Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
What Is ZooKeeper’s Role in Apache Kafka®?
You can think of Apache ZooKeeper as a “cluster manager” for Apache Kafka®. While Kafka handles the heavy lifting of moving data (messages), ZooKeeper manages the metadata and coordination required to keep the distributed system stable and consistent. ZooKeeper handles important tasks such as:
- Choosing a leader broker (called controller election)
- Keeping track of topics, partitions, and replicas
- Detecting when a broker joins or leaves the cluster
In this guide, we’ll cover how Zookeeper works, why it’s being replaced by KRaft, and how to migrate your clusters safely with Confluent.



Apache Kafka® Without ZooKeeper: Introduction to KRaft
As of Kafka 3.3+, ZooKeeper has been deprecated in favor of a new metadata management system called KRaft, which stands for Kafka Raft metadata mode. With KRaft, Kafka no longer requires ZooKeeper to manage the cluster. Instead, Kafka’s control plane now has its own built-in way to handle metadata, leader election, and broker coordination.
KRaft improves Kafka in several ways:
-
Simplifying the architecture by removing the need for a separate ZooKeeper service
-
Improving scalability because metadata updates are faster and more efficient
-
Reducing operational complexity, making installation, upgrades, and monitoring easier
-
Increasing reliability through faster failover and a more integrated control plane
With KRaft, Kafka becomes more self-contained and easier to operate, especially in large-scale or cloud environments.
Why Is Kafka Replacing ZooKeeper?
Kafka is moving away from ZooKeeper, because it became difficult to scale, operate, and manage in large, modern streaming environments. As Kafka deployments grew, ZooKeeper’s limitations made cluster management more complex than necessary.
Let’s review the main reasons the community began looking for an alternative way to manage Kafka metadata in 2019.
Scaling Challenges With ZooKeeper
ZooKeeper was never designed for the high-rate metadata updates that large clusters require. As Kafka clusters scaled vertically and added more topics, more partitions, and more brokers, ZooKeeper became a Kafka bottleneck:
-
Metadata write throughput was limited
-
Controller failover took longer
-
Large clusters became harder to expand
Operational Complexity
Running ZooKeeper meant maintaining two distributed systems: Kafka itself and a separate ZooKeeper ensemble. This increased operational overhead, requiring teams self-managing Kafka to take on:
-
Extra configuration and maintenance
-
Additional monitoring and alerting
-
More complicated upgrades
-
Strict dependency between Kafka and ZooKeeper versions
This added complexity often contributed to production issues, especially in fast-growing clusters.
Latency and Failover Delays
ZooKeeper stored metadata outside Kafka. So when a broker failed or leadership changed, the controller had to update metadata through ZooKeeper, causing delays that create reliability issues at scale, including:
