Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Implement a Cross-Platform Apache Kafka Producer and Consumer with C# and .NET
Sometimes you’d like to write your own code for producing data to an Apache Kafka® topic and connecting to a Kafka cluster programmatically. Confluent provides client libraries for several different programming languages that make it easy to code your own Kafka clients in your favorite dev environment.
One of the most popular dev environments is .NET and Visual Studio (VS) Code. This blog post shows you step by step how to use .NET and C# to create a client application that streams Wikipedia edit events to a Kafka topic in Confluent Cloud. Also, the app consumes a materialized view from ksqlDB that aggregates edits per page. The application runs on Linux, macOS, and Windows, with no code changes.
C# was chosen for cross-platform compatibility, but you can create clients by using a wide variety of programming languages, from C to Scala. For the latest list, see Code Examples for Apache Kafka®. The app reads events from WikiMedia’s EventStreams web service—which is built on Kafka! You can find the code here: WikiEdits on GitHub.
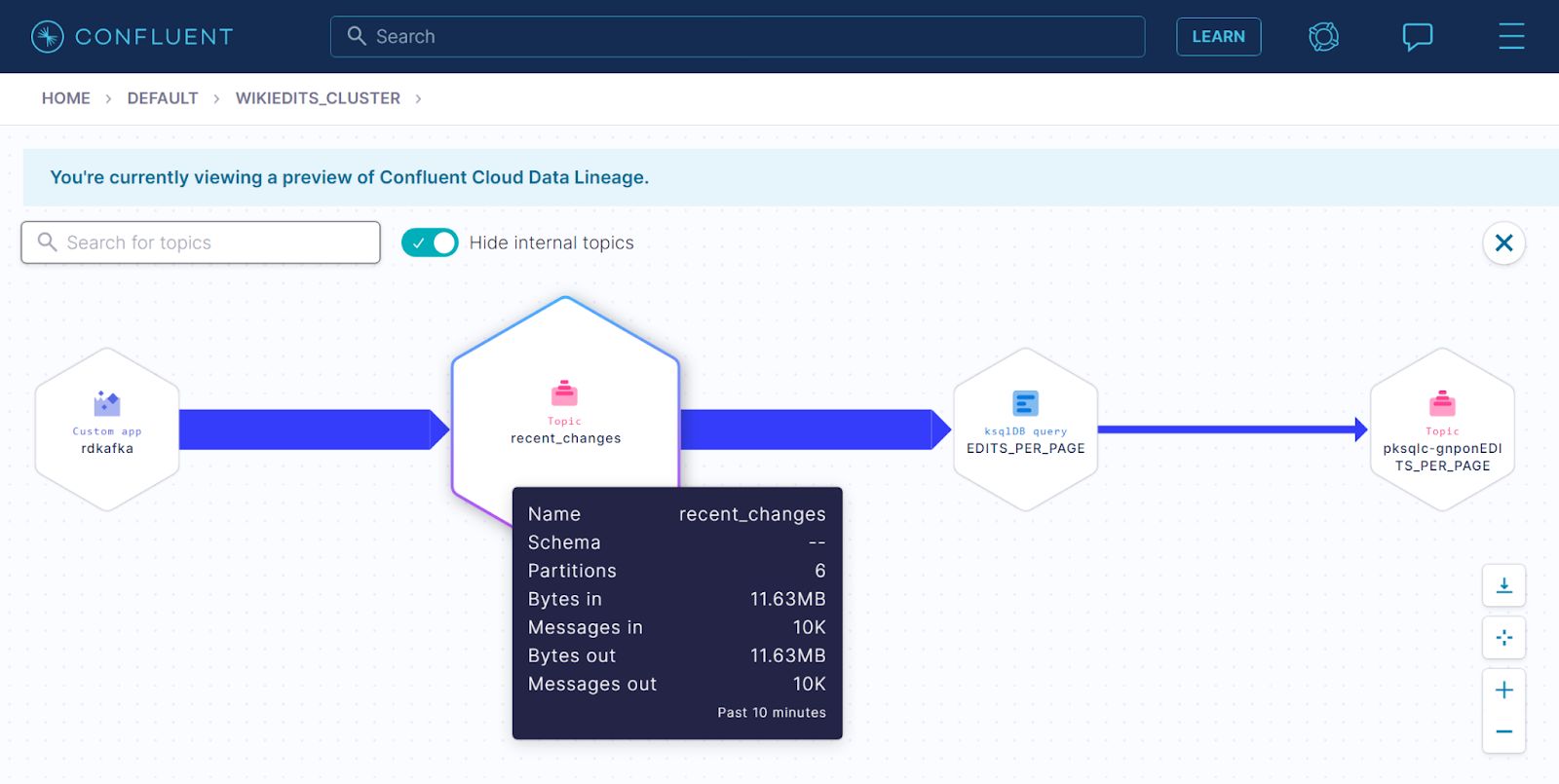
The following diagram shows the data pipeline, transformations, and the app’s topology. It was created with the Confluent Cloud Data Lineage feature, currently in Early Access. On the left, the node labeled rdkafka represents the producer app, which produces messages to the recent_changes topic, shown in the second node. The EDITS_PER_PAGE query, shown in the third node, consumes from the recent_changes topic, aggregates messages, and saves them to the sink topic in the fourth node, which for this cluster is named pksql-gnponEDITS_PER_PAGE.
Prerequisites:
- .NET 5: Download .NET 5.0 (Linux, macOS, and Windows)
- Visual Studio Code: Download Visual Studio Code – Mac, Linux, Windows
- A free Confluent Cloud account: Sign up for free with coupon code CL60BLOG
Create the project
Follow these steps to create the WikiEditStream project. Because VS Code and .NET are completely cross-platform, the same steps work on Linux, WSL 2, PowerShell, and macOS.
- Open a terminal window and navigate to a convenient directory, like your local GitHub repositories directory:
cd repos
- Start VS Code:
code .
- In VS Code, open a new terminal.
- Create a new project:
dotnet new console --name WikiEditStream
The dotnet new command creates the WikiEditStream directory for you and adds two files: Program.cs and WikiEditStream.csproj.
- Navigate to the WikiEditStream directory:
cd WikiEditStream
- Run the project:
dotnet run
Your output should resemble:
Hello World!
Install packages
The WikiEditStream project requires Confluent’s client library for .NET, which is available as a NuGet package named Confluent.Kafka.
In the VS Code terminal, add the Confluent.Kafka NuGet package:
dotnet add package Confluent.Kafka
When the package is installed, the project is ready for the producer and consumer code.
Get your Confluent Cloud API credentials
Your client code needs API credentials to connect to Confluent Cloud.
- Log in to your Confluent Cloud account.
- Open the Cluster menu and click Clients. The Clients page opens. Click New client to open the New Client page.

- Click the C# tile and scroll to the Set up and configuration section.
- Click Create Kafka cluster API key to get credentials for your client. Make note of the key, secret, and bootstrap servers—you’ll be using them soon.
Write Wikipedia edits to a Kafka topic
The Produce method implements these steps:
- Create an HTTP client to read the RC stream from Wikipedia.
- Build a producer based on the specified configuration.
- Open a stream reader on the RC stream from the HTTP client.
- Read the next message and deserialize it.
- For the message’s key, assign the URL of the page that was edited.
- Produce the message to the specified Kafka topic.
- Loop until Ctrl+C.
In VS Code, open Program.cs and include the following namespaces:
using Confluent.Kafka; using System; using System.IO; using System.Net.Http; using System.Text.Json; using System.Threading; using System.Threading.Tasks;
Copy the following code and paste it into Program.cs, after the Main method:
// Produce recent-change messages from Wikipedia to a Kafka topic.
// The messages are sent from the RCFeed https://www.mediawiki.org/wiki/Manual:RCFeed
// to the topic with the specified name.
static async Task Produce(string topicName, ClientConfig config)
{
Console.WriteLine($"{nameof(Produce)} starting");
// The URL of the EventStreams service.
string eventStreamsUrl = "https://stream.wikimedia.org/v2/stream/recentchange";
// Declare the producer reference here to enable calling the Flush
// method in the finally block, when the app shuts down.
IProducer<string, string> producer = null;
try
{
// Build a producer based on the provided configuration.
// It will be disposed in the finally block.
producer = new ProducerBuilder<string, string>(config).Build();
// Create an HTTP client and request the event stream.
using(var httpClient = new HttpClient())
// Get the RC stream.
using (var stream = await httpClient.GetStreamAsync(eventStreamsUrl))
// Open a reader to get the events from the service.
using (var reader = new StreamReader(stream))
{
// Read continuously until interrupted by Ctrl+C.
while (!reader.EndOfStream)
{
// Get the next line from the service.
var line = reader.ReadLine();
// The Wikimedia service sends a few lines, but the lines
// of interest for this demo start with the "data:" prefix.
if(!line.StartsWith("data:"))
{
continue;
}
// Extract and deserialize the JSON payload.
int openBraceIndex = line.IndexOf('{');
string jsonData = line.Substring(openBraceIndex);
Console.WriteLine($"Data string: {jsonData}");
// Parse the JSON to extract the URI of the edited page.
var jsonDoc = JsonDocument.Parse(jsonData);
var metaElement = jsonDoc.RootElement.GetProperty("meta");
var uriElement = metaElement.GetProperty("uri");
var key = uriElement.GetString(); // Use the URI as the message key.
// For higher throughput, use the non-blocking Produce call
// and handle delivery reports out-of-band, instead of awaiting
// the result of a ProduceAsync call.
producer.Produce(topicName, new Message<string, string> { Key = key, Value = jsonData },
(deliveryReport) =>
{
if (deliveryReport.Error.Code != ErrorCode.NoError)
{
Console.WriteLine($"Failed to deliver message: {deliveryReport.Error.Reason}");
}
else
{
Console.WriteLine($"Produced message to: {deliveryReport.TopicPartitionOffset}");
}
});
}
}
}
finally
{
var queueSize = producer.Flush(TimeSpan.FromSeconds(5));
if (queueSize > 0)
{
Console.WriteLine("WARNING: Producer event queue has " + queueSize + " pending events on exit.");
}
producer.Dispose();
}
}
Reading Wikipedia edits from a Kafka topic
The Consume method implements these steps:
- Configure a consumer group
- Build a consumer based on the specified configuration
- Subscribe to the specified Kafka topic
- Consume and deserialize the next message
Copy the following code and paste it into Program.cs, after the Produce method:
static void Consume(string topicName, ClientConfig config)
{
Console.WriteLine($"{nameof(Consume)} starting");
// Configure the consumer group based on the provided configuration.
var consumerConfig = new ConsumerConfig(config);
consumerConfig.GroupId = "wiki-edit-stream-group-1";
// The offset to start reading from if there are no committed offsets (or there was an error in retrieving offsets).
consumerConfig.AutoOffsetReset = AutoOffsetReset.Earliest;
// Do not commit offsets.
consumerConfig.EnableAutoCommit = false;
// Enable canceling the Consume loop with Ctrl+C.
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (_, e) => {
e.Cancel = true; // prevent the process from terminating.
cts.Cancel();
};
// Build a consumer that uses the provided configuration.
using (var consumer = new ConsumerBuilder<string, string>(consumerConfig).Build())
{
// Subscribe to events from the topic.
consumer.Subscribe(topicName);
try
{
// Run until the terminal receives Ctrl+C.
while (true)
{
// Consume and deserialize the next message.
var cr = consumer.Consume(cts.Token);
// Parse the JSON to extract the URI of the edited page.
var jsonDoc = JsonDocument.Parse(cr.Message.Value);
// For consuming from the recent_changes topic.
var metaElement = jsonDoc.RootElement.GetProperty("meta");
var uriElement = metaElement.GetProperty("uri");
var uri = uriElement.GetString();
// For consuming from the ksqlDB sink topic.
