Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Kafka Rebalancing Explained
In Apache Kafka®, rebalancing redistributes topic partitions among consumers in a group so work stays balanced and no instance becomes a hotspot. It’s essential for elasticity and fault tolerance—but can briefly pause processing and increase latency if unmanaged.
What Triggers a Rebalance
Rebalancing is triggered by membership changes, session timeouts, and exceeding the maximum poll interval. It is a necessary mechanism to ensure that all partitions are consumed and that the workload is distributed efficiently. It's triggered by changes in the consumer group membership or topic metadata. Common triggers for rebalancing include:
-
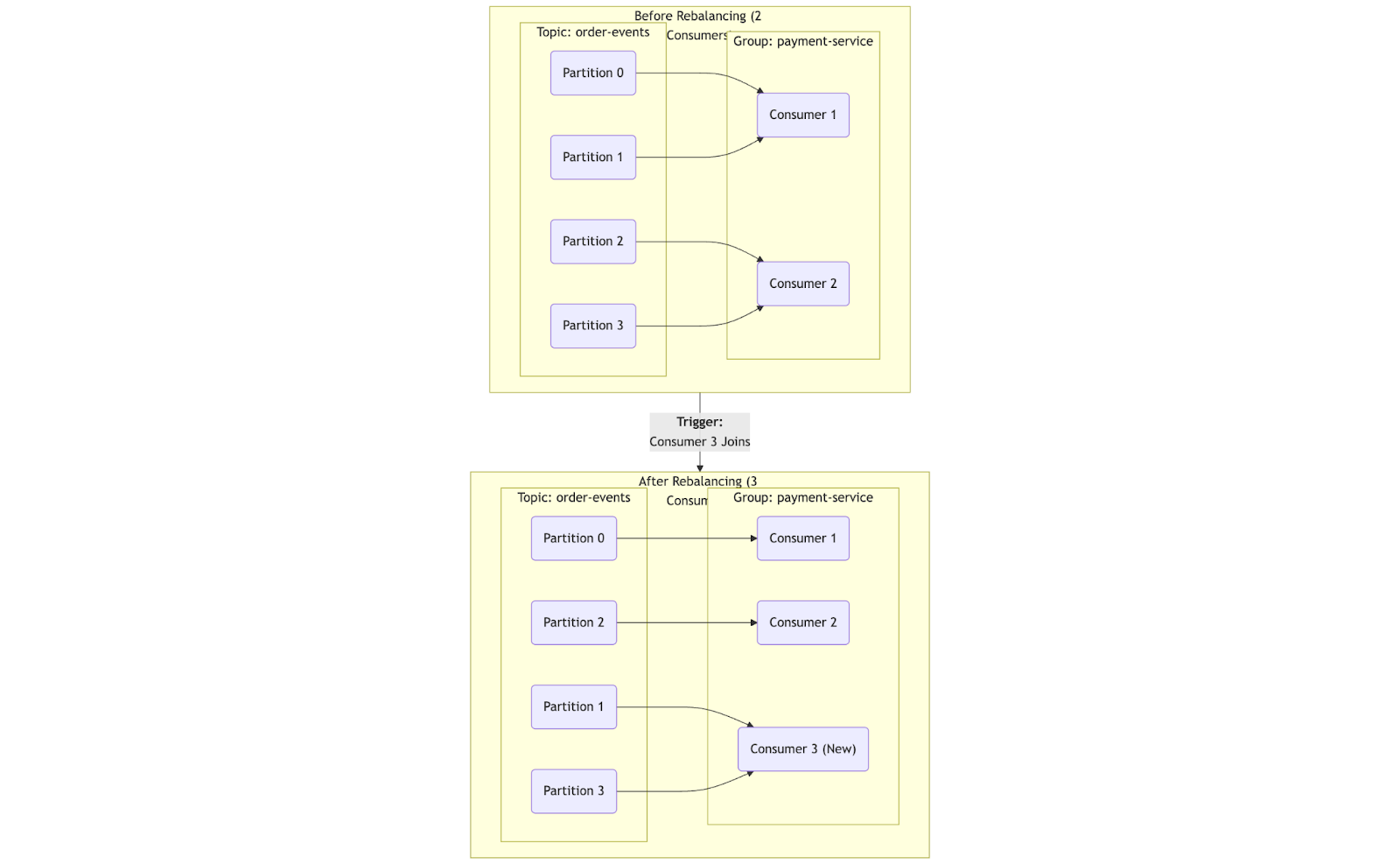
New Consumer Joins the Group: When a new consumer instance starts up and joins an existing consumer group, a rebalance is initiated to assign some partitions from existing members to the new member.
-
Existing Consumer Leaves the Group (or Fails): If a consumer intentionally shuts down or unexpectedly crashes (its session timeout expires), it leaves the group. A rebalance then occurs to redistribute its partitions among the remaining active consumers.
-
Consumer Session Timeout: If a consumer stops sending heartbeats to the Kafka broker for longer than its session.timeout.ms, the broker considers it dead and removes it from the group, triggering a rebalance.
-
Topic Metadata Changes:
-
-
New Partitions Added to a Topic: If you increase the number of partitions for a topic that a consumer group is consuming, a rebalance is triggered to distribute the new partitions among the consumers.
-
Topic Deletion/Creation (less common for rebalance itself, but impacts group state): While not a direct rebalance trigger for existing consumers, it changes the landscape for the group.
-
Group Coordinator Change: If the Kafka broker acting as the group coordinator for a consumer group goes down, a new coordinator is elected, which might trigger a rebalance during the transition.
-
How Kafka Rebalancing Works
Kafka rebalancing is the coordinated process of redistributing topic partitions among the active consumers in a consumer group. This process is managed by a specific Kafka broker known as the Group Coordinator and is triggered whenever a consumer joins or leaves the group, or when the topic's metadata changes (e.g., new partitions are added).
The rebalance works through the following steps:
-
Trigger and Notification: When an event occurs (like a consumer crashing), the Group Coordinator detects it and notifies affected consumers to discover the new rebalance during their periodic heartbeats or via errors (e.g., REBALANCE_IN_PROGRESS) received on requests, prompting them to rejoin the group.
-
Pause and Revoke: All consumers in the group temporarily pause processing, commit their current offsets, and revoke ownership of the partitions they were previously assigned.
-
Rejoin and Leader Election: Each consumer sends a JoinGroup request to the Group Coordinator. The coordinator then elects one of these consumers to be the temporary group leader for this specific rebalance.
-
Partition Assignment: The Group Coordinator provides the leader with a list of all active consumers and all partitions that need to be assigned. The leader uses a defined assignment strategy (like the modern CooperativeStickyAssignor) to create a new assignment plan, mapping each partition to a specific consumer.
-
Sync and Distribute: The leader sends this new assignment plan back to the Group Coordinator. The coordinator then distributes the plan, sending each consumer only the information about which partitions it is now responsible for.
-
Resume Processing: Once consumers receive their new assignments, they resume fetching and processing messages from their newly assigned partitions.
Kafka rebalancing is a critical concern because it can lead to:
-
Operational Disruption and Service Latency: Consumers temporarily pause processing data during rebalancing, impacting real-time data pipelines. This can delay critical business decisions and degrade customer experience.
-
Resource Utilization Spikes and Cloud Costs: Rebalances can cause surges in CPU, memory, and network usage, leading to higher infrastructure costs, especially in cloud environments.
-
Increased Operational Overhead and Debugging Cycles: Frequent rebalances often require manual intervention and troubleshooting, reducing developer productivity.
Why It Matters: Impact on Performance and Costs
Kafka rebalancing, while essential for the dynamic scaling and fault tolerance of consumer groups, comes with significant impacts on both performance and costs. Understanding these impacts is crucial for designing and operating efficient Kafka-based systems.
Common Scenarios Triggering Rebalances:
- Scaling Applications: Adding or removing application instances.
- Application Failures/Restarts: Causing partition redistribution.
- Infrastructure Maintenance: Broker updates or failures.
- Schema/Topic Changes: Expanding or modifying topics.
Resulting challenges that come with need for Kafka rebalancing:
- Erosion of Service Level Agreements (SLAs): Missing latency targets.
- Data Backlogs and Data Staleness: Messages accumulate during pauses.
- "Rebalance Storms" in Dynamic Environments: Cascading rebalances in Kubernetes.
- Complexity in Distributed Systems: Debugging and optimizing rebalancing behavior.
Here is a reference you can go through to understand more about the impacts.
