Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Apache Kafka Supports 200K Partitions Per Cluster
In Kafka, a topic can have multiple partitions to which records are distributed. Partitions are the unit of parallelism. In general, more partitions leads to higher throughput. However, there are some factors that one should consider when having more partitions in a Kafka cluster. I am happy to report that the recent Apache Kafka 1.1.0 release has significantly increased the number of partitions that a single Kafka cluster can support from the deployment and the availability perspective.
To understand the improvement, it’s useful to first revisit some of the basics about partition leaders and the controller. First, each partition can have multiple replicas for higher availability and durability. One of the replicas is designated as the leader and all the client requests are served from this lead replica. Second, one of the brokers in the cluster acts as the controller that manages the whole cluster. If a broker fails, the controller is responsible for selecting new leaders for partitions on the failed broker.
The Kafka broker does a controlled shutdown by default to minimize service disruption to clients. A controlled shutdown has the following steps. (1) A SIG_TERM signal is sent to the broker to be shut down. (2) The broker sends a request to the controller to indicate that it’s about to shut down. (3) The controller then changes the partition leaders on this broker to other brokers and persists that information in ZooKeeper. (4) The controller sends the new leader to other brokers. (5) The controller sends a successful reply to the shutting down broker, which finally terminates its process. At this point, there is no impact to the clients since their traffic has already been moved to other brokers. This process is depicted in Figure 1 below. Note that step (4) and (5) can happen in parallel.
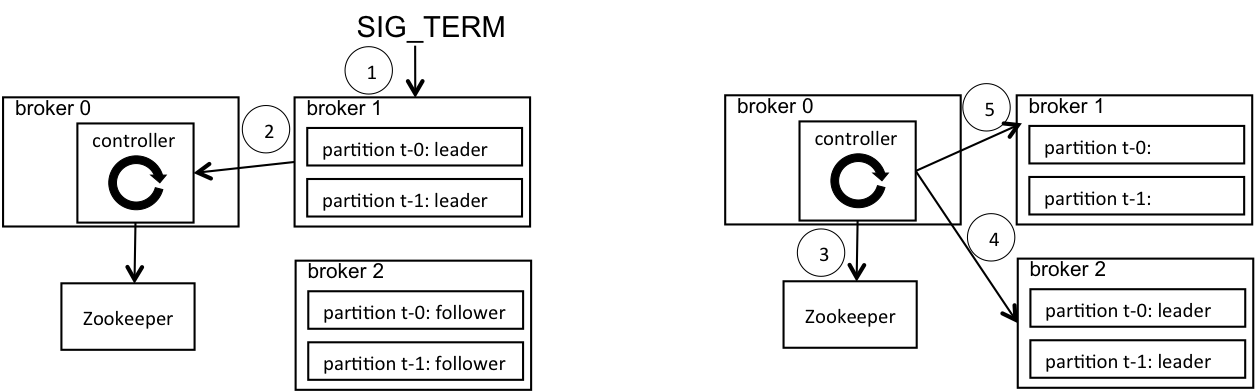
Figure 1. (1) shutdown initiated on broker 1; (2) broker 1 sends controlled shutdown request to controller on broker 0; (3) controller writes new leaders in ZooKeeper; (4) controller sends new leaders to broker 2; (5) controller sends successful reply to broker 1.
Before Kafka 1.1.0, during the controlled shutdown, the controller moves the leaders one partition at a time. For each partition, the controller selects a new leader, writes it to ZooKeeper synchronously and communicates the new leader to other brokers through a remote request. This process has a couple of inefficiencies. First, the synchronous writes to ZooKeeper have higher latency, which slows down the controlled shutdown process. Second, communicating the new leader one partition at a time adds many small remote requests to every broker, which can cause the processing of the new leaders to be delayed.
In Kafka 1.1.0, we made significant improvements in the controller to speed up the controlled shutdown. The first improvement is using the asynchronous API when writing to ZooKeeper. Instead of writing the leader for one partition, waiting for it to complete and then writing another one, the controller submits the leader for multiple partitions to ZooKeeper asynchronously and then waits for them to complete at the end. This allows for request pipelining between the Kafka broker and the ZooKeeper server and reduces the overall latency. The second improvement is that the communication of the new leaders is batched. Instead of one remote request per partition, the controller sends a single remote request with the leader from all affected partitions.
We also made significant improvement in the controller failover time. If the controller goes down, the Kafka cluster automatically elects another broker as the new controller. Before being able to elect the partition leaders, the newly-elected controller has to first reload the state of all partitions in the cluster from ZooKeeper. If the controller has a hard failure, the window in which a partition is unavailable can be as long as the ZooKeeper session expiration time plus the controller state reloading time. So reducing the state reloading time improves the availability in this rare event. Prior to Kafka 1.1.0, the reloading uses the synchronous ZooKeeper API. In Kafka 1.1.0, this is changed to also use the asynchronous API for better latency.
We executed tests to evaluate the performance improvement of the controlled shutdown time and the controller reloading time. For both tests, we set up a 5 node ZooKeeper ensemble on different server racks.
In the first test, we set up a Kafka cluster with 5 brokers on different racks. In that cluster, we created 25,000 topics, each with a single partition and 2 replicas, for a total of 50,000 partitions. So, each broker has 10,000 partitions. We then measured the time to do a controlled shutdown of a broker. The results are shown in the table below.
| kafka 1.0.0 | kafka 1.1.0 | |
| controlled shutdown time | 6.5 minutes | 3 seconds |
A big part of the improvement comes from fixing a logging overhead, which unnecessarily logs all partitions in the cluster every time the leader of a single partition changes. By just fixing the logging overhead, the controlled shutdown time was reduced from 6.5 minutes to 30 seconds. The asynchronous ZooKeeper API change reduced this time further to 3 seconds. These improvements significantly reduce the time to restart a Kafka cluster.
In the second test, we set up another Kafka cluster with 5 brokers and created 2,000 topics, each with 50 partitions and 1 replica. This makes a total of 100,000 partitions in the whole cluster. We then measured the state reloading time of the controller and observed a 100% improvement (the reloading time dropped from 28 seconds in Kafka 1.0.0 to 14 seconds in Kafka 1.1.0).
With those improvements, how many partitions can one expect to support in Kafka? The exact number depends on factors such as the tolerable unavailability window, ZooKeeper latency, broker storage type, etc. As a rule of thumb, we recommend each broker to have up to 4,000 partitions and each cluster to have up to 200,000 partitions. The main reason for the latter cluster-wide limit is to accommodate for the rare event of a hard failure of the controller as we explained earlier. Note that other considerations related to partitions still apply and one may need some additional configuration tuning with more partitions.
The improvement that we made in 1.1.0 is just one step towards our ultimate goal of making Kafka infinitely scalable. We have also made improvements on latency with more partitions in 1.1.0 and will discuss that in a separate blog. In the near future, we plan to make further improvements to support millions of partitions in a Kafka cluster.
The controller improvement work in Kafka 1.1.0 is a true community effort. Over a period of 9 months, people from 6 different organizations helped out and made this happen. Onur Karaman led the original design, did the core implementation and conducted the performance evaluation. Manikumar Reddy, Prasanna Gautam, Ismael Juma, Mickael Maison, Sandor Murakozi, Rajini Sivaram and Ted Yu each contributed some additional implementation or bug fixes. More details can be found in KAFKA-5642 and KAFKA-5027. A big thank you to all the contributors!
This article was originally published by the Apache Kafka Committee on The Apache Software Foundation blog.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent





