Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Introducing Stream Processing Use Case Recipes Powered by ksqlDB
From fraud detection and predictive analytics, to real-time customer experiences and cyber security, stream processing has countless benefits for use cases big and small. By unlocking the power of continuous data streams with real-time processing, we can now leverage data the second it happens. However, it can be tricky to get started, and there are an infinite number of use cases.
Today, we are excited to announce the launch of our new Stream Processing Use Case Recipes, powered by ksqlDB. ![]() Each recipe provides pre-built code samples and a step-by-step tutorial to tackle the most popular, high-impact use cases for stream processing, helping you move quickly from idea to proof-of-concept. Best of all, you can launch any of the recipes directly in Confluent Cloud in just a few minutes with a single click of a button!
Each recipe provides pre-built code samples and a step-by-step tutorial to tackle the most popular, high-impact use cases for stream processing, helping you move quickly from idea to proof-of-concept. Best of all, you can launch any of the recipes directly in Confluent Cloud in just a few minutes with a single click of a button!
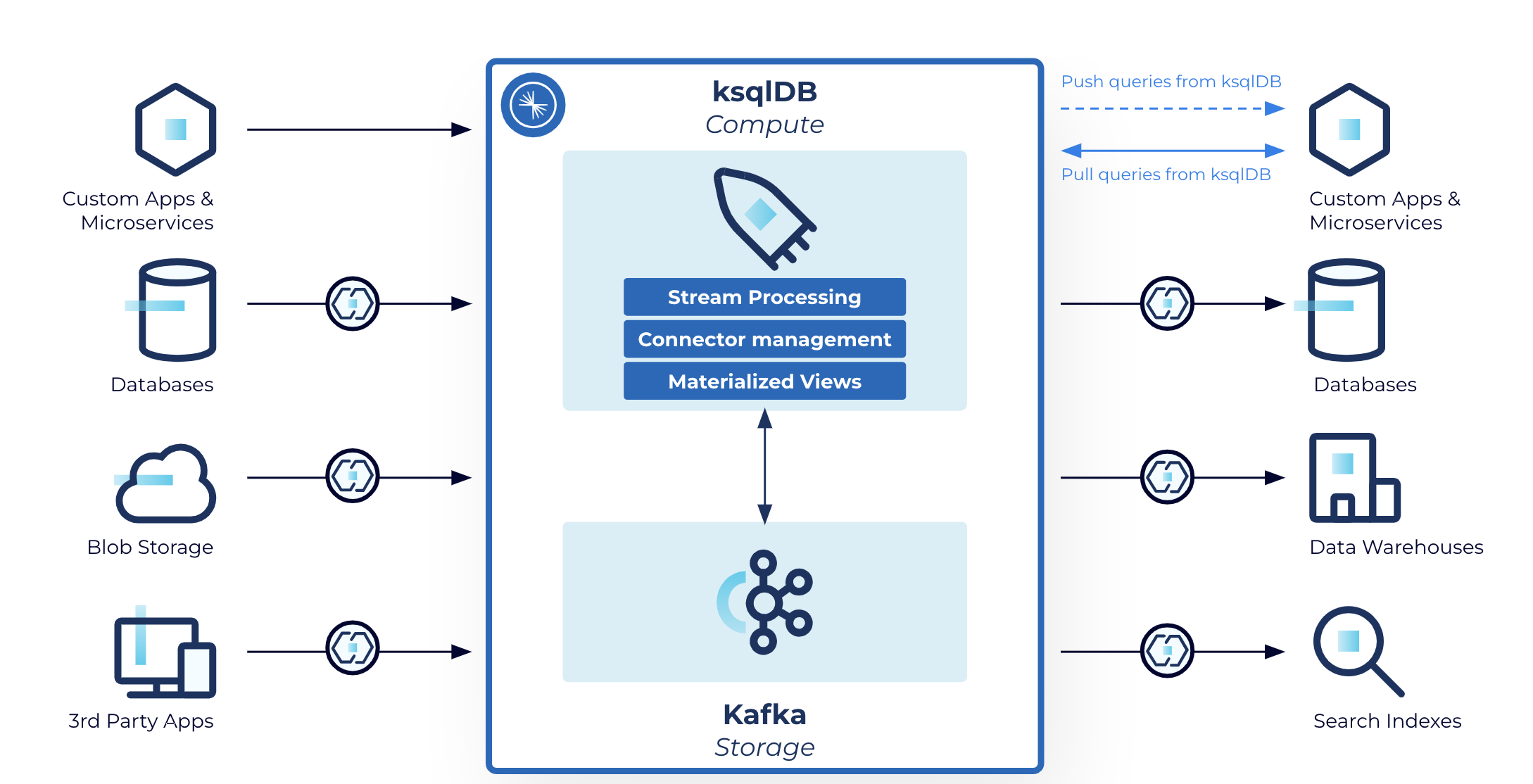
Challenges with stream processing
In our 7+ years of building data streaming technology, we’ve found teams face two common challenges when getting started with stream processing. First, stream processing is still a relatively new programming paradigm, so it can be difficult to truly grasp what types of use cases and workloads it enables. Many organizations have come to us asking for the specific problems others have solved using stream processing technologies like ksqlDB and Kafka Streams. Second, even once a team identifies a relevant use case for stream processing, it can still be tricky to implement. Stream processing is intrinsically different from traditional programming, and there are fewer examples to support the learning process than, say, for Python or machine learning.
