Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Keeping Multiple Databases in Sync Using Kafka Connect and CDC
Microservices architectures have now been widely adopted among developers, and with a great degree of success. However, drawbacks do exist. Data silos can arise where information processed by one microservice is not visible to the other microservice.
The blog post no-more-silos is an excellent introduction to how silos in an application can be bridged with Kafka Connect and CDC. This blog post will review the advantages and disadvantages inherent to moving data from a database using JDBC and CDC, and then move on to explore the real use case of how a legacy bank used Kafka Connect to bridge the silos and keep multiple applications/databases in sync.
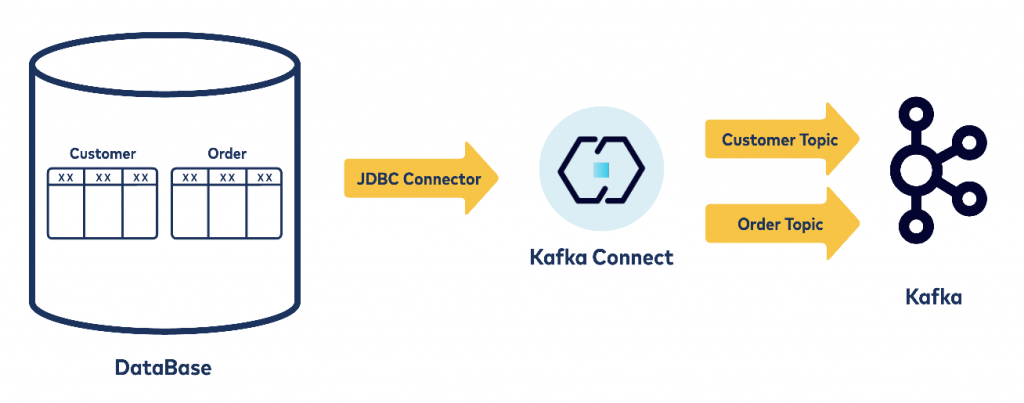
Moving data from a database to Apache Kafka® using JDBC
Kafka Connect users generally possess a good understanding of how connectors can be used to source/sink data in and out of Kafka using a no-code/low-code paradigm. Even so, customers can be unaware of the power and flexibility of Kafka Connect to solve some complex problems.
The JDBC source connector is probably the easiest ways to get data from a database into Kafka. Using this connector in conjunction with Kafka Connect allows you to obtain batches of data using a periodic SQL query, apply any necessary transformations, and then write it into a Kafka topic.
Advantages to using this approach
- This is a no-code solution and all the configurations will go in a property file
- Data can be pulled from the database and reformatted into AVRO, JSON, or ProtoBuf
- This connector creates a schema and registers it with the Schema Registry
- The schema is built using the definition of the SQL Table
Limitations to this approach
- It’s not very scalable. The entire production database (with possibly terabytes of data) cannot be retrieved with SQL queries alone. This is also unacceptable for most OLTP Databases running critical workloads.
- SQL just captures the current state of the database and not the actions that were performed to reach that state (for example: inserted and then updated).
- It doesn’t capture hard deletes, where the record is removed entirely from the database. (Although there are workarounds to this problem, like setting up triggers to delete, or using soft delete instead of hard delete.)
- There isn’t an exact one-to-one mapping between the source table data types and the target data types of Avro, Protobuf, and JSON. This mismatch may require further additional processing by the consumers.
- Running the connector queries puts an additional load on the database, which might not be acceptable on production databases.
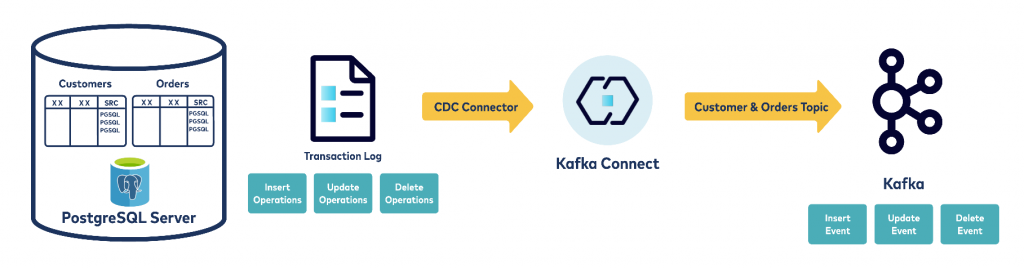
Moving data from a database to Kafka using CDC
Here is a different approach. We know the DBA won’t appreciate Kafka Connect constantly pulling data out of the database using SQL, and a lot of times that database has already been overwhelmed with other more important tasks and there is no room for accommodating Kafka Connect constantly running SQL queries on the database.
