Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Analytics on Bare Metal: Xenon and Kafka Connect
The following post is a guest blog from Tushar Sudhakar Jee, Software Engineer, Levyx responsible for Kafka infrastructure. You may find this post also on Levyx’s blog.
Abstract
As part of Levyx’s strategy to “plug into” and enhance the performance of leading Big Data platforms, the company recently had its Apache Kafka® connector based on Xenon™ certified by Confluent. In this blog we introduce Xenon, describe our connector, and showcase performance of connector on a commodity on-prem server with SSD ingesting 470GB data at 3.5 million messages per second on a 10GbE network.
Xenon
Xenon is a low latency and scalable data analytics engine designed to manage the retrieval, processing, and indexing of very large datasets. Xenon is designed to make efficient use of many core processors and SSD/NVM based storage. The driving goals behind Xenon are to achieve optimal I/O performance and compute efficiency. For optimal I/O performance, Xenon bypasses the file-system and directly performs flash friendly I/O to SSDs/NVMs, thereby reducing the I/O latency (important for transactional operations) and saturating the I/O bandwidth of storage devices (important for analytics).
On the compute side, Xenon uses just-in-time compilation (in C) to generate on-the-fly analytics code and executes that code on bare metal to achieve the lowest latency and highest throughput possible. The generated code performs direct I/O to the PCIe SSD to reduce read and write amplification. Xenon uses the latest Instruction Set Architecture (ISA), lock-free data structures, and multi-core design principles to maximize system resource utilization and thereby reducing the overall node count. Reducing the number of servers is beneficial not only from a cost standpoint (i.e., a reduced cloud bill), but also simplifies cluster management. The figure below shows the overall flow of data from Kafka to our connector and into Xenon. Note that while a single Xenon node is shown for the sake of clarity, Xenon is distributed and hence can be scaled to many nodes.
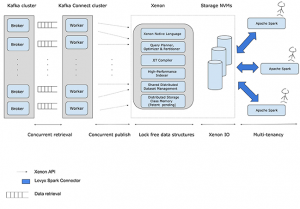 Figure: Data flow and Xenon Architecture
Figure: Data flow and Xenon Architecture
Xenon use case and capabilities
Consider using Xenon if you run analytics on very large datasets requiring a big cluster of nodes with substantial memory in order to meet your latency and throughput requirements. Xenon can place your large datasets on SSD at considerably less cost and perform the same analytics operations with fewer nodes. Moreover, Xenon datasets are shareable, making it ideal for use in environments where a single repository of data is used by multiple teams and applications.
Capabilities of Xenon include:
- Core SQL functionality: filter, projection, selection, sort, join, group by, and aggregates on structured data.
- Support for random lookup and neighborhood search using an index rather than scan and filter.
- Tightly integrated with the Apache Spark system for ease of deployment and use (although fully capable to function in native mode or serve as an off load layer for other big platforms and systems).
- Scales with number of cores in the cluster and uses SSD’s as storage fabric for dataset.
- Multi-tenancy: Xenon datasets are sharable among multiple applications, wherein each application can be running different analytics.
Kafka-Connect-Xenon
This post highlights the benefits of using Confluent certified Levyx Kafka connector, (a.k.a., Kafka-Connect-Xenon™), for streaming data from Kafka into Xenon — a high performance storage and analytics engine. The integration into Kafka uses the Kafka Connect framework. Besides the Kafka connector’s performance, storing data in Xenon includes benefits such as multi-tenancy via a connector interface to Apache Spark. In the rest of this article, we describe:
- Connector Integration: The seamless integration of Kafka-Connect-Xenon with Kafka.
- Connector Performance: Highlight the performance advantages of Xenon in Kafka environments showcasing over 3.5 Million messages per second ingest from Kafka into a single Xenon server with data on NVMe SSD.
Besides this, the Xenon connector offers the following features:
- Multitenancy of the data stored in Xenon via our Spark connector, i.e., multiple Apache Spark contexts can run analytics into data stored in Xenon concurrently.
- Streaming in data formats like Avro and Json with and without schema.
- A data lake to collect messages from different organizations for data exploration and insight generation using analytics.
Connector Integration
The Kafka Connect API is a robust framework for streaming data in and out of Kafka. Our implementation of Kafka-Connect-Xenon leverages the Kafka Connect Sink API to fulfill a simple yet important functionality of getting data out of Kafka into Xenon and leveraging this data to enable concurrent analytics. Kafka Connect, introduced as a new feature in Kafka 0.9+ simplifies building large scale, real time data pipelines by providing a standard way of moving data in and out of Kafka. The blog post on the release of Kafka Connect has more details. Details on the sink connector is available on Confluent site.
A quickstart guide including high level design and code examples are available on Levyx Kafka-Connect-Xenon Github. The supported data format and types are outlined below:
| Category | Supported types |
| Core types | INT8, INT16, INT32, INT64, FLOAT32, FLOAT64, BOOLEAN, STRING, BYTES, ARRAY, MAP and STRUCT |
| Logical types | Date, Time, TimeStamp, Decimal |
| Data formats | Avro and Json with and without schema |
The figure below depicts the flow of data between a Kafka cluster and Kafka-Connect-Xenon. Details on deployment and getting started using a docker based installation is documented on our GitHub page. Xenon being a complete data storage and analytics platform has its own configuration parameters that can be tuned for optimal performance, details of which are omitted for brevity.
