Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
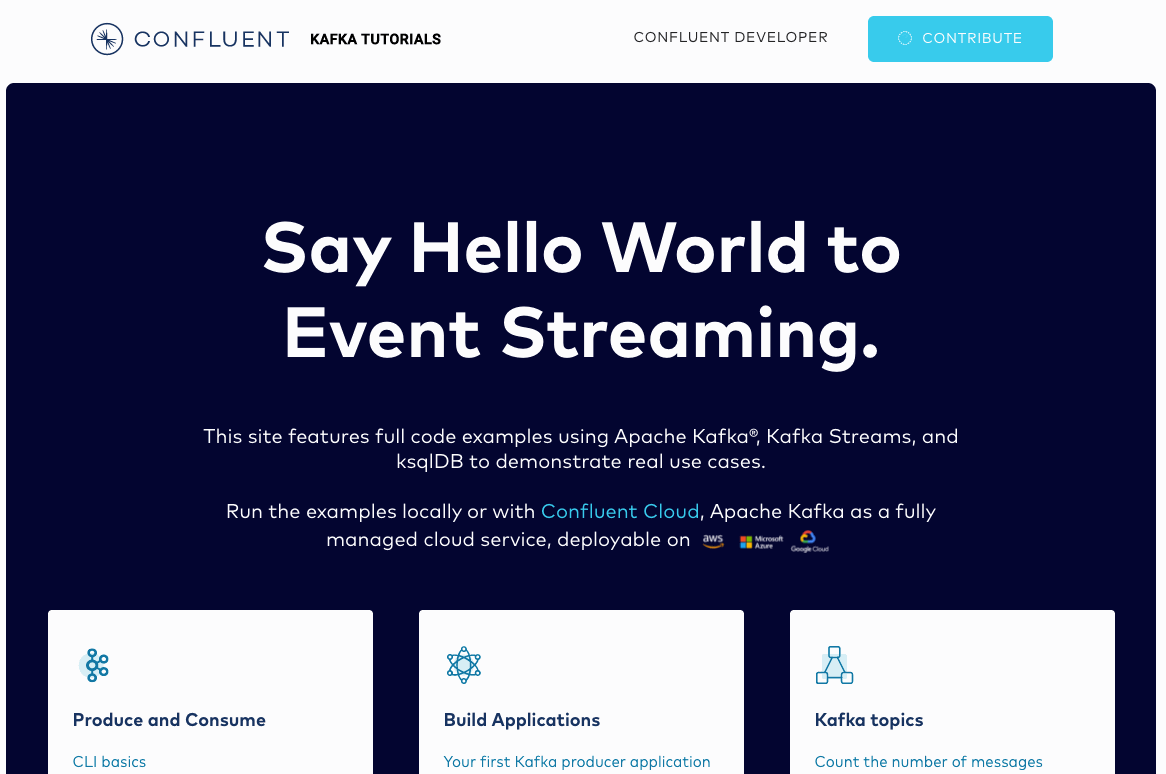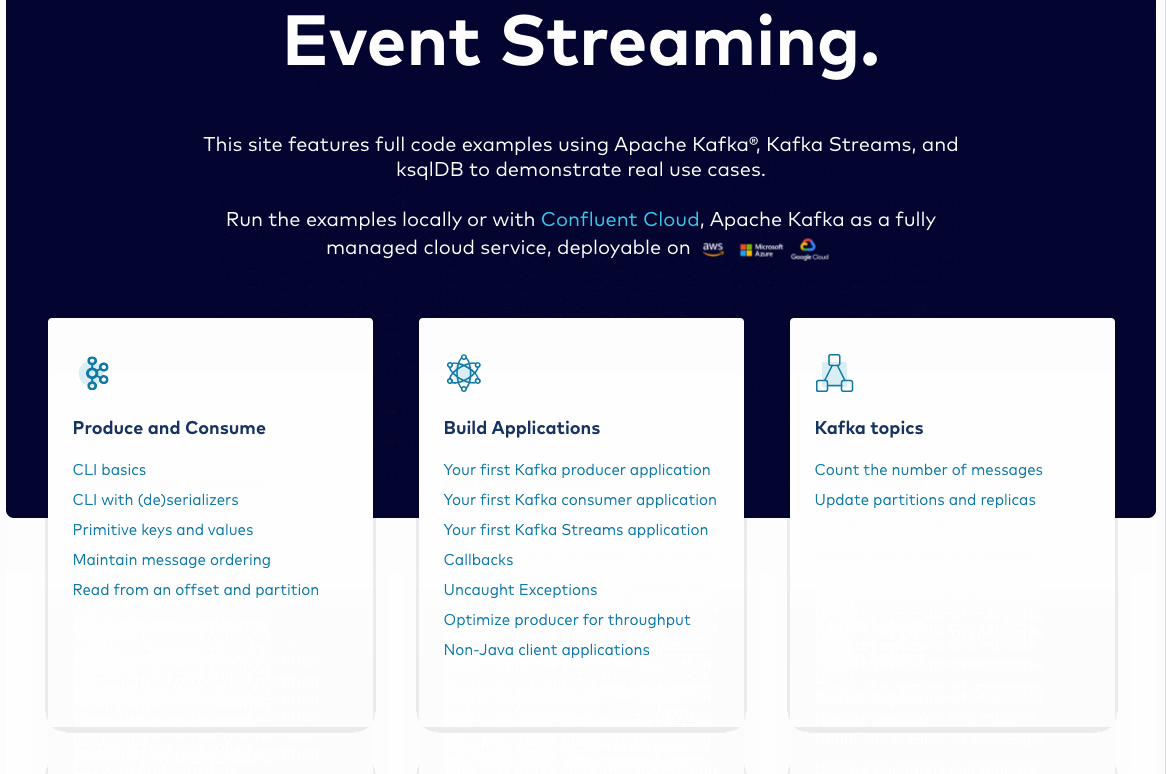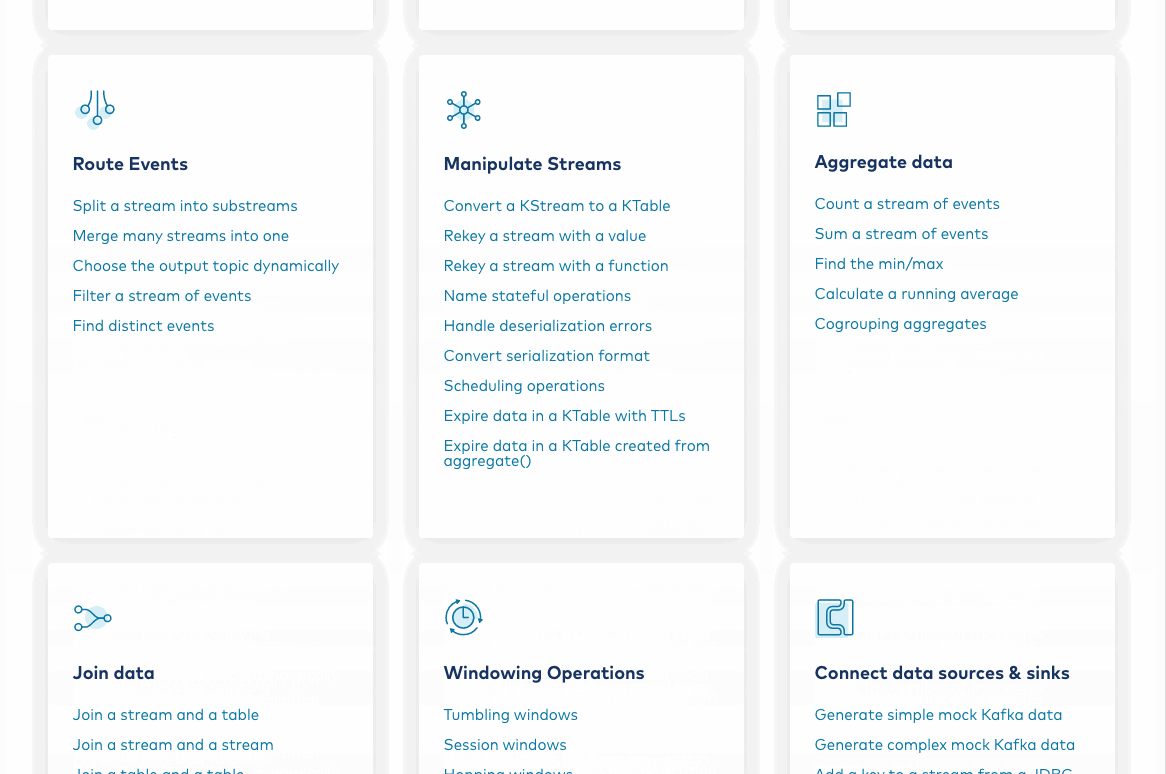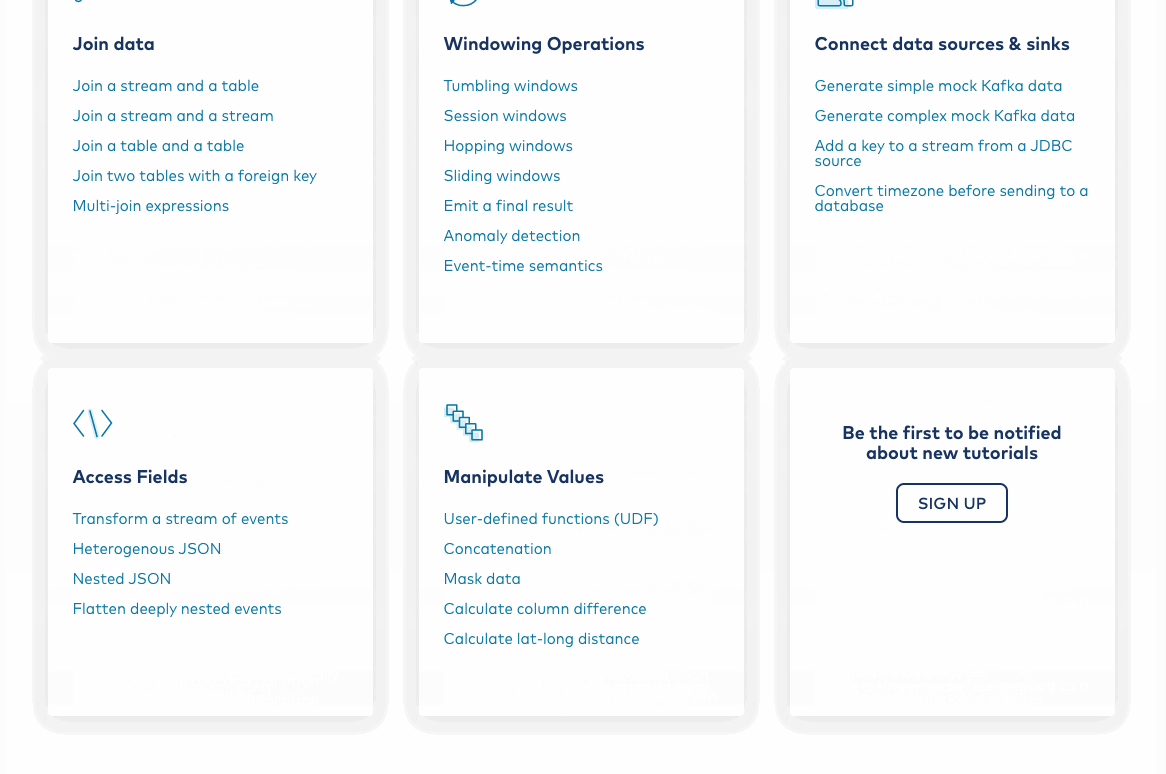
Best Tutorials for Getting Started with Apache Kafka
Each one of the more than 50 tutorials for Apache Kafka® on Confluent Developer answers a question that you might ask a knowledgeable friend or colleague about Kafka and its ecosystem—ranging from the most basic: –“What is the simplest way to write messages to and read messages from Kafka?”—to the most advanced: “If I have time series events in a Kafka topic, how can I group them into fixed-size, non-overlapping, contiguous time intervals?”
Conceptually, the goal of the tutorials is to present problems that event streaming can solve, as well as to teach the best way to solve them. The tutorials also cover edge cases where it may be hard to quickly find reliable information. Once you have become more advanced in your Kafka knowledge, the tutorials are a resource that you can always return to when you have a Kafka problem, in order to try and find a quick and correct answer and code snippet.
The multi-sectioned answers to the tutorial questions follow a literate programming paradigm, beginning with an example use case, which is often immediately followed by a short, copyable code snippet. Next, full instructions are given for setting up the relevant environments— whether ksqlDB, Kafka Streams, Basic Kafka, or Confluent Cloud—and for running the answer code in each. Finally, there is a section on testing your code and another on deploying to production.
This post will highlight a few of the common tasks that you might wish to try and achieve when you are just beginning with these tutorials: learning the CLI, writing a Hello World style Kafka application, connecting data sources to Kafka and generating mock data, processing and joining data using the tools in the Kafka ecosystem, and windowing data.
Learn CLI basics
CLI Basics in the “Produce and Consume” section is the tutorial to begin with if you are at the absolute beginning of your Kafka journey. ![]() It will show you how to set up a Kafka cluster and install Confluent CLI. You’ll create a topic, then produce and consume basic messages directly in the terminal, which is the simplest way to write messages to and read messages from Kafka. After finishing this first tutorial, you may wish to proceed to the next one in the section to add SerDes and Confluent Schema Registry to your Docker/Confluent Platform or Confluent CLI knowledge. The remainder of the tutorials in the section cover more advanced issues related to producing and consuming.
It will show you how to set up a Kafka cluster and install Confluent CLI. You’ll create a topic, then produce and consume basic messages directly in the terminal, which is the simplest way to write messages to and read messages from Kafka. After finishing this first tutorial, you may wish to proceed to the next one in the section to add SerDes and Confluent Schema Registry to your Docker/Confluent Platform or Confluent CLI knowledge. The remainder of the tutorials in the section cover more advanced issues related to producing and consuming.
Build your first Kafka application
The next step from here is to create your first Kafka application, a producer. Because each tutorial is self-sufficient, this one also![]() covers how to establish your environment. If you have already done this in the previous section, proceed to step 3 in Basic Kafka or step 5 in the Confluent Cloud versions of the tutorial to create a topic, add a build.gradle, add SerDes and properties, then create a producer to send data to Kafka. Finally, you’ll consume the same data to verify that everything is working. In the other tutorials in the “Build applications” section, you can complete a tutorial for writing a counterpart consumer application, learn how to produce and consume in non-Java languages, and learn how to handle uncaught exceptions using Kafka Streams.
covers how to establish your environment. If you have already done this in the previous section, proceed to step 3 in Basic Kafka or step 5 in the Confluent Cloud versions of the tutorial to create a topic, add a build.gradle, add SerDes and properties, then create a producer to send data to Kafka. Finally, you’ll consume the same data to verify that everything is working. In the other tutorials in the “Build applications” section, you can complete a tutorial for writing a counterpart consumer application, learn how to produce and consume in non-Java languages, and learn how to handle uncaught exceptions using Kafka Streams.
