Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Apache Kafka Native MQTT at Scale with Confluent Cloud and Waterstream
With billions of Internet of Things (IoT) devices, achieving real-time interoperability has become a major challenge. Together, Confluent, Waterstream, and MQTT are accelerating Industry 4.0 with new Industrial IoT (IIoT) and consumer IoT (CIoT) use cases, revolutionizing the way companies manufacture and use machines, devices, and other connected components.
This blog post takes a look at IoT, its relation to the MQTT standard, and options for integrating MQTT with Apache Kafka® and Confluent Cloud, including a new Kafka-native implementation of an MQTT broker.
Use Cases for IoT and event streaming with Apache Kafka
Let’s first overview a variety of CIoT and IIoT/Industry 4.0 examples to see how it works
- Lyft: Correlation of events from drivers, guests, and backend systems like CRM, weather service, traffic information, and the payment provider to calculate routes, estimated time of arrival, estimated cost, and more
- Audi: Connected car infrastructure for real-time ingestion, processing, and analysis of events for after-sales and other customer-related use cases
- Bosch Power Tools: Real-time alerting and new real-time dashboards that merge and present data from manufacturing plants, dealers, tool owners, and other sources across the company.
- Deutsche Bahn: Connectivity to different technologies, such as messaging systems, databases, and files to correlate events for calculation and display of real-time train information, delays, and cancellations on mobile apps, train station displays, and other interfaces
- E.ON: IoT cloud platform to integrate and correlate data from internal applications, smart homes, smart grids, and partner systems, providing a real-time infrastructure for energy distribution
- Severstal: Real-time analytics at the edge for quality improvements and predictive maintenance in factory production lines.
All of these share the following requirements:
- Real-time data integration and data processing
- Mission-critical, 24/7 deployments without downtime
- Large-scale processing of events from hundreds of thousands or even millions of users and machine and device interfaces
These examples use different architectures and infrastructures for edge computing, hybrid deployments, and cloud computing. Kafka and its ecosystem are the heart of all these deployments. We see this trend across many industries, including automotive, manufacturing, energy, oil and gas, logistics, and more.
To understand the deployment architecture for Kafka and IoT in more detail, please check out Architecture Patterns for Distributed, Hybrid, Edge, and Global Apache Kafka Deployments and Apache Kafka is the New Black at the Edge in Industrial IoT, Logistics, and Retailing. For a general overview of use cases and architectures for event streaming in IoT use cases, please check out the following presentation: Introduction to IoT with Apache Kafka and Event Streaming.Standards and Protocols for IoT Scenarios.
Standards and protocols for IoT scenarios
Several standards exist to support IoT projects:
- MQTT: The most relevant standard supporting plenty of use cases in CIoT and IIoT. Built for unreliable networks and millions of devices.
- OPC-UA: For Industrial IoT only. Most new machines, devices, and middleware in IIoT environments support this standard.
- HTTP: Synchronous communication with REST web services. Well understood, simple, and supported by almost all frameworks and products. Not an IoT standard, but often used in IoT projects if limited latency and scalability requirements are given.
- WebSocket: A modern, full-duplex communication channel over a single TCP connection. Used more and more in CIoT for real-time and scalable applications to replace HTTP communications, which do not scale and perform well in large deployments.
- Syslog, SNMP, and more: While standards like MQTT and OPC-UA are built to solve specific IoT challenges, most infrastructures complement these standards with other established technologies for logging, monitoring, and troubleshooting.
MQTT is one of the most important standards for IoT projects, both in IIoT and CIoT.
MQTT and Apache Kafka
Most IoT projects combine MQTT and Kafka for good reasons. The high-level architecture typically looks something like this:
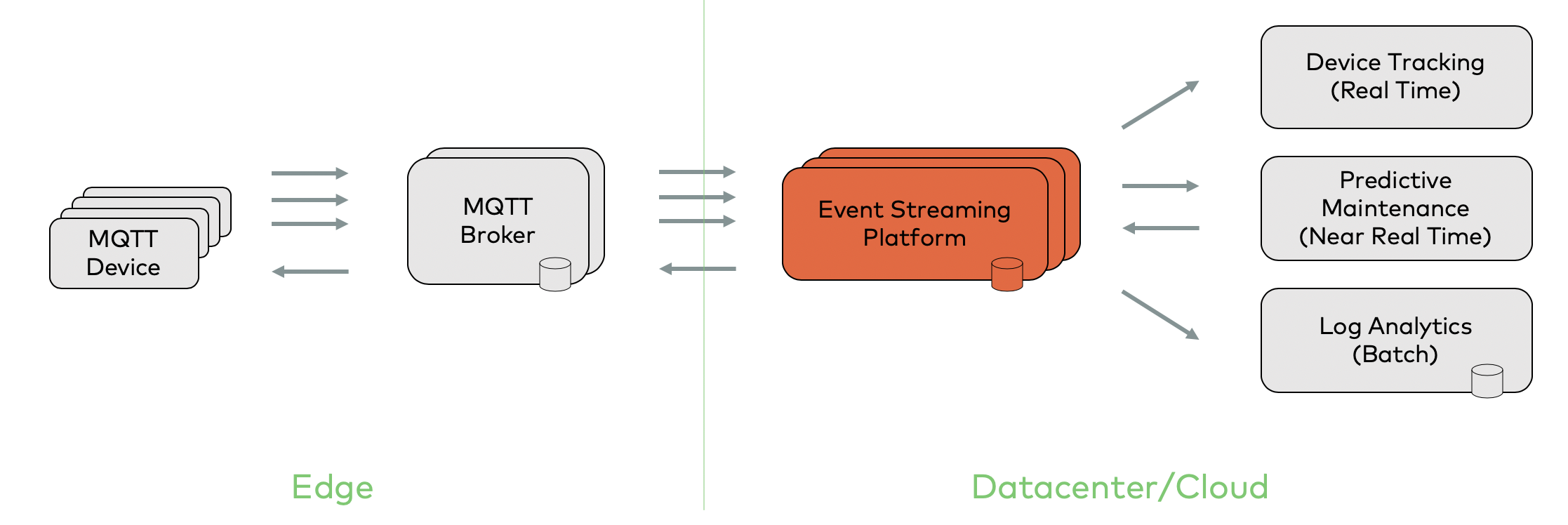
From a technical perspective, MQTT is just another producer and/or consumer. Kafka decouples different clients, applications, and backends from each other.
