[Webinar] Why Real-time Data Streaming is the Foundation of Modern AI Strategies | Register Now
Apache Kafka® Scaling Best Practices
When it comes to Kafka scaling best practices, many assume it’s just a matter of adding more brokers. In reality, scaling Kafka is not just about adding more brokers, it's about optimizing the overall architecture, resource utilization, and day-to-day operations to keep the platform reliable and performant.
Apache Kafka was built for scale from the ground up, with its distributed design separating producers, Kafka brokers, and consumers. This design makes Kafka capable of handling massive data volumes across industries. But with that scalability comes complexity.
If you scale without proper planning, say, adding brokers without adjusting partitions or tuning consumer groups, you can easily end up with wasted resources, uneven load, higher latency, or operational headaches like constant broker rebalancing.
In this guide, you understand how to scale Kafka intelligently. By following the practices here, you’ll learn how to:
-
Scale Kafka clusters both horizontally (adding brokers) and vertically (increasing broker resources).
-
Expand and shrink clusters dynamically as workloads change.
-
Avoid pitfalls like overprovisioning or underutilization.
-
Optimize costs while maintaining cluster health.
-
Improve throughput, minimize consumer lag, and reduce operational risk.
By the end, you’ll have a clear, practical roadmap for getting more out of Kafka without simply throwing hardware at the problem.
Core Principles for Scaling Kafka Effectively
Scaling Kafka is not about adding more brokers in a cluster, it’s about balancing the entire data pipeline. A Kafka deployment is made up of:
-
Producers that send data into topics.
-
Brokers that store and distribute data.
-
Consumers that process events.
-
Metadata services (ZooKeeper or KRaft) that track cluster state.
-
Storage layers that persist logs.
To scale effectively, you need to optimize all of these components together. The goal is to meet throughput, latency, and durability requirements without overspending on infrastructure or introducing unnecessary complexity.
For a deeper dive into these concepts, see the Kafka Docs, Confluent Developer, or the Confluent blog.
Brokers and Partitions: The Building Blocks of Scaling
Before diving into scaling strategies, it’s worth revisiting how Kafka distributes data:
-
Brokers are the servers in a Kafka cluster. Each broker stores and serves data for a subset of partitions. More brokers generally mean more storage and processing power.
-
Partitions are the fundamental unit of parallelism in Kafka. A topic is split into partitions, and each partition can be hosted on different brokers. Adding partitions increases throughput by allowing more consumers to read in parallel.
In practice, scaling Kafka usually involves adding brokers (horizontal scale), increasing partitions (parallelism), or a mix of both. Each decision comes with tradeoffs around complexity, metadata management, and balancing. That brings us to the how of scaling. Once you understand the moving parts of a Kafka deployment, the next step is choosing the right strategy to expand capacity. Not all methods are created equal, some deliver quick wins but hit hard limits, while others unlock long-term flexibility at the cost of added complexity. Let’s break down the core approaches and see where each one fits.
Vertical vs. Horizontal Scaling
-
Vertical scaling means adding more CPU, memory, or disk to existing brokers. It’s simple, but limited by hardware capacity and can create single points of failure.
-
Horizontal scaling means adding brokers and partitions. This improves parallelism and throughput but also increases metadata overhead, rebalancing events, and network traffic.
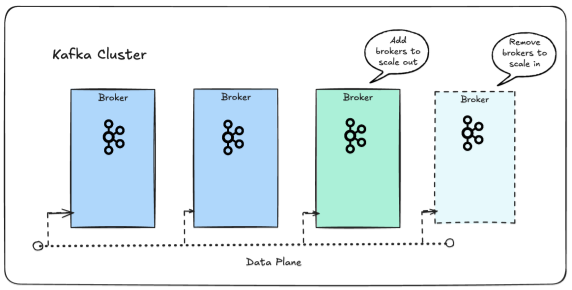
How horizontal scaling with Kafka clusters allows elastic scaling up and down
Load Balancing and Elasticity
-
Load balancing ensures partitions and traffic are evenly spread across brokers. Without it, “hot brokers” can become bottlenecks.