Real-World Scenarios and Challenges
While Kafka's automatic rebalancing mechanism is foundational for fault tolerance and scalability, real-world deployments often expose its limitations, leading to performance bottlenecks, data integrity issues, and operational complexities. Here are some of the scenarios and challenges we run into.
-
Slow Consumers and Processing Hotspots: A consumer might receive a large, complex message or a "poison pill" that takes an unusually long time to process. If this processing time exceeds the configured $max.poll.interval.ms$, the broker assumes the consumer has crashed and evicts it from the group, forcing a rebalance.
-
Stateful Applications (Kafka Streams): Consumers in a stateful application (like a Kafka Streams app) need to rebuild their local state from a changelog topic after a rebalance. This "rehydration" can be very time-consuming for large states, extending the rebalance downtime significantly.
-
Mismatched Configurations: In large organizations, different teams might manage consumers within the same group. If one team deploys a consumer with a more aggressive timeout configuration than the others, it can cause other, slower consumers to be inadvertently kicked out of the group.
-
Processing Lag and Stale Data: The most direct impact is that the consumer group falls behind the producers. For analytics dashboards, financial tickers, or inventory systems, this means the data presented to users becomes stale and unreliable.
-
Cascading Failures: In a microservices architecture, the lag from a rebalancing consumer can starve a downstream service of data. This can cause the downstream service's health checks to fail, leading to its own restarts and triggering a chain reaction of instability across the system.
-
Difficulty in Debugging: Rebalances caused by transient issues like brief network partitions or long garbage collection (GC) pauses are notoriously difficult to debug. Engineers often find themselves chasing "ghost" issues that disappear upon investigation, leading to high operational toil.
Managing and Minimizing Rebalance Impact
While Kafka rebalancing is a necessary mechanism for building elastic systems, it's not a "set it and forget it" feature. Unmanaged rebalances introduce direct risks to business continuity, manifesting as service latency, processing backlogs, and wasted engineering hours.
Championing a proactive approach to managing rebalances transforms them from a frequent source of disruption into a predictable, well-handled operational event. The following strategies provide a framework for achieving this stability and efficiency.
Strategic Capacity Planning and Partitioning
The number of partitions in a Kafka topic dictates the maximum level of parallelism your consumer applications can achieve. Think of it as setting the number of checkout lanes at a supermarket; you can't have more cashiers working than you have lanes open.
The key policy here is to plan for future growth. It's far less disruptive to over-partition a topic modestly during its creation than to add partitions later, as the latter will trigger a rebalance across all consuming applications. Encourage your teams to provision partitions based on their 12-18 month throughput forecasts to avoid this future disruption.
Optimizing Consumer Application Design and Deployment
The way your applications are designed has a direct impact on how they handle rebalances. Promote engineering best practices that prioritize stability:
-
Ensure Graceful Shutdowns: In modern containerized environments like Kubernetes, applications are frequently restarted for deployments or scaling. A consumer application must be designed to shut down cleanly faster than the container's termination grace period (e.g., under 30 seconds). A forceful shutdown is seen as a crash by Kafka, leading to a lengthy and unnecessary rebalance delay.
-
Minimize Stateful Complexity: Applications that hold large amounts of data in memory are the most vulnerable. A rebalance can force them to discard this state and spend minutes—or even hours—rebuilding it, during which time they are not processing any new data. Champion designs that externalize state or can recover it quickly.
Enforcing Configuration Best Practices
Standardizing key consumer configurations prevents most common rebalancing issues. These settings act as guardrails that define how your applications behave within the Kafka ecosystem.
|
Configuration |
Business Implication |
Recommended Policy |
|
session.timeout.ms |
Tolerance for "blips": Defines how long a consumer can be unresponsive before being considered "dead." |
Set high enough (e.g., 45000 ms) to tolerate transient network issues or brief processing stalls, preventing unnecessary rebalances. |
|
max.poll.interval.ms |
Maximum task time: The longest an application can work on a batch of data before the system thinks it's stuck. |
Ensure this is set higher than the longest realistic processing time for a single data batch to avoid false-positive failures. |
|
group.instance.id |
"Reserved Spot" for consumers: Known as Static Membership, this gives a consumer a persistent ID. |
Mandate the use of Static Membership for all critical applications. This allows a consumer to restart (for maintenance or a brief crash) and rejoin without triggering a full group rebalance, dramatically reducing downtime. |
Proactive Monitoring and Alerting
Your organization cannot manage what it cannot see. Moving from a reactive to a proactive stance on rebalancing requires monitoring key performance indicators. Mandate that your operations teams track and alert on:
-
Rebalance Frequency: An increase in the rate of rebalances is a leading indicator of underlying infrastructure or application instability.