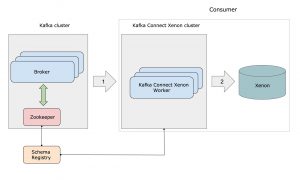
Figure: Deployment of kafka-connect-xenon.
Connector Performance
The metrics we used for monitoring performance and status of Kafka-Connect-Xenon include CPU utilization, Memory utilization, Network utilization, Java heap size on each Kafka Connect API worker and connector status. Overall, the workers balance the division of tasks evenly but there might be an imbalance of workload on workers with varying loads on topics.
The graphs below, generated using Grafana on the Consumer machine highlight some key benefits of Kafka-Connect-Xenon in action:
- We deploy Kafka-Connect-Xenon on a consumer’s machine in standalone mode, using workers of a Kafka Connect cluster. These workers make use of the kafka-connect-xenon-1.0.0-jar-with-dependencies.jar passed via the plugin path;
- The deployment is online, implying that the connect workers are already ready to consume records from the Kafka cluster, while we start the producer to push our records;
- The first section of the graph titled CPU usage highlights the consistent CPU utilization of 60% during the run;
- Monitoring the second section of the graph ensures no sudden spikes in memory utilization;
- The section titled Network Statistics(Reception) shows the connect workers consuming records from the Kafka cluster at ~700 MB/s on a 10GbE network; and
- The final section in the graph titled Disk Octets read/write shows the connect workers writing to XenonTM at ~700 MB/s.
| Feature | Value |
| Data format | JSON without schema as ArrayList. |
| Size of input data | 470 GB |
| Bytes per message | 200 |
| Number of fields | 1 |
| Schema of field in Xenon | CHAR |
| Memory for consumer machine | 256 GB |
| SSD used for brokers | NVMe |
| Storage for broker logs | 240 GB |
| Number of brokers | 3 |
| Cores for Consumer machine | 88 |
| Cores for Broker machine | 64 |
| Version of Confluent Platform | 4.0.0 |
| Version of Xenon | 3.2.0 |
| Mode of running Kafka Connect workers | Standalone in parallel |
| Number of topic partitions | 110 |
| Number of Standalone workers | 6 |
| Messages per second | 700/200 * 1000000 = 3.5M mps |
Performance of Connector
Xenon is designed to be a high performance storage and analytics engine. Therefore, it is natural to expect the same level of performance with Kafka-Connect-Xenon. We show the performance of the connector running on commodity servers and NVMe SSDs for storage. The setup in this example includes two machines running the broker and the connector. The system details are of the two machines are as follows:
| Parameter | Value |
| Broker machine CPU | 64 |
| Consumer machine CPU | 88 |
| RAM | 256 GB for both machines |
| Storage for Consumer Machine | 750 GB NVMe SSD |
| Storage for Broker Logs | 240 GB (on SSD) |
| Confluent Platform Version | 4.0.0 |
| Xenon Version | 3.2.0 |
Setup
Our total data is 470 GB consisting of 200 byte messages. This data, generated using 9 Kafka console producer instances, is pushed to the broker machine running three broker instances. The consumer machine runs (i) six Kafka-Connect-Xenon instances in standalone mode, and (ii) Xenon server using 750 GB SSD for storage. The software setup details are as follows:
| Parameter | Value |
| Data Format | Json without schema as ArrayList. |
| Message Size | 200 bytes |
| Total Data Size | 470 GB |
| Number of fields | 1 |
| Schema of field in Xenon | CHAR |
| Topic Partition | 110 |
| Standalone Workers | 6 |
| Broker Instances | 3 |
| Xenon Instances | 1 |
Measurement
The goals are to measure the following while running the ingest phase:
- Ingest the entire data (i.e., 470 GB) consisting of 2.5 Billion messages followed by the ability to run query via Spark-Xenon connector.
- Measure the performance (i.e., throughput) in messages per second.
- Measure system statistics for analysis.
Results
| Metric | Value |
| Throughput | 3.5 Million messages/sec |
| Total Records | 2.5 Billion (200 byte records) |
| Runtime | 715 seconds |
Note that we can achieve multi-million ingests on commodity servers while persisting the data. Due to the design of our connector and Xenon, the bottleneck here is not the software. We see 60% CPU utilization while the 10 GbE network becomes the bottleneck. With a better network, this can further go up to ~5.6 Million messages per second before CPU becomes the bottleneck. A snapshot of system statistics measurements are below (CPU, Network, Memory, and IO).
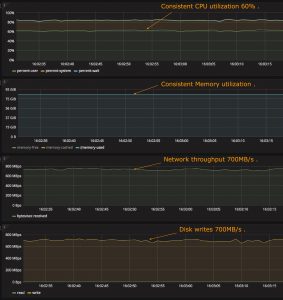
Figure: Monitoring performance of kafka-connect-xenon.
For further details on the Xenon Connector, please contact info@levyx.com.
Interested in More?
If you’d like to know more, here are some resources for you:
- You can download the Confluent Platform
- Read our documentation
- Confluent Professional Services offers advice and help with deployments
- Confluent Training can get your team ready for development and deployment of the Confluent Platform
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독