Why did we put together these recipes?
The recipes provide the simplest solution to these problems. Developers have asked for a prescriptive approach to tackling these stream processing use cases, which is why we have packaged the most popular real-world use cases sourced from our customers and validated by our experts. Each recipe provides a self-contained snippet of SQL code that demonstrates a single use case end-to-end. To make it even easier, we have created a one-click button that will launch the script directly into your fully managed Confluent Cloud instance in just a few minutes.
Get started with stream processing use cases in 3 easy steps
Step 1: Sign up for a Confluent Cloud account. Getting started is easy. Sign up for a Confluent Cloud account, if you don’t have one already. New signups automatically receive $400 dollars off your spend during the first 60 days.
Step 2: Discover top use case recipes. Go to our Confluent Developer website to find our complete collection of stream processing recipes. Browse through and select the recipe most relevant to your business.

Our use case recipes focus on anomaly and pattern detection, customer 360, predictive analytics, real-time alerts and notifications, and more.
Step 3: Ready, set, launch. When you enter the page, you’ll be able to see the full walkthrough that details each recipe end-to-end. Click Launch which takes you directly into the product itself. A guide for the recipe will pop up and walk you through step-by-step what you need to do. Complete the guide, hook up your own data source(s), and integrate to the relevant sinks in your environment. It’s as simple as that—your very own stream processing app up and running in a matter of minutes!
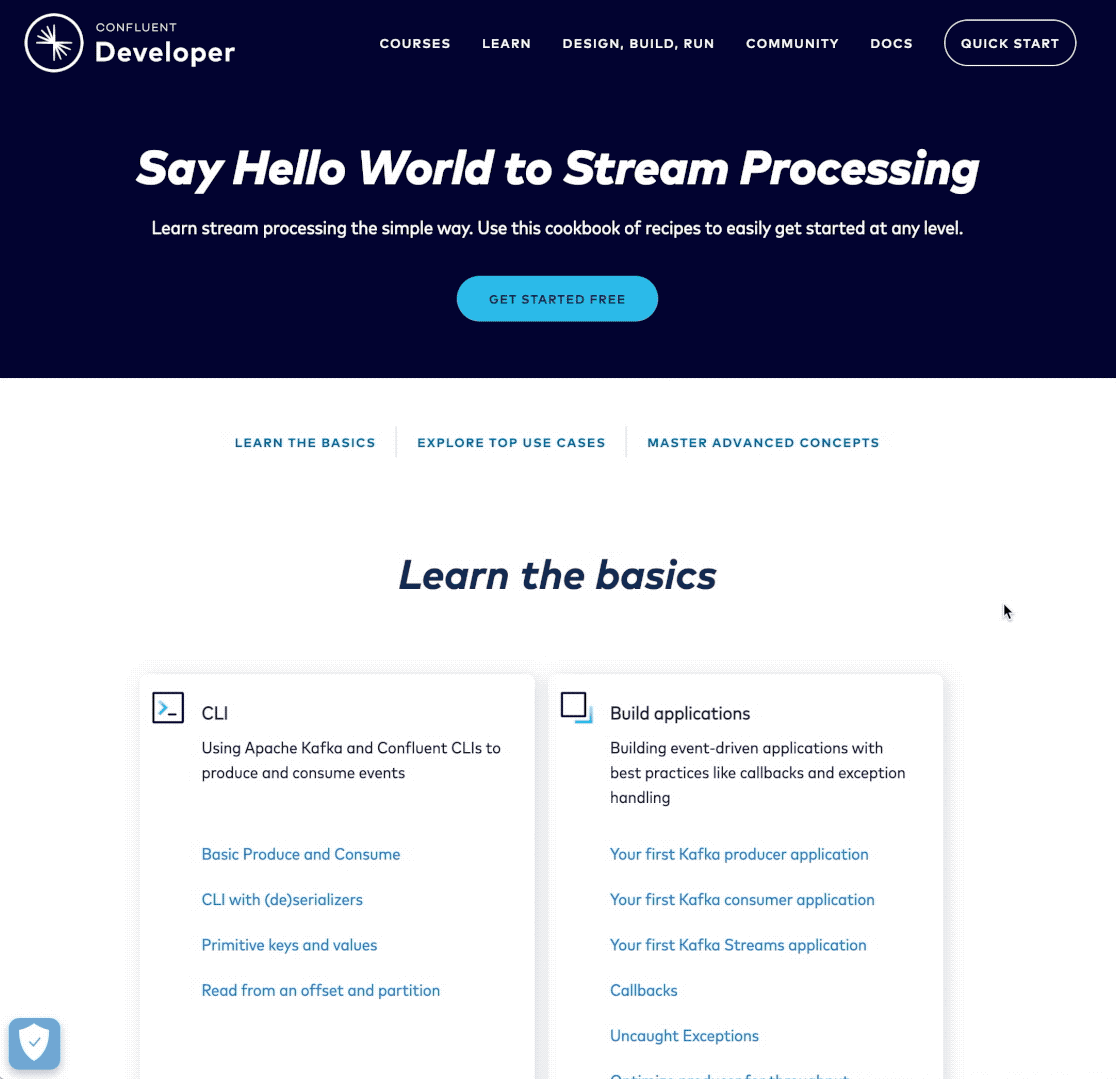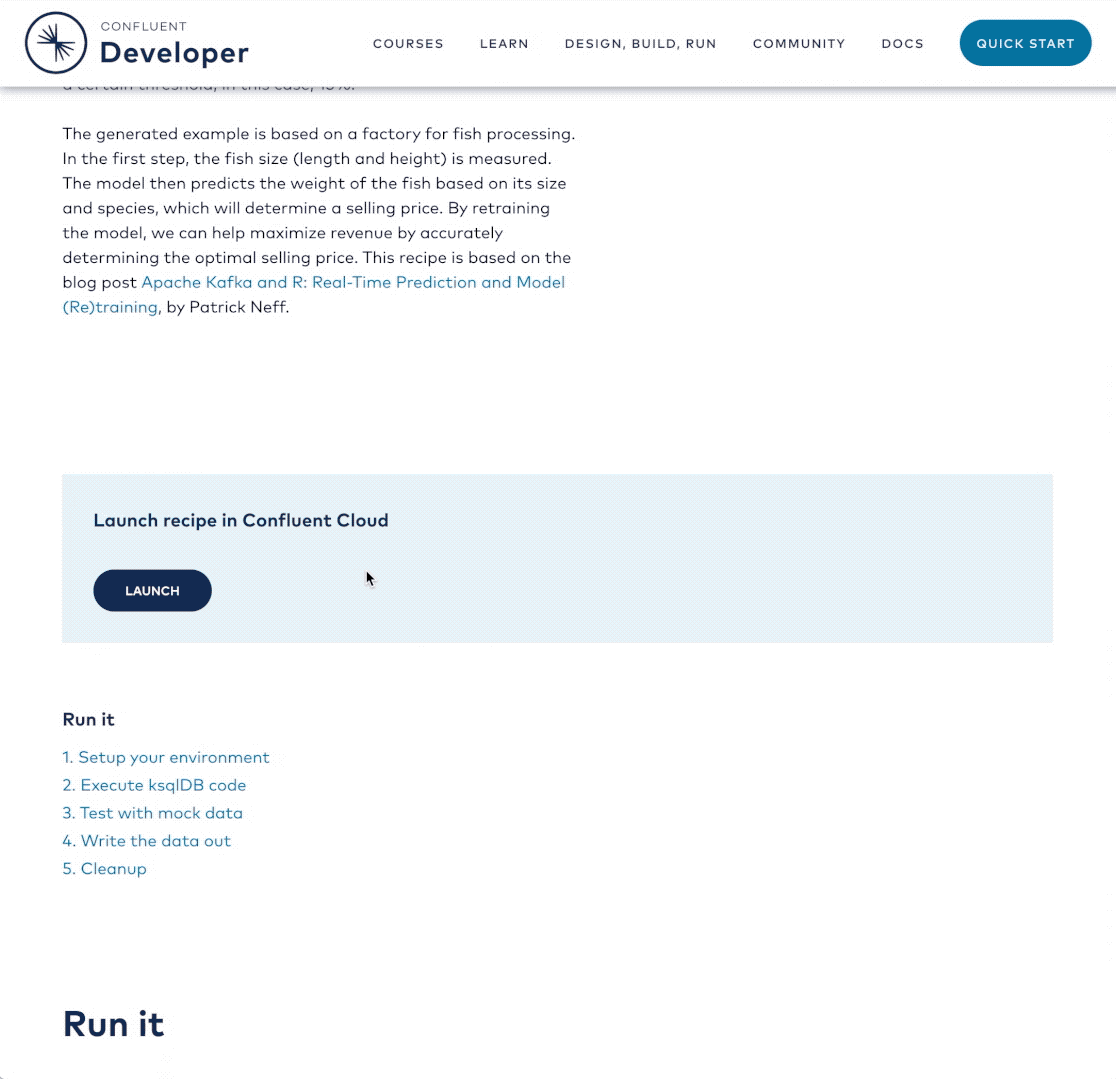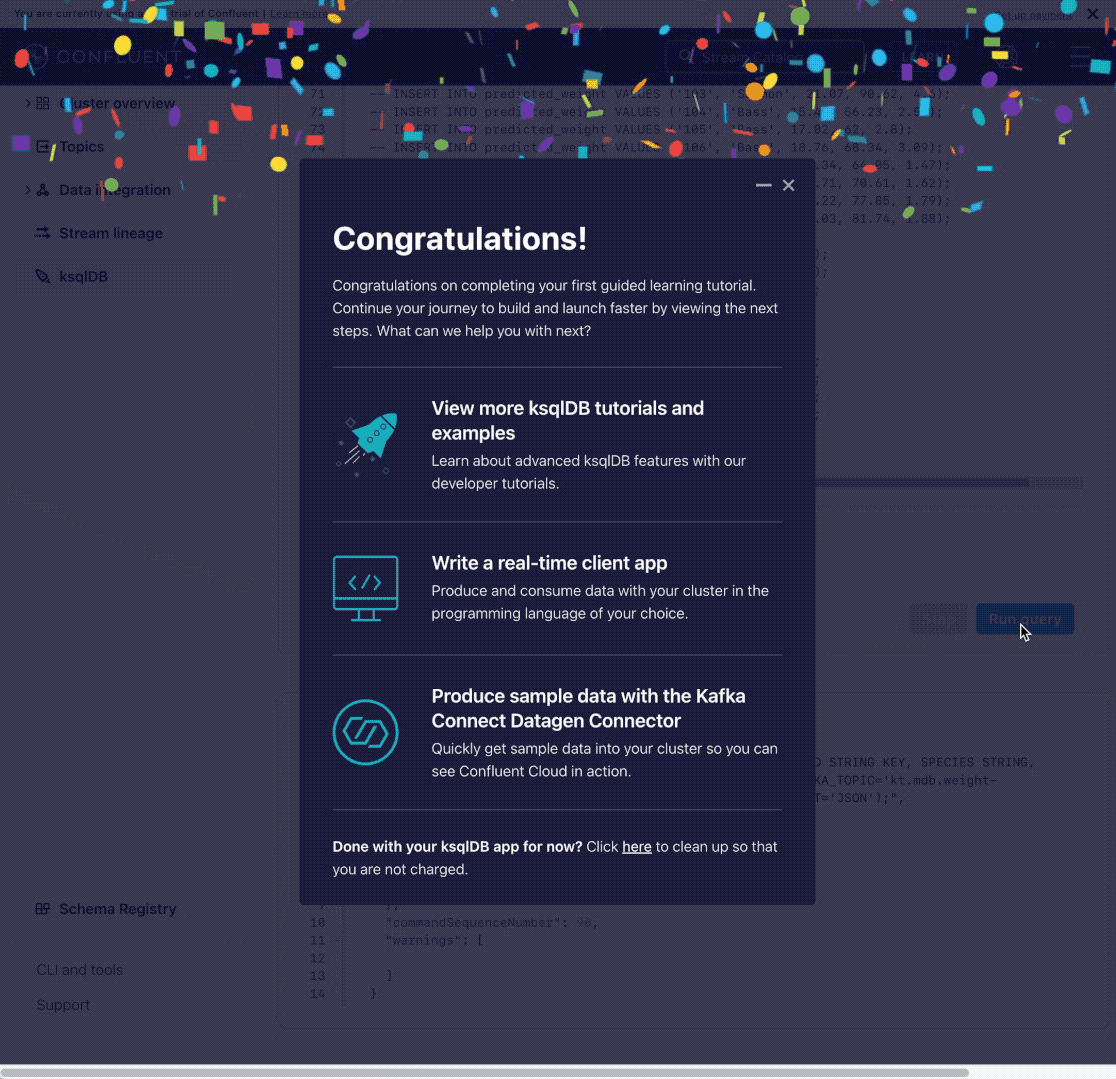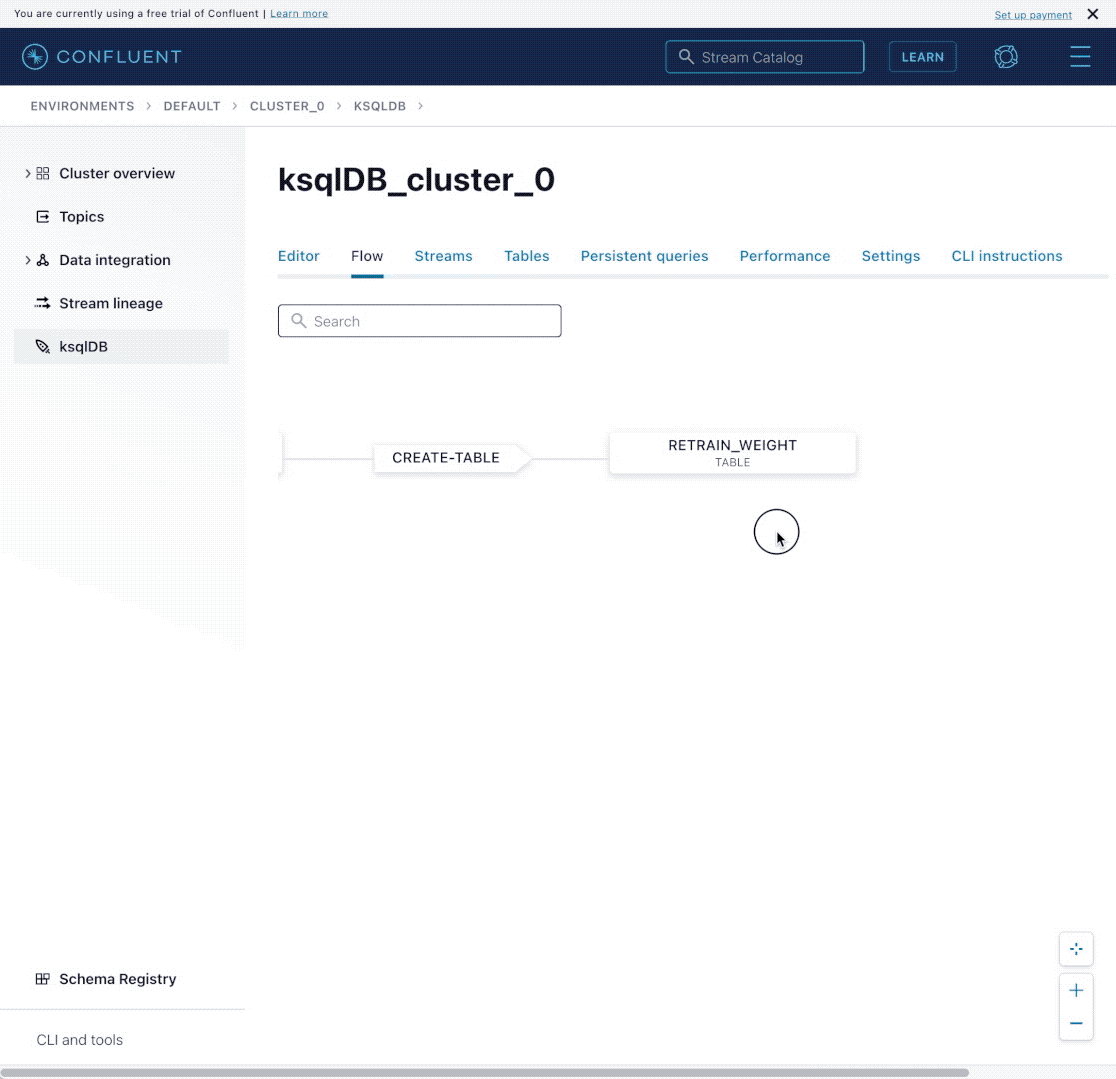
Voila, your first stream processing application is built! Just like that, your code is now running on a fully managed, cloud-native service.
Feel free to explore the complete collection of recipes we’ve launched, and we are just getting started. Our goal is to grow this collection of recipes over time to cover a diverse set of use cases, across any “cuisine” that may pique your interest. If you have a contribution, please send your submission through our intake form and someone on our team will reach out to you. We’d love to showcase your recipe across our entire stream processing community!
There’s no time to wait—sign into Confluent Cloud and start cooking! Even better, use the code TRYRECIPES150 to get an additional $150 dollars off, so you can try a recipe for free. This code is valid for 60 days upon claiming.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.