-
Slower failover between client applications
-
Longer recovery during outages
-
Reduced cluster responsiveness under load
ZooKeeper vs KRaft: A Complete Side-by-Side Comparison
The Kafka community wanted a simpler, unified architecture where Kafka manages its own metadata. This led to the creation of KRaft (Kafka Raft metadata mode), a consensus protocol which allows Kafka to manage the control plane using its own internal metadata quorum instead of ZooKeeper.
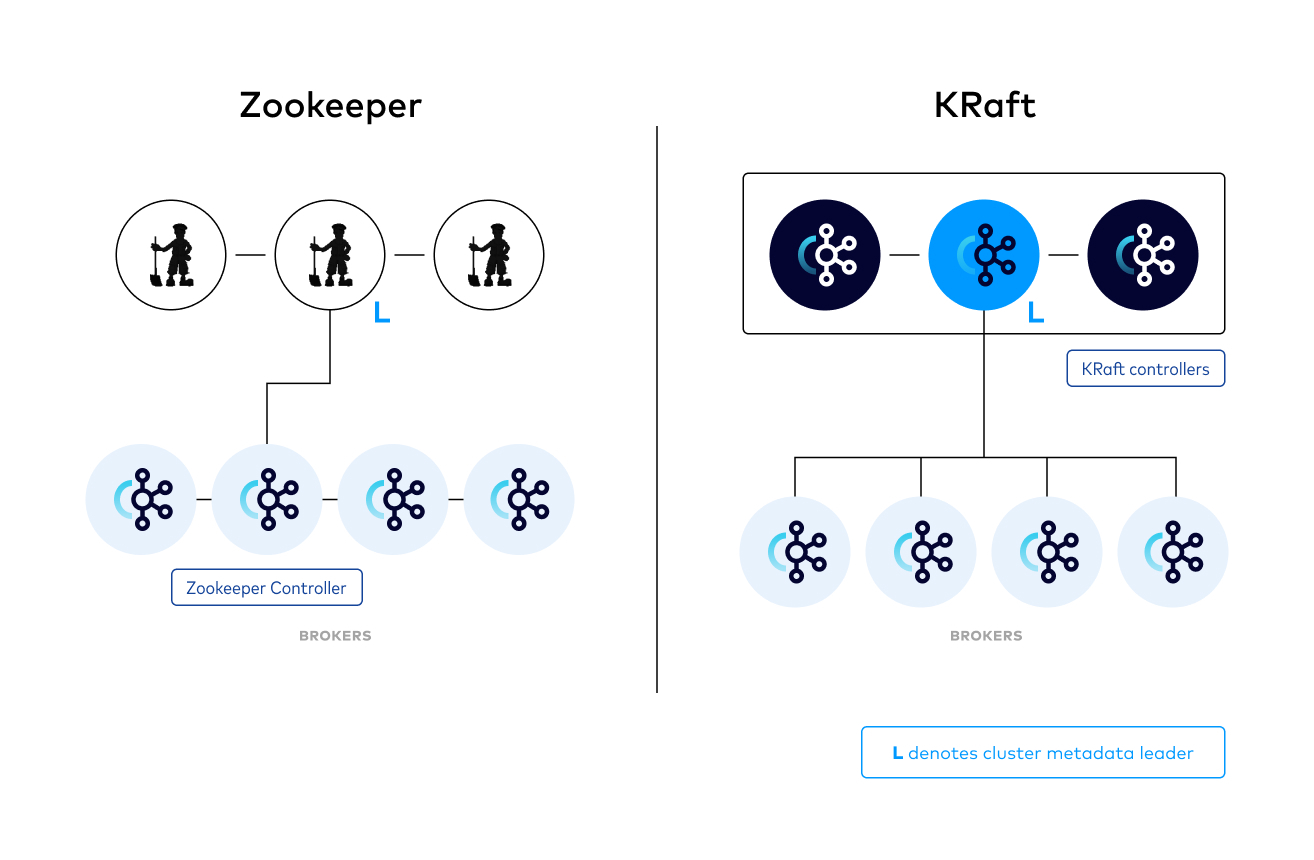
KRaft was introduced in KIP-500 to remove Kafka’s dependency on ZooKeeper and move metadata management into the Kafka cluster. Running Kafka in KRaft mode allows you to unify the control plane, rather than splitting it between two different systems.
The table below compares ZooKeeper vs. KRaft-based across architecture, operations, and security.
Side-by-Side Comparison of ZooKeeper vs. KRaft
|
Category |
Kafka with ZooKeeper |
Kafka with KRaft |
|
Architecture |
Uses an external ZooKeeper ensemble to manage metadata and controller election. |
Uses Kafka’s built-in Raft-based metadata quorum; no external coordination system required. |
|
Metadata Storage |
Stored in ZooKeeper as a separate state. |
Stored directly inside Kafka brokers (metadata nodes). |
|
Controller Election |
ZooKeeper selects the controller broker. |
KRaft uses Raft consensus to elect a leader internally. |
|
Scalability |
Limited scalability for large clusters due to ZooKeeper write/notification overhead. |
More scalable; metadata updates are faster and optimized for large deployments. |
|
Failover Speed |
Slower failover due to ZooKeeper round-trips. |
Faster failover through integrated Raft consensus. |
|
Operational Complexity |
Two systems to maintain: Kafka + ZooKeeper; more configs and monitoring. |
Single system to manage; simplified deployment, upgrades, and automation. |
|
Cluster Expansion |
Harder to scale because ZooKeeper can become a bottleneck. |
Easier to scale brokers and partitions without external coordination overhead. |
|
Security |
Requires managing ACLs and authentication for both Kafka and ZooKeeper. |
Unified security model inside Kafka; fewer moving parts. |
|
Upgrade Path |
Requires careful coordination between Kafka and ZooKeeper versions. |
Simplified upgrade experience with a single system. |
|
Cloud & Container Fit |
ZooKeeper adds extra stateful nodes and complexity. |
Designed for cloud-native and containerized environments. |
|
Dependency Count |
Kafka depends on ZooKeeper. |
No external dependency. |
|
Production Readiness |
Legacy model; still supported but being phased out. |
The future Kafka standard (KIP-driven modernization). |
Do You Still Need ZooKeeper for Kafka Today?
Whether you still need ZooKeeper today depends on the version of Kafka you or your Kafka service is running, but newer versions (3.3+) no longer require it.
