Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Mortgage Underwriting Multi-Agent System
Accelerate mortgage decisions with AI agents powered by real-time data. Built using Confluent Data Streaming Platform, this solution automates risk assessment, approvals, and offers – fast, accurate, and fully auditable.


Accelerate Mortgage Decisions with Real-Time AI Agents and Stream Processing
Streamline and automate your mortgage underwriting process by integrating agents with Confluent Cloud, AWS, Databricks, and Anthropic’s Claude LLM to deliver faster, more accurate decisions – from application submission to final offer.
Each agent is powered by contextualized data products created using Flink and governed through Confluent’s schema registry and data quality rules. Data flows continuously through Kafka topics, triggering Lambda-based fraud checks, Flink SQL-based decisioning, and dynamic offer generation via LLM calls – all while enabling human-in-the-loop review and full auditability for compliance and downstream analytics.
Automate end-to-end mortgage processing with AI agents
Ingest and enrich applicant data in real time using Flink
Ensure data integrity and compliance with Stream Governance
Seamlessly connect data streams to Databricks for analytics
Build with Confluent
This use case leverages the following building blocks in Confluent Cloud:
Reference Architecture
This multi-agent architecture ingests live mortgage applications and leverages Flink to stream process and contextualize them in real time using credit history, payment records, etc. enabling AI agents to assess risk, recommend terms, and issue offers without manual intervention. The system consists of these key agents:
- Agent 1: Credit and fraud assessment
- Agent 2: Mortgage decision and interest rate calculation
- Agent 3: Mortgage offer or rejection letter
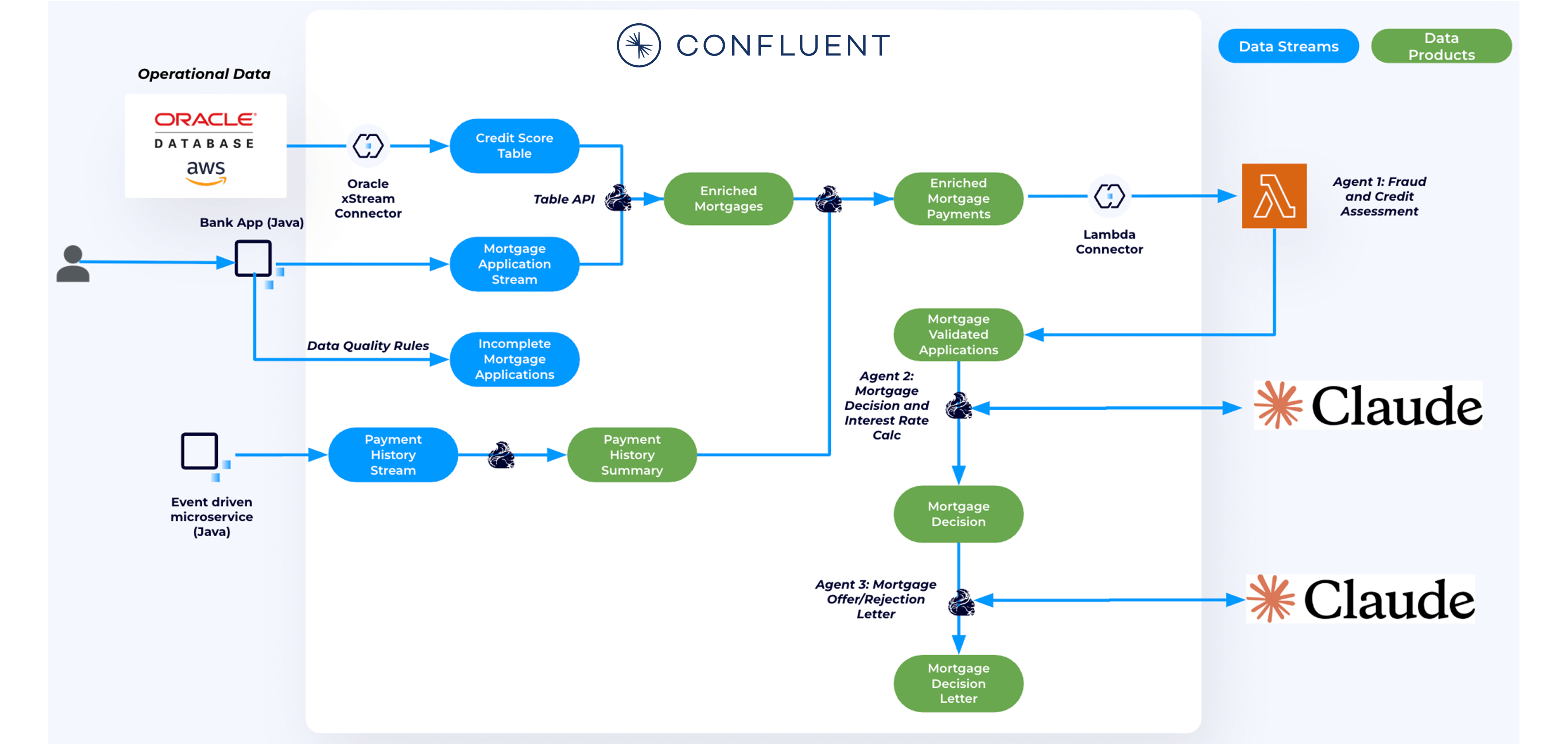
Fully managed connectors such as the Oracle xStream source connector streams applicant credit scores into Kafka topics. Additionally, Java producer apps publish historical payments and live mortgage applications, while an AWS Lambda sink connector delivers enriched data to AWS for AI model inference.
Flink builds real-time, contextualized data products by joining and enriching streams. Credit score data and payment history are merged with live mortgage applications using Flink SQL and Table API. User-defined functions (UDFs) compute custom fields, such as estimated insurance costs, while aggregation jobs summarize applicant history. These Flink jobs run serverlessly on Confluent Cloud and continuously emit enriched streams to downstream agents.
Stream Governance features such as Schema Registry and data quality rules ensure that schemas are enforced across all topics to maintain data integrity. In the case of invalid pay slip IDs, for example, those messages are automated routed to dead letter queues. Metadata including ownership info enable discoverability and governance across the data lifecycle.