-
Elasticity is the ability to expand or shrink clusters dynamically, matching resources to workload demand. This keeps performance high while avoiding waste.
Each of these strategies has its strengths and tradeoffs. The real challenge is knowing when to apply which approach:
|
Concept |
Description |
Tradeoffs |
|
Vertical Scaling |
Add CPU, RAM, or disk to existing brokers |
Limited scale, single point of failure risk |
|
Horizontal Scaling |
Add more brokers and partitions |
Higher throughput, but more complexity and metadata overhead |
|
Load Balancing |
Evenly distribute partitions/traffic |
Prevents bottlenecks, but requires monitoring and rebalancing |
|
Elasticity |
Scale clusters up or down dynamically |
Cost-efficient, but needs automation to avoid manual ops burden |
Each scaling strategy helps in different situations. Vertical scaling works well for quick fixes or smaller clusters, but it won’t take you very far. Horizontal scaling is the standard for large Kafka deployments, though it brings more moving parts to manage.
Load balancing keeps the cluster efficient, while elasticity ensures you’re not paying for unused capacity. In practice, most production setups use a mix of all four adding brokers for growth, tuning hardware where needed, balancing traffic carefully, and relying on automation to adjust capacity as workloads change.
Managing these tradeoffs on your own can be tough. Confluent makes it easier with autoscaling clusters that handle capacity adjustments automatically, so you maintain performance without overspending or managing infrastructure. You can get started with Confluent today and unlock effortless Kafka scaling.
Roles and Responsibilities for Scaling Self-Managed Kafka
Scaling Apache Kafka in a self-managed setup isn’t just a technical exercise, it’s a cross-team effort that requires clear ownership and collaboration. Without well-defined roles, organizations often face bottlenecks, misconfigurations, and firefighting rather than smooth operations.
Here’s how responsibilities typically break down across teams:
DevOps / SRE Teams
These teams form the backbone of cluster operations. They handle the nuts and bolts of provisioning infrastructure, from configuring servers and networks to deploying brokers. Their work doesn’t end at setup; they continuously monitor system health, configure alerts, apply patches and upgrades, and step in when incidents strike. In short, DevOps and SREs ensure that the Kafka cluster is not only up and running, but also resilient and performant under varying loads.
Data Engineers and Developers
Once the infrastructure is stable, the focus shifts to how data flows through Kafka. This is where engineers and developers come in. They design and implement partition strategies, fine-tune producers and consumers to strike the right balance between throughput and latency, and choose serialization formats (such as Avro or Protobuf) that keep data efficient and compact. They also keep a close eye on consumer lag and throughput, making adjustments to application logic or configurations so that the system scales gracefully as data volumes increase.
Data Architects and Engineering Leads
At a higher level, architects and leads focus on the bigger picture. They forecast future capacity needs, define scaling strategies, and set standards that guide both infrastructure and application decisions. Their job is to avoid extremes, both overprovisioning (which wastes resources and drives up costs) and underutilization (which leads to poor performance or outages). By aligning scaling strategies across teams, they reduce risk, ensure cost-effectiveness, and create a roadmap for sustainable growth.
Having these roles clearly defined not only improves efficiency but also builds confidence that scaling decisions are made thoughtfully rather than reactively. It’s the difference between firefighting problems after they occur versus anticipating and preventing them.
Common Challenges With Scaling Kafka
No matter how Kafka is deployed, whether you’re running it yourself on bare metal, in VMs, or using a cloud-hosted service, scaling it isn’t always smooth. Many of the core pain points are the same, just shifted in who has to deal with them (your ops team vs. the cloud provider).
-
Uneven Load and Hot Partitions
When certain partitions get far more traffic than others, the brokers holding those partitions become “hot.” This often happens because of poor keying strategy (e.g., hashing everything to one partition) or unbalanced partition assignment. Hot partitions can cause latency spikes and uneven throughput across the cluster.