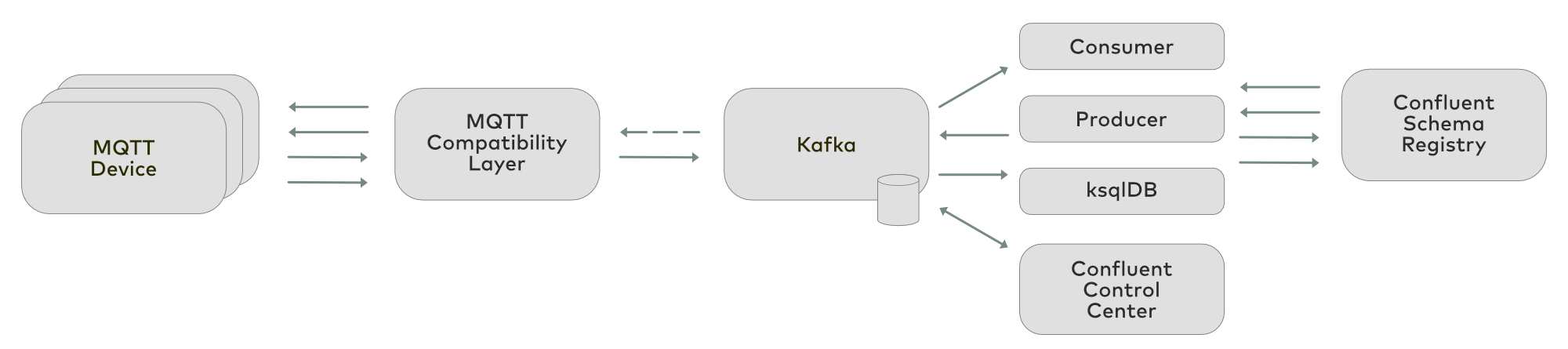
The pros and cons of MQTT (as IoT standard technology) and the pros and cons of Kafka (as the de facto standard for an event streaming platform) map to one another in a very complementary way, making it clear why both are combined so often.
Pros and cons of MQTT
MQTT pros:
- Lightweight
- Supports all programming languages
- Built for poor connectivity/high-latency scenarios (e.g., mobile networks)
- High scalability and availability*
- ISO standard
- Most popular IoT protocol
MQTT cons:
- Only pub/sub, not stream processing
- Asynchronous processing (clients can be offline for a long time)
- No reprocessing of events
Pros and cons of Apache Kafka (from an IoT perspective)
Kafka pros
- Stream processing, not just pub/sub
- High throughput
- Large scale
- High availability
- Long-term storage and buffering
- Reprocessing of events
- Strong integration other enterprise technology
Kafka cons
- Not built for tens of thousands connections
- Requires stable network and good infrastructure
- No IoT-specific features like Keep Alive, Last Will, or Testament
As you can see, MQTT and Kafka work together perfectly. You can learn more about this combination in Best Practices for Streaming IoT Data with MQTT and Apache Kafka.
Predictive maintenance in real time for 100,000 connected cars with MQTT and Kafka
MQTT and event streaming combined allow real-time integration, processing, and analytics of IoT data. A use case for MQTT and Kafka can look similar to this:
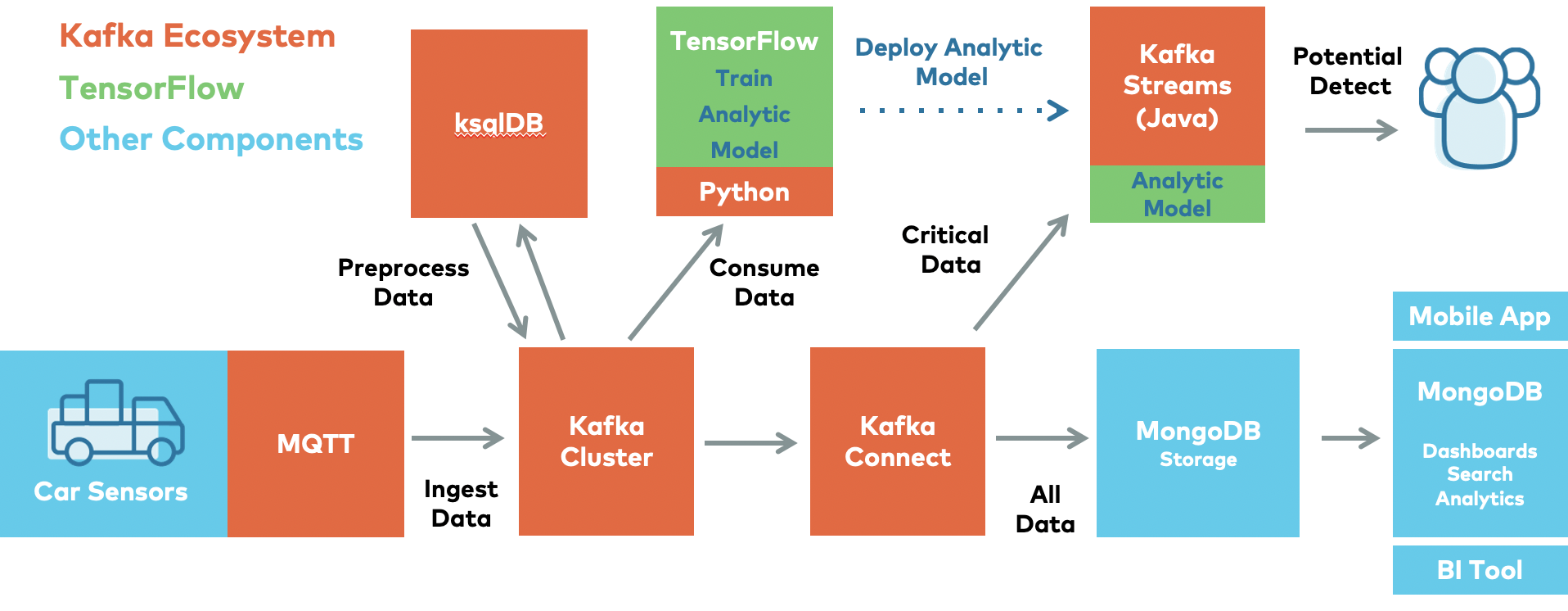
In this example, we see a real-time integration pipeline to stream data from millions of connected cars via MQTT to the event streaming platform for streaming ETL, machine learning, digital twin, big data analytics, and other use cases.
MQTT integration options for Apache Kafka, Confluent Platform, and Confluent Cloud
So what are the different options for MQTT implementation and integration with Apache Kafka?
Plenty of integration options exist for MQTT to Kafka integration:
- Kafka Connect + Confluent MQTT source and sink connectors + MQTT broker: A common option. Leverage the benefits of Kafka Connect for bidirectional communication with any standard compliant MQTT broker, including the reference implementation Mosquitto (for Hello World and non-critical deployments) or a scalable, battle-tested solution like HiveMQ
- Confluent MQTT Proxy: A very lightweight option allowing direct integration between MQTT devices and a Kafka cluster. No need for an MQTT broker at all. Drawbacks are the limited feature set and (at the time of this writing) no bidirectional communication but just ingestion from MQTT to Kafka.
