Fast, Frictionless, and Secure: Explore our 120+ Connectors Portfolio | Join Webinar!
Announcing Tutorials for Apache Kafka
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
We’re excited to announce Tutorials for Apache Kafka®, a new area of our website for learning event streaming. Kafka Tutorials is a collection of common event streaming use cases, with each tutorial featuring an example scenario and several complete code solutions. It’s the fastest way to learn how to use Kafka with confidence.
We’re building this because we know that event streaming is a radically different way of thinking. It causes us to rethink the way we architect our programs and systems. Although it has heaps of benefits (immutability, information sharing, and fault tolerance, to name a few), it can be surprisingly difficult for newcomers to learn.
It doesn’t need to be that way.
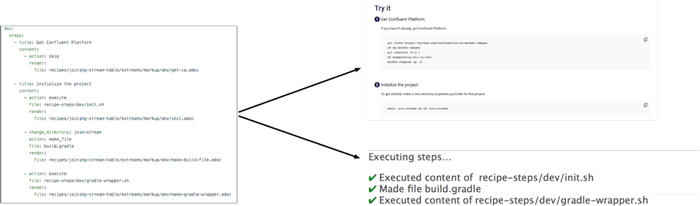
For beginners, Kafka Tutorials reveals the “shape” of the problems that event streaming can solve. It makes it easier to recognize the domain of things that you might use event streaming for. Moreover, each tutorial reliably takes you from zero to working code by following each of the steps.
For the experienced, it’s a crucial reference guide that makes your work easier. Easily look up how to join a stream and a table together when you’re rusty, or quickly recall how to merge discrete streams together. Over time, we’ll introduce more advanced material that makes use of the entire stack.
Although it’s early, we’re building Kafka Tutorials for the long term. That’s why we’ve intelligently engineered the site to use a unique flavor of literate programming. Each tutorial that you see on a page is backed by a single data structure. We’ve built programs that understand this shared structure—namely one to render the page, and another to test the content of the page. That means that when we make changes to each tutorial, they are automatically validated on a continuous integration system to ensure that we’re giving you actual code that works.
Lastly, Kafka Tutorials is a community-driven site. Its source code is available on GitHub. If you have a great idea for a new tutorial or can make an existing open better, we’d love your contributions.
Happy learning!
Apache, Apache Kafka, Kafka and the Kafka logo are trademarks of the Apache Software Foundation. The Apache Software Foundation has no affiliation with and does not endorse the materials provided.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.