Introducing CDC (Change Data Capture), where Kafka Connect is configured to read from the Databases WAL (Write Ahead Log) file. Broadly put, relational databases use a transaction log (also called a binlog or redo log, depending on DB flavor) to which every event in the database is written. Update a row, insert a row, delete a row – it all goes to the database’s transaction log. CDC tools generally work by utilizing this transaction log to extract at very low latency and low impact the events that are occurring on the database (or a schema/table within it).
Advantages to using this approach
- Since this connector reads directly from the WAL, there is no additional load on the database.
- This approach captures all the events that took place to reach a certain state (for example, insert, and then updated).
- For historical events, you can ensure the snapshot was enabled at an earlier time (which could also mean enabling flashback queries or equivalent in your database).
- It captures deletes very elegantly (delete is captured as a delete event).
- The payload captures the before and after values in the same payload along with the operation (update/create/delete), unlike the JDBC connector, which only captures the current state of the data.
Limitations to this approach
- CDC tools are more complex to set up and monitor compared to JDBC connector.
- Some of the complexity stems from the nature of the integration with the relatively low-level log files. This complexity may well be worth it given your requirements, but be aware that you are adding more moving parts to your overall solution.
- For rapid prototyping, CDC can be overkill.
- Often requires administration access to the database for initial setup, which can be a speed bump to rapid prototyping.
- There are cost considerations: many CDC tools are commercial offerings (typically those that work with proprietary sources).
- CDC payloads are complex and they capture a lot of metadata along with the data in the tables. This often makes transformation and extraction difficult.
Keeping two databases in sync using Kafka Connect
Now we’ll dive into a classic use case, a legacy bank attempting to keep up with customers’ needs by continually adding capability to their products.
Online banking transactions have been made available. Customer data from online transactions gets stored on the PostgreSQL database, but over-the-phone transactions are recorded on a different database.
A more traditional approach might have the bank run a nightly job to keep the two databases in sync. This approach has various limitations, primarily:
- The opportunity for a bad user experience, as data is only moved to the other database once a day, and
- To keep two databases in sync, there needs to be two ETL jobs
This problem can be avoided using Kafka Connect. Here is a visualization of the high-level architecture:
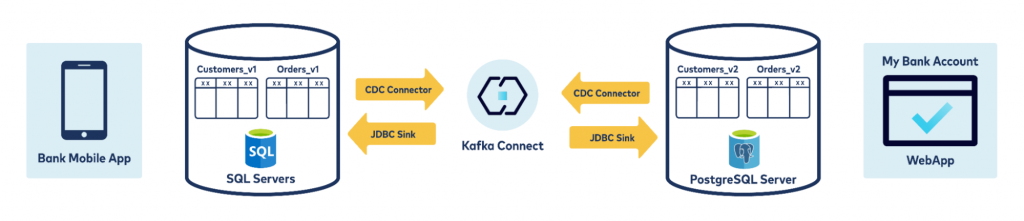
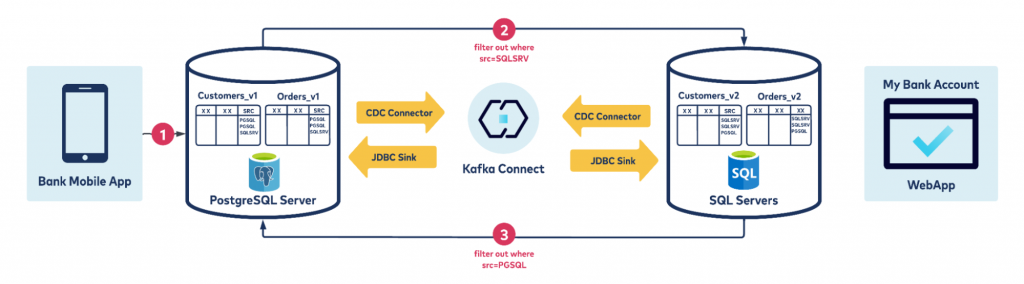
In the above example, data is pulled from the two databases, SQL Server and PostgreSQL, using the Debezium CDC connector. Note that the tables have a similar (but not the same) data model and, of course, different data types specific to each database.
The two sink connectors now pull data from the respective topic and sink to the other database.