While ZooKeeper has been the backbone of Kafka for over a decade, the ecosystem is aggressively moving toward KRaft (Kafka Raft Metadata mode), which eliminates ZooKeeper entirely. Here is the breakdown by situation:
-
For New Clusters: If you are deploying a new Kafka cluster today (using Kafka 3.3+), you should default to KRaft mode. It simplifies operations, deployment, and monitoring.
-
For Existing Clusters: Yes, for now. If you are running an older version of Kafka or have not yet executed a migration, you still need ZooKeeper—for now. However, you must start planning your exit strategy.
Key Timeline and Versions as of December 2025
|
Kafka Version |
Status of ZooKeeper |
Action Required |
|
< 2.8 |
Mandatory |
Plan Upgrade: You are on legacy architecture. |
|
2.8 – 3.2 |
Mandatory (KRaft in Preview) |
Prepare: KRaft is available but not production-ready in these versions. |
|
3.3+ |
Deprecated |
Adopt: KRaft is Production Ready. New clusters should use it. |
|
3.5+ |
Deprecated |
Migrate: Migration features from ZK to KRaft are production ready. |
|
4.0 |
Removed |
Urgent: ZooKeeper will be completely removed. |
For a deep dive into the metadata architecture, refer to Confluent’s KRaft documentation.
A Checklist for ZooKeeper-to-KRaft Migrations for Your Kafka Clusters
Migrating a running cluster from ZooKeeper to KRaft without downtime is a significant operation that requires a "bridge release." This allows the cluster to run in a dual-mode where it temporarily maintains metadata in both ZooKeeper and the KRaft controller quorum.
To ensure a seamless transition before you upgrade to Kafka 4.0, Kafka 4.1, or subsequent releases, follow this structured approach:
-
Audit Your Ecosystem: Identify all client applications and tools relying on direct ZooKeeper access. These must be refactored to communicate with Kafka brokers directly, as the ZK port will eventually close.
-
Upgrade to a Bridge Release: Update your cluster to a Kafka version that supports migration. Kafka 3.5 or 3.6 is recommended for the most stable migration tools.
-
Provision Controller Nodes: Deploy the new KRaft controller nodes that will eventually take over metadata management.
-
Enable Dual-Write Mode: Configure the cluster to write metadata to both ZooKeeper and the new KRaft controllers. This allows the systems to synchronize.
-
Rollover Brokers: Restart brokers in KRaft-migration mode. They will begin reading metadata from the KRaft quorum instead of ZooKeeper.
-
Finalize Cutover: Once all metrics are stable, disable the ZooKeeper connection. The cluster is now running purely on KRaft.
-
Decommission ZooKeeper: Safely shut down and remove the ZooKeeper servers from your infrastructure.
Warning: Do NOT attempt to upgrade directly to Kafka 4.0 running Kafka versions older than 3.3 or running versions 3.3-3.9 in ZooKeeper mode. You must pass through a "bridge release" to perform the migration first.
What Is Confluent’s Approach to the ZooKeeper to KRaft Transition?
As organizations move from ZooKeeper-based Kafka to KRaft, many teams look for a safer and more predictable migration path. Confluent provides managed Kafka on KRaft on Confluent Cloud, along with tools, guides, and automation to make the transition easier and lower risk—especially for production environments.
Learn more about how Confluent is navigating the ZooKeeper-to-KRaft migration and supporting its users and customers through this transition:
-
Docs:
-
Blog: “Confluent Cloud Is Now 100% KRaft and You Should Be Too”
-
Confluent Developer: Kafka Architecture Course – The Control Plane
Apache ZooKeeper, KRaft, and Kafka – FAQ
Do I need ZooKeeper for Kafka today?
It depends on what version of Kafka you are using. Older Kafka versions still use ZooKeeper, but newer releases support KRaft and will run only in KRaft mode after Kafka 4.0.
What is the difference between ZooKeeper and KRaft?
ZooKeeper is an external system for managing metadata, controller election, and broker coordination for Kafka, which the KRaft consensus protocol is replacing with capabilities built into Kafka’s control plane.
When will Kafka remove ZooKeeper completely?
ZooKeeper has been removed in Kafka 4.0 and later versions, where KRaft becomes the only supported mode.
How do I migrate from ZooKeeper to KRaft?
Start migrating from ZooKeeper to Kraft by assessing your current Kafka clusters for compatibility with Kafka 3.3-3.9 or Kafka 4.0+, planning whether you need a bridge release, monitoring and testing migrated workloads, and then cutting over and retiring ZooKeeper once migration is successful.
Does Confluent still use ZooKeeper?
Confluent Platform supports both modes today, but Confluent Cloud runs completely on KRaft, without ZooKeeper.