Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Confluent Platform Now Supports Protobuf, JSON Schema, and Custom Formats
When Confluent Schema Registry was first introduced, Apache Avro™ was initially chosen as the default format. While Avro has worked well for many users, over the years, we’ve received many requests for Schema Registry to support alternative formats. The two most requested formats have undoubtedly been Protocol Buffers (Protobuf) and JSON Schema. Now with the release of Confluent Platform 5.5, we’ve added comprehensive support for Protobuf and JSON Schema not only to Schema Registry but throughout the Confluent Platform. Furthermore, Schema Registry has been made extensible when it comes to new formats, and now users can even start adding their own custom formats to Schema Registry.
Protobuf and JSON schema everywhere
The new Protobuf and JSON Schema formats are supported in Schema Registry in addition to all other components of Confluent Platform 5.5.
Confluent Schema Registry
Confluent Schema Registry can now support multiple formats at the same time. That means you can have Avro schemas in one subject and Protobuf schemas in another. Furthermore, both Protobuf and JSON Schema have their own compatibility rules, so you can have your Protobuf schemas evolve in a backward-compatible or forward-compatible manner, just as with Avro today.
Schema Registry also adds the notion of schema references, which models the import statement of Protobuf.
Apache Kafka® serializers and deserializers
New serializers and deserializers are available for Protobuf and JSON Schema. The serializers can automatically register schemas when serializing a Protobuf message or a JSON-serializable object. In the case of the Protobuf serializer, it will even register all imported schemas, recursively.
The deserializers can be configured to return instances of either specific types or generic types (DynamicMessage for Protobuf and JsonNode for JSON Schema). With the proper configuration, they will even work with specific types in order to store multiple event types in the same Kafka topic.
The serializers and deserializers are available in multiple languages, including Java, .NET, and Python, with more to come.
Additionally, command line tools are available that wrap the serializers and deserializers. So getting started with Protobuf is as easy as:
bin/kafka-protobuf-console-producer --broker-list localhost:9092 --topic mytopic1 --property value.schema='message Foo { required string f1 = 1; }'
Or for JSON Schema:
bin/kafka-json-schema-console-producer --broker-list localhost:9092 --topic mytopic2 --property value.schema='{"type":"object","properties":{"f1":{"type":"string"}}}'
Alternatively, you can use the Confluent CLI as follows:
confluent local produce mytopic1 -- --value-format protobuf --property value.schema='syntax = "proto3"; message MyRecord { string f1 = 1; }'
Or for JSON Schema:
confluent local produce mytopic2 -- --value-format json --property value.schema='{"type":"object","properties":{"f1":{"type":"string"}}}'
Kafka Connect
New Kafka Connect converters have been added for Protobuf and JSON Schema. These allow conversions to and from Kafka Connect schemas. They also support conversions involving enums and unions in Protobuf and JSON Schema.
Confluent REST Proxy
Confluent REST Proxy has been extended with support for Protobuf and JSON Schema. Since Avro, Protobuf, and JSON Schema all have JSON representations for their payloads, a client can simply use JSON with the REST Proxy in order to interoperate with the different formats.
Kafka Streams
New serialization/deserialization classes (SerDes) have been added for use with Kafka Streams. These SerDes allow you to easily work with Protobuf messages or JSON-serializable objects when constructing complex event streaming topologies.
ksqlDB
Users of ksqlDB can now specify either VALUE_FORMAT='PROTOBUF' or VALUE_FORMAT='JSON_SR' in order to work with topics that contain messages in Protobuf or JSON Schema format, respectively. Creating a ksqlDB table using Protobuf is as easy as:
CREATE TABLE users
WITH (KAFKA_TOPIC='users-protobuf-topic',
VALUE_FORMAT='PROTOBUF',
KEY='userid');
Confluent Schema Validation
Confluent Schema Validation, introduced in Confluent Platform 5.4, also works with schemas of the newly supported formats, so that schema validation is enforced at the broker for any message that is in Avro, Protobuf, or JSON Schema format.
Confluent Control Center
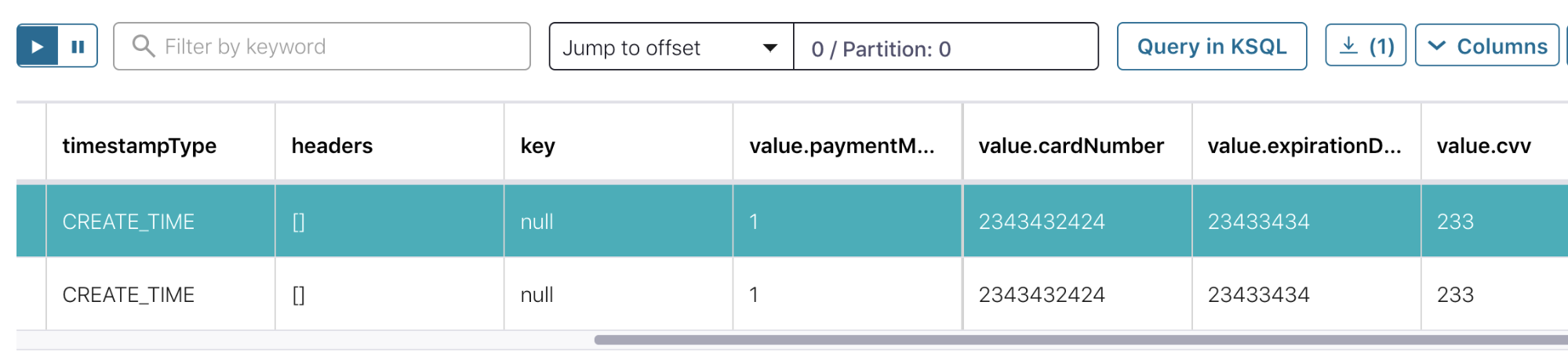
In addition to the existing Avro support, Confluent Control Center now allows for straightforward visualization of topic data containing either Protobuf or JSON Schema payloads, and can also create and display schemas for both Protobuf and JSON Schema.
