[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Announcing Kafka Connect: Building large-scale low-latency data pipelines
For a long time, a substantial portion of data processing that companies did ran as big batch jobs — CSV files dumped out of databases, log files collected at the end of the day etc. But businesses operate in real-time and the software they run is catching up. Rather than processing data only at the end of the day, why not react to it continuously as the data arrives? This is the emerging world of stream processing. But stream processing only becomes possible when the fundamental data capture is done in a streaming fashion; after all, you can’t process a daily batch of CSV dumps as a stream. This shift towards stream processing has driven the popularity of Apache Kafka. But, even with Kafka, building this type of real-time data pipeline has required some effort.
I’m happy to announce Kafka Connect, a new feature in Apache Kafka 0.9+ that makes building and managing stream data pipelines orders of magnitude easier.
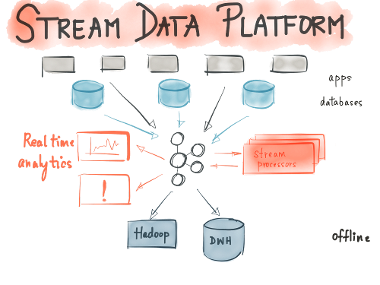
Stream Data Platform: A central hub for all your data
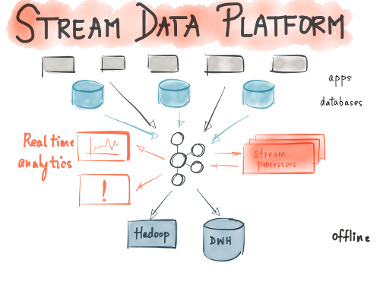
We had the opportunity to build out a Kafka-based stream data platform at LinkedIn and work with dozens of open source adopters and Confluent customers, as they built similar platforms. Here is what we think a future with stream data looks like — a stream data platform that can serve as a central hub for all data; one that runs at company-wide scale and enables diverse distributed applications and systems to consume and process data as free-flowing streams in real-time.
A stream data platform enables 2 things:
- Data integration: A stream data platform captures streams of events or data changes and feeds them to other data systems such as relational databases, key-value stores, Hadoop, or the data warehouse.
- Stream processing: It enables continuous, real-time processing and transformation of these exact same streams and makes the results available system-wide.
Here I will focus on data integration only and explain how Kafka Connect enables data integration by offering a common framework for allowing stream data flow between various systems.
Both data integration and stream processing rely on common infrastructure that can serve as the foundation of storage for stream data.
Kafka: the foundation of a stream data platform
![]() Over the years, Apache Kafka has emerged as the de-facto standard for storing and transporting large-scale stream data in low latency to a variety of applications. For thousands of companies around the globe, Kafka has become a mission-critical cornerstone of their data architecture. Kafka provides the foundation for modern day stream data integration; it is the central stream data platform, but how do you actually get the streams of data from other systems into Kafka?
Over the years, Apache Kafka has emerged as the de-facto standard for storing and transporting large-scale stream data in low latency to a variety of applications. For thousands of companies around the globe, Kafka has become a mission-critical cornerstone of their data architecture. Kafka provides the foundation for modern day stream data integration; it is the central stream data platform, but how do you actually get the streams of data from other systems into Kafka?
Today, companies that want to adopt Kafka write a bunch of code to publish their data streams. What we’ve learned from experience is that doing this correctly is more involved than it seems. In particular, there are a set of problems that every connector has to solve:
- Schema management: The ability of the data pipeline to carry schema information where it is available. In the absence of this capability, you end up having to recreate it downstream. Furthermore, if there are multiple consumers for the same data, then each consumer has to recreate it. We will cover the various nuances of schema management for data pipelines in a future blog post.
- Fault tolerance: Run several instances of a process and be resilient to failures
- Parallelism: Horizontally scale to handle large scale datasets
- Latency: Ingest, transport and process data in real-time, thereby moving away from once-a-day data dumps.
- Delivery semantics: Provide strong guarantees when machines fail or processes crash
- Operations and monitoring: Monitor the health and progress of every data integration process in a consistent manner
These are really hard problems in their own right, it just isn’t feasible to solve them separately in each connector. Instead you want a single infrastructure platform connectors can build on that solves these problems in a consistent way.
Until recently, adopting Kafka for data integration required significant developer expertise; developing a Kafka connector required building on the client APIs.
Introducing Kafka Connect
The wait for Kafka connectors is over. In the 0.9 release of Apache Kafka we added a framework called Kafka Connect that puts into practice everything we know about building scalable stream data pipelines.
