Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Introducing Confluent Platform 7.3
We are pleased to announce the release of Confluent Platform 7.3. This release accelerates mainframe modernization and unlocks data from legacy systems, increases efficiency while further simplifying management tasks for Apache Kafka® operators, and makes it easier for developers to build real-time applications.
Building on the innovative feature set delivered in previous releases, Confluent Platform 7.3 makes enhancements to three categories of features:
- Easily bridge legacy systems to the cloud with certified IBM MQ Premium Connectors for z/OS.
- Reduce TCO and operational burden with increased DevOps automation through Confluent for Kubernetes 2.5 and replica rack mixing for Multi-Region Clusters.
- Accelerate the development of stream processing pipelines with pause and resume functionality for persistent queries through ksqlDB 0.28.2.
This release blog post explores each of these enhancements in detail, taking a deeper dive into the major feature updates and benefits. As with previous Confluent Platform releases, you can always find more details about the features in the release notes.
Keep reading to get an overview of what’s included in Confluent Platform 7.3, or download Confluent Platform now if you’re ready to get started.
Download Confluent Platform 7.3
Confluent Platform 7.3 at a glance
Confluent Platform 7.3 comes with several enhancements to existing features, bringing more of the cloud-native experience of Confluent Cloud to your self-managed environments, enabling data streaming everywhere, and bolstering the platform with a complete feature set to implement mission-critical use cases end to end. Here are some highlights:
Confluent for Kubernetes 2.5 for simplified cluster ops
Confluent for Kubernetes (CFK) provides a complete, declarative API to deploy and operate Confluent as a cloud-native system on Kubernetes. It extends the Kubernetes API to provide you with first-class resources to manage all Confluent Platform components. You can also leverage Kubernetes-native resource management, such as Kubernetes labels and annotations to provide useful context to DevOps teams and ecosystem tooling, as well as tolerations and Pod/node affinity support for efficient resource utilization and Pod placement.
Previously, if you wanted to make changes to Kubernetes Pod functionality for custom deployments, such as how Pods are created, scheduled, and managed, you would have to modify the underlying Pod template in the CFK API (<component>.spec.PodTemplate). This would entail waiting for the CFK API to add first-class support before using new Kubernetes functionality, make the API harder to maintain, and require bespoke templating that is operationally challenging.
In the latest release, Confluent for Kubernetes adds functionality to use overlays for Pod resources to support new Kubernetes capabilities. By using overlays, you can use new Kubernetes functionality without waiting for the CFK API to add a variant configuration. Users can provide a complete overlay to configure the Pod template, which enables customizations like configuring custom init containers (specialized containers that run before app containers in a Pod) and other Kubernetes Pod functionality such as a custom scheduler. This provides greater flexibility to the user, while future-proofing the CFK API and making it easier to maintain.
apiVersion: v1
kind: ConfigMap
metadata:
name: foo-pod-overlay
namespace: operator
data:
pod-template.yaml: |
spec:
template:
spec:
initContainers:
- name: nginx
image: nginx:1.12.2
imagePullPolicy: IfNotPresent
Configuring PodTemplate using a Pod overlay
Certified IBM MQ source and sink Premium Connectors for z/OS
From order processing to financial transactions, inventory control to payroll, IBM mainframes running z/OS remain a widely used enterprise computing workhorse, still performing the majority of batch processing for many enterprises. Many of these companies are currently undergoing architecture modernization including cloud migration, moving from monolithic applications to microservices, and embracing open systems. Enterprises need real-time data streaming access to the mainframe to unlock access to siloed data, improve operational efficiencies, and drive cloud adoption for mission-critical business applications without incurring the complexity and expense that comes with sending ongoing queries to mainframe databases.
Currently, there's no way to easily offload mainframe data into the cloud for real-time data streaming use cases. Replicating the data to Kafka and building your own IBM MQ connector requires taking on significant operational burden, risk, and engineering months of writing custom code.
In order to address this need, Confluent Platform 7.3 enables the use of the Connect framework on z/OS by offering a certified Connect worker and certified IBM MQ source and sink Premium Connectors. This allows you to deliver and transform complex mainframe data and make it usable in modern cloud data platforms, such as Snowflake, Elastic, and MongoDB. Our expert-certified connectors help you save ~12-24+ engineering months of designing, building, testing, and maintaining highly complex integrations and are fully supported by our in-house team of experts. Moreover, because the connectors are written in Java, they are eligible to run on IBM's z Integrated Information Processors (zIIPs), resulting in lower MIPS cost for a reduced TCO.