// var editsElement = jsonDoc.RootElement.GetProperty("NUM_EDITS");
// var edits = editsElement.GetInt32();
// var uri = $"{cr.Message.Key}, edits = {edits}";
Console.WriteLine($"Consumed record with URI {uri}");
}
}
catch (OperationCanceledException)
{
// Ctrl+C was pressed.
Console.WriteLine($"Ctrl+C pressed, consumer exiting");
}
finally
{
consumer.Close();
}
}
}
Set up configuration
All that’s left is to set up the client app’s configuration. In the Main method, create a ClientConfig instance and populate it with the credentials from your Confluent Cloud cluster.
Replace the default Main method with the following code:
static async Task Main(string[] args)
{
// Configure the client with credentials for connecting to Confluent.
// Don't do this in production code. For more information, see
// https://docs.microsoft.com/en-us/aspnet/core/security/app-secrets.
var clientConfig = new ClientConfig();
clientConfig.BootstrapServers="<bootstrap-host-port-pair>";
clientConfig.SecurityProtocol=Confluent.Kafka.SecurityProtocol.SaslSsl;
clientConfig.SaslMechanism=Confluent.Kafka.SaslMechanism.Plain;
clientConfig.SaslUsername="<api-key>";
clientConfig.SaslPassword="<api-secret>";
clientConfig.SslCaLocation = "probe"; // /etc/ssl/certs
await Produce("recent_changes", clientConfig);
//Consume("recent_changes", clientConfig);
Console.WriteLine("Exiting");
}
Replace the bootstrap-host-port-pair, api-key, and api-secret configs with the strings you copied from Confluent Cloud.
Production code must never have hardcoded keys and secrets. They’re shown here only for convenience. For production code, see Safe storage of app secrets in development in ASP.NET Core.
Also, depending on your platform, there may be complexity around the SslCaLocation config, which specifies the path to your SSL CA root certificates. Details vary by platform, but specifying probe may be sufficient for most cases. For more information, see SSL in librdkafka.
Create the Kafka topic
Your program is ready to run, but it needs a topic in your cluster.
- Log in to your Confluent Cloud account and open your cluster.
- Open the Cluster menu and click Topics.
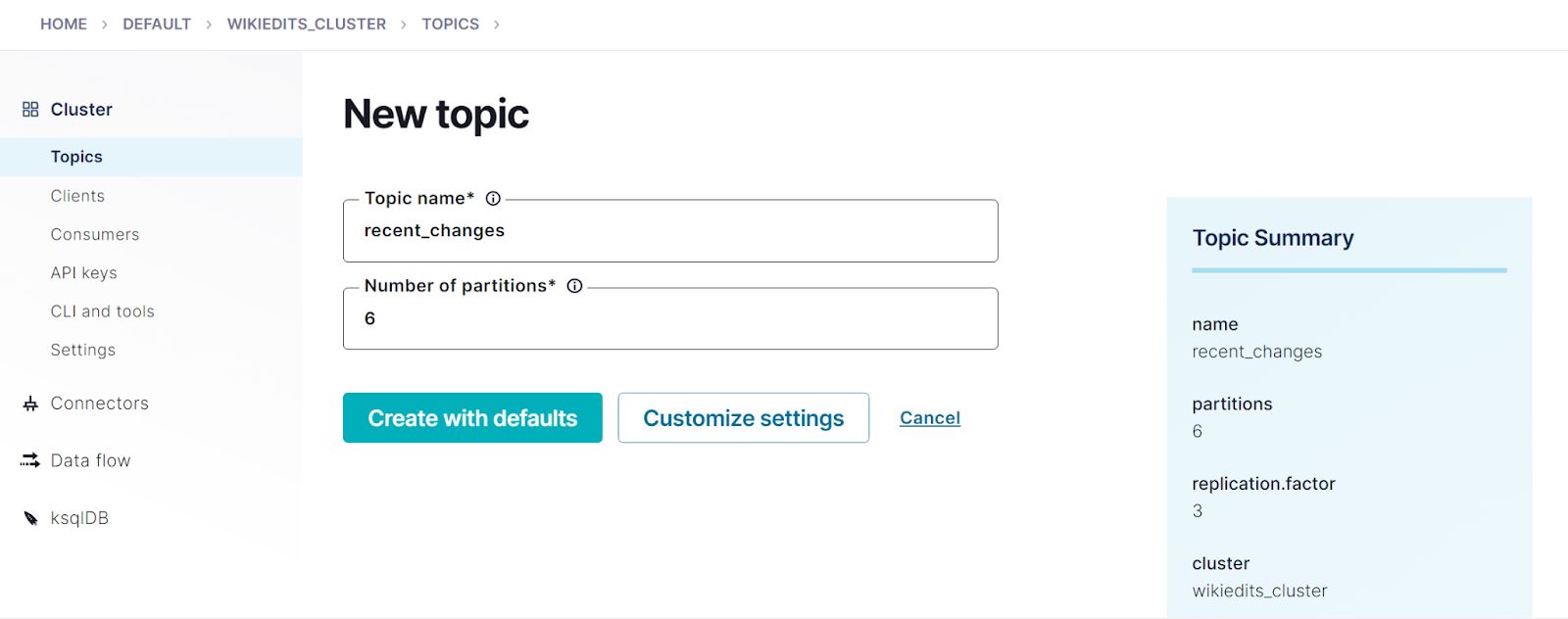
- Click Add topic, and in the Topic name textbox, enter recent_changes. Click Create with defaults to create the topic.
Run the producer
In the VS Code terminal, build and run the program.
dotnet run
You should see editing events printed to the console, followed by batches of production messages.
Produce starting
...