- Vendor-specific integration: Some vendors provide their own integrations between their MQTT broker and Kafka. For instance, HiveMQ has its own Kafka plugin for bidirectional communication.
- Kafka-native implementation of MQTT: This option does not require integration because the MQTT broker is running as a Kafka application connecting to Kafka via native Kafka consumers and producers.
The trade-offs between using Kafka Connect and MQTT Broker, Confluent MQTT Proxy, or the Confluent REST Proxy are discussed in more detail in this presentation: Processing IoT Data from End to End with MQTT and Apache Kafka.
Finding the right option for your problem and use case
When evaluating your MQTT solution in conjunction with Kafka, there are many factors to consider as many offerings have limitations. For instance, cloud offerings from the major cloud providers typically are not fully compliant MQTT brokers, have limited feature sets, and have limited scalability and performance characteristics.
Here are a few other aspects to check for:
- MQTT compliance
- Support of MQTT version 3.x or 5.x (the two main versions used in the industry)
- Full implementation or a limited feature set that misses any of the following: Quality of Service (QoS), retained messages, Last Will and Testament, Persistent Sessions, Keep Alive, Client Take-Over, etc.
- Uni or bidirectional communication between MQTT and Kafka
- Security features like authentication, authorization, and encryption
- Kafka integration (connector, plugin, and Kafka native)
For large-scale use cases, a dedicated, full MQTT broker implementation is the best option. The key question to ask yourself is whether you want to deploy a separate MQTT cluster or use a Kafka-native implementation.
Streaming Machine Learning at Scale from 100,000 IoT Devices with HiveMQ, Confluent, and TensorFlow is an example of a large-scale deployment with separated clusters for MQTT and Kafka. This architecture is well understood and works well in the real world.
Having said this, let’s now focus on a new option to evaluate: an implementation of MQTT on top of Kafka. This adds one more option to compare to find the right architecture for your use case. The key advantage of this option is that you have to operate, maintain, and monitor just one distributed infrastructure for your mission-critical IoT projects because the MQTT broker runs Kafka natively as a Kafka Streams application, with all the benefits of Kafka under the hood (like high availability, high throughput, low latency, etc).
Introducing Waterstream: A Kafka-native MQTT broker
Now you have a new option: Waterstream, which is Confluent verified and can turn your Kafka cluster into a full-featured MQTT broker. It works as a thin, bidirectional layer between Kafka and IoT devices. It doesn’t have intermediate persistence, and messages from MQTT clients are immediately written to Kafka and vice versa. As soon as the message is retrieved from Kafka, it’s sent to MQTT clients. All the necessary MQTT state (i.e., subscriptions, at-least-once and exactly-once QoS message status, and retained messages) is also stored in Kafka—no need for additional storage.
Besides required MQTT functionality, Waterstream offers optional features (such as WebSockets) and features that are beyond the scope of MQTT specification (such as X.509 authentication and flexible authorization rules based on X.509 identity).
Waterstream scales out linearly. For most operations, its nodes don’t depend on each other, so you can add more machines if you have more clients to handle. With 5–10 machines, it can handle hundreds of thousands of clients (see scalability and performance for more details).
The reference architecture for Kafka-based IoT infrastructure with Waterstream might look like this:
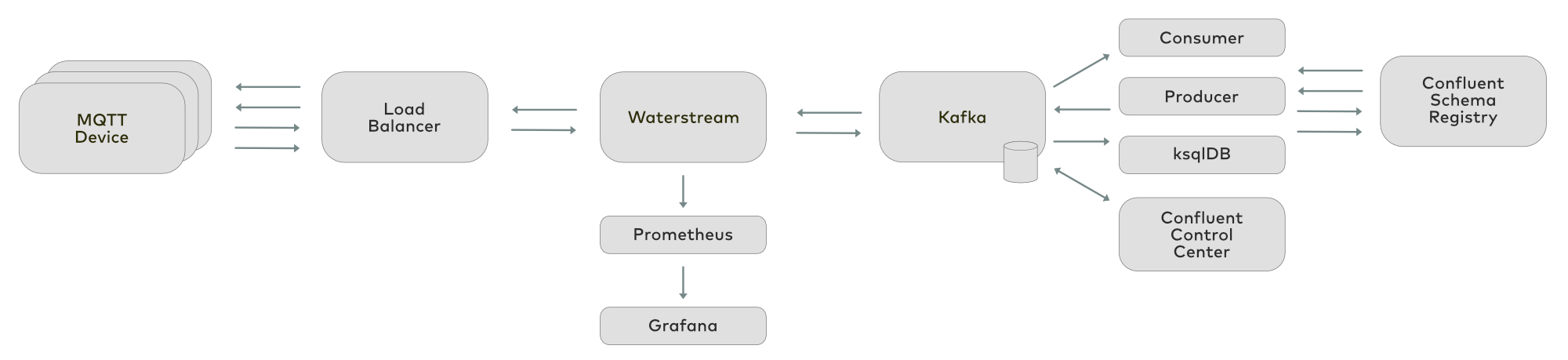
Devices send the telemetry to Waterstream through the load balancer. Waterstream nodes can be added or removed dynamically according to the current needs. Then this data is transferred to the Kafka topic and can be consumed by any Kafka tool—this may be custom code using a Kafka consumer, Kafka Connect, or a Kafka Streams application. ksqlDB can be leveraged to enrich the data as it arrives and feed some suggestions back to the devices. An example is alerting you of the nearest gas stations when you’re in a moving vehicle with low fuel. Producers (like some kind of management console) can send commands to the devices through Kafka and Waterstream.
Of the pre-existing solutions, Confluent MQTT Proxy is closest to Waterstream. But unlike MQTT Proxy, Waterstream supports bidirectional communication and persists MQTT sessions. Therefore, if an MQTT client reconnects to Waterstream after a single node failure, then the load balancer can send the request to any other healthy node, and that node can pick an unfinished message transmission with QoS at least once or exactly-once.
Compared to the MQTT Kafka connector, Waterstream has fewer moving parts—it doesn’t need a separately deployed, external MQTT broker because it is a full-featured broker itself (combined with Kafka, of course). Also, you wouldn’t need to deal with message loops or the unfortunate situation of a topic mapping a message from Kafka sent to an MQTT topic from which the connector reads again and sends back in the same Kafka topic.
What are the best use cases for Waterstream? The obvious one is tight integration of your devices with Kafka. A thin layer between Kafka and MQTT Waterstream ensures the small latency on MQTT to a Kafka path. Another reason to use Waterstream is simpler deployment. As its nodes are stateless, you have less moving parts to configure and you can easily scale out or scale in as your traffic goes up or down. Nodes don’t depend on each other for message processing, so you can scale it horizontally to handle typical IoT use cases, which need hundreds of thousands of devices.