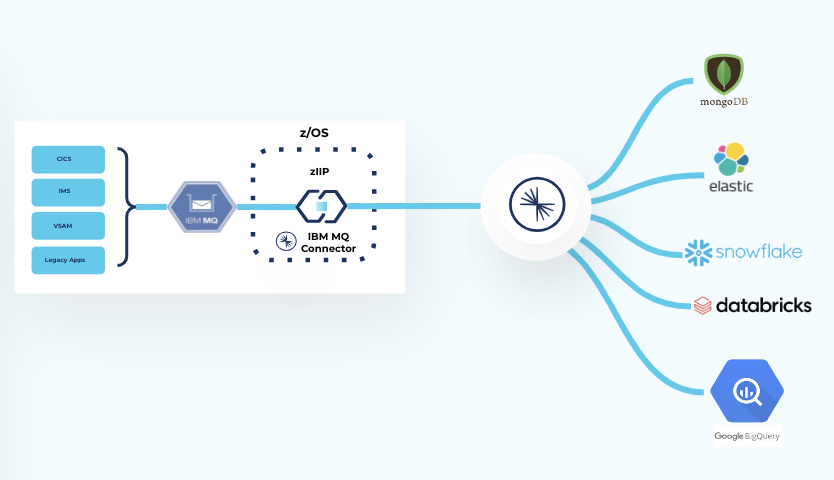
Bridging mainframe data to the cloud using Confluent’s certified IBM MQ connector
To get started running Connect on z/OS, you can download the Connect worker .tar file and manually run the worker node along with the certified IBM MQ source and sink Premium Connectors on it. To stay up to date, you can download newer versions of the .tar file from our website and migrate from the previous version.
ksqlDB 0.28.2 to accelerate streaming processing development
Confluent Platform 7.3 also comes with ksqlDB 0.28.2, which includes several new enhancements that improve developer velocity and make it easier to build streaming data pipelines.
Now that Kafka Streams supports pausing and resuming running topologies (more on that below), the same functionality has been uplifted into ksqlDB syntax, allowing you to pause and resume persistent queries. There are a number of reasons why you might want to temporarily pause a query:
- Reduce resource consumption when processing is not required
- Modify downstream parts of a data pipeline
- Respond to operational issues
Previously, to stop processing you had to bring down the entire application and then bring it back up again, which was potentially disruptive. Now, you can stop processing events and the application will remain up and you can resume processing far more efficiently.
The syntax to use this functionality is similar to the TERMINATE command (which stops a query completely). Note that the query ID is the argument passed to PAUSE/RESUME, not the query name:
-- Create a persistent query CREATE STREAM my_pq AS SELECT x, y, UCASE(z) FROM my_stream EMIT CHANGES;
-- Obtain the persistent query’s query ID: DESCRIBE my_pq;
The query ID is the argument passed to PAUSE/RESUME, not the query name
Pausing a single persistent query will stop processing events for the duration that it's paused. You can then resume it whenever you'd like to pick up where it left off without dropping any events.
You can also pause and resume all persistent queries in a workload at once in one command. This can be really useful if you just want to stop everything without having to run a bunch of individual commands, especially if the workload has many persistent queries.
PAUSE CSAS_MY_PQ_10; -- Now resume processing: RESUME CSAS_MY_PQ_10;
-- We can also pause/resume all persistent queries at once: PAUSE ALL; RESUME ALL;
Use the ALL command to act on all queries at once
There are a number of additional enhancements that are part of ksqlDB 0.28.2 that you can read about in the ksqlDB 0.28.2 release blog post:
- Wildcard Struct references
- PROTOBUF_NOSR serialization format
Replica rack mixing for Multi-Region Clusters
In Confluent Platform 6.1, we introduced Automatic Observer Promotion for Multi-Region Clusters to automate the process of failing over to a newly promoted "observer" replica in case a main datacenter goes offline, minimizing the risk of downtime and its associated costs to the business. Operators no longer had to manually intervene or spend engineering months building complex failover logic, thereby reducing operational burden and improving Kafka reliability.
A simple JSON file configures replica placement to specify the racks that sync replicas (replicas that are not observers and can be part of the in-sync replica list) and observers should be placed on. Previously, you could not place observers and sync replicas on the same rack within a JSON replica constraint. This required you to stand up dedicated servers just for the observers, which is not an efficient use of resources and could require running extra nodes to satisfy your business’ performance requirements.