Data string: {"$schema":"/mediawiki/recentchange/1.0.0","meta":{"uri":"https://ceb.wikipedia.org/wiki/Koudiet_Klib_Ethour" …
Data string: {"$schema":"/mediawiki/recentchange/1.0.0","meta":{"uri":"https://commons.wikimedia.org/wiki/Category:Images_from_Geograph_Britain_and_Ireland_missing_SDC_depicts" …
Produced message to: recent_changes [[1]] @191
Produced message to: recent_changes [[5]] @119
Produced message to: recent_changes [[3]] @202
...
While the producer is running, return to Confluent Cloud.
- Open the Cluster menu and click Topics.
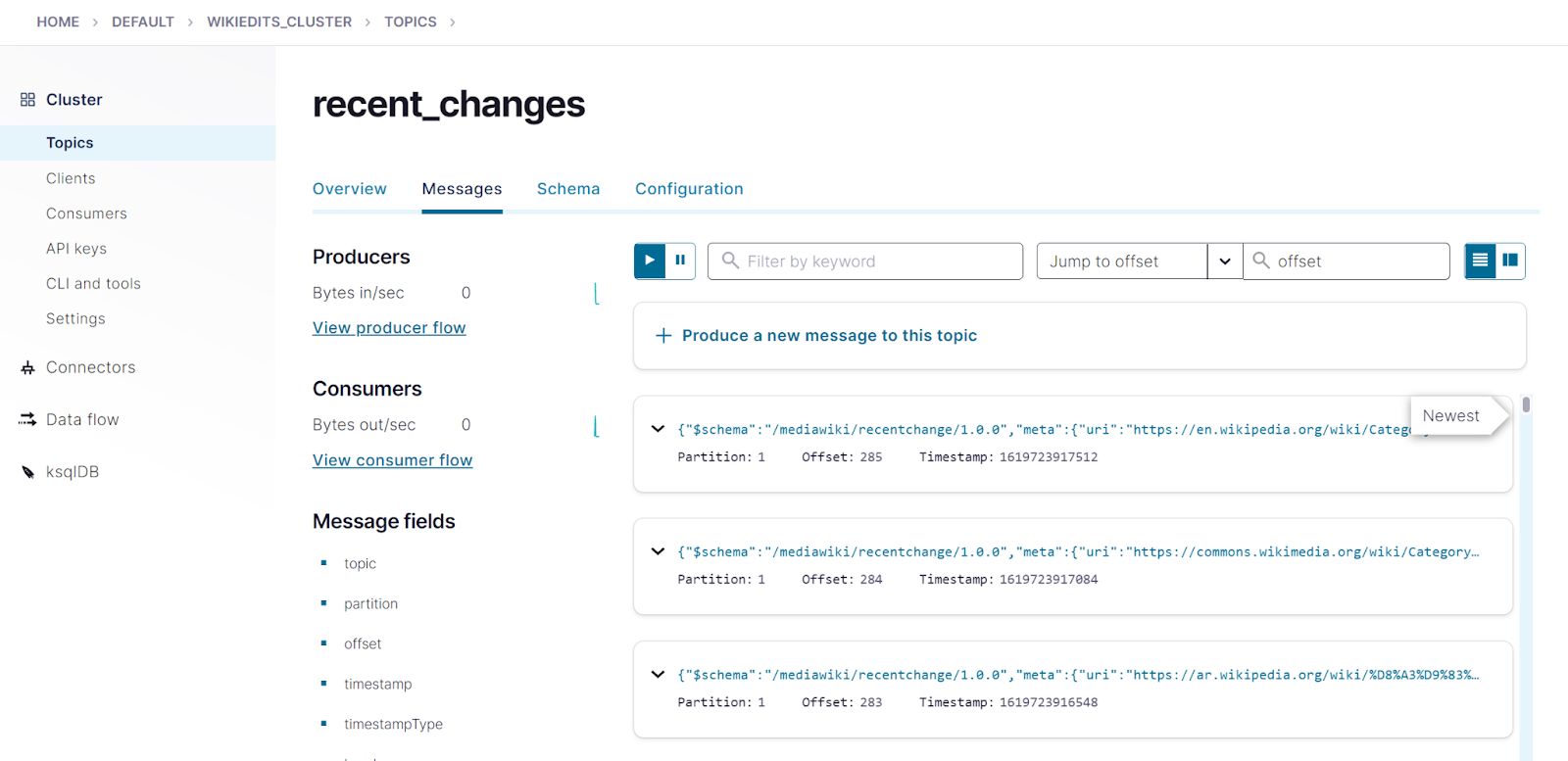
- In the topic list, click recent_changes.
- In the topic details page, click Messages. You should see the edit messages streaming to the recent_changes topic.
- In the VS Code terminal, press Ctrl+C to stop the producer.
Run the consumer
Now that you’ve produced messages to the recent_changes topic, you can consume them. In the Main method, comment out the call to Produce and uncomment the call to Consume.
// await Produce("recent_changes", clientConfig);
Consume("recent_changes", clientConfig);
In the VS Code terminal, build and run the program.
dotnet run
Your output should resemble:
Consume starting Consumed record with URI https://commons.wikimedia.org/wiki/Category:Flickr_images_missing_SDC_copyright_status Consumed record with URI https://pl.wiktionary.org/wiki/dane Consumed record with URI https://www.wikidata.org/wiki/Q91881031 ...
Because the consumer is configured with AutoOffsetReset.Earliest, it reads from the first message in the recent_changes topic to the most recent message and waits for more messages.
Press Ctrl+C to stop the consumer.
Add aggregation logic
Producing messages and simply passing them through to a consumer isn’t particularly useful, so you need to add some logic. The following steps show how to create a ksqlDB app that aggregates recent_changes records by URI and counts the number of edits that occur per page, providing a materialized view on the stream.
Create a ksqlDB application
- In Confluent Cloud, click ksqlDB, and on the ksqlDB page, click Add application.
