Fast, Frictionless, and Secure: Explore our 120+ Connectors Portfolio | Join Webinar!
A Comprehensive REST Proxy for Kafka
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
As part of Confluent Platform 1.0 released about a month ago, we included a new Kafka REST Proxy to allow more flexibility for developers and to significantly broaden the number of systems and languages that can access Apache Kafka clusters. In this post, I’ll explain the REST Proxy’s features, how it works, and why we built it.
What is the REST Proxy and why do you need one?
The REST Proxy is an HTTP-based proxy for your Kafka cluster. The API supports many interactions with your cluster, including producing and consuming messages and accessing cluster metadata such as the set of topics and mapping of partitions to brokers. Just as with Kafka, it can work with arbitrary binary data, but also includes first-class support for Avro and integrates well with Confluent’s Schema Registry. And it is scalable, designed to be deployed in clusters and work with a variety of load balancing solutions.
We built the REST Proxy first and foremost to meet the growing demands of many organizations that want to use Kafka, but also want more freedom to select languages beyond those for which stable native clients exist today. However, it also includes functionality beyond traditional clients, making it useful for building tools for managing your Kafka cluster. See the documentation for a more detailed description of the included features.
A quick example
If you’ve used the Confluent Platform Quickstart to start a local test cluster, starting the REST Proxy for your local Kafka cluster should be as simple as running
$ kafka-rest-start
To use it with a real cluster, you only need to specify a few connection settings. The proxy includes good default settings so you can start using it without any need for customization.
The complete API provides too much functionality to cover in this blog post, but as an example I’ll show a couple of the most common use cases. To keep things language agnostic, I’ll just show the cURL commands. Producing messages is as easy as:
$ curl -i -X POST -H "Content-Type: application/vnd.kafka.avro.v1+json" --data '{
"value_schema": "{\"type\": \"record\", \"name\": \"User\", \"fields\": [{\"name\": \"username\", \"type\": \"string\"}]}",
"records": [
{"value": {"username": "testUser"}},
{"value": {"username": "testUser2"}}
]
}' \
http://localhost:8082/topics/avrotest
This sends an HTTP request using the POST method to the endpoint http://localhost:8082/topics/avrotest, which is a resource representing the topic avrotest. The content type, application/vnd.kaka.avro.v1+json, indicates the data in the request is for the Kafka proxy (application/vnd.kafka), contains Avro keys and values (.avro), using the first API version (.v1), and JSON encoding (+json). The payload contains a value schema to specify the format of the data (records with a single field username) and a set of records. Records can specify a key, value, and partition, but in this case we only include the value. The values are just JSON objects because the REST Proxy can automatically translate Avro’s JSON encoding, which is more convenient for your applications, to the more efficient binary encoding you want to store in Kafka.
The server will respond with:
HTTP/1.1 200 OK
Content-Length: 209
Content-Type: application/vnd.kafka.v1+json
Server: Jetty(8.1.16.v20140903)
{
"key_schema_id": null,
"value_schema_id": 1,
"offsets": [
{"partition": 0, "offset":0, "error_code": null, "error": null},
{"partition": 0, "offset":1, "error_code": null, "error": null}
]
}
This indicates the request was successful (200 OK) and returns some information about the messages. Schema IDs are included, which can be used as shorthand for the same schema in future requests. Information about any errors for individual messages (error and error_code) are provided in case of failure, or are null in case of success. Successfully recorded messages include the partition and offset of the message.
Consuming messages requires a bit more setup and cleanup, but is also easy. Here we’ll consume the messages we just produced to the topic avrotest. Start by creating the consumer, which will return a base URI you use for all subsequent requests:
$ curl -i -X POST -H "Content-Type: application/vnd.kafka.v1+json" \
--data '{"format": "avro", "auto.offset.reset": "smallest"}' \
http://localhost:8082/consumers/my_avro_consumer
HTTP/1.1 200 OK
Content-Length: 121
Content-Type: application/vnd.kafka.v1+json
Server: Jetty(8.1.16.v20140903)
{
"instance_id": "rest-consumer-1",
"base_uri": "http://localhost:8082/consumers/my_avro_consumer/instances/rest-consumer-1"
}
Notice that we specified that we’ll consume Avro messages and that we want to read from the beginning of topics we subscribe to. Next, just GET a topic resource under that consumer to start receiving messages:
$ curl -i -X GET -H "Accept: application/vnd.kafka.avro.v1+json" \
http://localhost:8082/consumers/my_avro_consumer/instances/rest-consumer-1/topics/avrotest
HTTP/1.1 200 OK
Content-Length: 134
Content-Type: application/vnd.kafka.avro.v1+json
Server: Jetty(8.1.16.v20140903)
[
{
"key": null,
"value": {"username": "testUser"},
"partition": 0,
"offset": 0
},
{
"key": null,
"value": {"username": "testUser2"},
"partition": 0,
"offset": 1
}
]
When you’re done consuming or need to shut down this instance, you should try to clean up the consumer so other instances in the same group can quickly pick up the partitions that had been assigned to this consumer:
$ curl -i -X DELETE \
http://localhost:8082/consumers/my_avro_consumer/instances/rest-consumer-1
HTTP/1.1 204 No Content
Server: Jetty(8.1.16.v20140903)
This is only a short example of the API, but hopefully shows how simple it is to work with. The example above can quickly be adapted to any language with a good HTTP library in just a few lines of code. Using the API in real applications is just as simple.
How does the REST Proxy work?
I’ll leave a detailed explanation of the REST Proxy implementation for another post, but I do want to highlight some high level design decisions.
HTTP wrapper of Java libraries – At it’s core, the REST Proxy simply wraps the existing libraries provided with the Apache Kafka open source project. This includes not only the producer and consumer you would expect, but also access to cluster metadata and admin operations. Currently this means using some internal (but publicly visible) interfaces that may require some ongoing maintenance because that code has no compatibility guarantees; therefore the REST Proxy depends on specific versions of the Kafka libraries and the Confluent Platform packaging ensures the REST Proxy uses a compatible version. As the Kafka code standardizes some interfaces (and protocols) for these operations we’ll be able to rely on those public interfaces and therefore be less tied to particular Kafka versions.
JSON with flexible embedded data – Good JSON libraries are available just about everywhere, so this was an easy choice. However, REST Proxy requests need to include embedded data — the serialized key and value data that Kafka deals with. To make this flexible, we use vendor specific content types in Content-Type and Accept headers to make the format of the data explicit. We recommend using Avro to help your organization build a manageable and scalable stream data platform. Avro has a JSON encoding, so you can embed your data in a natural, readable way, as the introductory example demonstrated. Schemas need to be included with every request so they can be registered and validated against the Confluent Schema Registry and the data can be serialized using the more efficient binary encoding. To avoid the overhead of sending schemas with every request, API responses include the schema ID that the Schema Registry returns, which can subsequently be used in place of the full schema. If you opt to use raw binary data, it cannot be embedded directly in JSON, so the API uses a string containing the base64 encoded data.
Stateful consumers – Consumers are stateful and tied to a particular proxy instance. This is actually a violation of REST principles, which state that requests should be stateless and should contain all the information necessary to serve them. There are ways to make the REST Proxy layer stateless, e.g., by moving consumer state to a separate service, just as a separate database is used to manage state for a RESTful API. However, we felt the added complexity and the cost of extra network hops and latency wasn’t warranted in this case. The approach we use is simpler and the consumer implementation already provides fault tolerance: if one instance of the proxy fails, other consumers in the same group automatically pick up the slack until the failed consumers can be restarted.
Distributed and load balanced – Despite consumers being tied to the proxy instance that created them, the entire REST Proxy API is designed to be accessed via any load balancing mechanism (e.g. discovery services, round robin DNS, or software load balancing proxy). To support consumers, each instance must be individually addressable by clients, but all non-consumer requests can be handled by any REST Proxy instance.
Why a REST Proxy?
In addition to the official Java clients, there are more than a dozen community-contributed clients across a variety of languages listed on the wiki. So why bother writing the REST Proxy at all?
It turns out that writing a feature complete, high performance Kafka client is currently a pretty difficult endeavor for a few reasons:
Flexible consumer group model – Kafka has a consumer group model, as shown in the figure below, that generalizes a few different messaging models, including both queuing and publish-subscribe semantics. However, the protocol currently leaves much of the work to clients. This has some significant benefits for brokers, e.g., minimizing the work they do and making performance very predictable. But it also means Kafka consumers are “thick clients” that have to implement complex algorithms for features like partition load balancing and offset management. As a result, it’s common to find Kafka client libraries supporting only a fraction of the Java client’s functionality, sometime omitting high-level consumer support entirely.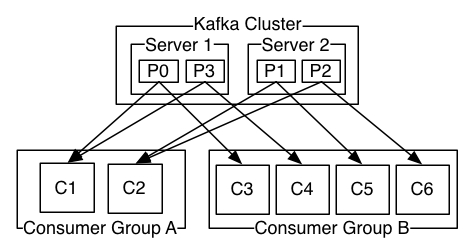 Kafka’s consumer group model supports multiple consumers on the same topic, organized into groups of variable and dynamic size, and supports offset management. This is very flexible, scalable, and fault tolerant, but means non-Java clients have to implement more functionality to achieve feature parity with the Java clients.
Kafka’s consumer group model supports multiple consumers on the same topic, organized into groups of variable and dynamic size, and supports offset management. This is very flexible, scalable, and fault tolerant, but means non-Java clients have to implement more functionality to achieve feature parity with the Java clients.
Low-level networking – Even a small Kafka cluster on moderate hardware can support very high throughput, but writing a cluster to take advantage of this requires low level networking code. Producers need to efficiently batch messages to achieve high throughput while minimizing latency, manage many connections to brokers (usually using an async I/O API), and gracefully handle a wide variety of edge cases and errors. It’s a substantial time investment to write, debug, and maintain these libraries.
Protocol evolution – The 0.8 releases come with a promise of compatibility and a new versioned protocol to enable this. The community has also implemented a new approach to making user visible changes, both to catch compatibility problems before they occur and to act as documentation for users. As the protocol evolves and new features are added, client implementations need to add support for new features and remove deprecated ones. By leveraging the official Java clients, the REST Proxy picks up most of these changes and fixes for free. Some new features will require REST API changes, but careful API design that anticipates new features will help insulate applications from these changes.
The REST Proxy is a simple solution to these problems: instead of waiting for a good, feature-complete client for your language of choice, you can use a simple HTTP-based interface that should be easily accessible from just about any language.
But there were already a few REST proxies for Kafka out there, so why build another? Although the existing proxies were good — and informed the design of the Confluent REST Proxy — it was clear that they were written to address a few specific use cases. We wanted to provide a truly comprehensive interface to Kafka, which includes administrative actions in addition to complete producer and consumer functionality. We haven’t finished yet — today we provide read-only access to cluster metadata but plan to add support for administrative actions such as partition assignment — but soon you should be able to both operate and use your cluster entirely through the REST Proxy.
Finally, it’s worth pointing out that the goal of the REST Proxy is not to replace existing clients. For example, if you’re using C or Python and only need to produce or consume messages, you may be better served by the existing high quality librdkafka library for C/C++ or kafka-python library for Python. Confluent is invested in development of native clients for a variety of popular languages. However, the REST Proxy provides a broad-reaching solution very quickly and supports languages where no developer has yet taken on the task of developing a client.
Tradeoffs
Of course, there are some tradeoffs to using the REST Proxy instead of native clients for your language, but in many cases these tradeoffs are acceptable when you consider the capabilities you get with the REST Proxy.
The most obvious tradeoff is complexity: the REST Proxy is yet another service you need to run and maintain. We’ve tried to make this as simple as possible, but adding any service to your stack has a cost.
Another cost is in performance. The REST Proxy adds extra processing: clients construct and make HTTP requests, the REST Proxy needs to parse requests, transform data between formats both for produce and consume requests, and handle all the interaction with Kafka itself, at least doubling bandwidth usage. And the performance costs aren’t only as simple as doubling costs because the REST Proxy can’t use all the same optimizations that the Kafka broker can (e.g., sendfile is not an option for the proxy consumer responses). Still, the REST Proxy can achieve high throughput.
I'll discuss some benchmarking numbers in more detail in a future post, but the most recent version of the proxy achieves about ⅔ of the current Kafka throughput benchmark of the Java clients when producing binary messages and about ⅕ the rate when consuming binary messages.
Some of this performance can be regained with higher performance CPUs on your REST Proxy instances because a significant fraction of the performance reduction is due to increased CPU usage (parsing JSON, decoding embedded content in produce requests or encoding embedded content in responses, serializing JSON responses).
The REST Proxy also exposes a very limited subset of the normal client configuration options to applications. It is designed to act as shared infrastructure, sitting between your Kafka cluster and many of your applications. Limiting configuration of many settings to the operator of the proxy in this multi-tenant environment is important to maintaining stability. One good example where this is critical is consumer memory settings. To achieve good throughput, consumer responses should include a relatively large amount of data to amortize per-request overheads over many messages. But the proxy needs to buffer that amount of data for each consumer, so it would be risky to give complete control of that setting to each application that creates consumers. One misbehaving consumer could affect all your applications. Future versions should offer more control, but these options need to be added to the API with considerable care.
Finally, unless you have a language-specific wrapper of the API, you won’t get an idiomatic API for your language. This can have a significant impact on the verbosity and readability of your code. However, this is also the simplest problem to fix, and at relatively low cost. For example, to evaluate and validate the API, I wrote a thin node.js wrapper of the API. The entire library clocks in at about 650 lines of non-comment non-whitespace code, and a simple example that ingests data from Twitter’s public stream and computes trending hashtags is only about 200 lines of code.
Conclusion
This first version of the REST Proxy provides basic metadata, producer, and consumer support using Avro or arbitrary binary data. We hope it will enable broader adoption of Kafka by making all of Kafka’s features accessible, no matter what language or technology stack you’re working with.
We’re just getting started with the REST Proxy and have a lot more functionality planned for future versions. You can get some idea of where we’re heading by looking at the features we’ve noted are missing right now, but we also want to hear from you about what features you would find most useful, either on our community mailing list, on the project’s issue tracker, or through pull requests.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.