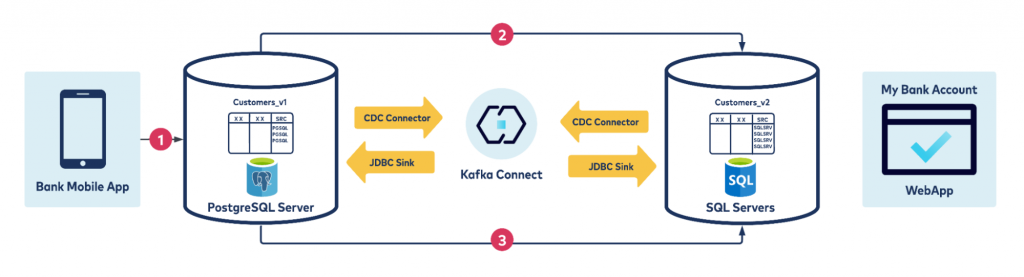
Look at the sequence of events closely, and you’ll see that it will get stuck in an infinite loop. Here is why:
- Mobile App writes to PostgreSQL Server
- CDC Connector for PostgreSQL copies that data to a Kafka topic and the JDBC Sink Connector writes data present on the Kafka topic to SQLServer database
- This insert operation now creates a CDC create event on the SQLServer database and it writes to a Kafka topic, while the JDBC Sink Connector writes data present on the Kafka topic to the Original PostgreSQL resulting in an infinite loop)
You can break this loop using SMT, as described in the next section.
Source code for source and sink connectors can be found here.
Filtering using SMT in the CDC Source connector
This is a familiar problem for anyone who has worked with the Kafka Replicator. Replicator supports active setup in a multi-dc setup, where producers can write to both Kafka clusters (DC-1 and DC-2), and data from one cluster will be copied over to the other as a backup site. This problem is solved with some simple filtering. To enable this Replicator feature, configure provenance.header.enable=true. The replicator then puts the provenance information in the message header after replication. The Replicator will not replicate a message to a destination cluster if the cluster-ID of the destination cluster matches the origin cluster-ID in the provenance header, and the destination topic name matches the origin topic name in the provenance header.
Now that you understand how the Replicator handles active-active setup, you may want to do filtering similar to the Replicator. You may choose to create a column in the database table to show where that record was created and use it to filter records where not required.
For example, you could add an SRC column with a default value of “PGSQL”, to indicate where each record was first created. (This column also becomes important for traceability once we start copying this record to different databases.)
Apply filter operations so the data produced in the current database (PGSql) is copied to the destination (SqlServer), but once copied to the destination it’s not sent back to the initiating DB (PGSql), hence breaking the infinite loop. Here is the sequence of events:
- Mobile App writes to PostgreSQL Server, a record is inserted to a table, and data in the column SRC is set to PGSQL (indicating its origin, as shown in the image above).
- Debezium CDC Source Connector for PostgreSQL copies the event to a topic.
- This source connector has an exclusion filter on SRC = SQLSRV, so only data created by the Mobile App is captured in the Kafka topic.
- JDBC Sink connector writes data on the same topic to SQL Server with SRC=PGSQL.
- This insert to SQLServer is captured by the CDC SQLServer connector. However since there is an exclusion filter of SRC=PGSQL this record is ignored.
Here is the snippet of PostgreSQL CDC Source connector, which filters out anything produced by the other database. (SRC == “SQLSRV”),
"name": "postgres-cdc-azure-src",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "oncloud.postgres.database.azure.com",
"transforms": "unwrap, filterPostGres, ExtractField, TimestampConverter",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.filterPostGres.type": "io.confluent.connect.transforms.Filter$Value",
"transforms.filterPostGres.filter.condition": "$[?(@.SRC == \"SQLSRV\")]",
"transforms.filterPostGres.filter.type": "exclude",
"transforms.filterPostGres.missing.or.null.behavior": "include",
We implemented this filter operation using SMT (single message transform); here is the list of all available SMT with a detailed explanation. You also need to account for the case when the WebApp writes to SQLServer. The source code for source and sink connectors can be found here.
Keeping three databases in sync using CDC and JDBC Sink Connectors
Now that you know keeping two databases in sync is possible using Kafka Connect, you can implement a three-way database sync.
The bank now wants to offer customers a new capability: smartwatch/credit card payments. Assuming this data is stored in a MySql database, you now have to keep three databases in sync.