- In the New application page, click Global access and Continue.
- In the Application name textbox, enter recent_changes_app, and click Launch application. Provisioning your new application starts and may take a few minutes to complete.
- When your application is provisioned, click recent_changes_app to start writing the SQL statements and queries that define your app.
Create a stream
The first step for implementing aggregation logic is to register a stream on the recent_changes topic.
Copy and paste the following SQL into the query editor and click Run query. It registers a stream, named recent_changes_stream, on the recent_changes topic. The CREATE STREAM statement specifies the schema of the records.
CREATE STREAM recent_changes_stream (
schema VARCHAR,
meta STRUCT<uri VARCHAR,
request_id VARCHAR,
id VARCHAR,
dt VARCHAR,
domain VARCHAR,
wiki_stream VARCHAR,
wiki_topic VARCHAR,
wiki_partition BIGINT,
offset BIGINT>,
id BIGINT,
edit_type VARCHAR,
wiki_namespace INT,
title VARCHAR,
comment VARCHAR,
edit_timestamp BIGINT,
user VARCHAR,
bot VARCHAR,
server_url VARCHAR,
server_name VARCHAR,
server_script_path VARCHAR,
wiki VARCHAR,
parsedcomment VARCHAR)
WITH (KAFKA_TOPIC='recent_changes',
VALUE_FORMAT='JSON',
PARTITIONS=6);
Your output should resemble:
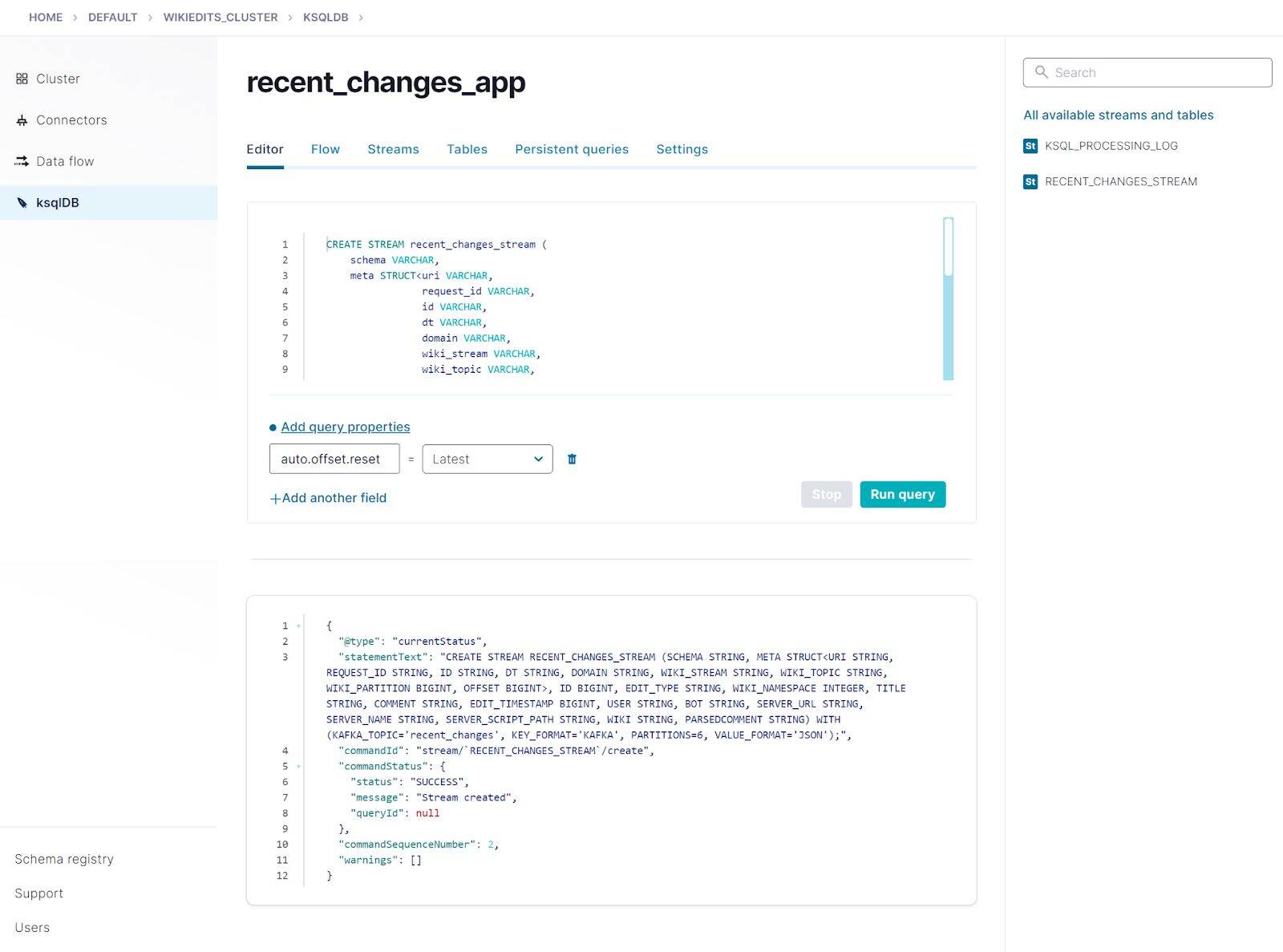
To define the schema of the recent_changes_stream, you can infer the fields from one of the messages. You must rename the stream, topic, and partition fields, because these are keywords in ksqlDB SQL. It’s fun to see a bit of the Kafka infrastructure that powers the WikiMedia stream in these messages—for example, the stream is named “mediawiki.recentchange”, and the underlying Kafka topic is named “eqiad.mediawiki.recentchange”.