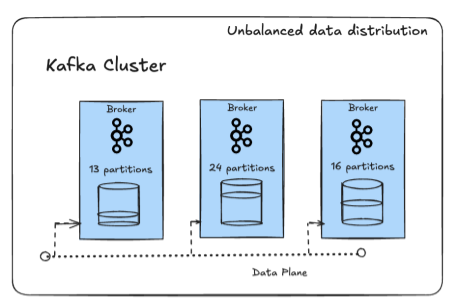
Unbalanced data distribution across brokers in a Kafka cluster
-
Consumer Lag
If consumers can’t keep up with the rate of incoming messages, lag builds up. This leads to backlogs, delayed processing, and in extreme cases, even the risk of hitting retention limits and losing data. Causes range from inefficient consumer code to simply not having enough parallelism or resources.
-
Painful Broker Rebalancing
Adding or removing brokers sounds straightforward, but it triggers partition reassignments across the cluster. During rebalancing, throughput drops, CPU and network usage spike, and operators often need to carefully throttle the process to avoid further instability. In a cloud setup, the provider may handle this but the downtime or performance hit is still felt by the applications.
-
Disk and Network Bottlenecks
Kafka is heavily dependent on fast disks and networks. If a broker’s disk fills up due to retention misconfigurations or a traffic surge, it can stop accepting new data. Similarly, network saturation can throttle producer throughput or slow down replication. Scaling storage and bandwidth quickly in self-managed setups is especially tricky.
-
ZooKeeper/KRaft Bottlenecks
Older Kafka clusters rely on ZooKeeper for cluster metadata management, while newer versions use KRaft (Kafka Raft). Both act as the “brains” of the system. As clusters scale, these control planes can struggle under metadata-heavy workloads, slowing down partition reassignment, topic creation, or controller failovers.
-
Resource Utilization Challenges
Even in well-balanced clusters, CPU, memory, and disk usage aren’t always evenly distributed. One broker may consistently run hotter than others, wasting resources and increasing the chance of failure. In self-managed setups, fixing this is manual and time-consuming; in the cloud, it usually means higher costs for overprovisioning.
Cost of Inefficient Scaling
Failing to scale Kafka efficiently leads to:
-
Increased Operational Overhead: Teams spend more time firefighting issues, troubleshooting lag, fixing partition imbalance, rebalancing brokers, or recovering from outages, rather than focusing on business innovation.
-
Wasted Hardware or Cloud Spend: Overprovisioning means paying for idle compute and storage. Underprovisioning causes performance bottlenecks, downtime, or delayed data pipelines that directly impact SLAs.
-
Delayed Analytics and Business Impact: If data streams are slow or lagging, real-time analytics lose their effectiveness. This delay reduces decision-making speed and business agility.
-
Higher Risk of Outages: Poor scaling increases the chance of broker failures, partition hotspots, and cascading system-wide outages, leading to customer dissatisfaction and reputational risk.
These challenges add up to higher costs, delayed insights, and increased risk of outages. This is where the right platform can make all the difference.
How Is Scaling Kafka Clusters on Confluent Different?
Confluent is designed to reduce these costs by offering fully managed Kafka with automated scaling, operational best practices, and integrations beyond open source Kafka.
Here’s how Confluent addresses the scaling challenges above:
-
Automated Elastic Scaling:
-
Confluent Cloud scales clusters up or down automatically based on traffic removing the need for manual broker sizing, partition redistribution, or capacity planning.
-
Unlike Amazon MSK or self-managed Kafka, which require engineers to monitor and rebalance, Confluent ensures scaling is seamless and invisible to applications.
-
-
Optimized Cost Efficiency:
-
Pay-as-you-go model: you’re billed for actual usage, not idle capacity.
-
Intelligent resource allocation ensures you don’t overprovision for peak loads or risk underprovisioning during spikes.
-
Example: A retail company handling seasonal spikes (Black Friday, Diwali sales) can scale automatically without pre-paying for unused infrastructure.
-
-
Faster Time-to-Value:
-
By removing infrastructure management tasks, teams can focus on building data products, real-time analytics, or event-driven applications instead of Kafka tuning.
-
This translates to faster delivery of insights (e.g., fraud detection models, IoT monitoring, personalized recommendations).
-
-
Built-in Reliability and Resilience:
-
Confluent Cloud provides self-healing, auto-rebalancing, and intelligent partition placement to minimize hot partitions.
-
Guarantees SLAs for uptime and latency, which open source Kafka and hosted Kafka do not provide out of the box.
-
-
Beyond Kafka – A Complete Data Streaming Platform:
-
Confluent integrates connectors, ksqlDB (stream processing), schema registry, and governance tools.
-
This reduces integration costs and operational complexity making it more than just “Kafka as a service.”
-
These challenges make it clear that scaling is more than just a technical exercise. To overcome them, we need both best practices and an awareness of what not to do.
Best Practices for Scaling Kafka
Scaling Apache Kafka isn’t just about adding more brokers or throwing hardware at the problem. It’s about making smart design and configuration decisions that let your cluster grow smoothly without bottlenecks. Here are ten best practices that seasoned Kafka operators rely on:
1. Right-size your partitions per topic
Why it matters: Partitions are the foundation of Kafka’s scalability. More partitions mean more parallelism, but they also mean more metadata to manage.
How to implement: A good rule of thumb is 100–200 partitions per broker as a baseline. Avoid going beyond 4,000 partitions per broker, or you’ll overload the controller. Always size partitions based on expected throughput, not guesswork, and keep an eye out for partition skew (when some partitions get hammered with more traffic than others).
2. Monitor and balance broker workloads
Why it matters: Uneven partition distribution leads to hotspots, where one broker gets overloaded while others idle.
How to implement: Use tools like Cruise Control or Confluent Control Center to automatically rebalance partitions. Regularly check ISR (in-sync replicas) health, if replicas are offline, your durability guarantees are at risk. A balanced cluster is a resilient cluster.
3. Tune producer batching and Kafka compression
Why it matters: Sending tiny messages one at a time is the fastest way to waste network bandwidth and bloat metadata.
How to implement: Set linger.ms to 5–20 ms to give producers time to batch messages, and adjust batch.size to suit your workload. Use lightweight compression codecs like lz4 or snappy for throughput-heavy pipelines. This not only reduces bandwidth but also lowers storage costs over time.
4. Manage topic count and avoid topic sprawl
Why it matters: Every topic adds metadata overhead. Too many topics, and your cluster’s controller can start struggling.
How to implement: Disable auto topic creation in production. Instead, create topics deliberately with naming conventions. Regularly audit your cluster to retire unused topics, and where possible, consolidate related data streams into fewer, well-designed topics.
5. Use Kafka replication wisely
Why it matters: Replication protects you from data loss, but it isn’t free, extra replicas consume disk, network, and CPU.
How to implement: Use a replication factor of 3 for production workloads, with min.insync.replicas=2. Producers should set acks=all to ensure durability. Balance replication with available hardware and latency requirements. The wrong replication strategy either wastes resources or leaves you vulnerable.
6. Secure ZooKeeper, or better, move to KRaft
Why it matters: ZooKeeper has historically been a single point of fragility. Misconfigured, it can become both a bottleneck and a security risk.
How to implement: If you’re still on ZooKeeper, lock it down with ACLs and network restrictions. But longer term, plan a migration to KRaft mode (available in Kafka 3.3+). KRaft removes ZooKeeper entirely, simplifying the control plane and making Kafka clusters more scalable.
7. Use tiered storage for long retention
Why it matters: Keeping months of data on local disks slows brokers down and risks disk exhaustion.
How to implement: Separate hot and cold data. Keep recent data on brokers for low-latency access, and push older segments to cloud storage like S3 or GCS with solutions such as Confluent Tiered Storage. This keeps your cluster lean while retaining historical data cost-effectively.