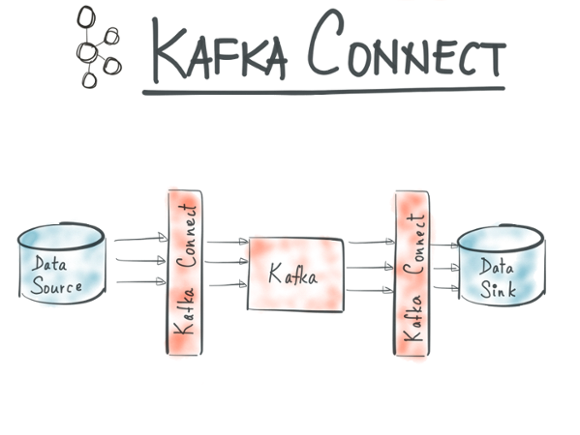 Kafka Connect is a framework for large scale, real-time stream data integration using Kafka. It abstracts away the common problems every connector to Kafka needs to solve: schema management, fault tolerance, partitioning, offset management and delivery semantics, operations, and monitoring. The goals of Kafka Connect are two-fold:
Kafka Connect is a framework for large scale, real-time stream data integration using Kafka. It abstracts away the common problems every connector to Kafka needs to solve: schema management, fault tolerance, partitioning, offset management and delivery semantics, operations, and monitoring. The goals of Kafka Connect are two-fold:
- Encourage the development of a rich ecosystem of open source connectors on top of Kafka. We envision a large repository of connectors to be available soon for enabling stream data flow between various systems.
- Simplify adoption of connectors for stream data integration. Users can deploy Kafka connectors that work well with each other and can be monitored, deployed, and administered in a consistent manner.
The rest of this blog post is a quick overview of Kafka Connect without diving into the architectural details.
At its heart, Kafka Connect is simple. So-called Sources import data into Kafka, and Sinks export data from Kafka. An implementation of a Source or Sink is a Connector. And users deploy connectors to enable data flows on Kafka
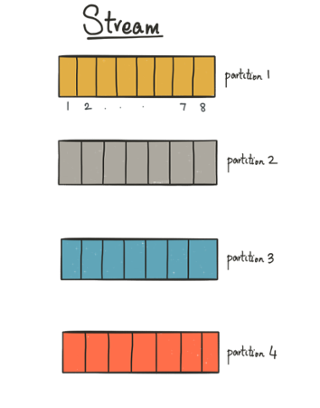
Kafka Connect is designed for large-scale data integration and has a built-in parallelism model; all Kafka Connect sources and sinks map to partitioned streams of records. This is a generalization of Kafka’s concept of topic partitions: a stream refers to the complete set of records that are split into independent infinite sequences of records.
Let me give a few examples. If a stream represents a database, then a stream partition would represent a table in the database. Likewise, if a stream represents an HBase cluster, for example, then a stream partition would represent a specific HBase region.
Stream partitions are the smallest unit of parallelism and allow connectors to process data in parallel. In the examples above, Kafka Connect can copy data for each table or each HBase region, independently, on different hosts, in parallel. Kafka Connect supports a dynamic number of partitions; over time, a stream may grow to add more partitions or shrink to remove them. This allows the database connector, for instance, to discover newly created tables without having to restart the connector.
 Kafka Connect integrates closely with Kafka so it can leverage several capabilities critical to its operation that are natively built within Kafka. This close integration with Kafka has several benefits. First, Kafka has a parallelism model that allows for horizontal scalability while preserving ordering guarantees per partition. This allows Kafka connectors to leverage Kafka’s parallelism model for horizontally scaling high volume stream data integration workloads. Second, Kafka has support for offsets that define the position of a record in a partition and also offers inbuilt support for offset management. This allows every connector built on top of Kafka, whether it is a source or sink, to share a common mechanism of keeping track of the connector’s position in a stream, as well as to restart ingestion after failover. These capabilities are joined by a third one of equal significance in the 0.9 release of Kafka: group management. The group management mechanism allows a group of processes to not only agree on group membership but to also coordinate actions on membership changes. Similar to how Kafka consumer groups use it to agree which consumers are part of the same group and coordinate who consumes which partitions, Kafka Connect leverages it to load-balance connector partitions over the set of processes that form a Kafka Connect cluster.
Kafka Connect integrates closely with Kafka so it can leverage several capabilities critical to its operation that are natively built within Kafka. This close integration with Kafka has several benefits. First, Kafka has a parallelism model that allows for horizontal scalability while preserving ordering guarantees per partition. This allows Kafka connectors to leverage Kafka’s parallelism model for horizontally scaling high volume stream data integration workloads. Second, Kafka has support for offsets that define the position of a record in a partition and also offers inbuilt support for offset management. This allows every connector built on top of Kafka, whether it is a source or sink, to share a common mechanism of keeping track of the connector’s position in a stream, as well as to restart ingestion after failover. These capabilities are joined by a third one of equal significance in the 0.9 release of Kafka: group management. The group management mechanism allows a group of processes to not only agree on group membership but to also coordinate actions on membership changes. Similar to how Kafka consumer groups use it to agree which consumers are part of the same group and coordinate who consumes which partitions, Kafka Connect leverages it to load-balance connector partitions over the set of processes that form a Kafka Connect cluster.
 Offset management is key to stream data integration; since there is no expected end to the data stream, it is necessary that connectors remember their position in the stream in a continuous fashion. This allows connectors to failover while preserving delivery guarantees; resume data copying from where they left off instead of losing or recopying too much data. Every record in Kafka Connect contains a key, a value, as well as an offset that marks the position of every record in the stream partition. The offset varies per source: for a generic database source, an offset might refer to a timestamp column value while for the MySQL source, an offset would refer to the position of the row in the transaction log. For a sink connector, it is the Kafka offset. Kafka Connect natively offers an offset storage mechanism that connectors can rely on; connectors either flush offsets on demand or at a configured regular interval. The framework handles offset recovery transparently such that connectors can restart data ingestion from the last checkpointed position in the stream.
Offset management is key to stream data integration; since there is no expected end to the data stream, it is necessary that connectors remember their position in the stream in a continuous fashion. This allows connectors to failover while preserving delivery guarantees; resume data copying from where they left off instead of losing or recopying too much data. Every record in Kafka Connect contains a key, a value, as well as an offset that marks the position of every record in the stream partition. The offset varies per source: for a generic database source, an offset might refer to a timestamp column value while for the MySQL source, an offset would refer to the position of the row in the transaction log. For a sink connector, it is the Kafka offset. Kafka Connect natively offers an offset storage mechanism that connectors can rely on; connectors either flush offsets on demand or at a configured regular interval. The framework handles offset recovery transparently such that connectors can restart data ingestion from the last checkpointed position in the stream. Kafka Connect supports two different levels of delivery guarantees between a source and sink system: at least once, at most once, and will support exactly once in a future release when that capability is available natively within Kafka. The connector implementation drives the delivery guarantees offered. For instance, any sink that allows idempotent writes and offers the ability to store offsets with the data, can provide exactly once delivery semantics. The Kafka HDFS connector, that ships with Confluent Platform 2.0, provides exactly once guarantees by storing both the data and offset in one atomic operation. On the other hand, Kafka does not support exactly-once writes yet, and hence, a source connector that writes to Kafka only supports at least once and at most once guarantees.
Kafka Connect supports two different levels of delivery guarantees between a source and sink system: at least once, at most once, and will support exactly once in a future release when that capability is available natively within Kafka. The connector implementation drives the delivery guarantees offered. For instance, any sink that allows idempotent writes and offers the ability to store offsets with the data, can provide exactly once delivery semantics. The Kafka HDFS connector, that ships with Confluent Platform 2.0, provides exactly once guarantees by storing both the data and offset in one atomic operation. On the other hand, Kafka does not support exactly-once writes yet, and hence, a source connector that writes to Kafka only supports at least once and at most once guarantees.
Kafka Connect is agnostic to process deployment and resource management; it is not responsible for starting, stopping, or restarting processes. In other words, Kafka Connect automatically detects failures and rebalances work over remaining processes. What it doesn’t do is impose a particular resource management framework or set of operational tools; it will work well with Puppet, Chef, Mesos, Kubernetes, YARN etc. — or none if you prefer to manage processes manually or through other orchestration tools.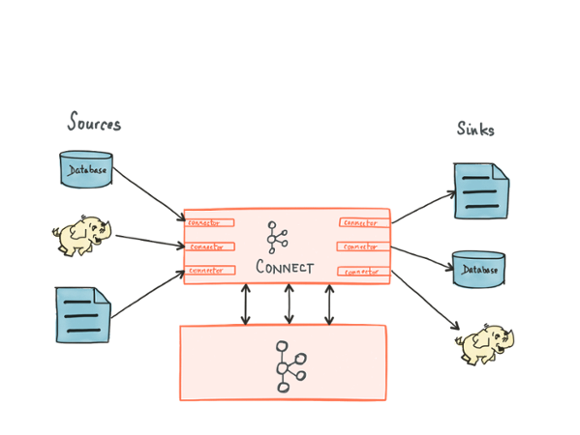
Kafka Connect is part of Apache Kafka 0.9+
The connector development follows a federated model: anyone in the open source community can write a Kafka connector. Confluent Platform 2.0+ ships with certified and open source HDFS and JDBC connectors.
Calling all Kafka connector builders
I invite the community to help build open source connectors to Apache Kafka. To build one, you can browse through the Kafka Connect documentation, this tutorial or read the Javadocs. If you are ready to write a connector, reference the Connector Developer Guide, post questions or requests to the open source mailing list, and ping us to add your connector to the Kafka Connector hub.
Kafka Connect: All Your Data, Everywhere, Now
Kafka Connect is designed for large scale stream data integration and is the standard way of copying data using Kafka. If you use Kafka, then running Kafka Connect will allow the entire company’s data flows to be managed, run, and monitored all the same way. By offering better interoperability between connectors to various systems, Kafka Connect enables organizations to adopt a unified approach to data integration for both stream and batch data sources.
Acknowledgements: I’d like to acknowledge Ewen Cheslack-Postava, Gwen Shapira, Liquan Pei, and the Apache Kafka community for their work on Kafka Connect.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



More Signal, Less Guesswork: New Kafka Observability Updates in Confluent Cloud
Confluent Cloud rolled out new observability updates that give operators direct visibility into streaming workload performance. New Metrics API signals expose client throttling by principal, consumer group rebalance duration, connection attempt spikes, and compacted partition counts.



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.