{
"$schema": "/mediawiki/recentchange/1.0.0",
"meta": {
"uri": "https://commons.wikimedia.org/wiki/Category:Botanists_from_Poland",
"request_id": "bd5cd656-eef7-44e6-ac7a-360dbe1f92bc",
"id": "b6aa54cd-ea42-4ac0-9900-54670804f575",
"dt": "2021-05-04T18:29:29Z",
"domain": "commons.wikimedia.org",
"stream": "mediawiki.recentchange",
"topic": "eqiad.mediawiki.recentchange",
"partition": 0,
"offset": 3157257551
},
"id": 1674896597,
"type": "categorize",
"namespace": 14,
"title": "Category:Botanists from Poland",
"comment": "[[:File:Teofil Ciesielski (-1906).jpg]] added to category",
"timestamp": 1620152969,
"user": "2A01:C22:842E:7000:E8EE:6BD9:C640:FC09",
"bot": false,
"server_url": "https://commons.wikimedia.org",
"server_name": "commons.wikimedia.org",
"server_script_path": "/w",
"wiki": "commonswiki",
"parsedcomment": "<a href=\"/wiki/File:Teofil_Ciesielski_(-1906).jpg\" title=\"File:Teofil Ciesielski (-1906).jpg\">File:Teofil Ciesielski (-1906).jpg</a> added to category"
}
The official schema is in the Wikimedia schemas/event/primary repo.
Query the stream
With the stream registered, you can query the records as they’re appended to the recent_changes topic.
In VS Code, edit the Main method to comment out the Consume call and uncomment the Produce call.
await Produce("recent_changes", clientConfig);
//Consume("recent_changes", clientConfig);
Run the app to start producing messages.
dotnet run
In the ksqlDB query editor, copy and paste the following query and click Run query:
select META -> URI from RECENT_CHANGES_STREAM EMIT CHANGES;
Your output should resemble:
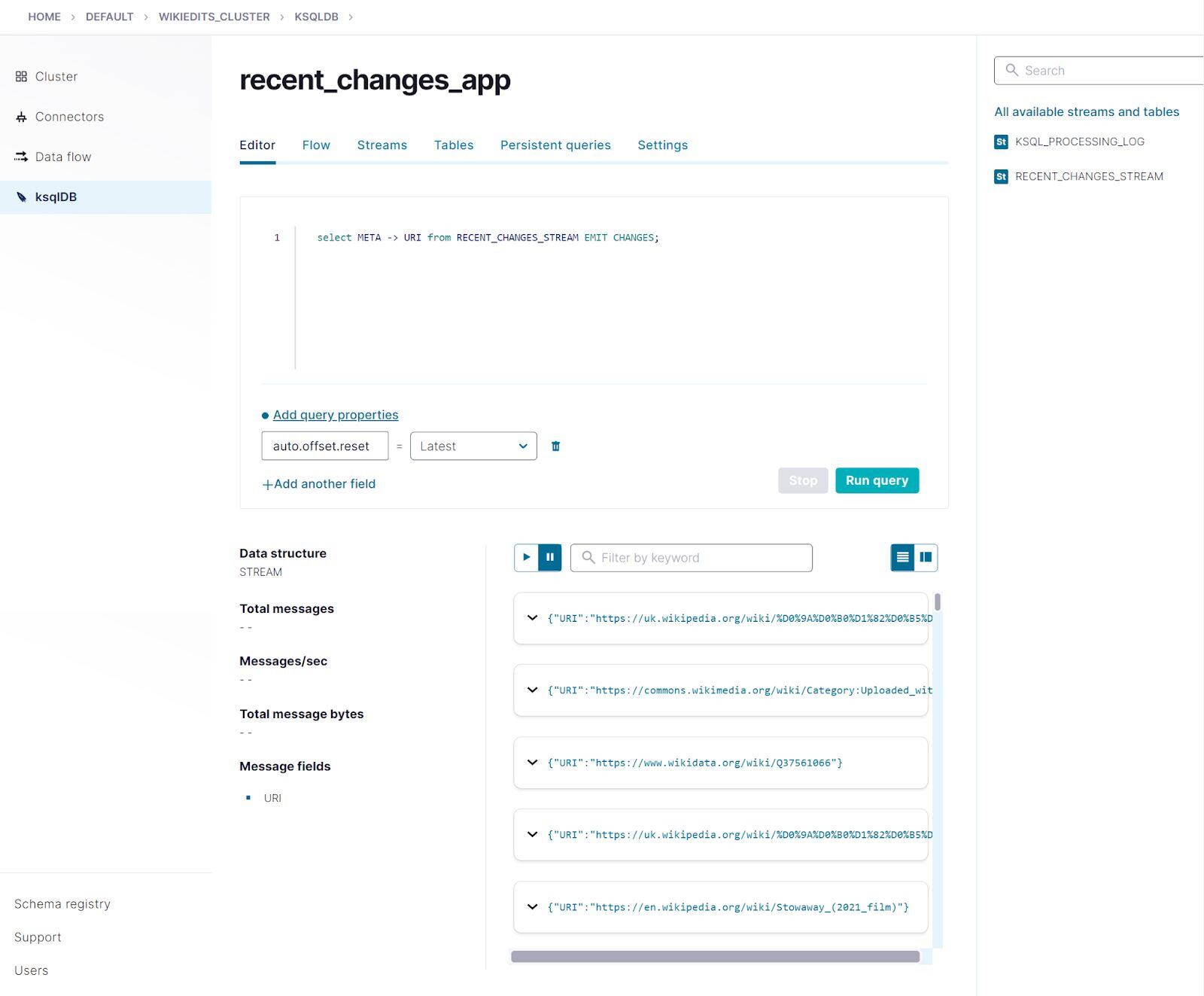
This is a transient, client-side query that selects the URI from each record. It runs continuously until you cancel it. Click Stop to cancel the query.
Add aggregation logic
With the stream defined, you can derive a table from it that aggregates the data.
In the Add query properties section, configure the commit.interval.ms query property, which sets the output frequency from a table. The default is 30000 ms, or 30 seconds. Set it to 1000, so you wait for one second only before table updates appear.
commit.interval.ms = 1000
In the query editor, run the following statement to create the edits_per_page table, which is derived from recent_changes_stream and shows an aggregated view of the number of edits per Wikipedia page:
CREATE TABLE edits_per_page AS
SELECT meta->uri,
COUNT(*) AS num_edits
FROM recent_changes_stream
GROUP BY meta->uri
EMIT CHANGES;
Copy the following SELECT statement into the editor and click Run query:
SELECT * FROM edits_per_page EMIT CHANGES;
After a one-second delay, your output should resemble: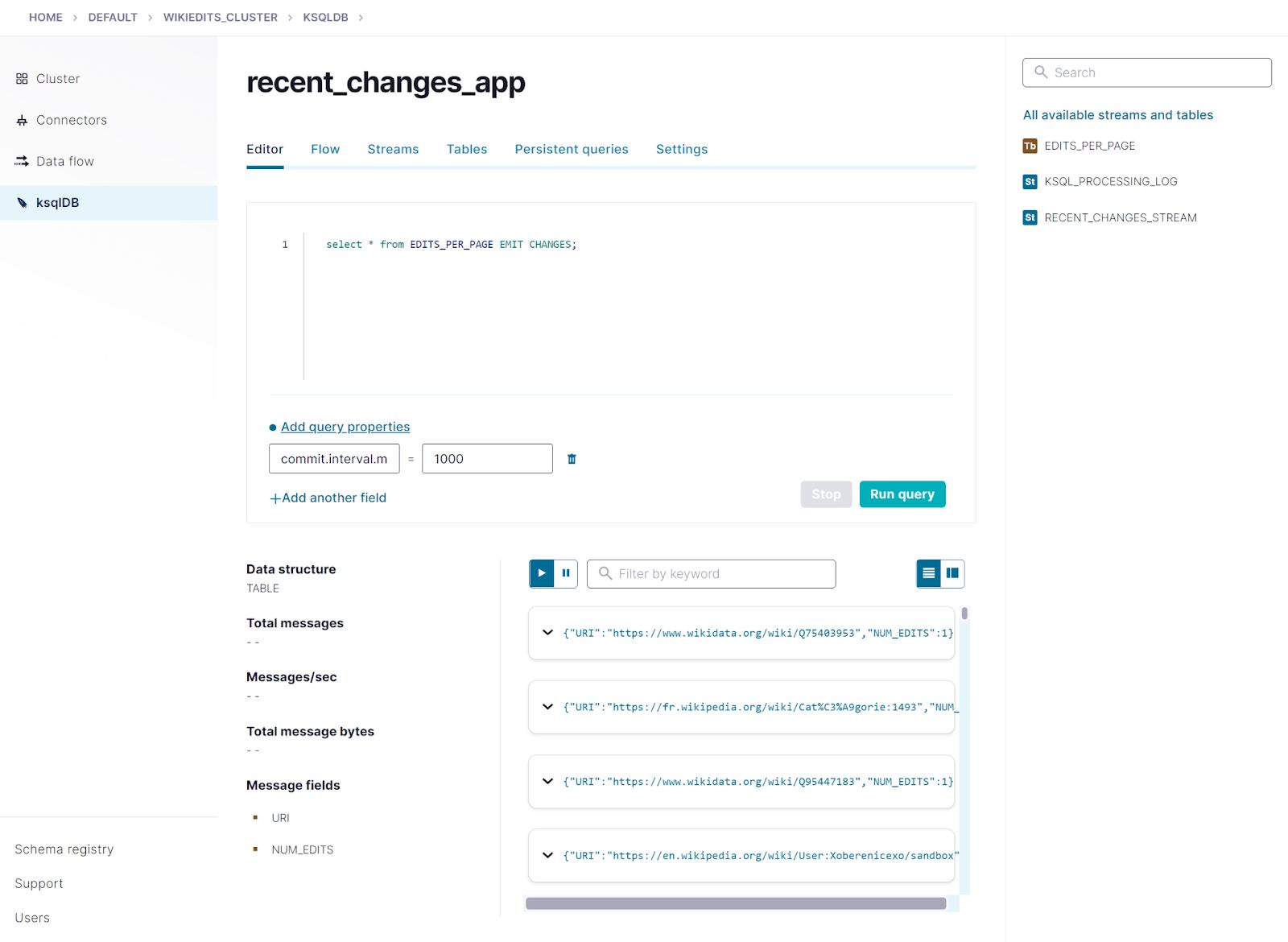
Consume the aggregated results
Your consumer code can access the output from the ksqlDB app by consuming from the sink topic that receives the results from the edits_per_page query. Use the Confluent Cloud UI to find the name of the table topic.
- Click Tables, and in the tables list, click EDITS_PER_PAGE to inspect the table.
- In the details view, find the topic name, which should resemble pksqlc-gnponEDITS_PER_PAGE.