8. Optimize consumer group behavior
Why it matters: Misbehaving consumer groups are notorious for causing lag and endless rebalance storms.
How to implement: Tune session timeouts and heartbeat intervals carefully. Use static group membership to avoid kicking out stable consumers unnecessarily. And make sure your consumers can actually keep up, parallelize processing where needed so lag doesn’t spiral out of control.
9. Monitor key metrics proactively
Why it matters: Kafka failures rarely come out of nowhere. The signs are usually visible in metrics long before an outage.
How to implement: Track broker CPU, disk I/O, JVM heap, garbage collection times, consumer lag, partition skew, and controller status. Set up automated alerts so your team knows about anomalies before they become business-impacting incidents. Don’t wait for angry users to be your monitoring system.
10. Automate scaling decisions with Confluent Cloud autoscaling
Why it matters: Manual scaling is reactive, error-prone, and slow. In the cloud, you shouldn’t be babysitting broker counts.
How to implement: Use managed services like Confluent Cloud, which scale broker counts and partition assignments automatically based on workload. This eliminates capacity planning guesswork and ensures your cluster always has the right resources at the right time.
Takeaway: Scaling Kafka is as much about discipline as it is about infrastructure. By following these practices, you can build clusters that scale smoothly, avoid hot partitions, and give your teams the confidence to build real-time systems without fearing the next traffic spike. But just as important as knowing what to do is knowing what to avoid. Let’s explore the anti-patterns.
Kafka Scaling Anti-Patterns to Avoid
When it comes to scaling Kafka, many teams assume the solution is simply to throw more hardware at the problem. But Kafka isn’t just another database you can scale vertically or horizontally without thought. It’s a distributed streaming system with moving parts, brokers, producers, consumers, partitions, and metadata management, all of which can become bottlenecks in different ways. Scaling the wrong thing (or scaling too early) often introduces more problems than it solves.
Here are some of the most common scaling mistakes you should actively avoid:
-
Adding More Servers Without Diagnosing the Root Cause
It’s tempting to add more Kafka brokers when you notice lag, high CPU, or delayed messages. But blindly expanding the cluster is rarely the right answer. The issue might actually lie in consumer inefficiency, poor network throughput, or badly designed producers. Adding servers in such cases doesn’t fix the bottleneck, it just spreads the pain across more machines, burning money and complicating operations.
Instead, start with end-to-end profiling. Check whether the delay is coming from consumers, producers, or the brokers themselves. Only scale the cluster once you’re sure it’s the real source of the problem. -
Scaling Kafka When Consumers Are the Bottleneck
A surprisingly common mistake is to assume Kafka itself is slow, when in reality the consumers can’t keep up. Maybe they’re processing messages inefficiently, or maybe you haven’t provisioned enough consumer instances for the partitions available. If you keep scaling brokers in this scenario, you’ll never solve the lag. It's like widening a highway when the traffic jam is actually at the exit ramp.
The fix here is to scale the consumers first. Add more consumer instances, tune your processing logic, and make sure the partition assignment is balanced.
-
Leaving Automatic Topic Creation Enabled in Production
By default, Kafka can automatically create topics the first time they’re referenced. This seems convenient in development, but in production it’s a recipe for chaos. A single typo in a topic name can generate a brand-new topic, leading to topic sprawl, wasted resources, and bloated metadata that slows down the entire cluster.
Always disable auto topic creation in production. Make topic creation an intentional, managed process, ideally automated through Infrastructure as Code (IaC) or Kafka management tooling. -
Ignoring Metadata Scaling Issues
Kafka’s scalability isn’t just about message throughput it’s also about metadata. Every topic and every partition adds to the metadata load managed by the controller (and ZooKeeper or KRaft). Too many topics, or unused ones left lingering, can overwhelm the cluster, leading to controller failovers or increased latency for all operations.
Monitor metadata carefully. Audit your topics regularly, clean up unused ones, and avoid letting partitions balloon without reason. Treat metadata growth as seriously as data growth. -
Overprovisioning Partitions
Partitions are often touted as the magic ingredient for scaling Kafka throughput. And while it’s true that more partitions can increase parallelism, overprovisioning them comes at a heavy cost. Each partition adds file handles, open sockets, and metadata overhead. Too many partitions per broker can bog down even a well-provisioned cluster.
Instead of defaulting to “more partitions = better,” size partitions to match your actual throughput needs. Start smaller, benchmark performance, and increase incrementally.
In short: scaling Kafka isn’t just about making the cluster bigger. It’s about scaling the right part of the system, based on evidence. Avoiding these anti-patterns will save you from unnecessary firefighting and keep your cluster efficient, stable, and easier to manage.
Kafka Scaling Do’s and Don’ts
When it comes to scaling Kafka, there’s no shortage of levers you can pull. But the reality is, scaling well often comes down to avoiding the obvious mistakes and sticking to a few tried-and-true habits. Here’s a quick checklist you can lean on as a sanity check before pushing your cluster into higher loads.
Kafka Scaling Do’s
-
Right-size partitions – Too few partitions can create bottlenecks, while too many increase overhead. Aim for a balance that fits your throughput and consumer scaling needs.
-
Enable batching and compression – Combine smaller messages into batches and use compression to reduce both network traffic and storage footprint.
-
Use replication wisely – Replication adds durability, but also costs performance. Tune replication factors to balance fault tolerance with efficiency.
-
Monitor proactively – Keep an eye on broker health, topic performance, and consumer lag so you can act before issues turn critical.
-
Offload cold data – Move older, less frequently accessed events to cheaper storage like object stores to keep your Kafka clusters lean.
Kafka Scaling Don’ts
-
Don’t over-provision partitions – Having too many can overwhelm the controller, bloat metadata, and slow down cluster operations.
-
Don’t ignore metadata scaling – Both ZooKeeper and KRaft are sensitive to metadata load; overlooking this can destabilize clusters.
-
Don’t scale manually in the cloud – Managed Kafka services and auto-scaling are designed to handle elasticity. Manual scaling often leads to inefficiency and errors.
Scaling Kafka isn’t about blindly throwing more resources at the problem, it’s about balancing efficiency and reliability. By avoiding overprovisioning, automating routine tasks, and keeping a close eye on your metrics, you ensure that your cluster scales gracefully without unnecessary cost or risk.
Of course, knowing the do’s and don’ts is only half the battle. The harder part is applying them consistently at scale, especially when traffic is unpredictable or when teams are stretched thin. This is where a managed platform like Confluent comes in, it bakes many of these best practices into the service itself, so you don’t have to constantly tune, rebalance, or firefight just to keep your clusters running smoothly.
How Confluent Simplifies Kafka Scaling
Confluent abstracts much of the complexity involved in scaling Kafka, making it easier for teams to focus on building applications rather than managing infrastructure. By packaging core Kafka capabilities into a managed, cloud-native service, Confluent helps organizations scale without running into the operational pitfalls we’ve outlined earlier.
-
Autoscaling without manual tuning
In traditional setups, scaling often means predicting traffic spikes and manually adjusting broker counts or partitions. With Confluent Cloud, autoscaling handles this dynamically, resources expand or contract based on workload demands. This ensures applications run smoothly during peak events without unnecessary over-provisioning during quieter periods. -
Serverless Kafka experience
Running Kafka clusters typically requires monitoring controller load, balancing partitions, and provisioning storage. Confluent eliminates this overhead by offering a serverless Kafka experience, where the platform handles resource allocation automatically. Developers can publish and consume events without worrying about underlying infrastructure constraints. -
Tiered storage for cost efficiency
Kafka clusters often face storage bloat as event data grows over time. Confluent’s tiered storage moves older events to cloud object stores, freeing up brokers while keeping data accessible when needed. This keeps clusters lean and reduces operational costs, while still providing the durability and replayability teams rely on. -
Integrated monitoring and governance
Scaling Kafka introduces monitoring challenges, tracking throughput, lag, and metadata health. Confluent simplifies this with integrated monitoring and governance tools, so teams can track performance, enforce data contracts, and maintain compliance without stitching together external tools. -
Faster time-to-value for developers
Instead of investing weeks in cluster setup, tuning, and scaling exercises, developers can onboard quickly with pre-built connectors, APIs, and managed infrastructure. This allows teams to shift focus from cluster management to delivering business value with real-time applications.
By aligning these capabilities with the practical do’s and don’ts of scaling, Confluent ensures Kafka deployments stay resilient, cost-efficient, and future-ready. Instead of reacting to scaling bottlenecks, you can proactively design for growth with confidence.
With that foundation covered, let’s move on to some of the most frequently asked questions about Kafka scaling.
FAQs: Common Kafka Scaling Questions
-
How many partitions should I use in Kafka?
There’s no single “magic number,” but most production deployments start with 50–100 partitions per topic and scale from there. The right number depends on:
-
Throughput requirements – higher throughput needs more partitions.
-
Consumer parallelism – each partition maps to a single consumer thread.
-
Broker capacity – don’t overwhelm brokers with too many small partitions.
A good practice is to start lower and expand as load grows, rather than over-partitioning upfront.
-
What are signs that Kafka needs to be scaled?
Look out for these red flags:
-
Lagging consumers (they can’t keep up with partition throughput).
-
High broker CPU/memory usage (above 70–80% for extended periods).
-
Frequent ISR (In-Sync Replica) changes or rebalances.
-
Increased latency in producing or consuming messages.
If you’re constantly firefighting these, it’s a clear scaling signal.
-
Can Kafka scale automatically in the cloud?
Yes, if you’re using Confluent Cloud or another managed service. Features like:
-
Autoscaling partitions (so you don’t have to resize manually).
-
Elastic storage tiers for handling cold vs. hot data.
-
Serverless options where you only pay for throughput and retention.
In self-managed Kafka, autoscaling is possible but requires custom automation around metrics and infrastructure.
-
How does replication affect Kafka scalability?
Replication improves fault tolerance but also adds network and storage overhead. For example:
-
A topic with replication factor 3 means each message is stored on 3 brokers.
-
This impacts disk usage, network bandwidth, and recovery times.
The tradeoff: higher replication = stronger durability but more resource consumption.
-
What is the best way to monitor Kafka scaling performance?
Key metrics to track include:
-
Consumer lag – are consumers keeping pace with producers?
-
Broker utilization – CPU, memory, and disk I/O.
-
Network throughput – messages in vs. messages out.
-
Partition distribution – ensure partitions are balanced across brokers.
Tools like Confluent Control Center, Prometheus + Grafana, and Datadog provide real-time insights.
-
How do I balance partitions across brokers?
Use Kafka’s partition rebalancing tools or Cruise Control to redistribute load. Balanced partitions prevent hotspots where a few brokers get overloaded while others sit idle.
-
Can I scale Kafka storage without scaling the compute?
Yes, with tiered storage (in Confluent Platform / Cloud). Hot data stays on brokers for low-latency access, while cold data offloads to cheaper object storage like S3 or GCS. This way, you don’t need to overprovision brokers just to hold old messages.
-
What’s better: scaling up (bigger brokers) or scaling out (more brokers)?
Scaling up is simpler but hits limits with CPU, disk I/O, or network.
Scaling out (adding brokers) is more elastic and fault-tolerant, but requires careful partition rebalancing.
In practice, most enterprises do a mix scale up until hardware efficiency peaks, then scale out for elasticity.
Ultimately, scaling Kafka is not about resources alone, but about balance, efficiency, and smart design choices.
Wrapping Up
Scaling Kafka is as much about smart design choices as it is about adding hardware. From knowing the right number of partitions to keeping an eye on lag and replication tradeoffs, the key is balance. With Confluent’s managed services, much of this heavy lifting is automated, letting you focus on building data-driven applications not firefighting cluster issues.