Nothing comes without a cost, of course. All MQTT communication in Waterstream flows through Kafka, even if it’s supposed to go from one device to another, and there is no additional processing in centralized facilities like ksqlDB as expected. This means it takes longer for the message roundtrip. If you only need to send a message from one device to another, without integration with Kafka, Waterstream may have higher latency compared to traditional solutions.
How Waterstream works
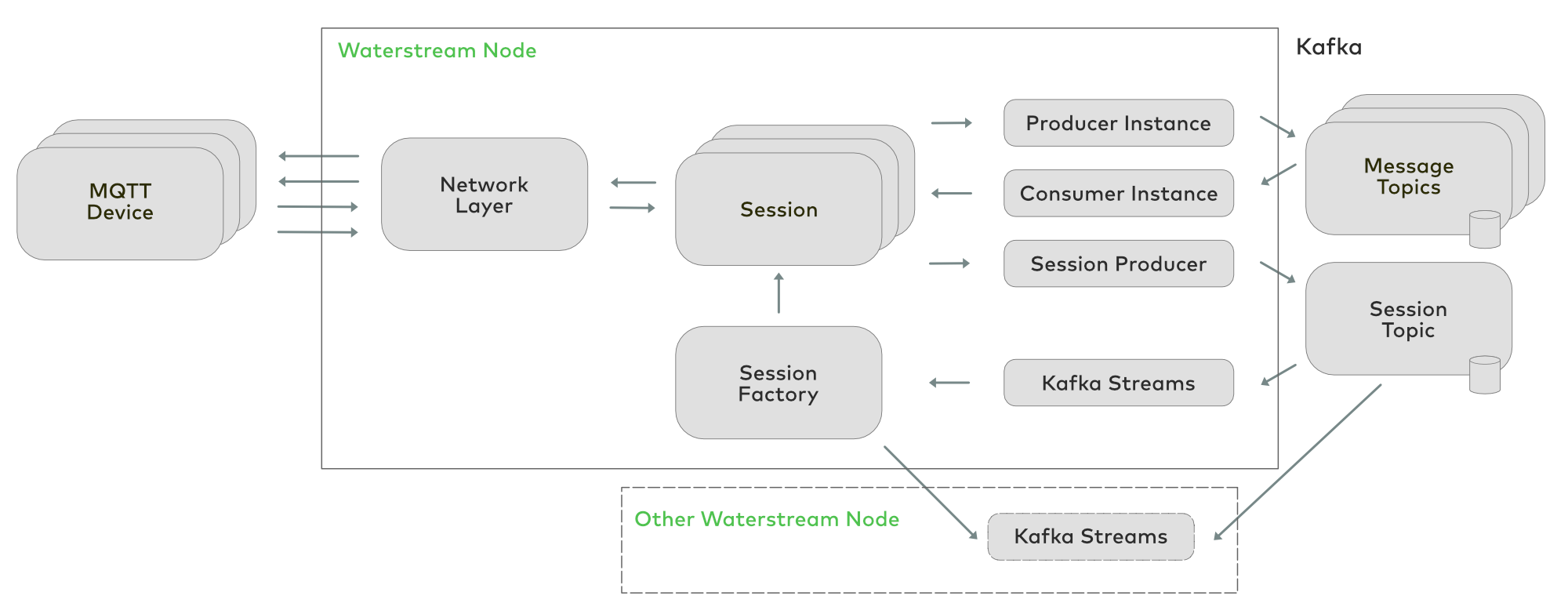
According to configuration, Waterstream reads/writes MQTT messages from/to one or many Kafka topics using the MQTT topic name as the Kafka message key and the MQTT message payload as the Kafka message value. For each MQTT connection, an in-memory session is maintained, which keeps track of stateful aspects, such as at-least-once or exactly-once message transmission status, subscriptions, Last Will message, offsets of the last consumed messages, etc.
If the session is persistent (the MQTT client flags the “Clean Session” as false), then the changes are persisted into the session topic in Kafka. This makes it possible to hand the session over to another Waterstream instance if the current one fails or if the MQTT client reconnects and the load balancer directs it to the other instance. When the client connects again, the Kafka Streams component picks the latest session state from this node or another one. Persisting the MQTT state in Kafka and reading it back in case of failure allows MQTT clients to achieve end-to-end, exactly-once integration if you use QoS 2 for publishing the messages and subscribing to the topics, in which case, the reconnected, unfinished MQTT message will finish publishing and any missed messages from the subscriptions will be delivered in order.
Since topic naming rules in Kafka are much stricter than in MQTT, not every MQTT topic may map to a Kafka topic. Therefore, an MQTT topic is represented by a message key in Kafka, and a single Kafka topic may contain messages for multiple MQTT topics. Waterstream supports topic mapping rules with MQTT-style wildcards.
Beyond that, a default Kafka topic must be configured in Waterstream, which contains messages from topics that don’t match any of the mapping rules. For example, with the rules kafkaTopic1:cars/speed/+ and kafkaTopic2:cars/#, the MQTT topic cars/speed/1 is mapped to kafkaTopic1, cars/location/1, then to kafkaTopic2, cars/speed/1/2, trains/speed/1, and the default topic.
Whenever an MQTT client subscribes to some MQTT topic’s pattern, the Kafka consumer in the corresponding Waterstream node starts reading from the Kafka topics that are necessary to cover this pattern. Using the mapping from our previous example, if the client subscribes to cars/speed/+, then only kafkaTopics1 is consumed. But if it subscribes to cars/#, then both kafkaTopic1 and kafkaTopic2 are consumed, and if trains/#, then only the default topic.
Some caveats for an MQTT subscription still remain. If a Waterstream node consumes some Kafka topic, it has to read messages from all partitions, because from the MQTT topic wildcard (such as car/speed/+ or trains/#), you can’t always tell which exact Kafka keys to watch. MQTT topics are dynamic; they may come and go as the new messages arrive, so Waterstream should check every new message in the Kafka topics that match the MQTT subscription pattern. Hence, MQTT topics, which are meant to be consumed separately, should be mapped to the different Kafka topics. This is the key principle for configuring MQTT to a Kafka topic mapping in order to achieve the best possible read performance.
Scalability and performance
We want to evaluate how many clients with a reasonable IoT message rate that Waterstream can support per node and how well it scales out to handle a larger number of clients. To simulate the load, we’ve developed a simple but flexible tool that is easy to run in different cloud environments (Kubernetes, GCP, etc.). It is configured to publish one message with a random text every 10 seconds. Message length is randomly picked between 400 and 600 bytes.
Both Waterstream and the load simulator are deployed on GCP—Waterstream on n1-standard-1 and n1-standard-2 (2 CPU, 7.5 GB RAM) machines, and the load simulator on n1-standard-1 (1 CPU, 3.75 GB RAM) machines. For more details, check out the following:
For Kafka, we used Confluent Cloud, which is the easiest way to get it running and operated without any efforts on our side. It comes with tools to visualize and monitor the underlying topics and data flow from producers to consumers.