-
Consumer Lag: When this number grows, it's a direct sign that your applications are not keeping up with the data being produced—often because they are stuck in a rebalance loop.
Tracking these metrics allows your teams to identify and resolve issues before they escalate into service-impacting incidents.
Learn more about advanced monitoring techniques in our DevRel Course on Kafka Operations.
Advanced Strategies for Kafka Rebalancing
Kafka rebalancing, while an automatic process, can introduce latency and disrupt message processing if not managed effectively. For high-throughput and stateful applications, employing advanced strategies is crucial to minimize its impact and ensure continuous operation.
Embracing Cooperative Rebalancing
A pivotal advancement in Kafka 2.4+, cooperative rebalancing fundamentally changes how consumer groups handle partition reassignments. It eliminates the disruptive "stop-the-world" pauses characteristic of the older eager rebalancing protocol.
In an eager rebalance, all consumers stop processing, give up all their assigned partitions, and wait for the entire reassignment to complete before resuming.
In contrast, the cooperative protocol is a two-phase process where only the specific partitions being moved are affected. This allows unaffected consumers to continue processing without interruption, drastically reducing downtime and application latency.
The Two-Phase Cooperative Process
A cooperative rebalance event unfolds in two small, consecutive rebalances or phases:
-
Phase 1 (Revocation): First, the consumer group leader instructs any consumers that need to give up partitions to revoke them. For example, a consumer that is shutting down will release its partitions. Critically, other consumers are not interrupted and continue processing their own partitions.
-
Phase 2 (Assignment): In the second phase, the now-unowned partitions are assigned to other consumers in the group. Only the consumers receiving new partitions are paused briefly to accept them.
This process ensures that any given partition is only paused once (either during revocation or assignment), and partitions not involved in the move are never paused at all.
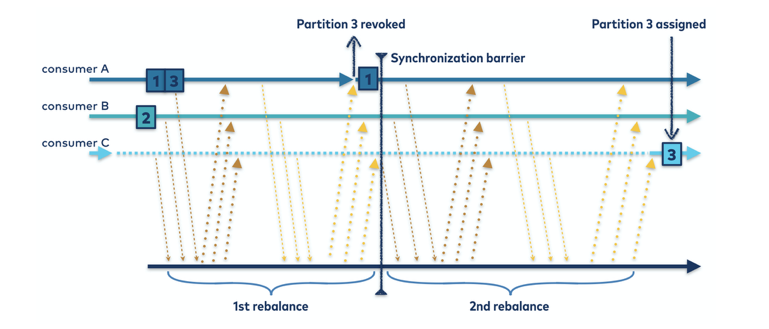
-
Initial State: The group is stable. Consumer A processes Partition 1, Consumer B processes Partition 2, and Consumer C processes Partition 3.
-
1st Rebalance (Revocation Phase): Consumer C leaves the group. As part of its clean shutdown, it revokes its assignment to Partition 3. During this time, Consumer A and Consumer B are completely unaffected and continue processing their respective partitions (shown by the solid lines).
-
Synchronization Barrier: This is the point where the group acknowledges that Partition 3 has been successfully revoked and is now available for assignment.
-
2nd Rebalance (Assignment Phase): The consumer group leader assigns the orphaned Partition 3 to an existing consumer. In this case, it is assigned to Consumer B. Consumer A remains unaffected.
The net result is a seamless transition where processing was only ever paused for Partition 3, first when Consumer C left and second when Consumer B acquired it. This is far more efficient than the old "stop-the-world" method.
Leveraging Static Consumer Group Membership
Static group membership provides a robust mechanism to prevent unnecessary rebalances by allowing a consumer instance to rejoin its group with the same member.id after a temporary disconnection. This is particularly valuable during planned events like rolling restarts or in dynamic environments where consumer instances might be temporarily offline.
-
Unique Instance ID: Assign a stable, unique group.instance.id to each consumer instance. This is ideal for containerized deployments (e.g., Kubernetes StatefulSets) where a stable hostname can serve as the ID.
-
Session Timeout: Carefully configure session.timeout.ms to give the consumer sufficient time to rejoin using its static ID before its partitions are reassigned.