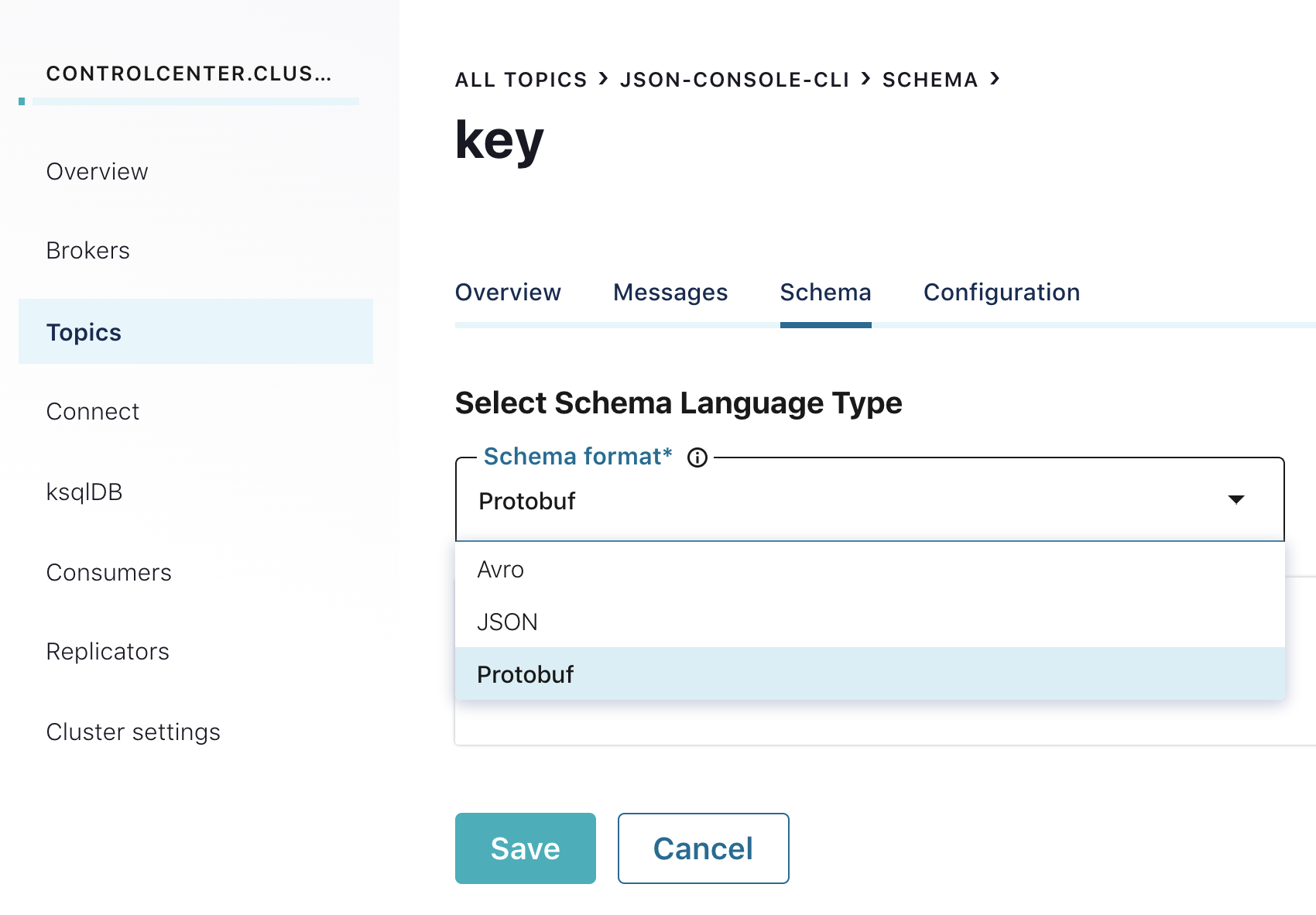
Confluent Cloud
Support for Protobuf and JSON Schema is being rolled out to Confluent Cloud as well. If you’re using Schema Registry or ksqlDB in Confluent Cloud, you’ll be able to use them with Avro, Protobuf, and JSON Schema.
Add your own schema formats
Schema Registry has been made completely extensible, so you are free to add new formats and even define compatibility rules for them. You can even introduce your new formats into other parts of the Confluent Platform by adding custom SerDes to work with Kafka Streams or by adding custom converters to work with Kafka Connect.
For example, some users have asked for Schema Registry to support XML. Now, you can add XML support to Schema Registry directly, and use Schema Registry to store both XML and Avro at the same time. For more on how to add your own schema formats, please refer to the documentation and check out the Streaming Audio podcast.
In summary, with Confluent Platform, you now have the freedom to choose from the most popular formats: Avro, Protobuf, and JSON Schema. You now also have the freedom to add new formats to Schema Registry to suit your needs. We’ve been listening to our users, and we look forward to seeing what you’ll do with these new features in the future.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.