Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Building a Real-Time Streaming ETL Pipeline in 20 Minutes
There has been a lot of talk recently that traditional ETL is dead. In the traditional ETL paradigm, data warehouses were king, ETL jobs were batch-driven, everything talked to everything else, and scalability limitations were rife. Messy pipelines were begrudgingly tolerated as people mumbled something about the resulting mayhem being “the cost of doing business.” People learned to live with a mess that looked like this:
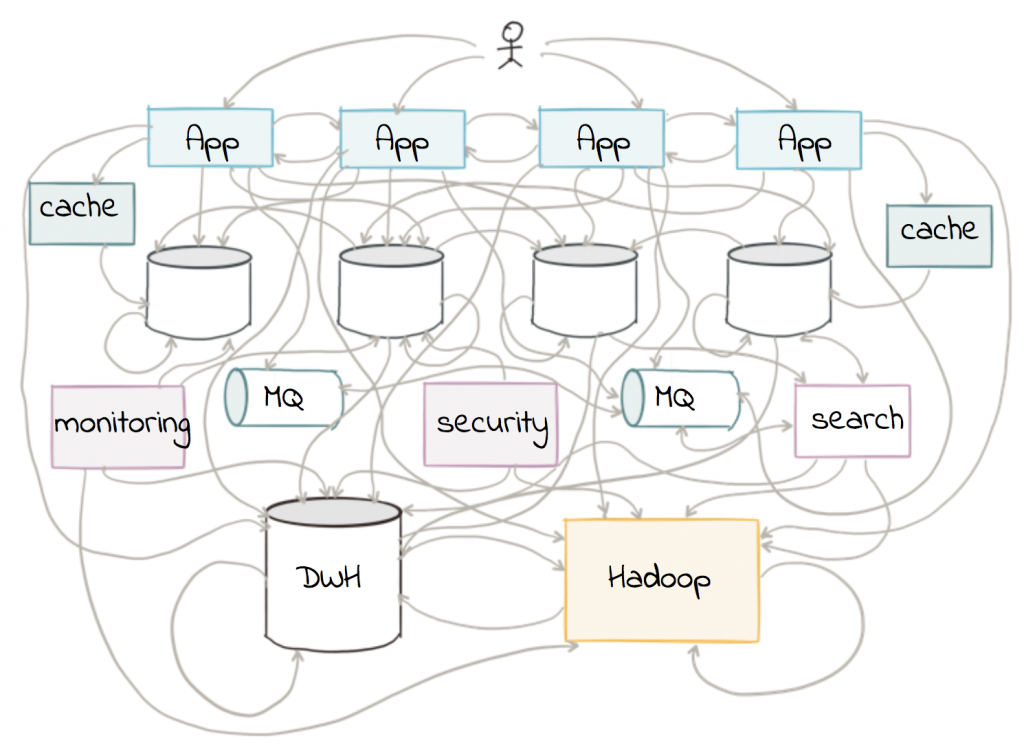
However, ETL is not dead. Developers increasingly prefer a new ETL paradigm with distributed systems and event-driven applications, where businesses process data in real time and at scale. There is still a need to “extract”, “transform”, and “load,” but the difference now is the treatment of data as a first-class citizen. Businesses no longer want to relegate data to batch processing, which often is limited to being done offline, once a day. They have many more data sources and of differing types, and want to do away with messy point-to-point connections. We can embed stream processing directly into each service, and core business applications can rely on a streaming platform to distribute and act on events. The focus of this blog post is to demonstrate how easily you can implement these streaming ETL pipelines in Apache Kafka®.