In Confluent Platform 7.3, you can do Automatic Observer Promotion without needing to split datacenters into arbitrary “replica” and “observer” racks. Sync replicas and async observers can be placed on the same rack within the same JSON replica constraint. This offers a number of advantages:
- More efficient resource utilization by mixing replicas on the same rack, reducing infrastructure costs
- Intuitive and better user experience by having one straightforward replica placement JSON file
- Better performance by balancing leaders and transaction coordinators across all nodes in a datacenter automatically without manual intervention
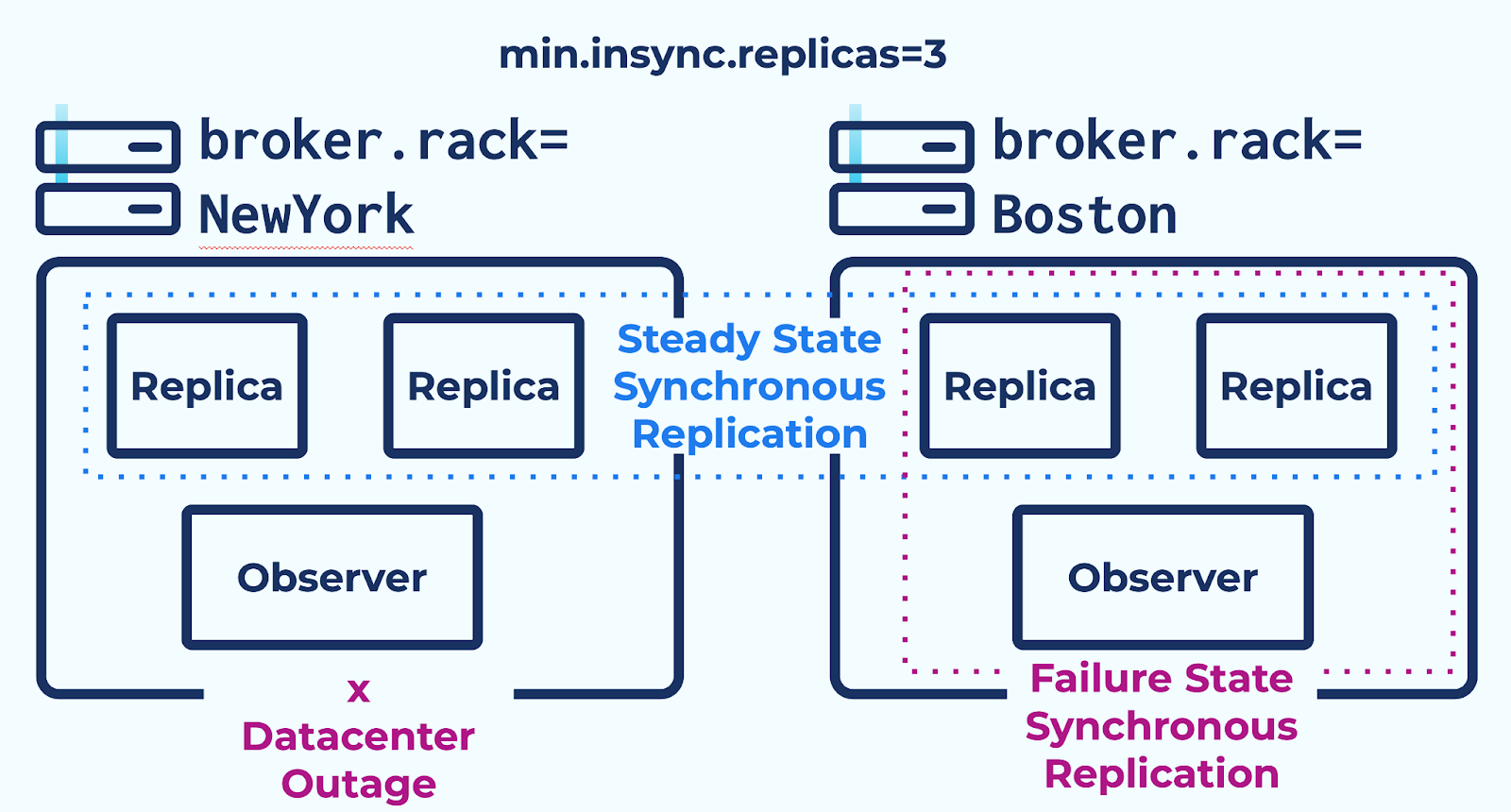
Sync replicas and observers are mixed on the same rack
Built on Apache Kafka 3.3
Confluent Platform 7.3 is built on the most recent version of Apache Kafka, in this case, version 3.3. For more details about Apache Kafka 3.3, please read the blog post by Jose Armando Garcia Sancio or check out the video by Danica Fine below.
Get started today
Download Confluent Platform 7.3 today to get started with the only cloud-native and complete platform for data in motion, built by the original creators of Apache Kafka.
The preceding outlines our general product direction and is not a commitment to deliver any material, code, or functionality. The development, release, timing, and pricing of any features or functionality described may change. Customers should make their purchase decisions based upon services, features, and functions that are currently available.
Confluent and associated marks are trademarks or registered trademarks of Confluent, Inc.
Apache® and Apache Kafka® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by the use of these marks. All other trademarks are the property of their respective owners.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Announcing ksqlDB 0.28.2 and Improvements to ksqlDB in Confluent Cloud
We are excited to announce the ksqlDB 0.28.2 release as well as new cloud-specific improvements! This release simplifies the getting started experience, helps to run and monitor critical pipelines



Introducing Confluent for Kubernetes
We are excited to announce that Confluent for Kubernetes is generally available! Today, we are enabling our customers to realize many of the benefits of our cloud service with the […]