Use Kafka Connect to wire up data sources and sinks
Getting data into and out of your cluster via Kafka Connect is the next skill you will want to learn. The tutorial on implementing the Kafka Connect Datagen Connector will teach![]() you how to use connectors to produce some simple mock data to your cluster. The second tutorial explains how to generate more complex data using ksqlDB (or Basic Kafka) and the Voluble Source Connector, which will enable you to generate realistic test data that can also be made referentially consistent across topics. In the other two tutorials in the section, you can learn how to augment or change the data in a stream before sending it into Kafka or out to a database, respectively.
you how to use connectors to produce some simple mock data to your cluster. The second tutorial explains how to generate more complex data using ksqlDB (or Basic Kafka) and the Voluble Source Connector, which will enable you to generate realistic test data that can also be made referentially consistent across topics. In the other two tutorials in the section, you can learn how to augment or change the data in a stream before sending it into Kafka or out to a database, respectively.
Process an event stream both statelessly and statefully
You’ll quickly find that you want to process the data in your event streams, both with state and without it. You can begin by learning how to apply a simple filter in the![]() “Route Events” section, where you only retain the messages in a stream that match a particular field. If you use the ksqlDB version of the tutorial, you can build the program interactively in the ksqlDB CLI. Next, you can learn how to statefully aggregate data using a sum operation that calculates total ticket sales per sample movie. After successfully completing sum, make sure to try out some of the other operations in the “Aggregate data” section, such as count and min/max.
“Route Events” section, where you only retain the messages in a stream that match a particular field. If you use the ksqlDB version of the tutorial, you can build the program interactively in the ksqlDB CLI. Next, you can learn how to statefully aggregate data using a sum operation that calculates total ticket sales per sample movie. After successfully completing sum, make sure to try out some of the other operations in the “Aggregate data” section, such as count and min/max.
Join events from distinct streams and tables
In the previous section, you worked with a single stream, filtering or aggregating its events; however, at some point, you’ll want to join data from more than one entity. Perhaps you’d like to ![]() enrich a customer record with additional data like previous orders or a library book record with the book’s lending history. You can join streams to streams, streams to tables, tables to tables, and GlobalKTables to streams in the Kafka ecosystem, and you can begin by learning how to join a stream against a table. After completing the exercise, work your way through the other tutorials in the “Join data” section to learn more about other join types and their nuances.
enrich a customer record with additional data like previous orders or a library book record with the book’s lending history. You can join streams to streams, streams to tables, tables to tables, and GlobalKTables to streams in the Kafka ecosystem, and you can begin by learning how to join a stream against a table. After completing the exercise, work your way through the other tutorials in the “Join data” section to learn more about other join types and their nuances.
Limit your aggregations with windowing
Something you may need to accomplish early on in your Kafka journey is to limit the size of your aggregations using windowing. This way, a particular data set won’t become too large and unwieldy. ![]() You have multiple options for windows, but the fixed-size, non-overlapping, contiguous tumbling variant is easy to reason about and easy to implement for the sake of learning. To use tumbling windows with the Confluent Platform environment and Kafka Streams or Confluent Cloud and Kafka Streams, you’ll need a TimeStampExtractor class. If you use ksqlDB with Confluent Platform, you can build the program interactively in the ksqlDB CLI, as with the earlier examples.
You have multiple options for windows, but the fixed-size, non-overlapping, contiguous tumbling variant is easy to reason about and easy to implement for the sake of learning. To use tumbling windows with the Confluent Platform environment and Kafka Streams or Confluent Cloud and Kafka Streams, you’ll need a TimeStampExtractor class. If you use ksqlDB with Confluent Platform, you can build the program interactively in the ksqlDB CLI, as with the earlier examples.
Conclusion
If you are new to the Kafka ecosystem, event streaming can take some time to properly comprehend. Working your way through the community-driven, zero-to-code tutorials is one of the most efficient (“slow-yet-fast”) methods to gain proficiency with Apache Kafka and its nuances. As mentioned earlier, the tutorials are also the resource of first order to check when looking for quick code for a Kafka problem, whether basic or obscure. Get started today!
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent