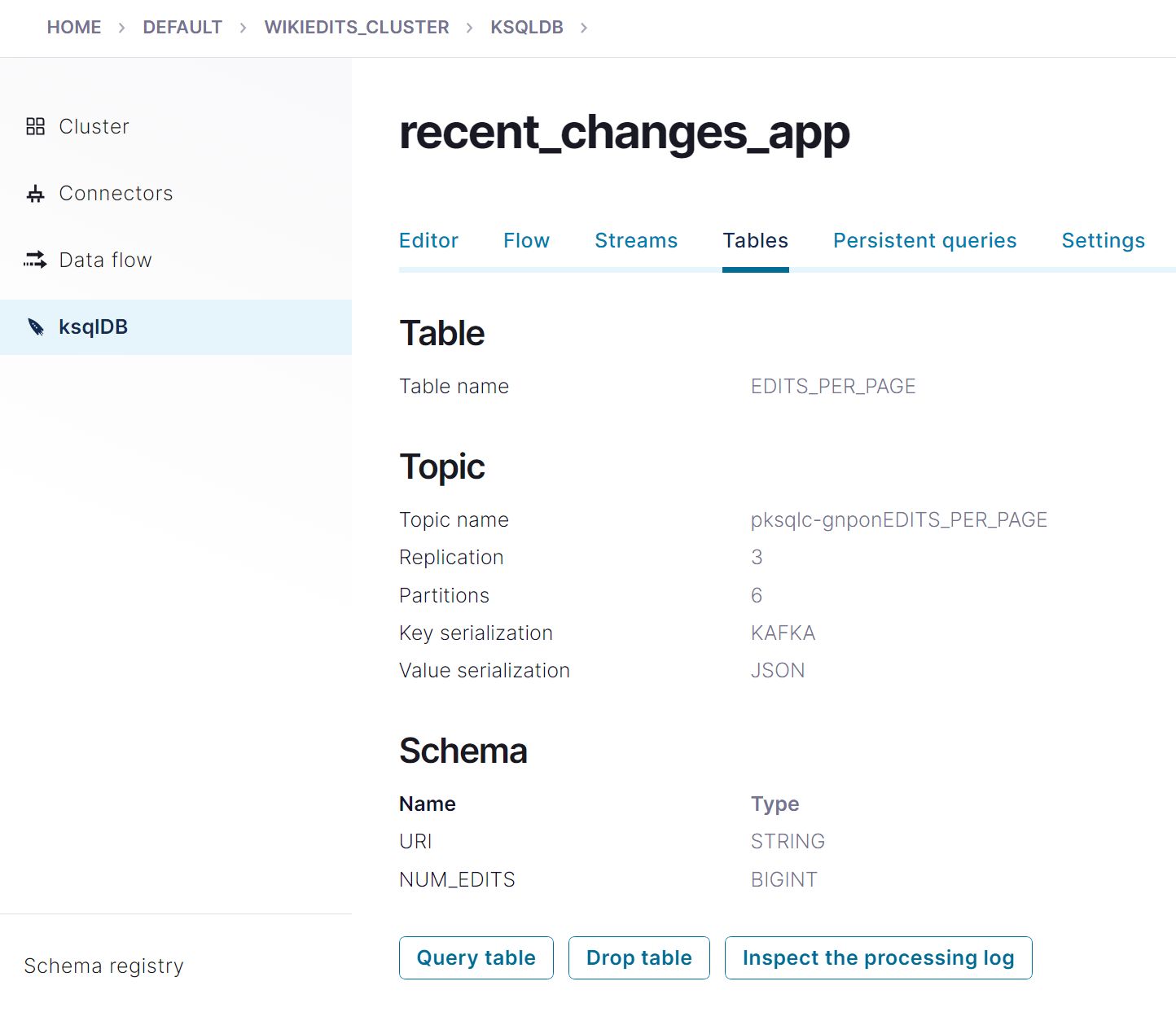
- In the VS Code terminal, press Ctrl+C to stop the producer.
- Edit the Main method to comment out the Produce call and uncomment the Consume call. Replace recent_changes with the topic name for your table.
//Produce("recent_changes", clientConfig).Wait(); Consume("<table-topic-name>", clientConfig);
In the Consume method, get the URI from the message’s key, and get the number of edits from the NUM_EDITS field in the message’s value. Comment out the code for the recent_changes topic and uncomment the code for the ksqlDB sink topic.
// For consuming from the recent_changes topic.
// var metaElement = jsonDoc.RootElement.GetProperty("meta");
// var uriElement = metaElement.GetProperty("uri");
// var uri = uriElement.GetString();
// For consuming from the ksqlDB sink topic.
var editsElement = jsonDoc.RootElement.GetProperty("NUM_EDITS");
var edits = editsElement.GetInt32();
var uri = $"{cr.Message.Key}, edits = {edits}";
Run the consumer to view the aggregation results.
dotnet run
Your output should resemble:
Consume starting Consumed record with URI https://en.wikipedia.org/wiki/Discovery_(Daft_Punk_album), edits = 1 Consumed record with URI https://en.wikipedia.org/wiki/Inverness_Athletic_F.C., edits = 2 Consumed record with URI https://en.wikipedia.org/wiki/Alma_Mater_Society_of_Queen%27s_University, edits = 5 ...
Run cross-platform
.NET provides a true “write once, run anywhere” experience. If you have access to two different platforms, for example, Linux and Windows, you can run the app as a producer on one platform and a consumer on the other.
For example, you can replace the Produce and Consume calls in Main with some conditional logic:
if(platform == System.PlatformID.Unix)
{
await Produce("recent_changes", clientConfig);
//Consume("recent_changes", clientConfig);
}
else if(platform == System.PlatformID.Win32NT)
{
Consume("recent_changes", clientConfig);
//await Produce("recent_changes", clientConfig);
}
Here’s the app running as a producer on Linux (WSL 2) and as a consumer in Windows PowerShell:
Wrap up
In this tutorial, you created a simple cross-platform client that produces Wikipedia edit messages to a Kafka topic and consumes a table of aggregated records from a ksqlDB application.
This is demo code, and it can be improved in a number of ways:
- Add schema support: Validate messages with the Confluent.SchemaRegistry.Serdes packages, which provide serializers and deserializers for working with formatted data and Confluent Schema Registry
- Manage credentials: Managing credentials requires a lot of care in your code, and Andrea Chiarelli shows how to store secrets in the appsettings.json configuration file: Secrets Management in .NET Applications
- Create a custom connector: A more sophisticated implementation might use Chris Matta’s Server Sent Events Source Connector, as shown in Confluent Platform Demo
With Confluent Cloud, you can develop cross-platform Kafka applications rapidly by using VS Code alongside the pipeline visualization and management features in the Confluent Cloud UI. Get started with a free trial of Confluent Cloud and use the promo code CL60BLOG for an additional $60 of free Confluent Cloud usage.*
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent