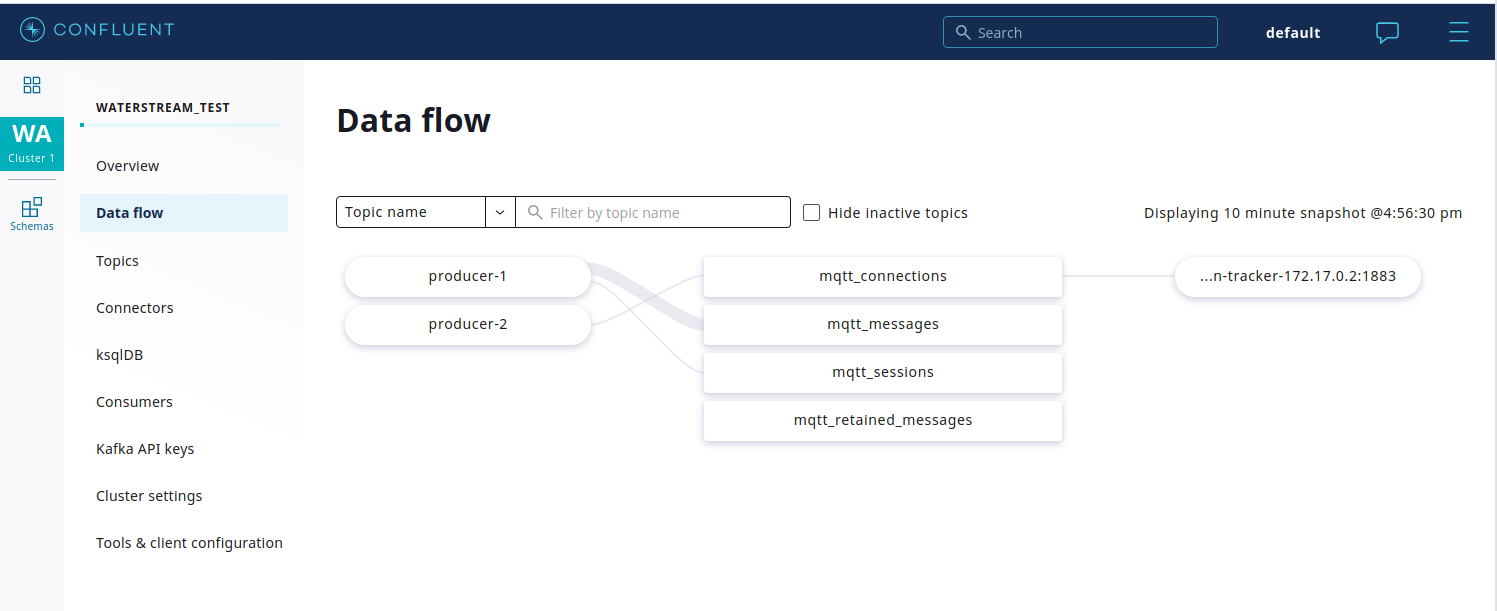
With each Waterstream deployment configuration, we gradually increase client count in the load simulator and watch the Grafana dashboard. Looking at the connections count and Kafka publish rate, we’ll decide if the current Waterstream configuration is sufficient for such a number of clients.
| Waterstream | Load simulator | Results | |||
| Nodes Count | Heap | Nodes Count | Clients Per Node | Successful Connections | Kafka Publish Rate (msg/sec) |
| 3 | 6000m | 10 | 20K | 190K | 19K |
| 5 | 6000m | 10 | 20K | 200K | 20K |
| 5 | 6000m | 20 | 20K | 400K | 40K |
| 5 | 6000m | 30 | 20K | 579K | 50K |
| 10 | 6000m | 30 | 20K | 600K | 60K |
| 10 | 6000m | 40 | 20K | 800K | 80K |
| 10 | 6000m | 50 | 20K | 993K | 97K |
| 12 | 6000m | 50 | 20K | 1,000K | 100K |
| 12 | 6000m | 60 | 20K | 1,180K | 110K |
The results in green indicate cases where the system handled the load well. Those in yellow shows where the system was on the verge of falling behind (up to 5% fewer connections than expected).
After building a graph from this data, we see nearly linear scalability:
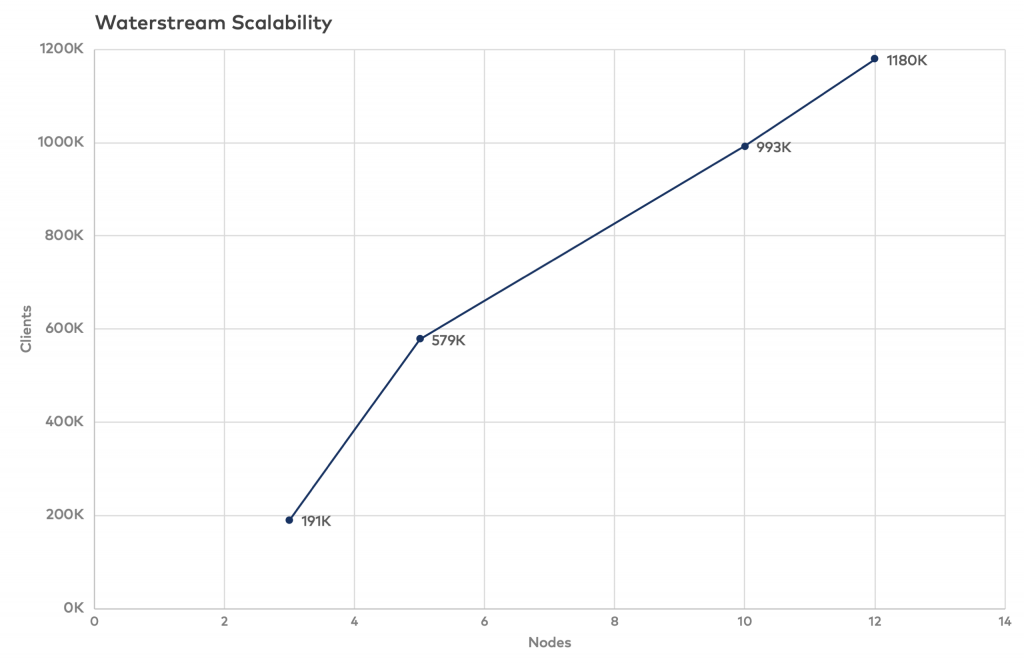
During last evaluations, 12 n1-standard-2 nodes successfully handled 1.18 million of simulated devices. That means that one n1-standard-2 node can handle about 98,000 MQTT connections.
MQTT, Waterstream, and Kafka at the edge
While Waterstream and Kafka scale out well to support large loads in big datacenters, they can also scale down to tiny deployments at the edge. You can have a smaller deployment closer to the devices, such as in a factory building). This reduces the latency between the devices and Waterstream, helps to survive temporary internet connection outages, and reduces storage costs. You may not need to send all the data to the datacenter, just some pre-filtered or pre-aggregated records. Confluent Replicator can pump the data from these small deployments at the edge to the bigger cluster, which could be managed by Confluent Cloud.
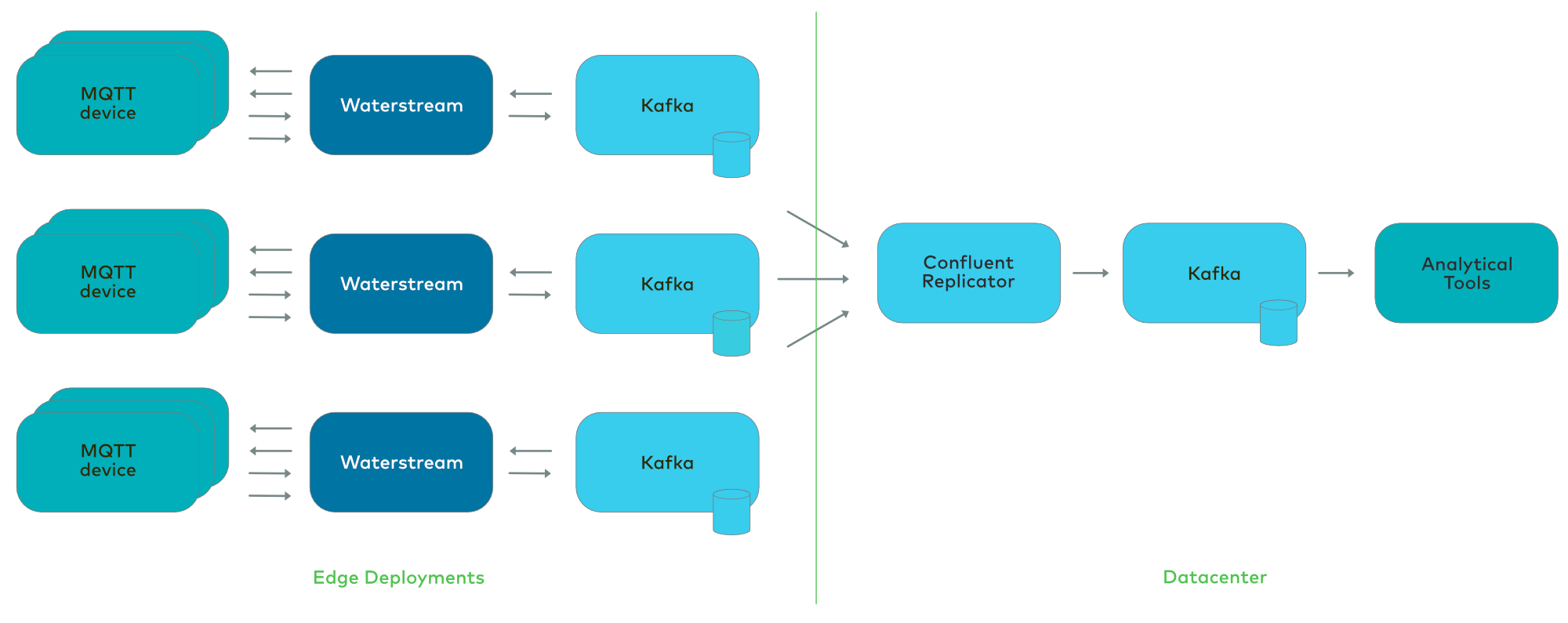
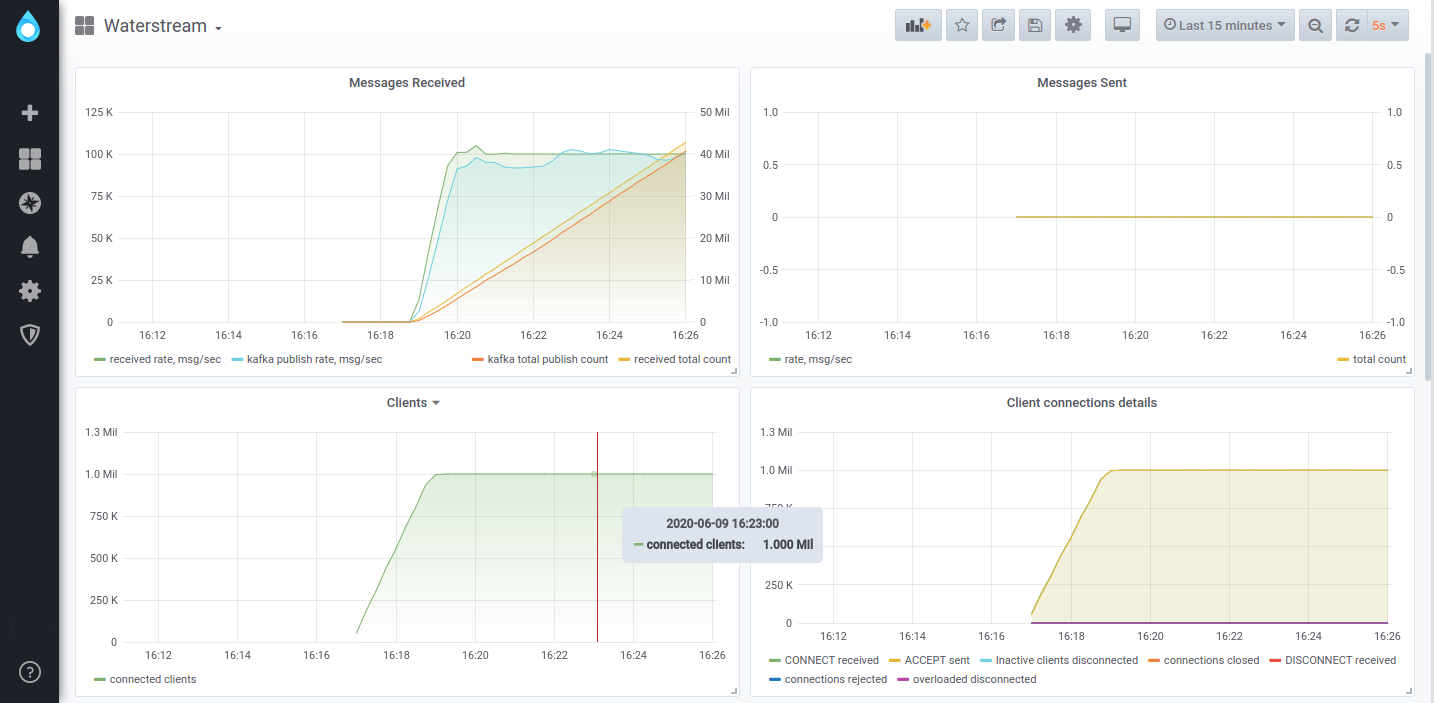
To take it to the extreme, we’ve tested a deployment on a single n1-standard-1 node in GCP (1 CPU, 3.7 GB RAM), which contains Apache ZooKeeper, Kafka, and Waterstream. The same tool used for generating the load for the scalability tests was used, but with only one node simulating 20,000 clients, each sending one message per every 10 seconds. Of those clients, 14,000 managed to connect successfully, with Waterstream writing 1,400 messages/second to Kafka. Below is a Grafana dashboard running locally, scraping data from Waterstream, which runs on a GCP node.
