Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
IoT Reference Architecture and Implementation Guide Using Confluent and MongoDB Realm
The Internet of Things (IoT)—connecting physical objects to software components—has created several innovations and opportunities for enterprise companies, and continues to grow in top industries, including healthcare, smart factories, energy, retail, industrial facilities, and even smart home products.
For example, imagine sitting in a global control center and being able to remotely monitor and control the entire production of an automobile parts and assembly unit. IoT is able to create a connected enterprise and remotely monitor, control, and visualize it.
This blog post presents how Confluent and MongoDB work together to deliver an easy and robust IoT pipeline with the MongoDB connector and MongoDB predefined IoT databases. It will help you address the challenges with IoT and provides a detailed look at additional features such as ksqlDB, MongoDB Atlas, and MongoDB Realm. By following this approach you can build faster, smarter, and make your IoT architecture more efficient.
Types of IoT customers
Generally, there are two categories of IoT use cases: thick and thin edge use cases.
Thick edge customers are large or mid-sized industries like building management systems and automobile manufacturers. These use cases typically require multi-core CPUs and GBs of RAM at the edge with a private network.
Thin edge customers are businesses like fleet management providers, smart devices, and banks. Here the devices are small movable/static assets that require minimal resources and generally communicate via a public network.
Solution architectures
The following details the reference architectures for both types of use cases mentioned above. Check out the video below for more details on IoT use cases and the reference architectures.
Thick edge use cases
Sensors (such as for detecting pressure, proximity, temperature, etc.) embedded within machinery or other physical assets often communicate to the edge gateway via a frequency protocol like Zigbee or LoRa through repeaters (which extends network coverage to the gateway). Listeners or services at the edge collect the data from the gateway to process and act on the data before sending it to cloud or enterprise data center environments. In a thick edge scenario, you need decent computing and storage resources, since they often provide the localized intelligence to act quickly. Use cases include large-scale industries like oil and gas providers, manufacturing automation, and building management systems.
Data from different assets are aggregated at the edge and pushed to the Confluent Platform at edge by using out-of-the-box connectors for different protocols—like MQTT/REST. Confluent has an Apache Kafka® setup where data is stored as transient for edge processing/analysis. Replicators seamlessly replicate the messages from the edge broker to Confluent Cloud.
The diagram below depicts the reference architecture for a thick edge use case:
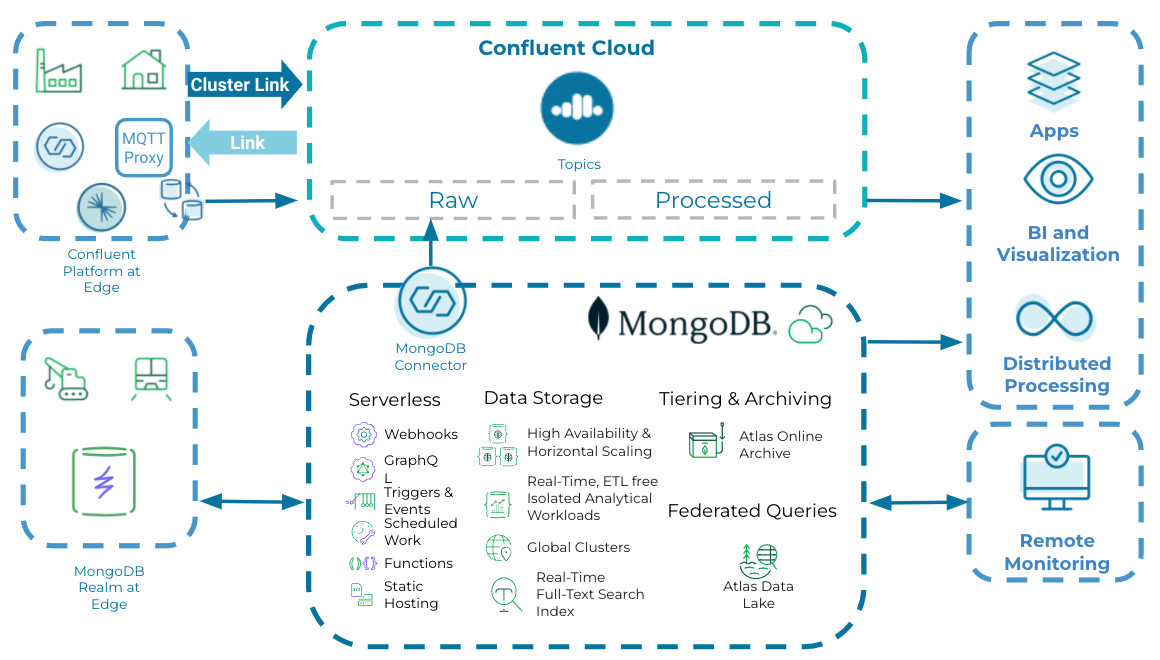
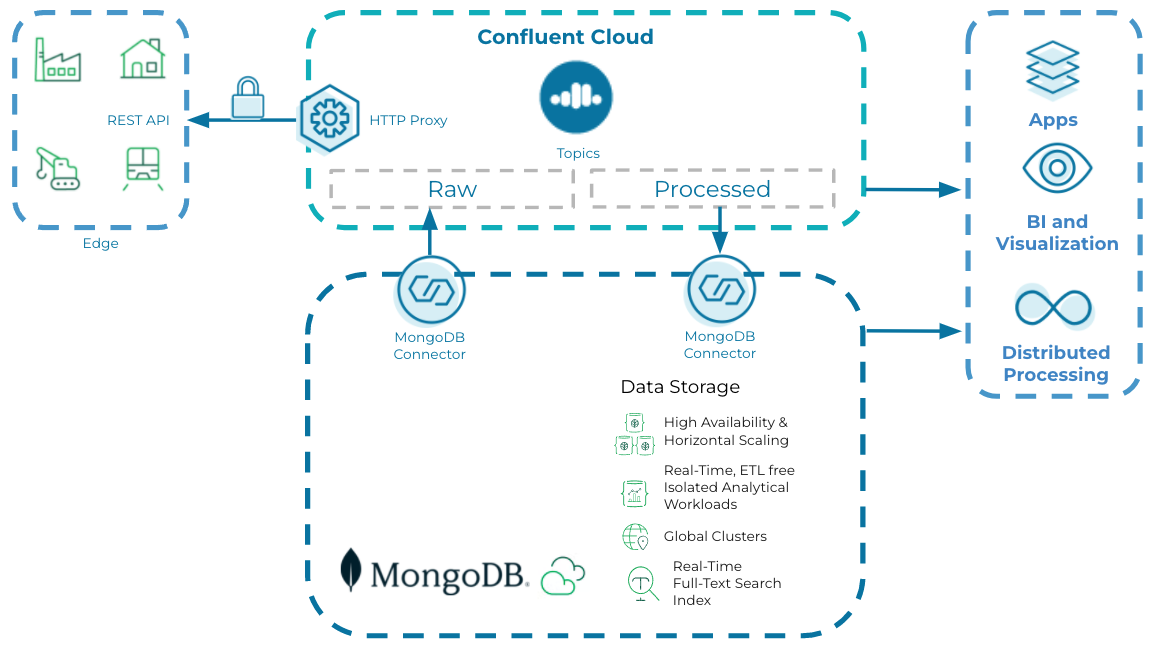
Thin edge use cases
In thin edge use cases, individual sensors directly push the corresponding data to the centralized processing hub where it will be analyzed, persisted, and acted upon. There is minimal processing or intelligence happening at the thin edge. Further, there may be little to no data filtering and aggregation happening at the edge. Use cases include high-speed data ingest and real-time analytics, simplified time-series data, and offline-first mobile applications.
The architecture for thin edge processing is very similar to thick edge use cases, apart from where the data is directly published to Confluent Cloud using Kafka Connect-based connectors and Rest proxy.
Example cash logistics use case
Cash logistics service providers offer the physical handling of cash from one location to another. For example, they might be responsible for replenishing the cash in ATMs. One of the key requirements of a cash logistics management company is ensuring the security of their vehicles that transport the cash.
Key features that need to be supported in this use case include:
- Tracking the trajectory of the armored vehicle
- Alerts and notifications when the cash or vehicle is being mishandled
- Handling data sync during periods of poor network connectivity
You can build a platform that supports these features using MongoDB and Confluent Cloud with low code and a simplified cloud-native architecture. This use case falls under the thin edge category. We’ll go through the step-by-step instructions to implement the solution architecture in the next section. You can also check out the video below which walks through a demo of the cash logistics use case.
Implementation
The implementation detailed below demonstrates how to easily configure Confluent and MongoDB Realm to collect a stream of continuous data that has been generated by any IoT device. The context of the cash logistics management company use case described above is used to provide a solution for ensuring the security of their vehicles handling ATM replenishment.
This implementation uses:
- Confluent for reading and writing the IoT simulated data to MongoDB Atlas
- MongoDB Realm as a lightweight mobile database
- Realm is an object database that is simple to embed in your mobile app. It is a developer-friendly alternative to mobile databases such as SQLite and CoreData.
- The MongoDB time series collection
- MongoDB triggers
- Database triggers allow you to execute server-side logic whenever a document is added, updated, or removed in a linked MongoDB Atlas cluster.
- Realm third-party services
To learn more in depth about the MongoDB and Confluent features used in this implementation, check out the videos below.
MongoDB features
Confluent features
Configure Confluent Cloud and create a topic, connectors, and streams before you start with the data generation.
For this implementation, we will begin by generating a stream of data in JSON format to simulate the moving vehicle using Python script, which in turn is captured by the Confluent topic. Please refer to the GitHub repository for complete implementation of the data generator and to get started with the data generator implementation. The data is then modified to the required format using ksqlDB. This modified data is then written into MongoDB Atlas using Confluent connectors.
Below are the ksqlDB queries to transform the data into the required format to insert into a MongoDB collection in order to perform geospatial queries on the data.
-- this flag tells Kafka where to start reading offsets.
-- define iiot_simulated stream
set 'auto.offset.reset'='earliest';
create stream iiot_simulated
(
"reg_num" varchar,
"owner" varchar,
"city" varchar,
"lon" double,
"lat" double,
"partition_key" varchar
) WITH (KAFKA_TOPIC='iot.data',
VALUE_FORMAT='JSON'
);
create stream finalStream as select "city", "owner", "reg_num" as "_id", struct("type":='Point', "coordinates":=array["lat", "lon"]) as "location","partition_key" from iiot_simulated emit changes;
Create the connectors with the below settings to write the data to the MongoDB time series collection as well as the normal collection respectively.
For time series collection:
{
"name": "MongoDbAtlasSinkConnector_0",
"config": {
"connector.class": "MongoDbAtlasSink",
"name": "MongoDbAtlasSinkConnector_0",
"input.data.format": "JSON",
"topics": "iot.data",
"connection.host": "iiotapp.2wqno.mongodb.net",
"connection.user": "venkatesh",
"database": "vehicle",
"collection": "tracking-historic",
"max.num.retries": "1",
"timeseries.timefield": "Timestamp",
"timeseries.timefield.auto.convert": "true",
"timeseries.timefield.auto.convert.date.format": "yyyy-MM-dd'T'HH:mm:ss'Z'",
"tasks.max": "1"
}
}
For normal collection:
{
"name": "MongoDbAtlasSinkConnector_1",
"config": {
"connector.class": "MongoDbAtlasSink",
"name": "MongoDbAtlasSinkConnector_1",
"input.data.format": "JSON",
"topics": "pksqlc-o2znjFINALSTREAM",
"connection.host": "iiotapp.2wqno.mongodb.net",
"connection.user": "venkatesh",
"database": "vehicle",
"collection": "TrackingGeospatial",
"write.strategy": "UpdateOneTimestampsStrategy",
"tasks.max": "1"
}
}
We use two MongoDB collections to store the data. A time series collection named “tracking-historic” will store the historic data and a collection named “TrackingGeospatial” with geospatial capabilities will store only the latest data for the simulated vehicle. The data in the “TrackingGeospatial” collection will be in sync with the Realm database on mobile applications using MongoDB Realm Sync.
![]()

Any changes to the data in the “TrackingGeospatial” collection will be reflected on the Realm mobile database using Realm Sync. We also used MongoDB Webhooks to access the data in the time series collection for analytical purposes. It helps with the timeline of the vehicle for the past 24 hours and action taken against any event.
The detailed implementation is explained in the readme file of the use case implementation repository.
What’s next?
Given the increased scale of operation on MongoDB Realm deployments, we are always looking at ways to improve the architecture and scalability of the entire telemetry pipeline. To learn more, check out the following resources:
- Choosing the best data platform for IoT needs
- What is IoT Architecture?
- Using Confluent for Kubernetes to deploy Confluent at the edge—on single node, on servers in a ship, or in an on-premises datacenter
- Using Cluster Linking to seamlessly move data from the edge to Confluent Cloud
- Replacing fragmented data stores with a single DB, MongoDB Realm for great mobile apps
If you’d like to get started using Confluent Cloud, sign up for a free trial and use the code CL60BLOG for an additional $60 of free usage.*
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



From 1 to 1 Million: How Agent Taskflow Built a Scalable AI Future with AWS and Confluent
Agent Taskflow built a multi‑agent AI platform on Confluent Cloud and AWS that can scale from one to one million agents with sub‑30ms latency. This post breaks down their architecture, benchmark results, and why an event‑driven backbone is critical for production agentic AI.



Scaling the Streaming Stack: Introducing the Sell with Confluent Partner Program
Sell with Confluent is our new reseller engagement model, designed to empower partners with streamlined quoting, automated incentives, and scalable growth.