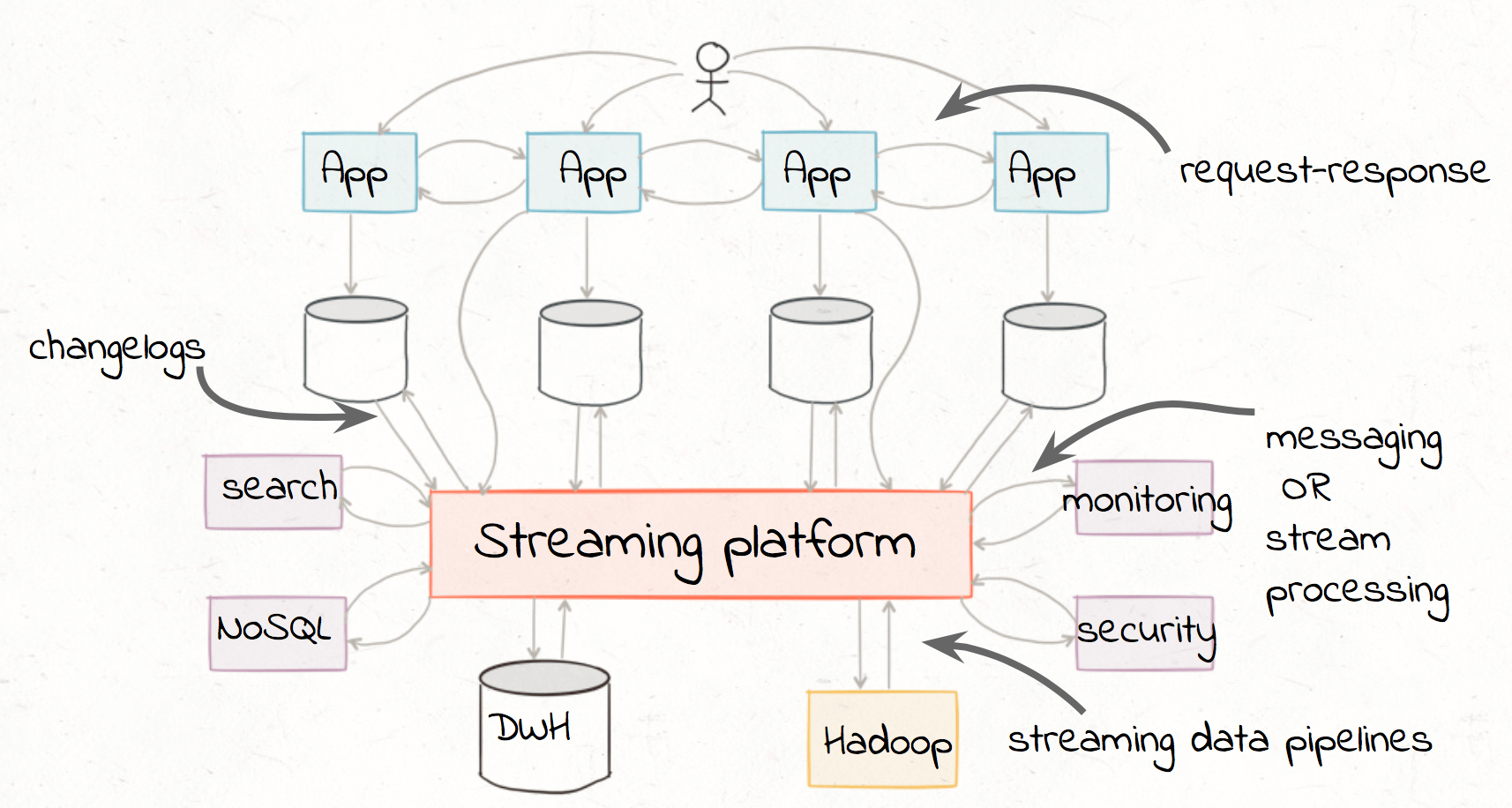
Kafka is a distributed streaming platform that is the core of modern enterprise architectures. It provides Kafka connectors that run within the Kafka Connect framework to extract data from different sources, the rich Kafka Streams API that performs complex transformations and analysis from within your core applications, and more Kafka connectors to load transformed data to another system. You can deploy the Confluent Schema Registry to centrally manage schemas, validate compatibility, and provide warnings if data does not conform to the schema. (Don’t understand why you need a Schema Registry for mission critical data? Read this blog post.) The end-to-end reference architecture is below:
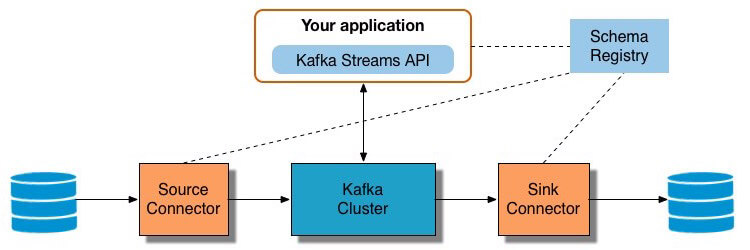
Let’s consider an application that does some real-time stateful stream processing with the Kafka Streams API. We’ll run through a specific example of the end-to-end reference architecture and show you how to:
- Run a Kafka source connector to read data from another system (a SQLite3 database), then modify the data in-flight using Single Message Transforms (SMTs) before writing it to the Kafka cluster
- Process and enrich the data from a Java application using the Kafka Streams API (e.g. count and sum)
- Run a Kafka sink connector to write data from the Kafka cluster to another system (AWS S3)
The workflow for this example is below:
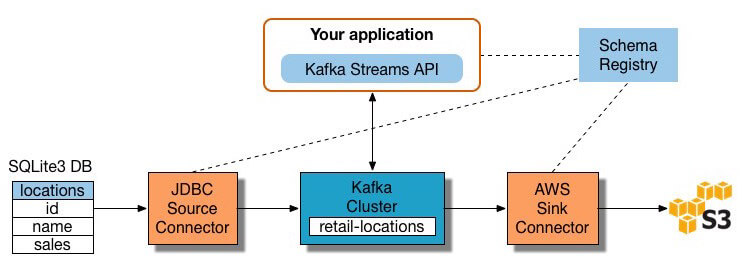
If you want to follow along and try this out in your environment, use the quickstart guide to setup a Kafka cluster and download the full source code.