This drastically decreases the frequency of rebalances, especially during deployments or minor outages, thereby enhancing system stability and minimizing operational disruptions.
Optimizing Partition Assignment Strategies
Beyond the defaults, tailoring your partition assignment strategy can yield significant performance benefits, especially for applications with specific requirements like local state or workload distribution.
-
StickyAssignor: Prior to cooperative rebalancing, the StickyAssignor was designed to minimize partition movements, aiming to keep partitions with the same consumer across rebalances. This is beneficial for applications maintaining local state or caches.
-
Custom Partition Assignors: For highly specialized scenarios, implementing a custom PartitionAssignoroffers ultimate control. This allows for bespoke logic to distribute partitions based on criteria such as:
-
Workload Balancing: Distributing partitions according to consumer capacity or current load.
-
Data Locality: Assigning partitions to consumers geographically or network-topologically closer to their data sources.
-
Stateful Applications: Minimizing data re-shuffling for consumers that manage substantial local state.
-
Implementing Graceful Consumer Shutdowns
An abrupt consumer shutdown can trigger a rebalance and potentially lead to duplicate message processing if offsets are not committed. Graceful shutdowns are crucial for maintaining data integrity and minimizing rebalance impact.
-
ConsumerRebalanceListener: Implement the onPartitionsRevoked callback. This crucial step ensures that all outstanding offsets are committed before the partitions are revoked, guaranteeing that the last processed message is properly recorded.
-
Clean Consumer Close: Always invoke consumer.close() to ensure the consumer properly leaves the group and informs the broker.
This prevents unwarranted rebalances, eliminates message duplication, and upholds data consistency.
Fine-Tuning Consumer Configuration Parameters
Several Kafka consumer parameters can be precisely adjusted to influence rebalance behavior and overall consumer group stability.
-
session.timeout.ms: Defines the maximum inactivity period before a broker considers a consumer dead, triggering a rebalance. Increase this if consumers require more time for processing or face high network latency.
-
heartbeat.interval.ms: The frequency at which heartbeats are sent to the group coordinator. Ideally, set this to roughly one-third of session.timeout.ms. Shorter intervals detect failures faster but increase network traffic.
-
max.poll.interval.ms: The maximum allowed time between consecutive poll() calls. If processing a batch exceeds this, the consumer is deemed unresponsive. Adjust based on your message processing duration.
-
max.poll.records: Limits the number of records fetched in a single poll() call. Reducing this can help prevent max.poll.interval.ms timeouts if individual record processing is time-intensive.
-
group.initial.rebalance.delay.ms (Kafka 2.1+): Introduces an initial delay before the group coordinator initiates a rebalance when new members join. This is particularly useful in scenarios where multiple consumers start up concurrently, mitigating "rebalance storms."
By systematically applying these advanced strategies, organizations can significantly mitigate the challenges associated with Kafka rebalancing, enabling more stable, performant, and resilient real-time data processing architectures.
Kafka rebalancing ensures even data distribution among consumer group members, preventing overloads and maintaining performance. Triggered by consumers who join/leave a group or topic changes, this process can temporarily disrupt processing, increase latency, and raise costs. To mitigate these impacts, developers should use strategies like static group membership and careful configuration tuning. Leveraging a fully managed Kafka service like Confluent Cloud can further simplify operations and enhance efficiency.
Learn the difference between hosted vs. managed Kafka when it comes to cost-efficient scaling, keeping brokers alive, and maintaining your Kafka deployment in “Why Hosted Apache Kafka® Leaves You Holding the Bag.”
FAQs
1) What triggers a Kafka consumer group rebalance?
Membership changes (join/leave/timeouts), partition count changes, or a coordinator change. Rebalancing redistributes partitions so each active consumer has work.
2) Why do rebalances cause latency or backlog?
Consumers briefly pause while partitions are revoked and reassigned, which can spike lag and slow downstream apps until the group returns to steady state.
3) How can I reduce rebalance disruption?
Use static membership (group.instance.id) so brief restarts don’t trigger full rebalances, prefer cooperative/Sticky assignors to minimize partition movement, and set timeouts to match real processing times.
4) What should I monitor to stay ahead of issues?
Track rebalance frequency, consumer lag SLO, and time to steady state after a rebalance. Rising trends usually point to sizing, rollout, or timeout policy gaps.