Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Providing Timely, Reliable, and Consistent Travel Information to Millions of Deutsche Bahn Passengers with Apache Kafka and Confluent Platform
Every day, about 5.7 million rail passengers rely on Deutsche Bahn (DB) to get to their destination. Virtually every one of these passengers needs access to vital trip information, including departure and arrival times, their train’s assigned platform, where to queue when waiting for a train, and more. If any of the information shown in the station’s displays does not match what is in the DB Navigator mobile app and on the website, it can lead to confusion among our passengers.
With this in mind, we set a goal of providing our customers with up-to-date, accurate, and consistent information at all times and in all locations. To achieve this goal, we created a new system, RI-Plattform (Passenger Information Application), which acts as a single source of truth, feeding all of the information channels throughout Deutsche Bahn in the near future. We needed a partner to help us get RI-Plattform up and running with maximum reliability. We decided to work with Confluent on this project.
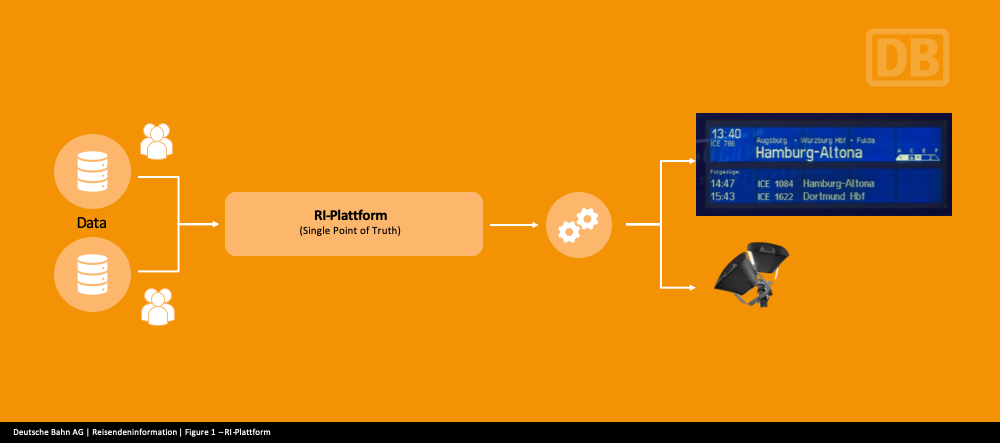
First steps in developing a modern passenger information system based on event streaming
On a daily basis, in addition to serving more than 5.7 million customers, Deutsche Bahn manages approximately 24,000 trains per day. This results in about 180 million events that the new system RI-Plattform has to process within 24 hours.
When we began envisioning a system that could reliably ingest data, process it, and then deliver it to both customers and Deutsche Bahn employees, we evaluated several potential solutions. First, we decided to try a combination of Apache Kafka® and Apache Storm™. We soon discovered that, in our environment at least, Storm was fairly complicated to deploy, to operate, and to build applications with. We also suspected that the configuration we had settled on for Kafka on Amazon Web Services (AWS) was not optimal.
To address these issues, we looked into using Kafka Streams instead of Storm, and found that Kafka Streams improved our development lifecycle and reduced the complexity of our environment. In addition, Kafka Streams made it much easier for us to implement some of the smaller use cases with the domain-specific language (DSL), while also giving us the ability to tackle much more sophisticated use cases with the Processor API.
With Kafka Streams, we were also able to significantly reduce the time required for the platform announcement service to process the daily schedule import. We achieved this through the use of local state stores. Instead of sending requests to a remote database, processing is now entirely performed locally. This has improved the processing time by 90% from 20 minutes to just two minutes. This has shown us that Kafka Streams, in conjunction with local state stores, is a promising approach that we want to apply to more microservices in the future.
Another big step forward was bringing in Confluent Platform, and with it the support of Confluent engineers. We discussed our requirements and set up a Kafka configuration together that was much more reliable. We had changed many of the default settings during the evaluation of Apache Kafka. One of the lessons learned here is that the defaults values really are right for most situations. Fortunately, we are now in a situation where we are supported by Confluent in case adjustments are required.
Our development, testing, and deployment workflow
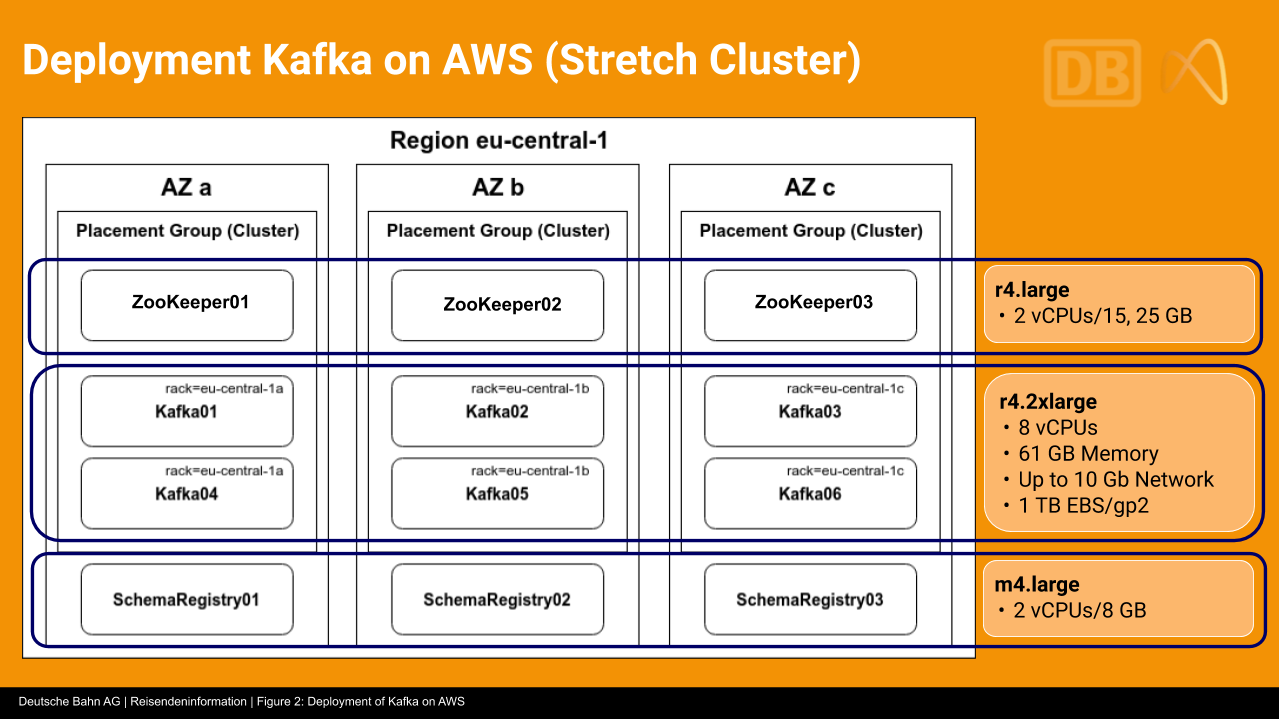
The development group for RI-Plattform consists of 110 people organized into 13 scrum teams. The technology stack for the platform includes Apache Kafka, Apache Cassandra™, and Kubernetes (K8s) running on AWS across three availability zones. Our teams have developed around 100 microservices that use Confluent Platform as the event streaming platform to communicate with one another and access the 180 million events generated and processed on the platform each day.
