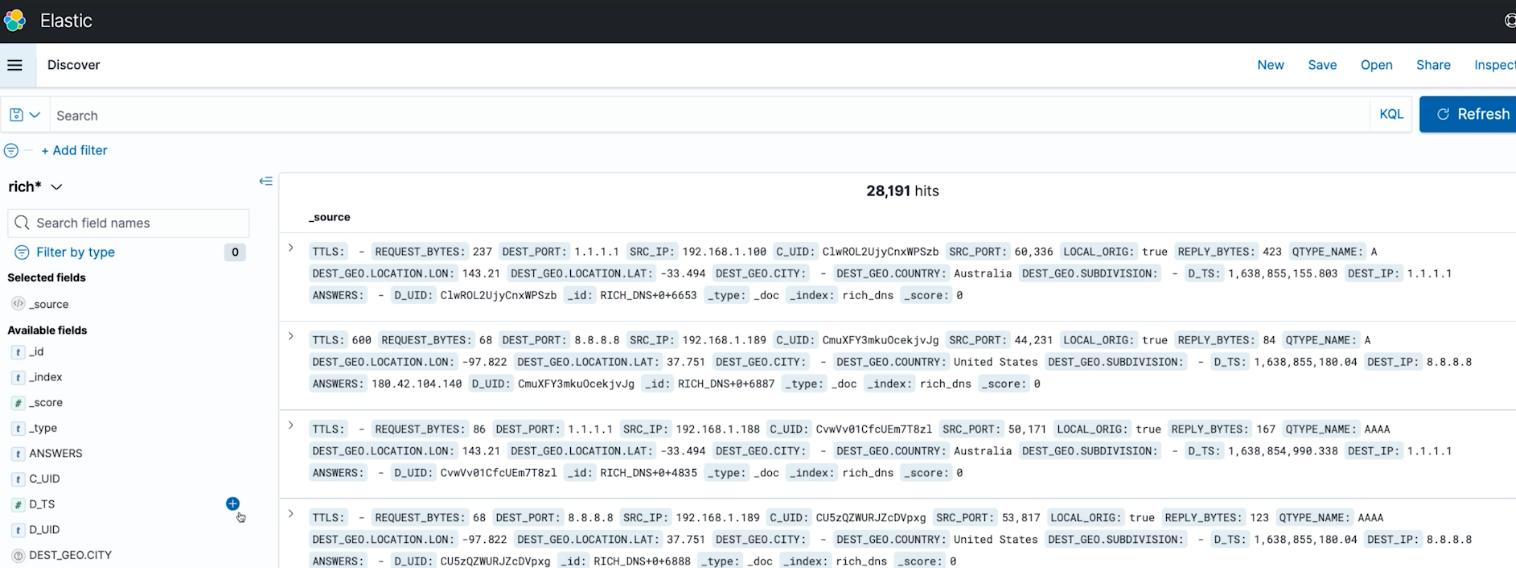
Similar data sent to Elastic for separate analysis
Confluent goes a long way toward solving the problems faced by users of SIEM tools today.
Confluent’s solution for SIEM enables fragmented tools to share data with each other using Kafka as the central nervous system, with the ability to scan and process the streaming data as it flows between them. None of the tools are displaced from what they do well, and new data sources and tools can be added as needed.
Unlike traditional SIEM tools which are rooted in batch architectures, Confluent can deliver and process event data as it is generated. Working with different time characteristics and late arriving data is table stakes for any stream processor, and Confluent is no exception. Confluent provides robust and complete stream processing natively through both Kafka Streams and ksqlDB.
Confluent can tap all data streams, sift through them, and present a distilled version to the SOC to improve incident response effectiveness.
Lastly, Confluent’s solution for SIEM can address these issues in a high volume, scalable, and cost-effective manner.
Learn more
There’s a lot that Confluent can do to help you optimize your SIEM platforms. So, here are links to some of our most-popular resources to help you get started:
- Watch this presentation video for an overview and demo on how to optimize your SIEM platforms.
- Run our SIEM demonstration in the browser using this Gitpod workspace with just a few clicks.
- See the demonstration on GitHub. It is fully Dockerized and has somewhat robust requirements. Since it includes 16 different Docker containers it’s probably too much for a laptop. We’ve tested it with good performance on a c4.4xlarge EC2 instance.
- Learn more at additional resources, including:
- The Confluent solution page on SIEM.
- Our datasheet on using Confluent to improve the nation’s cybersecurity stance in response to a recent executive order by the Biden administration.
- Intel’s Kafka Summit talk on building a scalable cyber intelligence platform.
- Robin Moffatt’s tutorial on detecting attacks with ksqlDB.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.