To implement this, you will need two more connectors and a little more filtering: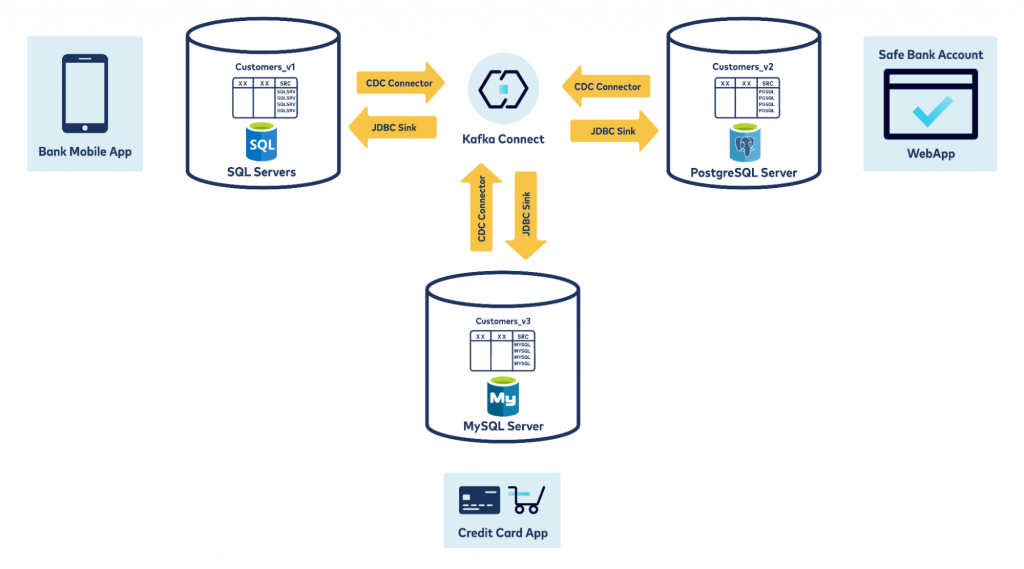
Filtering on source connector and topics
The same concept applies whether you need to keep two, three, or more databases in sync. Here is a diagram of events with three databases:
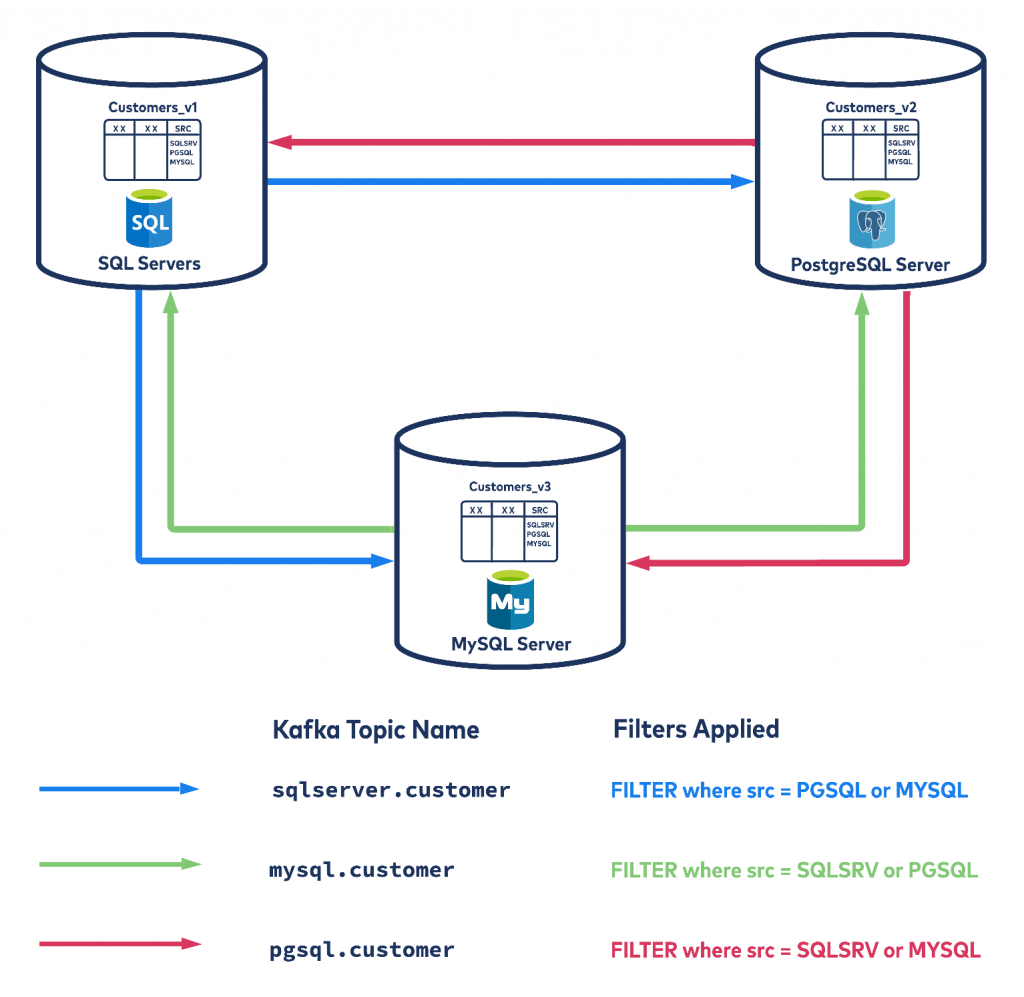
You need just one topic per database and table, so to capture changes on customers table on SQL Server you will also only need one topic sqlserver.customer, which can be sinked to anywhere using the available connectors.