Extracting Data into Kafka
First, we have to get the data into your client application. To copy data between Kafka and other systems, users can choose a Kafka connector from a variety of readily available connectors. Kafka source connectors import data from another system into Kafka, and Kafka sink connectors export data from Kafka into another system.
For our example, we want to pull data from a SQLite3 database, which is saved to /usr/local/lib/retail.db. The database has a table called locations, and it has three columns id, name, and sale with sample contents:
|
locations |
||
| id | name | sale |
| 1 | Raleigh | 300 |
| 2 | Dusseldorf | 100 |
| 1 | Raleigh | 600 |
| 3 | Moscow | 800 |
| 4 | Sydney | 200 |
| 2 | Dusseldorf | 400 |
| 5 | Chennai | 400 |
| … | … | … |
We want to create a stream of data from that table, where each message in the stream is a key/value pair. What is the key and what is the value, you ask? Well, let’s work through that.
 To extract the table data into a Kafka topic, we use the JDBC connector that comes bundled in Confluent Platform. Note that by default, the JDBC connector doesn’t add a key to messages. Since message keys are useful for organizing and grouping messages, we will set the key using SMTs. If we used the default configuration settings, the data would be written to a Kafka topic with the following configuration:
To extract the table data into a Kafka topic, we use the JDBC connector that comes bundled in Confluent Platform. Note that by default, the JDBC connector doesn’t add a key to messages. Since message keys are useful for organizing and grouping messages, we will set the key using SMTs. If we used the default configuration settings, the data would be written to a Kafka topic with the following configuration:
|
Default Configuration |
|
| Source database | test.db |
| Kafka topic created | test-sqlite-jdbc-locations |
| Message key present | Effectively null (JSON schema with null values) |
| Message value schema | JSON |
| Data governance | None |
Instead, we want the following target configuration:
|
Target Configuration |
|
| Source database | /usr/local/lib/retail.db |
| Kafka topic created | retail-locations |
| Message key present | Yes, insert key using Kafka Connect’s Single Message Transform feature |
| Message value schema | Avro |
| Data governance | Yes, with Schema Registry |
To achieve the target configuration, we modify the JDBC source connector properties file source-quickstart-sqlite.properties:
Then we add these configuration lines to the JDBC source connector properties file to leverage Single Message Transform (SMT) functions, which manipulate the data extracted from the table rows before they are written to the Kafka topic. We use the ValueToKey and ExtractField SMT functions to replace the null key with a field derived from the message value.
Finally we add these configuration lines to the JDBC source connector properties file to configure the key converter to be String (which could have just as easily been serialized as JSON or Avro) and the value converter to be schema’d Avro. Confluent Schema Registry is running at http://schemaregistry1:8081.
For simplicity, we are running the JDBC source connector in Kafka Connect standalone mode. In production you should always use distributed mode for scalability and fault tolerance and Confluent Control Center for central management.
At this point, Kafka Connect runs the JDBC connector and pulls each row of the table and writes it as a key/value pair into the Kafka topic retail-locations. Applications interested in the state of this table will read from this topic. As rows are added to the source table in the SQLite3 database, Kafka Connect automatically writes them as messages to the Kafka topic, and then they are automatically available to your client application in a KStream object. Thus we have achieved getting the data as an unbounded, continuous real-time flow. This data flow is what we call a “stream.”
Each table row is serialized as an Avro record. We can look up the schema for the message value in Confluent Schema Registry from the topic retail-locations.
Transforming Data with Kafka Streams API
Now that the source data is written to a Kafka topic, any number of applications can read from the topic and deserialize the message value, which is an Avro record, using the Schema Registry. One simple application could be kafka-avro-console-consumer:
But the console consumer command line tool is not our end goal. We want to demonstrate how to use the Kafka Streams API in your client applications for stream processing with the data in that topic. Confluent has excellent documentation on how to develop applications using the API.
Here, I want to emphasize two parts of the application:
- Creating Kafka Streams objects from the Kafka topics
- Data transformation with Kafka Streams processing operations
Creating Kafka Streams Objects
Creating Kafka Streams objects from the Kafka topics means converting byte records in Kafka to Java objects in the client application. Since the message value is an Avro record, we need a Java class that matches the schema. We create an Avro schema file called location.avsc that defines the client’s expectation of the data structure. It is formatted in JSON and has a record with three fields id, name, and sale that correspond to the table columns.
For the Java client application to be able to deserialize messages that have been written in this Avro schema, we need to have a corresponding Java class (e.g. Location). However, we don’t need to write the Java code! In our pom.xml we use the Maven plug-in avro-maven-plugin which automatically generates the Java code for these classes.
Now that the Java sources are automatically created from the Avro schema file, your application can import that package:
The next key steps are to configure the streams configuration to use the appropriate serialization/deserialization classes and to point to the Schema Registry:
You can now create KStream objects:
Note that some of the basic Kafka Streams setup was omitted in the workflow above, but remember to check out the Streams Developer Guide for detailed instructions.
Processing and Enriching Data
At this point in the client application, we have a KStream object called locationsStream which contains a stream of messages where the message key is a <Long> id and the message value is a <Location> record that contains its id, name, and sale values.

Now we can do our data transformations with stream processors. There is a rich Kafka Streams API for real-time streams processing that you can leverage in your core business applications. There are a variety of stream processors, which receives one input record at a time, applies its operation to it, and may subsequently produce one or more output records to its downstream processors. These processors can be stateless (e.g. transform one message at a time, or filter out messages based on some condition) or stateful (e.g. join, aggregate, or window data across multiple messages).
To get started with the Kafka Streams API, here are three examples with sample code and a corresponding visualization of what the resulting stream of data looks like:
- Convert streams of data into newly typed key/value pairs. For example, we can use the map method to convert the original KStream<Long, Location> to KStream<Long, Long> of key/value pairs where the key is the same key and the value is just the value of sale.

- Count the occurrences of a specific key by first grouping the messages based on key and then counting the occurrences using the count method. The Kafka Streams API has native abstractions that capture the duality of streams and tables: KStream represents message streams, where each data record represents a self-contained datum in the unbounded data set, and KTable represents changelogs, where each data record represents an update. We can also name a local state store for aKTable, which allows us to easily query it like a normal table. For example, we can count the number of occurrences of each key.

- Sum the values for a specific key by first grouping messages based on key and then summing the value using the reduce method. For example, we can sum the value of sales for a given key across all messages, and it will get updated in real-time as new sales are added. This example also shows how Kafka Streams allows us to go back and forth between a KStream andKTable.

Loading Data into other Systems
At this point, all the enriched data is still in our client application, and we may want to stream it into another system. In fact, you may want the data in numerous target downstream systems as part of a pipeline that fans out. You can run Kafka Connect with multiple Kafka sink connectors such that any number of target downstream systems can receive the same data. The Kafka sink connectors can run in parallel with Kafka source connectors.
In our example, the destination system is an AWS S3 bucket. To load the data there, it’s as easy to get data out of Kafka as it was to get into Kafka. The application writes theKStream out to a Kafka topic with this single statement:
Then a Kafka sink connector handles the ingestion into the downstream system. You can point the sink connector at this Kafka topic and run it with Kafka Connect in a similar fashion as you did running Kafka connect for the Kafka source connector.
To load the data into AWS S3, you could configure your S3 connector properties with the appropriate topic name, S3 region, and bucket, and then run the connector. We’ll omit the precise S3 configuration for now (there’s another blog post coming soon on that!), but you would start the connector with this command:
Conclusion
Perhaps the workflow described in this blog post seems to carry a lot of overhead for our very simple example. However, consider real-world scenarios with multiple data sources and targets that need to ingest the data while supporting varied schemas that evolve over time. There are multi-step, real-time workflows with complex transformations that require high durability and fault tolerance. Kafka provides the bedrock of a very flexible, scalable architecture for building streaming ETL pipelines. You don’t want to attempt to glue this together with the traditional ETL paradigm, as the whole process becomes unavoidably messy. Referring back to the Kafka reference architecture diagram, you can see how real-time, business-critical applications can benefit from Kafka’s streaming ETL capabilities:
The Kafka streaming platform allows mission critical applications to process data in real-time:
- Kafka Connectors run within the Kafka Connect framework enable developers to extract data from one system or load it into another
- Kafka Streams API gives applications the stream processing capabilities to transform data, one message or event at a time. These transformations can include joining multiple data sources, filtering data, and aggregating data over a period of time
- Confluent Schema Registry provides data governance with Avro schemas
- Confluent Control Center provides central management
Download Confluent Platform and get started with examples of code using Kafka Streams, Kafka Connect, Avro, Schema Registry together. If you like Docker, you can also check out the Kafka Streams music demo.
Our online talk series Streaming ETL – The New Data Integration is also available on demand.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독