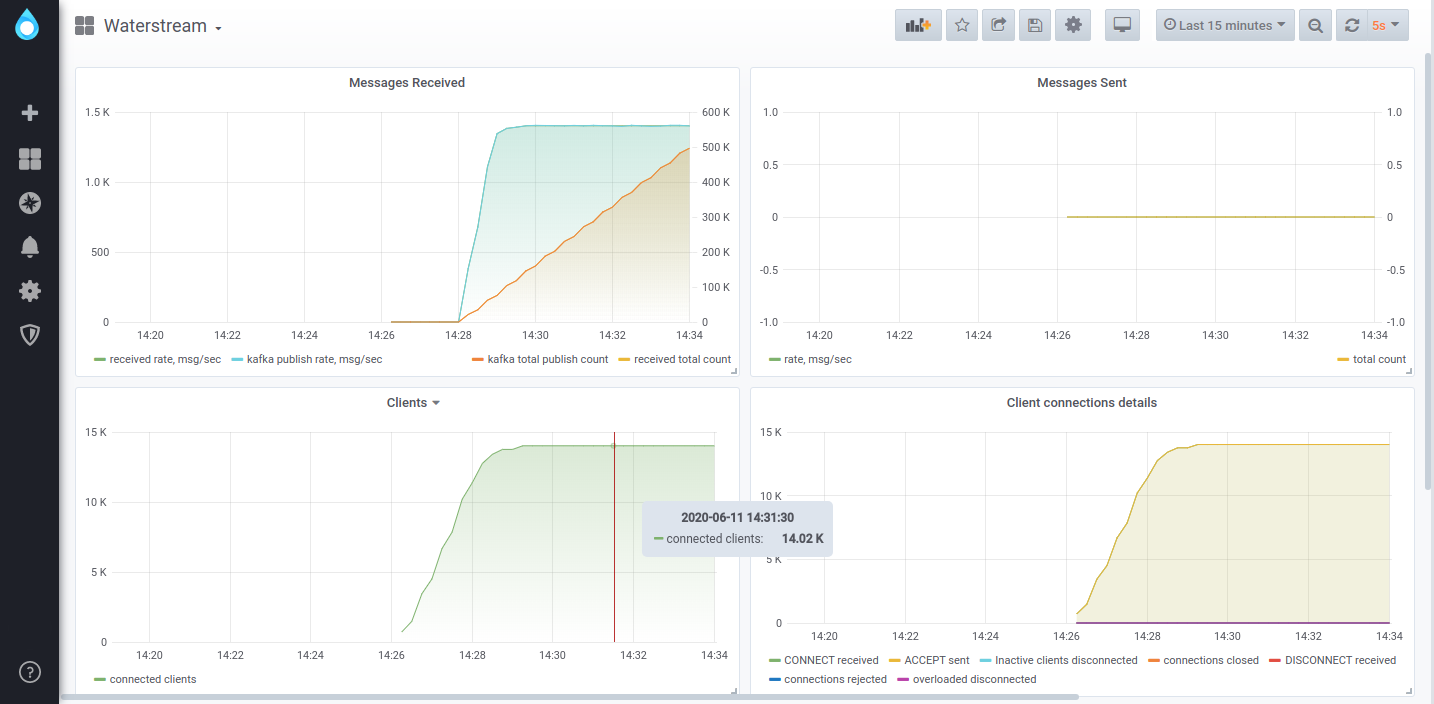
Of course, with just a single node, you don’t have high availability and may suffer some downtime. Actual edge deployments will rarely go that far and should choose the size and number of nodes according to availability and performance needs.
Live demo of Waterstream, Confluent Cloud, and ksqlDB
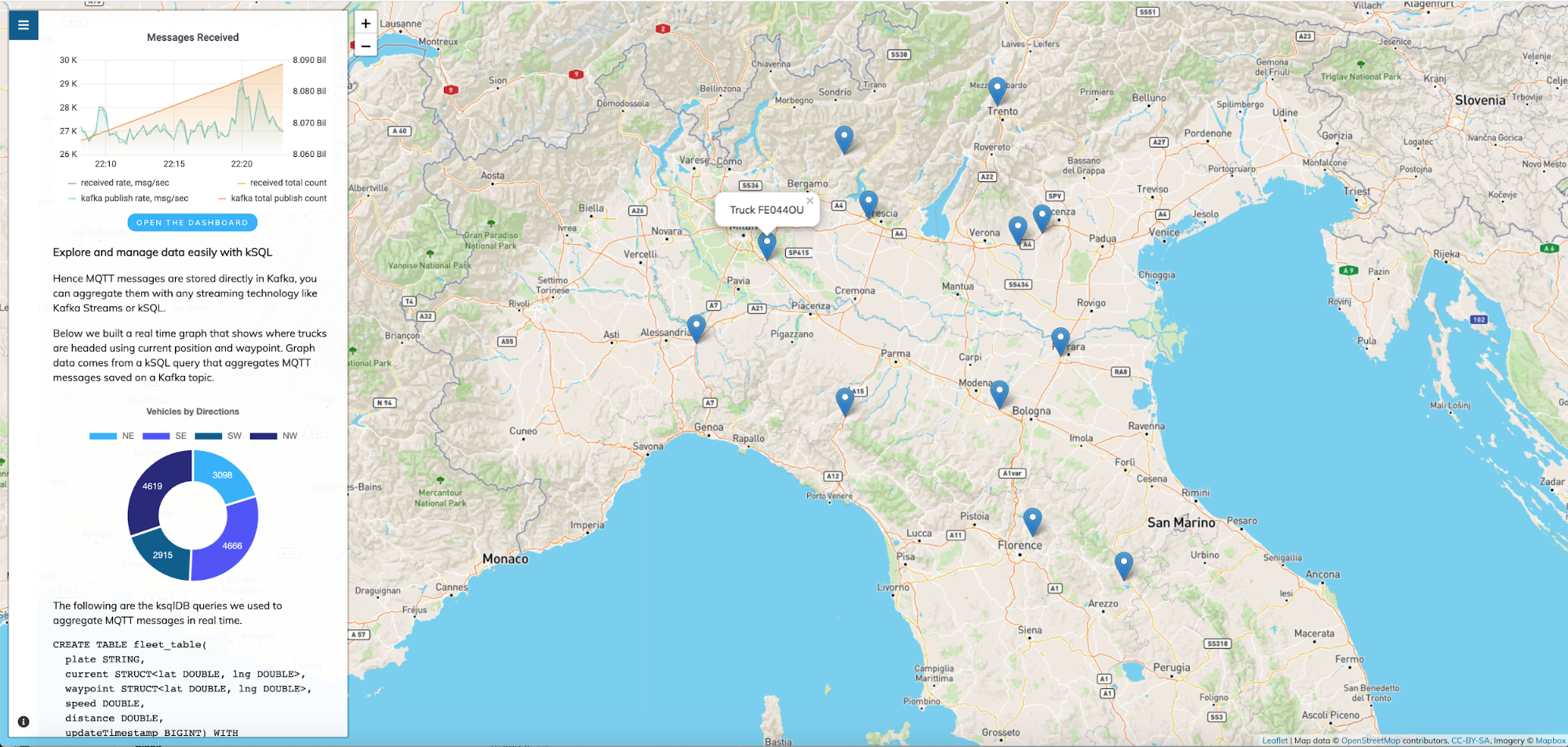
We’ve built a live demo of Waterstream connecting thousands of (virtual) devices and integrating it with Confluent Cloud and ksqlDB. It simulates a fleet of 15,000 trucks driving through Italy, which continuously send their position using MQTT messages.
Starting from the current position, each truck is assigned to a random destination. The route is computed with OpenStreetMap using a profile compatible with a heavy vehicle. Upon reaching the destination, the truck stops for a random amount of time before starting again, thus simulating driver rest and new load preparation.
The map displays a subset of the vehicles so that you can follow them as they move. The overall effect is pretty realistic with a smooth, fluctuating flow of messages presented in the embedded Grafana dashboard.
Each device is simulated with an MQTT client that sends the following data to Waterstream in JSON format:
- The plate that is used as the truck identifier
- The current position
- The next waypoint
- The current speed
- A timestamp
Each truck uses its MQTT topic, which consists of the concatenation of a fixed prefix together with the plate. Those topics are mapped into a single Kafka topic to make it easier to analyze them.
The UI presents two kinds of information extracted from the Kafka topic. On the map, there are 15 markers showing moving vehicles, while on the sidebar, we present an aggregation of truck direction partitioned by cardinal points.
This is how the data travels across this demo:
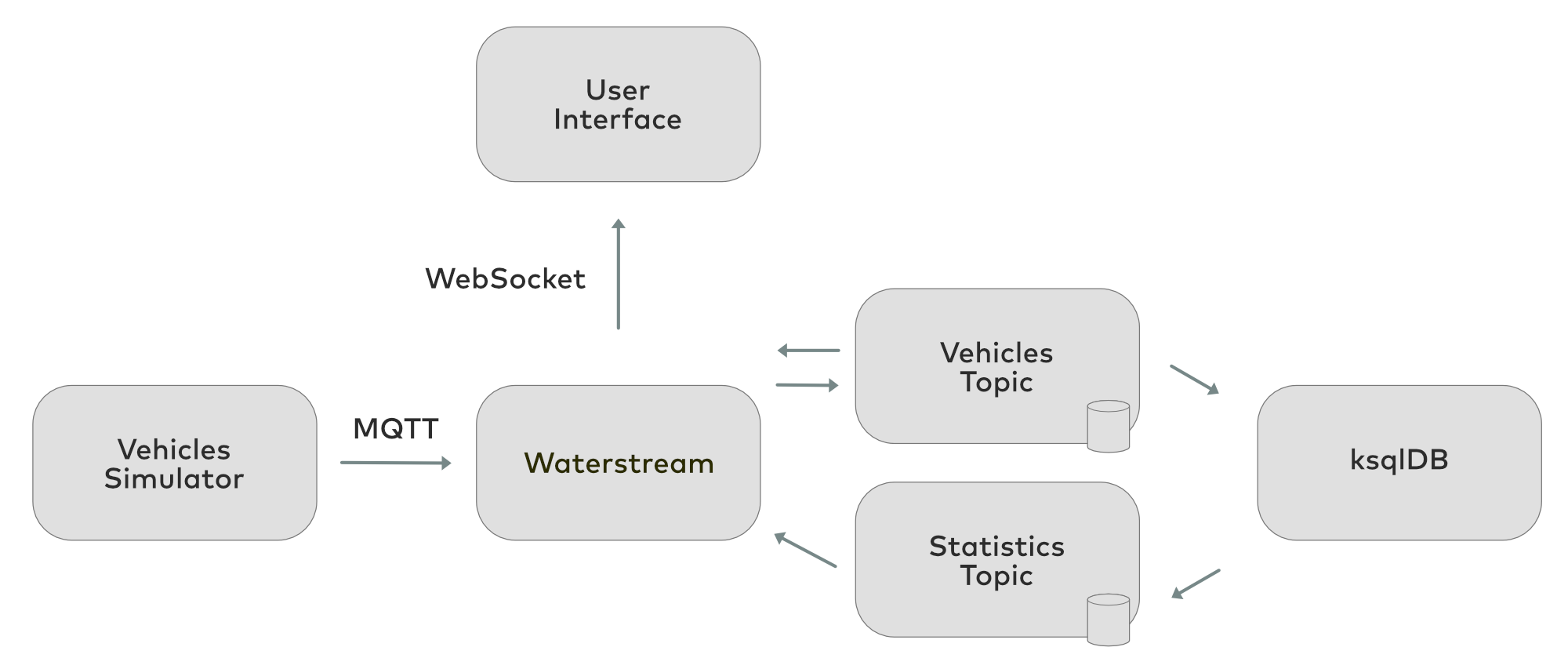
The vehicles simulator sends data to Waterstream via MQTT, which in turn streams the data into Kafka for tracking the vehicles. ksqlDB processes this information and writes the results into another Kafka topic. Waterstream has mappings for both these topics so it can read them. The UI uses MQTT over WebSocket to connect to the Waterstream without any intermediaries. Authorization rules in Waterstream are configured in such a way that allows read-only access to the UI and write permissions to the vehicles simulator.
The source code of the demo is available on GitHub.
Conclusion
This blog post introduced a new option for combining MQTT and Kafka: Waterstream, a Kafka-native MQTT broker implementation leveraging Kafka Streams. This simplifies your event streaming architecture, no matter if your deployment is in the cloud with Confluent Cloud or at the edge with Confluent Platform.
As proven by its design and benchmarks, this solution is scalable, able to connect to hundreds of thousands of MQTT devices, and fully MQTT compliant with bi-directional communication.
To get started with Apache Kafka as a service, you can use the promo code CL60BLOG for an additional $60 of free Confluent Cloud and follow the quick start.*