In summary
You have now reviewed a real-life business problem, where Kafka Connect helped a bank keep multiple applications/databases in sync for a better customer experience.
Superior application architecture provides the flexibility to share data created by your application with other applications while supporting data evolution. Kafka Connect, with the use of AVRO, solves these problems and offers various benefits, such as:
- Flexibility: The same code will work for almost any database or data warehouse, and supports schema evolution and backward compatibility.
- Loose Coupling: None of the downstream applications should be impacted by the changing source application.
- Scalability: In case of load increases, scaling is addressed by Kafka Connect.
- High Availability: If a node or application crashes, it provides automatic failover.
- Data Integrity: Data is conforming to a published schema using Schema Registry.
- Monitoring: There are tools readily available to monitor data movement in a production environment.
Trying to keep multiple databases in sync can be tricky. This table includes a concise list of some of the problems you may encounter, and the solution to those problems.
| Problem | Solution |
| Databases use specific data types. For example: date, datetime, smallint, money |
Use SMT to cast such database-specific datatypes to something supported by AVRO. |
| The destination database data model is different. | KConnect supports transformation; also we encourage inserting data in insert/upsert mode. |
| The parent table should always insert a record before the child table in case of referential integrity between multiple tables. | This is a hard problem to solve and has many approaches. The ideal approach would be to introduce some sort of delay for child tables, but this solution is error-prone. A good solution is using ksqlDB to write to a topic only after the parent record is already present. |
How to get started
Sample code is available in the git repo. This environment is complex to set up, as you need to set up two or maybe even three databases in CDC mode. You can take a more straightforward approach for a PoC where you can use any database (MySql, in this example) and create three tables in different schemas (Oracle, Postgres, SQLserver) to mimic the three databases. You can also replace the CDC source connector with A JDBC source connector if you want to avoid CDC completely.
Here is an example:
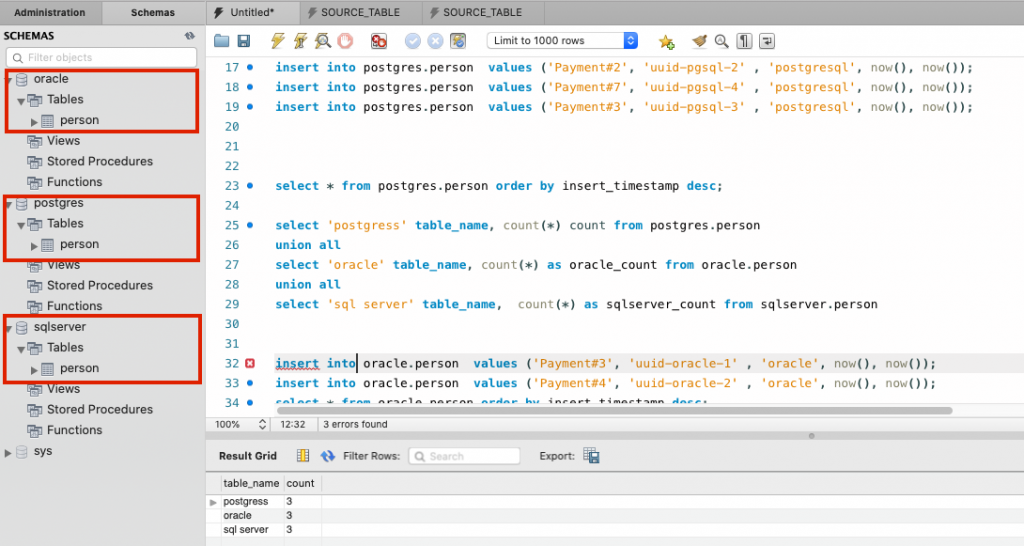
Source Code for this setup can be found here.
Further reading
Here are some more recommended readings that you may find useful. Check out why stream processing is better than batch processing(ETL), and how CDC is a better way of fetching data from a database.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent