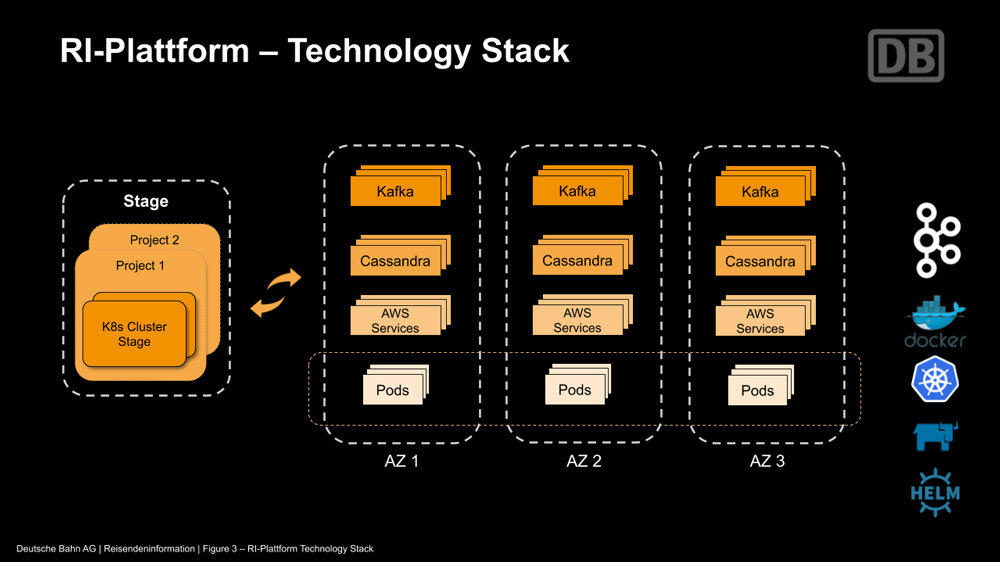
We have developed our own test framework with approximately 3 million test cases. Our teams use this framework when they want to deploy to production. Currently, we are deploying between four to eight times a day using a continuous integration/continuous deployment workflow. In order to establish short issue response times and a reliable operation, we have adopted a “you build it, you run it” DevOps approach.
Accelerating deployments and new feature deliveries
One of the key advantages of building RI-Plattform atop Confluent Platform is the speed at which we can deliver new capabilities. Depending on the business case, we persist the required events in Kafka with the necessary retention times. When we create a new microservice, it is instantly operative, reading all the data persisted in Kafka and immediately processing new information.
Our new event streaming architecture has made it easier to take advantage of additional information sources. For example, we developed a microservice that uses sensor data from the station platforms to detect the arrival of a train. It then triggers the announcement over the station’s loudspeakers.
This is also an example of a use case for which low-latency event streaming is very important. Already short delays in the delivery of events will have an impact on the accuracy of the time tables and announcements at the passenger platform. During normal operations, Kafka satisfies these requirements; however, during deployments of Kafka Streams applications, the rebalancing is causing a stop-the-world effect for a short moment of time. To reduce the impact of a rebalance, we are looking forward to evaluating the new Static Membership group management protocol released with Kafka 2.3.0.
99.9% availability and a look at what’s to come
As part of a pilot phase at 80 stations across Germany, we have been in production with RI-Plattform for a little more than a year now. Kafka and Confluent Platform had been remarkably reliable, supporting us to achieve 99.9% availability from the moment it went live. We had less than seven hours of outage in the first year, and that was for only part of the system, not the whole application. In our experience, it is not easy to achieve that level of reliability right from the start.
Currently the system is handling only intercity travel, but we have plans to add intracity travel as well, at which point our Kafka deployment will be handling approximately 20 times its current load.
We are also looking into using ksqlDB and into the possibility of using Confluent Cloud instead of operating Kafka ourselves. For now though, we are taking one step at a time, as we continue to add new features to RI-Plattform.
Software architects and developers don’t always get to see the effect that their work has on the public. However, we do, and that’s why the work we have done on RI-Plattform is a source of pride. It is not only one of the most complex projects we’ve ever been involved with; it is also improving the day-to-day travel experience of millions of travelers across Germany.
Interested in more?
To get started with event streaming, you can also download the Confluent Platform and try it out for yourself free for 30 days.





